【流式处理系统】使用 Flink 消费数据并处理落库的完整方案
可以完全在 Flink 中完成数据消费、计算加工和结果落库的整个流程,不需要将数据拉到本地服务处理。以下是完整的实现方案:
方案架构
数据源 → Flink(消费+处理) → MySQL
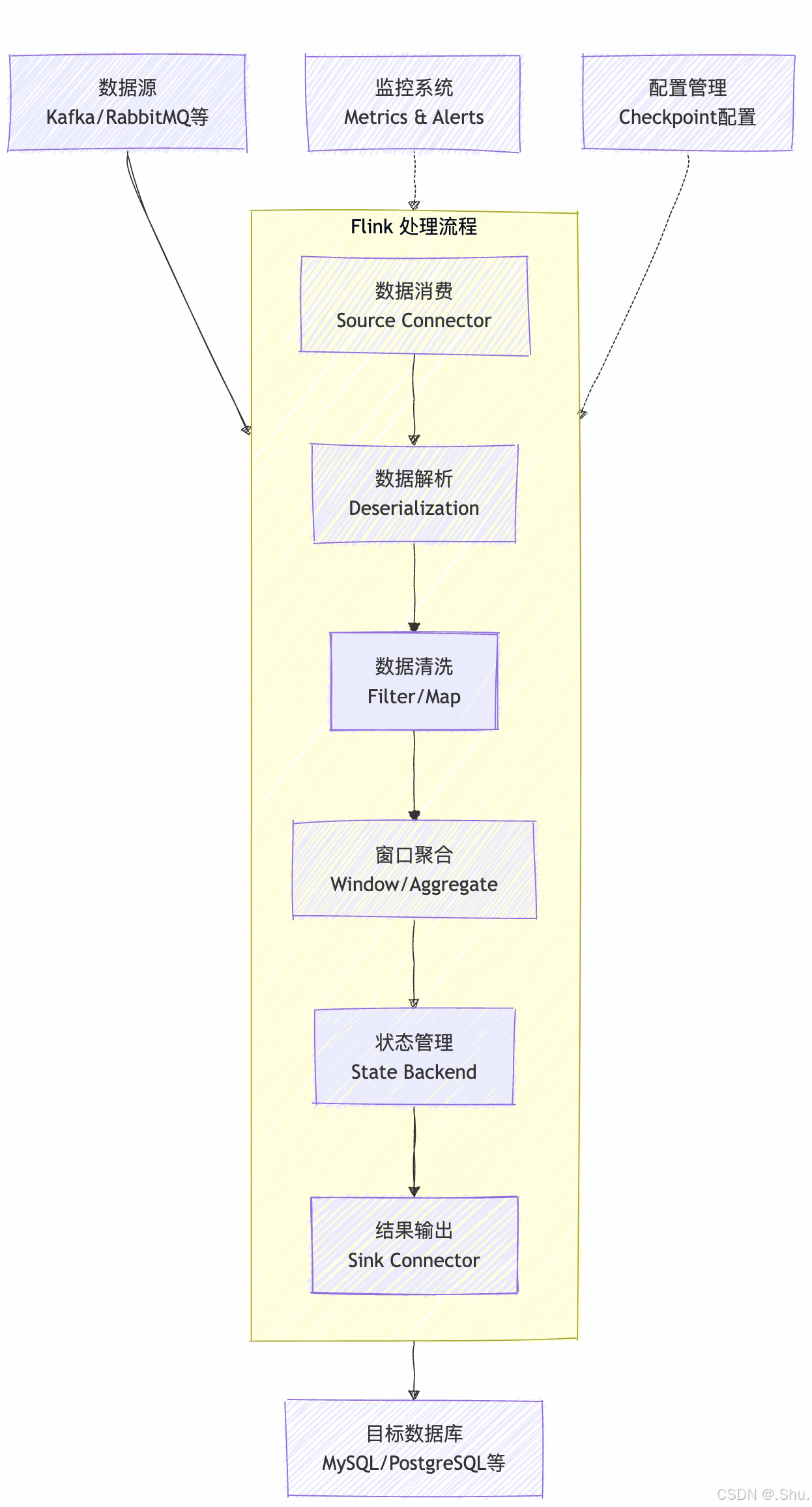
具体实现步骤
1. 添加依赖
首先确保你的 Flink 项目中包含以下依赖(Maven 示例):
<!-- Flink 基础依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 数据源连接器(以Kafka为例) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- MySQL连接器 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
2. Flink 数据处理代码示例
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import java.util.Properties;
public class FlinkToMysqlJob {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 配置Kafka消费者(数据源)
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-group");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"input-topic",
new SimpleStringSchema(),
properties
);
// 3. 添加数据源
DataStream<String> stream = env.addSource(kafkaSource);
// 4. 数据处理(示例:解析JSON、过滤、转换)
DataStream<Order> orders = stream
.map(new MapFunction<String, Order>() {
@Override
public Order map(String value) throws Exception {
// 解析JSON字符串为Order对象
return parseOrderFromJson(value);
}
})
.filter(order -> order.getAmount() > 0); // 过滤无效订单
// 5. 数据聚合(示例:按用户ID分组,计算总金额)
DataStream<UserOrderSummary> userSummaries = orders
.keyBy(Order::getUserId)
.timeWindow(Time.minutes(5)) // 5分钟窗口
.aggregate(new OrderAggregator()); // 自定义聚合函数
// 6. 配置MySQL Sink
JdbcConnectionOptions jdbcOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/your_db")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("username")
.withPassword("password")
.build();
// 7. 添加MySQL Sink
userSummaries.addSink(JdbcSink.sink(
"INSERT INTO user_order_summary (user_id, total_amount, order_count, window_end) " +
"VALUES (?, ?, ?, ?) ON DUPLICATE KEY UPDATE " +
"total_amount = VALUES(total_amount), order_count = VALUES(order_count)",
(statement, summary) -> {
statement.setString(1, summary.getUserId());
statement.setDouble(2, summary.getTotalAmount());
statement.setInt(3, summary.getOrderCount());
statement.setTimestamp(4, new java.sql.Timestamp(summary.getWindowEnd()));
},
JdbcExecutionOptions.builder()
.withBatchSize(100)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
jdbcOptions
));
// 8. 执行任务
env.execute("Flink Kafka to MySQL Job");
}
// 自定义聚合函数示例
public static class OrderAggregator implements AggregateFunction<Order, Accumulator, UserOrderSummary> {
@Override
public Accumulator createAccumulator() {
return new Accumulator();
}
@Override
public Accumulator add(Order order, Accumulator accumulator) {
accumulator.userId = order.getUserId();
accumulator.totalAmount += order.getAmount();
accumulator.orderCount++;
return accumulator;
}
@Override
public UserOrderSummary getResult(Accumulator accumulator) {
return new UserOrderSummary(
accumulator.userId,
accumulator.totalAmount,
accumulator.orderCount,
System.currentTimeMillis()
);
}
@Override
public Accumulator merge(Accumulator a, Accumulator b) {
a.totalAmount += b.totalAmount;
a.orderCount += b.orderCount;
return a;
}
}
// 辅助类
public static class Accumulator {
public String userId;
public double totalAmount = 0;
public int orderCount = 0;
}
}
关键点说明
-
数据消费:Flink 提供了各种数据源的连接器(Kafka、RabbitMQ、文件等)
-
数据处理:可以在 Flink 中完成:
- 数据清洗和转换(map、filter)
- 复杂计算(process function)
- 窗口聚合(window、aggregate)
- 状态管理(state)
-
结果存储:
- 使用
JdbcSink将结果写入 MySQL - 支持批处理写入(提高性能)
- 支持重试机制(提高可靠性)
- 使用
-
优势:
- 全流程在 Flink 中完成,避免数据移动开销
- 利用 Flink 的分布式计算能力,处理大规模数据
- 支持 exactly-once 语义,保证数据一致性
部署方式
- 本地运行:直接运行 main 方法(开发测试用)
- Standalone 集群:打包后提交到 Flink 集群
- YARN/K8s:在生产环境部署
注意事项
- 根据你的数据源类型选择合适的连接器
- 对于高吞吐场景,调整 MySQL Sink 的批处理参数
- 考虑使用连接池管理数据库连接
- 生产环境需要配置 checkpoint 和状态后端
这种方案比将数据拉到本地处理更高效、更可靠,特别适合大规模数据处理场景。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120698

 浙公网安备 33010602011771号
浙公网安备 33010602011771号