Redis 底层数据结构解析(一):String 类型与 SDS 的深度优化
1. 引言:Redis 字符串的设计哲学
Redis 作为高性能的内存数据库,其字符串类型的实现远非表面上看起来那么简单。当我们执行 SET name "John" 这样简单的命令时,Redis 在底层做出了精妙的工程设计决策,这些决策直接影响着内存使用效率、性能表现和系统稳定性。
与 C 语言传统的以空字符结尾的字符串不同,Redis 自主研发了简单动态字符串(Simple Dynamic String,SDS)抽象类型,这不仅解决了 C 字符串的诸多缺陷,还为 Redis 的高性能奠定了坚实基础。本文将深入剖析 String 类型的三种编码方式(int、embstr、raw),详细解析 SDS 的实现原理,并通过源码分析展示 Redis 如何在这些简单操作背后做出复杂的优化决策。
2. Redis 字符串的三种编码方式
2.1 INT 编码:极致简单的数值存储
当存储的数据是整数值时,Redis 会采用最直接的存储方式 - 直接将整数值存储在指针位置上。
实现原理:
在 64 位系统中,一个指针占用 8 字节空间,而 long 类型也占用 8 字节。Redis 利用这一特性,直接将整数值存储在原本应该指向 SDS 结构的指针字段中,通过类型标识来区分这是整数值还是实际指针。
源码分析(Redis 7.0):
// object.c
robj *createStringObjectFromLongLongWithOptions(long long value, int tryobj) {
// 如果值在 0-10000 范围内且尝试使用共享对象
if (tryobj && value >= 0 && value < OBJ_SHARED_INTEGERS) {
return shared.integers[value];
} else {
// 检查值是否适合直接编码在指针中
if (value >= LONG_MIN && value <= LONG_MAX) {
robj *o = createObject(OBJ_STRING, NULL);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*)((long)value);
return o;
} else {
// 对于超出long范围的值,仍然使用字符串编码
return createStringObjectFromLongLongForValue(value);
}
}
}
内存布局对比:
普通字符串对象内存布局:
[RedisObject结构] -> [SDS结构] -> [实际字符串数据]
INT编码字符串对象内存布局:
[RedisObject结构] (ptr字段直接存储整数值)
优势:
- 零额外内存分配:不需要为值单独分配内存,减少内存碎片
- 极致性能:无需解引用指针,直接访问数据
- 减少内存占用:节省了SDS头部和单独分配的内存开销
适用场景:
计数器、小范围ID、状态标志等整数值存储场景,如 SET counter 100、INCR counter。
2.2 EMBSTR 编码:小字符串的优化之道
对于较短的字符串,Redis 采用了 embstr (embedded string) 编码方式,将 RedisObject 和 SDS 结构在内存中连续存放。
实现原理:
embstr 编码通过一次内存分配操作,创建一块连续的内存空间,前半部分存储 RedisObject,后半部分存储 SDS 结构和字符串数据。这种布局对 CPU 缓存更加友好。
关键阈值计算:
Redis 7.0 中,embstr 和 raw 的分界点通常是 44 字节,这个值的计算基于:
- RedisObject 占用 16 字节
- sdshdr8 占用 3 字节(len、alloc、flags)
- 字符串内容 + 1 字节的结束符 ‘\0’
- 内存分配器通常按 2^N 字节对齐分配
64 位系统中计算:16 + 3 + 44 + 1 = 64 字节,正好是内存对齐的理想大小。
源码分析:
// object.c
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 分配单块连续内存
robj *o = zmalloc(sizeof(robj) + sizeof(struct sdshdr8) + len + 1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh + 1;
o->refcount = 1;
// 设置 SDS 属性
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
// 复制数据
if (ptr) {
memcpy(sh->buf, ptr, len);
sh->buf[len] = '\0';
} else {
memset(sh->buf, 0, len+1);
}
return o;
}
内存布局:
[RedisObject (16字节)] [sdshdr8 (3字节)] [字符串数据 (N字节)] [\0 (1字节)]
所有内容在一段连续的内存中,没有任何指针间隔。
优势:
- 单次内存分配:减少内存分配器压力
- 缓存局部性:连续内存布局提高CPU缓存命中率
- 减少内存碎片:紧凑布局减少内存碎片
限制:
embstr 编码是只读的,任何修改操作都会导致编码转换为 raw。
2.3 RAW 编码:大字符串的标准表示
当字符串长度超过阈值或需要修改时,Redis 使用 raw 编码,这是标准的 SDS 表示方式。
实现原理:
raw 编码中,RedisObject 和 SDS 是分开分配的内存块,RedisObject 的 ptr 字段指向独立的 SDS 结构。
源码分析:
// object.c
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr, len));
}
robj *createObject(unsigned type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW; // 设置为RAW编码
o->ptr = ptr;
o->refcount = 1;
// ... 其他初始化
return o;
}
内存布局:
[RedisObject] -> [SDS结构] -> [实际字符串数据]
优势:
- 可修改性:支持原地修改和扩容
- 灵活性:适合各种长度的字符串
- 兼容性:支持二进制安全数据
3. SDS 深度解析:Redis 字符串的核心
3.1 SDS 结构设计
Redis 为不同长度的字符串设计了多种 SDS 结构,以优化内存使用:
sdshdr5(已弃用但保留布局):
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 低3位存储类型,高5位存储长度 */
char buf[];
};
sdshdr8 / sdshdr16 / sdshdr32 / sdshdr64:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 已使用长度 */
uint8_t alloc; /* 总分配容量,不包括头和空终止符 */
unsigned char flags; /* 类型标志 */
char buf[];
};
类型选择策略:
Redis 根据字符串长度自动选择最合适的 SDS 类型:
- 长度 < 2^5:使用 sdshdr5(实际很少使用)
- 长度 < 2^8:使用 sdshdr8
- 长度 < 2^16:使用 sdshdr16
- 以此类推…
3.2 SDS 的优势特性
3.2.1 O(1) 时间复杂度获取长度
传统 C 字符串的问题:
// 需要遍历整个字符串直到遇到 '\0'
size_t strlen(const char *str) {
const char *s = str;
while (*s) s++;
return (s - str);
}
SDS 的解决方案:
static inline size_t sdslen(const sds s) {
// 通过指针运算获取header,然后读取len字段
unsigned char flags = s[-1];
switch(flags & SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
// ... 其他类型
}
}
3.2.2 杜绝缓冲区溢出
C 字符串的隐患:
char str1[10] = "hello";
char str2[10] = "world";
strcat(str1, " too long!"); // 缓冲区溢出!
SDS 的安全机制:
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
// 检查是否需要扩容
s = sdsMakeRoomFor(s, len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
3.2.3 减少内存重分配次数
空间预分配策略:
当 SDS 需要扩容时,不仅会分配所需的空间,还会额外分配冗余空间:
- 新长度 < SDS_MAX_PREALLOC (1MB):分配双倍所需空间
- 新长度 >= SDS_MAX_PREALLOC:每次多分配 1MB
惰性空间释放:
缩短字符串时并不立即释放多余空间,而是通过 alloc 字段记录,供后续操作使用。
源码实现:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s - sdsHdrSize(oldtype);
newlen = (len + addlen);
// 空间预分配策略
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// 根据新长度选择适当的SDS类型
type = sdsReqType(newlen);
// ... 类型转换和内存分配逻辑
}
3.2.4 二进制安全
传统 C 字符串不能包含空字符 ‘\0’,因为这会提前终止字符串。SDS 通过 len 属性来记录长度,使得它可以安全地存储任何二进制数据。
// 可以安全存储包含空字符的数据
sds s = sdsnewlen("hello\0world", 11);
printf("%zu\n", sdslen(s)); // 输出11,而不是5
3.3 SDS API 内部机制
3.3.1 字符串创建
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
// 根据长度选择适当的SDS类型
switch(type) {
case SDS_TYPE_5: {
// ... 处理小字符串
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh = s_malloc(sizeof(struct sdshdr8) + initlen + 1);
if (sh == NULL) return NULL;
s = (char*)sh + sizeof(struct sdshdr8);
s[-1] = type;
SDS_HDR(8,s)->len = initlen;
SDS_HDR(8,s)->alloc = initlen;
break;
}
// ... 其他类型
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
3.3.2 内存管理策略
Redis 使用自定义的内存分配器(zmalloc、zfree)来管理 SDS 内存,这些分配器在标准 malloc/free 基础上增加了内存使用统计和边界检查等功能。
// zmalloc.c
void *zmalloc(size_t size) {
void *ptr = malloc(size + PREFIX_SIZE);
if (!ptr) zmalloc_oom_handler(size);
// 记录内存分配统计
update_zmalloc_stat_alloc(zmalloc_size(ptr));
return (char*)ptr + PREFIX_SIZE;
}
4. 编码转换与动态适配
4.1 自动编码转换
Redis 会根据操作动态调整字符串的编码方式:
INT → RAW:
当对整数字符串进行追加操作时:
// 示例操作
SET counter 100
APPEND counter 1 // counter 现在值为 "1001",编码变为 RAW
// 源码逻辑(object.c)
if (o->encoding == OBJ_ENCODING_INT) {
// 将整数字符串转换为RAW编码
char buf[32];
ll2string(buf, sizeof(buf), (long)o->ptr);
o->ptr = sdsnew(buf);
o->encoding = OBJ_ENCODING_RAW;
}
EMBSTR → RAW:
任何修改 embstr 编码字符串的操作都会触发转换:
// object.c
robj *tryObjectEncoding(robj *o) {
// 如果对象是embstr编码且需要修改
if (o->encoding == OBJ_ENCODING_EMBSTR) {
o->encoding = OBJ_ENCODING_RAW;
// 其他转换逻辑...
}
return o;
}
4.2 共享对象优化
Redis 对小型整数对象(0-9999)实现了共享机制,避免重复创建相同的对象:
// server.c
void createSharedObjects(void) {
// 创建共享整数对象
for (j = 0; j < OBJ_SHARED_INTEGERS; j++) {
shared.integers[j] = makeObjectShared(createObject(
OBJ_STRING, (void*)(long)j));
shared.integers[j]->encoding = OBJ_ENCODING_INT;
}
}
4.3、Redis String 编码选择与转换流程图
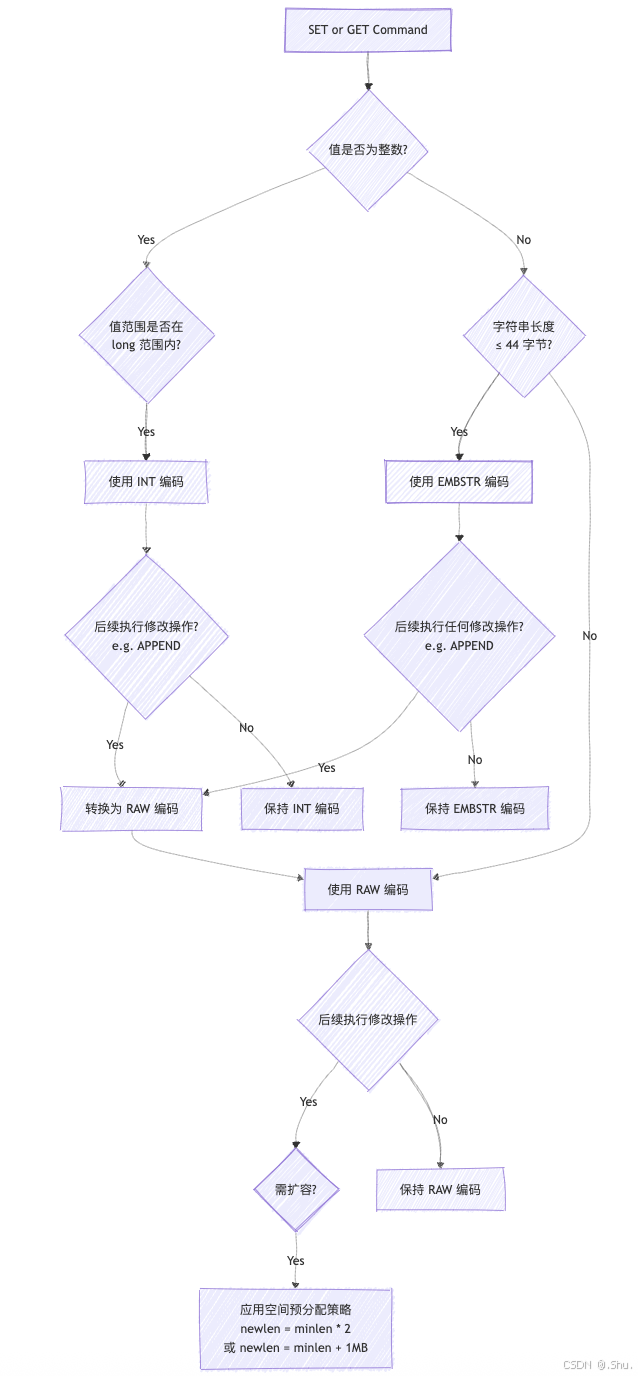
5. 性能分析与最佳实践
5.1 内存使用对比
通过实际数据对比不同编码的内存使用情况:
| 场景 | 数据 | INT编码 | EMBSTR编码 | RAW编码 |
|---|---|---|---|---|
| 小整数 | 100 | 16字节 (RedisObject) | - | - |
| 短字符串 | “hello” | - | 16+3+5+1=25字节 | 16+8+5+1=30字节 |
| 长字符串 | 1KB数据 | - | - | 16+8+1024+1=1049字节 |
5.2 性能优化建议
- 使用整数编码:对于计数器等整数值,直接使用整数存储
- 利用共享对象:优先使用0-9999范围内的小整数
- 避免大字符串修改:大字符串的追加操作可能触发重分配
- 预分配空间:对于已知大小的字符串,使用
sdsnewlen预分配空间
5.3 实际应用场景
场景一:高性能计数器
# 使用整数编码,极致性能
SET user:1000:visits 0
INCR user:1000:visits
场景二:用户会话存储
# 中等长度字符串,通常使用embstr编码
SET session:abc123 "{userid:1000, expires:1630000000}"
场景三:大型数据缓存
# 大字符串,使用raw编码
SET large:data "<large json or binary data>"
6. 总结
Redis 的 String 类型通过三种编码方式(INT、EMBSTR、RAW)和 SDS 的精心设计,在简单易用的接口背后实现了复杂而高效的内存管理和性能优化。这种分层设计哲学体现了 Redis 的几个核心原则:
- 根据数据特性选择最优表示:整数、短字符串、长字符串各有其最适合的编码方式
- 空间与时间的权衡:通过空间预分配换取操作性能,通过惰性释放减少内存碎片
- 渐进式优化:根据操作动态调整编码方式,适应数据变化
理解 String 类型的底层实现不仅有助于我们更好地使用 Redis,也为设计高性能存储系统提供了宝贵的思路。在后续文章中,我们将继续深入探讨 List、Hash、Set 等数据结构的底层实现原理。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120690

 浙公网安备 33010602011771号
浙公网安备 33010602011771号