MySQL 和 MongoDB 在高并发场景下的表现分析对比 & 执行流程分析
MySQL 在高并发场景下的表现分析
数据模型特性带来的影响
步骤 1:数据规范化与关联查询
- MySQL 要求数据高度规范化,不同实体存储在独立的表中
- 在高并发读取时,获取完整业务对象需要执行多表 JOIN 操作
- 性能影响:每个 JOIN 都涉及索引查找、临时表创建,在并发量高时成为瓶颈
- 优化手段:需要通过反规范化、应用层缓存来减少 JOIN 次数
步骤 2:固定模式的数据写入
- 表结构必须预先定义,ALTER TABLE 操作需要锁表
- 在高并发环境下,schema 变更会导致服务不可用
- 应对策略:需要在业务低峰期进行 DDL 操作,或使用在线 DDL 工具
步骤 3:事务处理的性能代价
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
COMMIT;
- 跨行事务需要维护 undo log、redo log,保证 ACID
- 在极高并发下,事务锁等待和死锁检测开销显著增加
- 优化方案:减少事务范围,使用乐观锁,读写分离
扩展性实现路径
步骤 4:垂直扩展优先
- 首先升级硬件:更多 CPU 核心、更大内存、更快 SSD
- 优点:简单直接,应用无需改造
- 瓶颈:单机硬件存在物理上限,成本指数增长
步骤 5:读写分离
- 写操作仍然集中在单主库,存在写入瓶颈
- 主从延迟导致读到的数据可能不是最新的
- 适合读多写少的场景,缓解读压力
步骤 6:分库分表 - 应用层实现的复杂性
- 分片键选择:需要精心设计,避免热点问题
- 跨分片查询:需要在应用层合并结果,复杂度高
- 分布式事务:需要引入额外框架(如 Seata),性能损耗大
- 数据迁移:需要停机或使用双写方案,风险高
锁机制与并发控制
步骤 7:InnoDB 行级锁的实战表现
- 理论上支持行级锁,但在高并发更新同一页面时可能升级为页锁
- Gap Lock 和 Next-Key Lock 在 REPEATABLE-READ 隔离级别下减少幻读,但增加锁冲突
- 死锁检测机制在极高并发下消耗大量 CPU 资源
MongoDB 在高并发场景下的表现分析
文档模型的核心优势
步骤 1:嵌入式文档的数据局部性
// 一次查询获取完整订单信息,无需 JOIN
{
"_id": ObjectId("..."),
"order_id": "ORD001",
"customer": {
"name": "张三",
"address": {"city": "北京", "street": "..."}
},
"items": [
{"product": "手机", "price": 2999, "quantity": 1},
{"product": "耳机", "price": 299, "quantity": 2}
],
"total_amount": 3597
}
- 性能优势:单次磁盘 I/O 读取完整业务对象
- 缓存友好:相关数据集中存储,提高缓存命中率
- 并发收益:减少网络往返和查询解析次数
步骤 2:动态模式的敏捷性
- 新增字段无需 DDL 操作,不影响在线服务
- 适合快速迭代的业务,适应需求变化
- 高并发优势:零停机 schema 变更,支持灰度发布
内置分片的线性扩展能力
步骤 3:分片集群的自动数据分布
- 写扩展:通过分片键将写入负载分布到多个分片
- 自动平衡: chunks 自动分裂和迁移,无需人工干预
- 应用无感知:mongos 提供统一入口,路由逻辑对应用透明
步骤 4:分片键设计的决定性影响
- 优质分片键示例:
{user_id: 1, timestamp: -1}- 写负载均匀分布到所有分片
- 查询通常包含 user_id,可以靶向单个分片
- 劣质分片键示例:
{status: 1}- 大部分新订单状态为"pending",导致写热点
- 查询需要扫描所有分片(散射-聚集)
并发控制与写入性能
步骤 5:WiredTiger 引擎的并发优势
- 文档级锁:不同文档的并发写入互不阻塞
- 压缩写入:默认使用 Snappy 压缩,减少 I/O 压力
- 内存优化:使用缓存友好的 B-Tree 结构,批量写入
步骤 6:写入关注与一致性权衡
// 弱一致性,最高吞吐量
db.products.insertOne(
{item: "card", qty: 15},
{writeConcern: {w: 0}} // 不等待确认
)
// 强一致性,性能较低
db.products.insertOne(
{item: "card", qty: 15},
{writeConcern: {w: "majority", j: true}} // 等待多数节点确认并刷盘
)
- 可根据业务需求灵活调整一致性级别
- 日志类数据可用弱一致性换取更高吞吐
聚合框架的并行处理
步骤 7:分片环境下的聚合优化
// 聚合管道在分片间并行执行
db.sales.aggregate([
{$match: {date: {$gte: ISODate("2024-01-01")}}},
{$group: {_id: "$product", total: {$sum: "$amount"}}},
{$sort: {total: -1}},
{$limit: 10}
])
- 每个分片并行执行聚合前期阶段
- mongos 负责最终合并,充分利用集群计算能力
- 适合实时数据分析场景
高并发场景对比决策流程
场景 1:电商交易系统
需求:高一致性、复杂事务、库存管理
选择 MySQL 的原因步骤:
- 库存扣减需要精确性:UPDATE inventory SET stock = stock - 1 WHERE product_id = ? AND stock > 0
- 订单创建涉及多表:orders, order_items, payments 需要事务保证
- 数据一致性优先:不能超卖,不能重复支付
场景 2:物联网平台
需求:海量设备数据采集、实时监控、灵活 schema
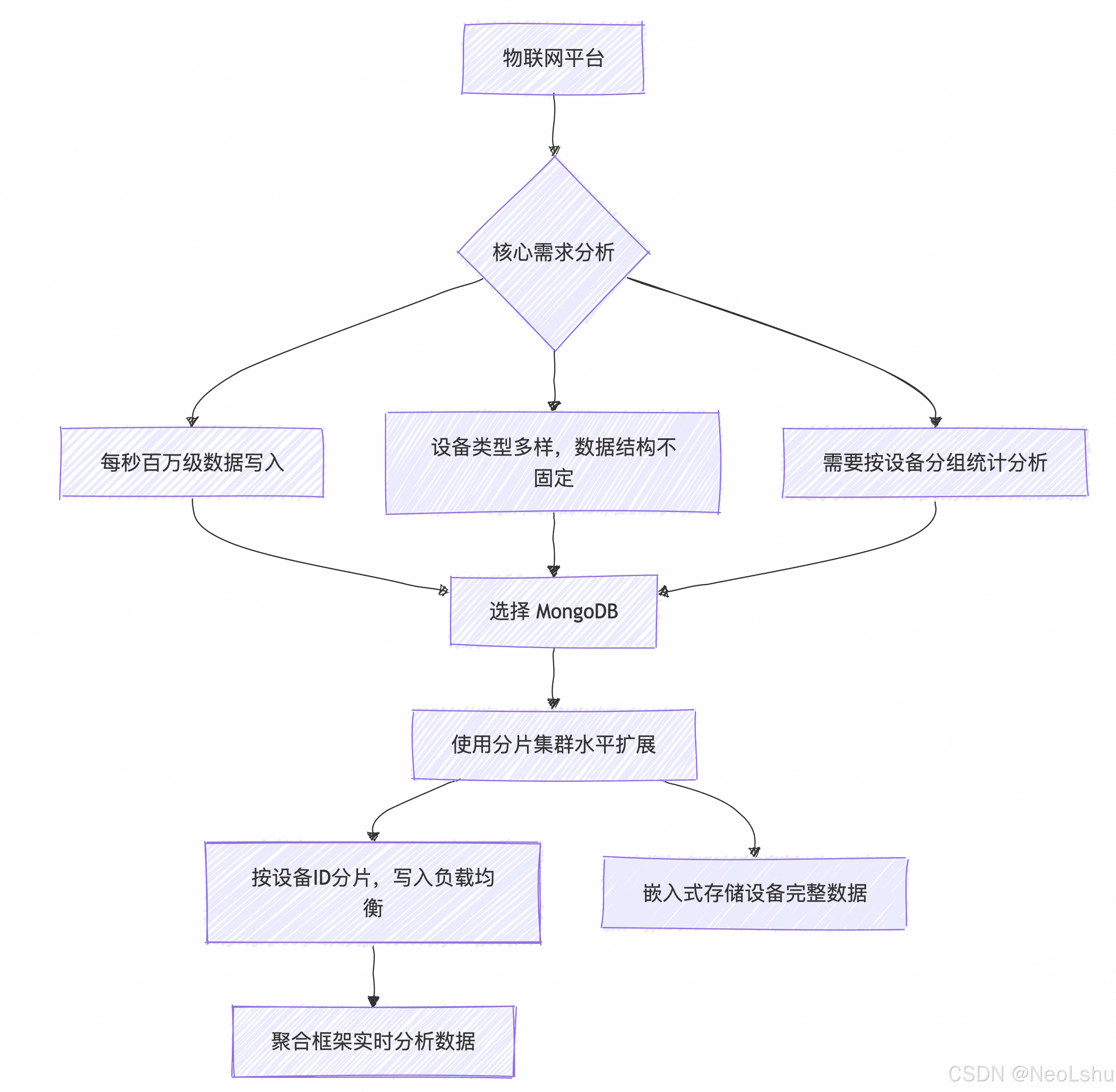
选择 MongoDB 的原因步骤:
- 写入吞吐量要求:分片集群轻松应对百万级 TPS
- 设备异构性:不同型号设备上报字段不同,动态 schema 完美适应
- 数据分析模式:聚合管道高效处理时间序列数据
场景 3:内容管理系统
需求:快速迭代、多版本内容、个性化推荐
混合架构选择步骤:
- 用户关系数据 → MySQL:关注、粉丝关系需要严格一致性
- 文章内容数据 → MongoDB:支持富文本、版本历史、标签数组
- 用户行为日志 → MongoDB:记录浏览、点赞历史,用于推荐计算
- 缓存层 → Redis:热点内容缓存,减少数据库压力
性能优化关键指标对比
| 优化维度 | MySQL 优化策略 | MongoDB 优化策略 |
|---|---|---|
| 读取优化 | 增加从库、查询优化、覆盖索引 | 合理分片、使用投影、创建复合索引 |
| 写入优化 | 批量插入、减少索引、分区表 | 有序插入、调整写关注、分片扩展 |
| 扩展性 | 分库分表(复杂)、读写分离 | 自动分片(简单)、标签感知分片 |
| 事务处理 | 原生支持、降低隔离级别 | 多文档事务(4.0+)、合理设计数据模型 |
| 数据模型 | 反规范化、垂直/水平分表 | 嵌入式文档、数组引用、分片键设计 |
总结
MySQL 和 MongoDB 在高并发下的表现差异根源在于其设计哲学:
- MySQL 像精密瑞士手表,为复杂关系和强一致性而生,通过精细优化在固定场景下表现卓越
- MongoDB 像高度可扩展的乐高系统,为灵活性和水平扩展设计,通过架构优势应对海量并发
最终建议:没有绝对的优劣,只有适合与否。在超大规模场景下,很多企业采用多模数据库架构,让每个数据库做最擅长的事情,这才是应对高并发的最优解。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120587

 浙公网安备 33010602011771号
浙公网安备 33010602011771号