Java JMM(Java Memory Model)全方位深入剖析,直击 HotSpot VM 源码和硬件内存模型!!
本文将会深入剖析 Java 内存模型(JMM, Java Memory Model)。这不仅是一个语言规范,更是理解 Java 并发编程精髓和 JVM 底层机制的钥匙。我们将从它的产生原因、核心概念、实现原理,一直深入到 HotSpot VM 的源码层面。
一、为什么需要 JMM?—— 背景与核心问题
现代计算机硬件架构为了弥补 CPU 与主内存(RAM)之间的速度鸿沟,引入了多级缓存、写缓冲区,并且为了充分利用 CPU,编译器(Compiler)和处理器(CPU)会对指令进行重排序优化。这导致了以下问题在多线程环境下被放大:
- 可见性(Visibility):一个线程对共享变量的修改,另一个线程无法立即看到。因为修改可能发生在该线程独有的缓存或写缓冲区中,尚未刷新到主内存。
- 有序性(Ordering):程序代码的执行顺序未必是源代码的书写顺序。编译器的优化重排和 CPU 的指令级并行重排会打乱顺序,虽然在单线程下遵循
as-if-serial语义(结果不变),但在多线程下会导致意想不到的行为。 - 原子性(Atomicity):对于非原子操作(如
i++),一个线程的执行可能被中断,导致另一个线程看到中间状态。
JMM 的核心使命就是: 在各种各样的硬件平台和操作系统之上,通过定义一套标准,为开发者提供一个一致的内存访问视图。它规定了线程如何、何时能看到其他线程写入共享变量的值,以及在必要时如何同步地访问这些变量。JMM 是一个抽象的概念模型,它屏蔽了底层硬件的差异。
二、JMM 的核心架构与概念模型
1. 抽象的架构视图
JMM 将内存抽象为以下结构:
- 主内存(Main Memory):存储所有的共享变量。对应于物理上的部分内存。
- 工作内存(Working Memory):每个线程都有自己的工作内存,其中存储了该线程使用的变量的主内存副本。工作内存是一个抽象概念,它涵盖了缓存、寄存器、写缓冲区以及其他硬件和编译器优化。
![在这里插入图片描述]()
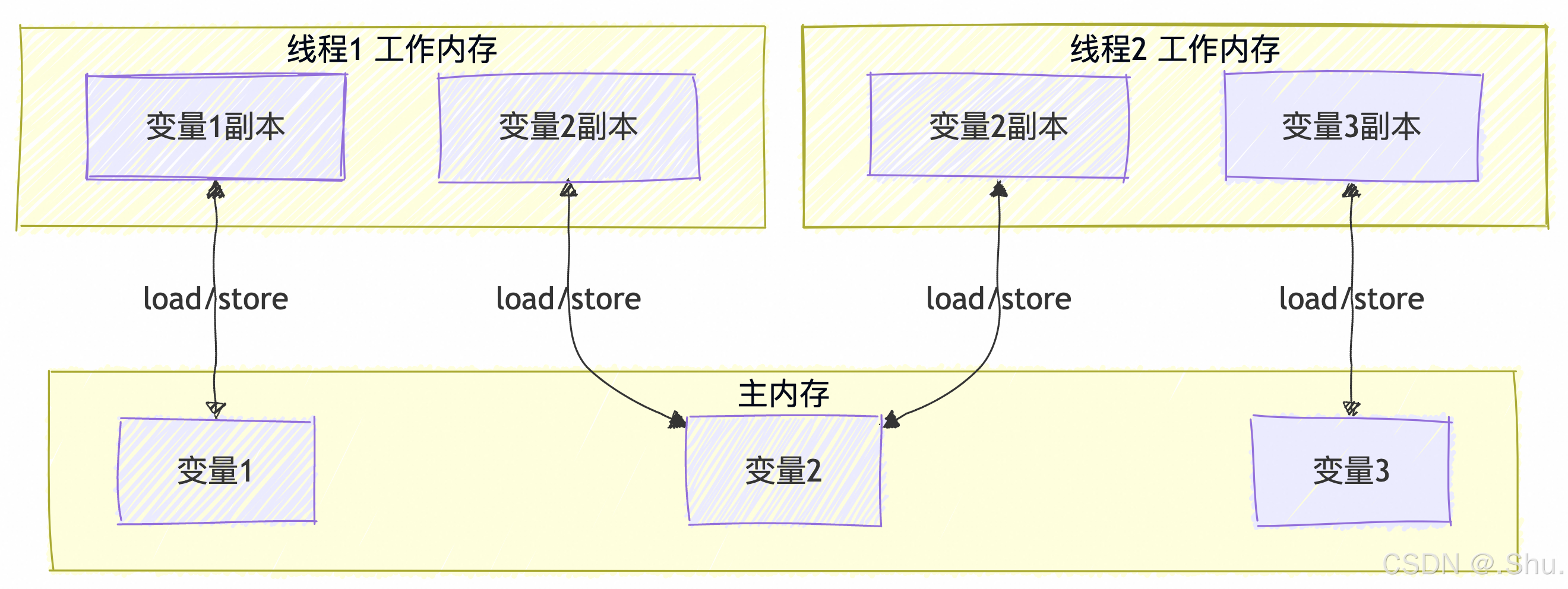
交互规则(JSR-133 规范定义):
- 线程对共享变量的所有操作(读、写)都必须在工作内存中进行。
- 线程不能直接读写主内存中的变量。
- 不同线程之间无法直接访问对方工作内存中的变量。
- 线程间变量的传递(值的同步)必须通过主内存来完成。
2. Happens-Before 关系

这是 JMM 最核心、最本质的概念。它并非指时间上的先后,而是一种可见性保证。happens-before 规则定义了哪些写操作对其他线程的读操作是可见的。
JMM 通过 happens-before 规则来约束编译器和处理器的优化行为,确保在某些关键点上,内存可见性得到保证。
核心规则包括:
- 程序顺序规则(Program Order Rule):在同一个线程中,书写在前面的操作
happens-before书写在后面的操作。 - 监视器锁规则(Monitor Lock Rule):对一个锁的解锁
happens-before于后续对这个锁的加锁。 - volatile 变量规则(Volatile Variable Rule):对一个
volatile变量的写操作happens-before于后续对这个volatile变量的读操作。 - 线程启动规则(Thread Start Rule):
Thread.start()的调用happens-before于这个新线程中的任何操作。 - 线程终止规则(Thread Termination Rule):一个线程中的所有操作都
happens-before于其他线程检测到该线程已经终止(通过Thread.join()返回或Thread.isAlive()返回false)。 - 传递性(Transitivity):如果 A
happens-beforeB,且 Bhappens-beforeC,那么 Ahappens-beforeC。
happens-before 与 as-if-serial 的关系:
as-if-serial是针对单线程的语义,保证结果正确,但不关心其他线程的可见性。happens-before是针对多线程的语义,既保证结果的正确性(在同步正确的情况下),也保证内存的可见性。
三、实现机制:内存屏障(Memory Barriers)
JMM 的 happens-before 规则和内存可见性语义在底层是通过内存屏障(Memory Barrier,也称 Memory Fence)来实现的。内存屏障是一种 CPU 指令,它告诉 CPU 和编译器:
- 确保屏障两侧指令的执行顺序。
- 强制刷新缓存/使缓存失效,确保内存可见性。
JVM 主要使用以下四种屏障(对应不同的重排序限制):
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1; LoadLoad; Load2 | 确保 Load1 数据的装载先于 Load2 及所有后续装载指令。 |
| StoreStore | Store1; StoreStore; Store2 | 确保 Store1 的数据对其他处理器可见(刷新到内存)先于 Store2 及所有后续存储指令。 |
| LoadStore | Load1; LoadStore; Store2 | 确保 Load1 的数据装载先于 Store2 及所有后续的存储指令。 |
| StoreLoad | Store1; StoreLoad; Load2 | 确保 Store1 的数据对其他处理器变得可见(指刷新到内存)先于 Load2 及所有后续装载指令。这是一个“全能型”屏障,开销最大。 |
线程与主内存交互示意图
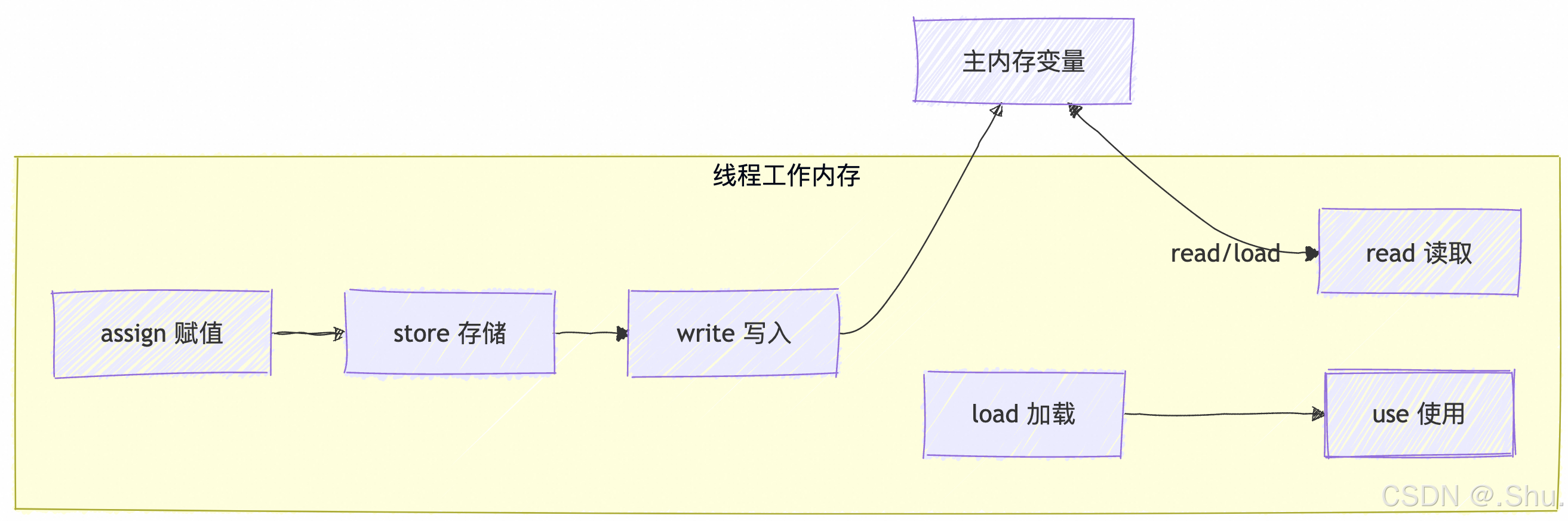
JMM 语义如何映射到内存屏障
JVM 在编译 JIT(Just-In-Time)生成的机器码时,会根据特定平台的内存模型(如 x86-TSO, ARMv8)在相应的位置插入内存屏障,以实现 JMM 要求的语义。
volatile写操作: 在写之后插入一个 StoreStore 屏障(防止上面的普通写与volatile写重排序)和一个 StoreLoad 屏障(防止volatile写与下面可能有的volatile读/写重排序,并保证写结果立即对其他线程可见)。volatile读操作: 在读之前插入一个 LoadLoad 屏障(防止volatile读与上面的普通读重排序)和一个 LoadStore 屏障(防止volatile读与下面的普通写重排序)。synchronized锁的获取(monitorenter): 相当于一个 LoadLoad + LoadStore 屏障(具有acquire语义)。synchronized锁的释放(monitorexit): 相当于一个 StoreStore + StoreLoad 屏障(具有release语义)。
四、源码窥探:HotSpot VM 的实现
让我们深入到 OpenJDK HotSpot VM 的源码中,看看这些抽象概念是如何落地的。
1. 内存屏障的抽象层:OrderAccess
HotSpot 在 src/hotspot/share/runtime/orderAccess.hpp 中定义了一个平台无关的屏障接口。
// 示例代码 (orderAccess.hpp)
class OrderAccess : public AllStatic {
public:
// 插入一个 LoadLoad 屏障
static void loadload();
// 插入一个 StoreStore 屏障
static void storestore();
// 插入一个 LoadStore 屏障
static void loadstore();
// 插入一个 StoreLoad 屏障 (全能型,开销最大)
static void storeload();
// 具有 acquire 语义的屏障,防止后续读写重排到该屏障之前
static void acquire();
// 具有 release 语义的屏障,防止前面读写重排到该屏障之后
static void release();
// 全能屏障 fence()
static void fence();
...
};
其具体实现位于平台相关的子目录中,例如对于 Linux x86_64:src/hotspot/os_cpu/linux_x86/orderAccess_linux_x86.hpp。
// 示例实现 (orderAccess_linux_x86.hpp)
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); } // x86 上 StoreLoad 需要强屏障
inline void OrderAccess::acquire() {
compiler_barrier();
}
inline void OrderAccess::release() {
compiler_barrier();
}
inline void OrderAccess::fence() {
// 使用 lock 前缀的指令实现一个内存栅栏,如 `lock; addl $0, 0(%%rsp)`
// 这个操作将栈指针寄存器的值加0,是一个空操作,但 lock 前缀起到了屏障作用
if (os::is_MP()) { // 如果是多处理器才需要屏障
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
}
}
// compiler_barrier() 防止编译器重排序,如: `__asm__ volatile ("" : : : "memory");`
关键点: x86 架构拥有较强的内存模型(TSO),很多屏障是隐式的,不需要实际的内存屏障指令,只需要编译器屏障(compiler_barrier())阻止编译器重排即可。但 StoreLoad 屏障在 x86 上仍需一条带 lock 前缀的指令。
2. volatile 关键字的具体实现
在解释器模式中,HotSpot 为每个字节码指令生成了模板(一段汇编代码)。当执行到访问 volatile 字段的 putfield 或 getfield 字节码时,会调用插入了内存屏障的模板。
相关源码在 src/hotspot/cpu/x86/templateTable_x86.cpp:
// volatile 写操作 (putfield 或 putstatic)
void TemplateTable::putfield_or_static(int byte_no, bool is_static, bool is_volatile) {
...
if (is_volatile) {
// 对于 volatile 写,在写操作之后,需要 release 屏障(包含 StoreStore 和 LoadStore?)
// 在 x86 上,通常只需要在写之后加一个 StoreLoad 屏障即可满足 JMM 对 volatile 写的要求
// 这里的 `release()` 在 x86 上是编译器屏障,而写操作本身在 x86 上有 release 语义
OrderAccess::release();
}
// 执行实际的存储指令 (如 mov)
__ store(....);
if (is_volatile) {
// 在写操作完成后,插入一个 StoreLoad 屏障。
// 确保写结果对其他处理器立即可见,并防止与后续操作重排序。
OrderAccess::storeload();
}
...
}
// volatile 读操作 (getfield 或 getstatic)
void TemplateTable::getfield_or_static(int byte_no, bool is_static, bool is_volatile) {
if (is_volatile) {
// 对于 volatile 读,在读操作之前,需要 acquire 屏障(包含 LoadLoad 和 LoadStore)
// 在 x86 上,volatile 读本身具有 acquire 语义,这里主要是编译器屏障
OrderAccess::acquire();
}
// 执行实际的加载指令 (如 mov)
__ load(....);
if (is_volatile) {
// 在某些平台上,可能需要额外的屏障。
// 在 x86 上,由于内存模型强大,读操作本身已经具有 acquire 语义,不需要额外机器指令屏障。
// 但依然需要编译器屏障防止编译期重排。
OrderAccess::loadload(); // 在 x86 上是空操作(编译器屏障)
}
}
在 JIT 编译(如 C2 编译器)中,过程类似。编译器在生成中间表示(IR)时,会识别 volatile 访问,并将其转换为特定的内存节点(如 LoadVolatile 和 StoreVolatile)。在最终生成机器码的阶段,这些节点会被 lowering( lowering 是编译器中的一个步骤,将高级的、与机器无关的中间表示(IR)转换为低级的、与机器相关的指令或操作。)为相应的加载/存储指令,并在周围插入正确的内存屏障。
JMM对关键字的内存语义
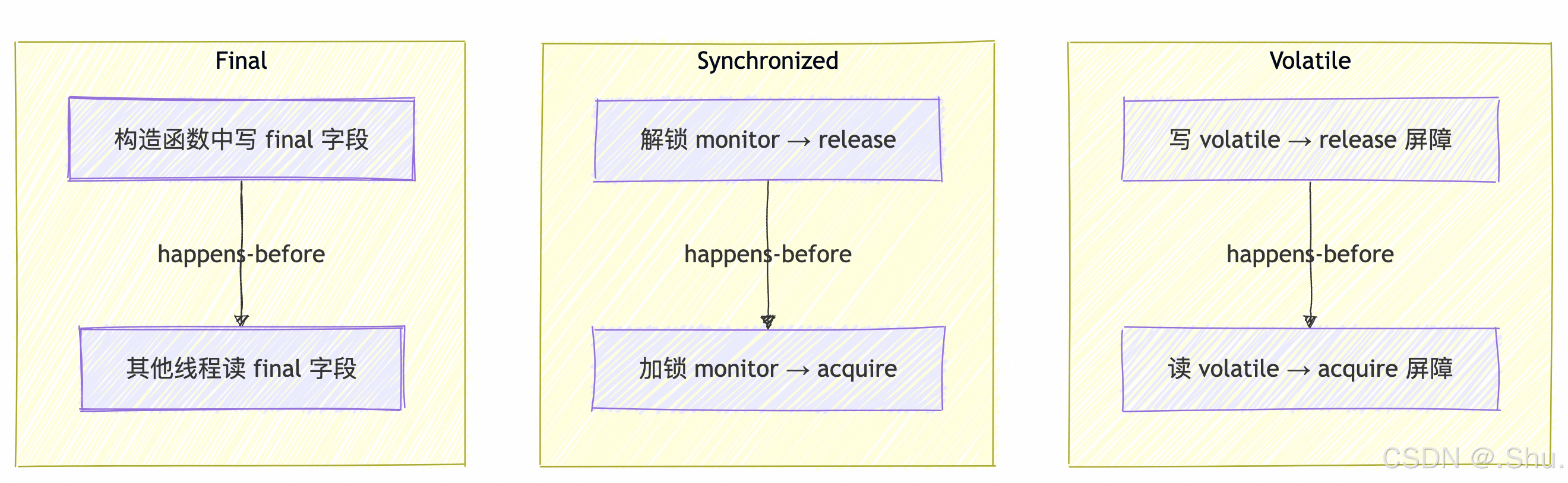
相关源码路径:src/hotspot/share/opto/memnode.hpp (定义 LoadVolatileNode, StoreVolatileNode)。
五、JMM 的正确用法与最佳实践
理解了原理,关键在于正确使用。
-
正确同步(Correct Synchronization):
synchronized:保证原子性、可见性和有序性。是万能的但可能较重的解决方案。volatile:仅保证可见性和有序性(防止重排序),不保证原子性。适用于状态标志、一次性发布等场景。java.util.concurrent.locks.Lock:提供更灵活、更复杂的锁操作。
-
原子变量(Atomic Variables):
java.util.concurrent.atomic包下的类(如AtomicInteger)。- 利用 CAS(Compare-And-Swap)指令实现,提供非阻塞的原子操作。
- 底层同样依赖
volatile语义和 CPU 的原子指令。
-
安全构造(Safe Construction) - 不可变对象(Immutable Objects):
- 所有字段声明为
final。 final字段在 JMM 中有特殊的语义:通过正确构造的对象,任何线程都能看到该对象的final字段被正确初始化后的值,无需同步。这是最有效、最简单的线程安全保证。
- 所有字段声明为
-
线程安全集合(Thread-Safe Collections):
- 优先使用
java.util.concurrent包下的并发集合(如ConcurrentHashMap,CopyOnWriteArrayList),而非自行使用锁同步包装的集合。
- 优先使用
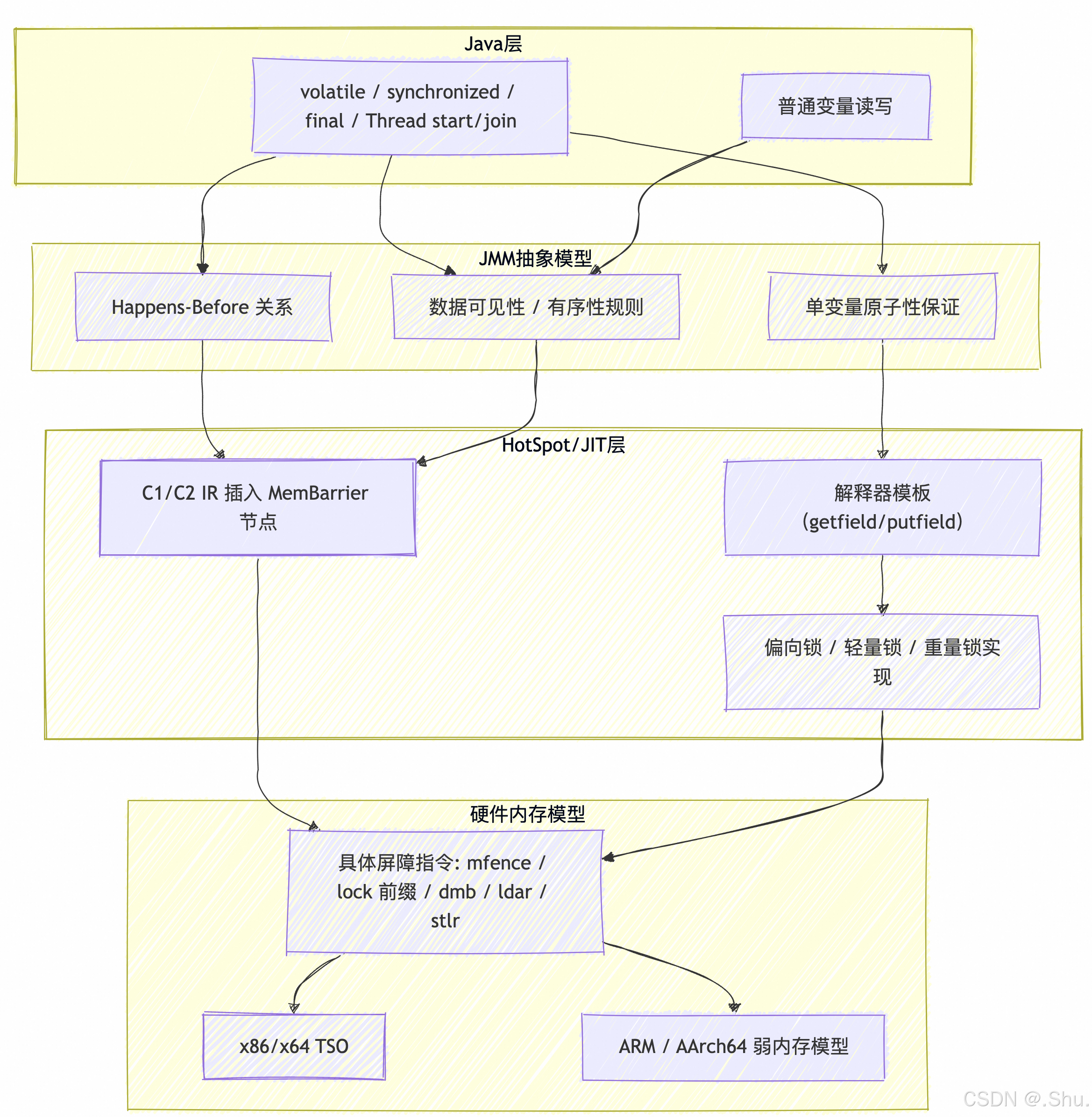
六、HotSpot 层面的实现(高层次)——如何把 JMM 语义落地到机器
注:下面为高层次、常见实现策略。具体细节(函数名、IR 节点)随 JDK/HotSpot 版本与架构会有差异,阅读源码时以你目标 JDK 为准。
- 字节码 / 字段标志层
- 源代码
volatile→ class 文件里该字段带ACC_VOLATILE标志。 - 字节码本身仍然是
getfield/putfield或getstatic/putstatic,JVM 在运行时/编译期在这些访问点插入合适的内存屏障(memory fences / membar)以满足 JMM 语义。
- JIT/Interpreter & IR
- 在 HotSpot 的解释器和 JIT(C1/C2)里,针对 volatile、monitor、thread start/join 等动作,编译器会在 IR 层插入 mem-barrier 节点(例如 acquire/release barrier 节点),且这些屏障在后端被映射为目标架构的具体指令序列或原子操作。
- 优化时(比如常见的代码移动、表达式合并等),编译器必须尊重 HB 关系:不能把某个操作重新排序越过需要保持顺序的 barrier。
- Monitor(synchronized)在 HotSpot 的实现(概览)
- Java 对象头包含 mark word,用于存放锁状态、哈希码等。
- 锁演化路径(加速路径常见):
- 无锁状态:mark word 存储对象哈希/年龄等。
- 偏向锁(biased locking):针对单线程频繁获取的锁,记录占有线程 id,避免 CAS 成本(JDK 早期引入,但版本与开关可能变动)。
- 轻量级(thin)锁:使用自旋 + CAS 在对象头与栈帧之间建立关联。
- 膨胀/重量级锁(inflated/monitor):激烈竞争时,将锁膨胀为操作系统 mutex/monitor 结构,涉及操作系统阻塞。
这些实现是为了降低 uncontended 情况下的锁开销(fast-path),同时在竞争高时退化到可靠的阻塞机制。
- 内存屏障在硬件层的映射(示例,架构相关)
-
x86/x64(TSO)
- x86 的内存模型较强,不允许 Load→Load、Load→Store、Store→Store 重排,但允许 Store→Load(即写后读可被重排)。
- 因为 Store→Load 是唯一需要阻止的重排,JVM 往往在需要时插入一个 StoreLoad 屏障。在 x86 上可以用
mfence或某些lock前缀指令(如lock addl $0,0(%%rsp))来实现。 - Volatile 写通常需要确保 StoreLoad 屏障效果;volatile 读通常可通过普通 load 实现(或带 acquire 语义的 load,视实现)。
-
ARM / AArch64(弱内存模型)
- 更弱的模型允许更多重排;JVM 会插入
dmb/ldar/stlr等带 acquire/release 语义的指令来实现 JMM 语义:ldar(load-acquire),stlr(store-release),或显式dmb ish以形成全屏障。
- 更弱的模型允许更多重排;JVM 会插入
总之:具体用哪条汇编指令取决于目标架构与 JIT 实现;常见做法是用 acquire/release 型原语 + 在必要处加强型 barrier 以满足 StoreLoad 等强排序需求。
- Unsafe / VarHandle / Fences
JDK 9+ 引入了更细粒度的内存访问与 fence API:VarHandle(getAcquire/setRelease/getOpaque/setOpaque/getVolatile/setVolatile)和 Unsafe 的 storeFence/loadFence/fullFence 等。
这些提供了比 volatile 更灵活的可见性/排序控制,可以用于高性能的并发结构实现(但同时更难以正确使用)。
七、Mermaid 图谱合集
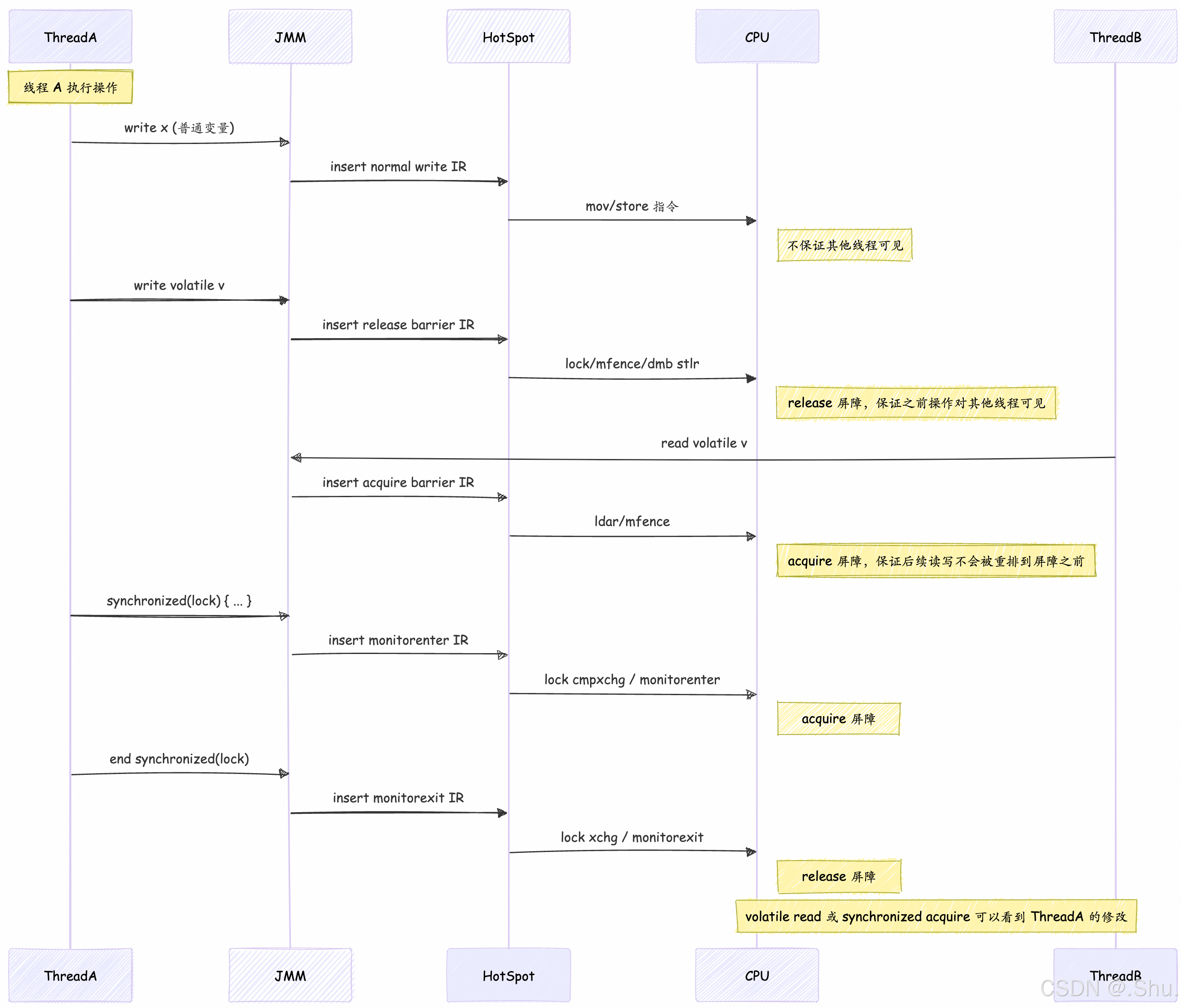
1、线程操作到 CPU 指令的完整时序
结合上述内容,我们可以得到以下时序图
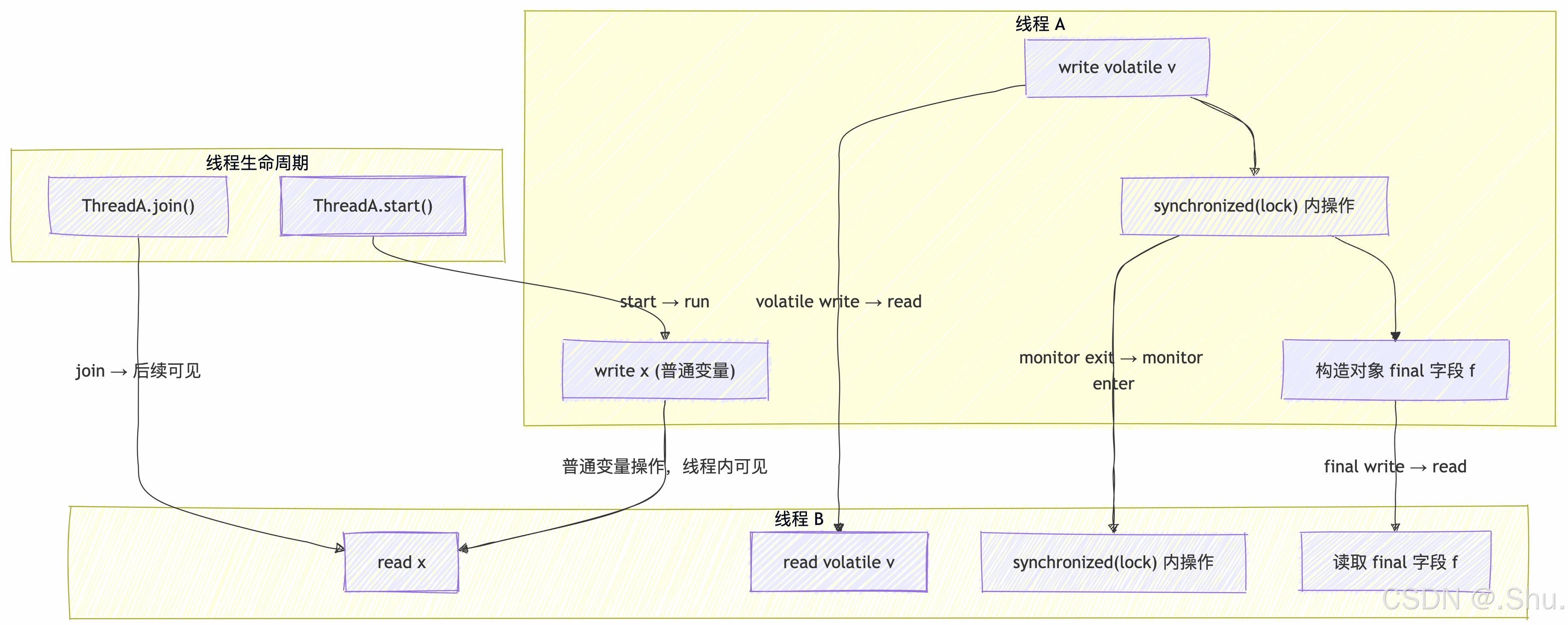
2、JMM 可见性链路
综合上述关键字的相关知识内容,汇总输出可见性链路图谱
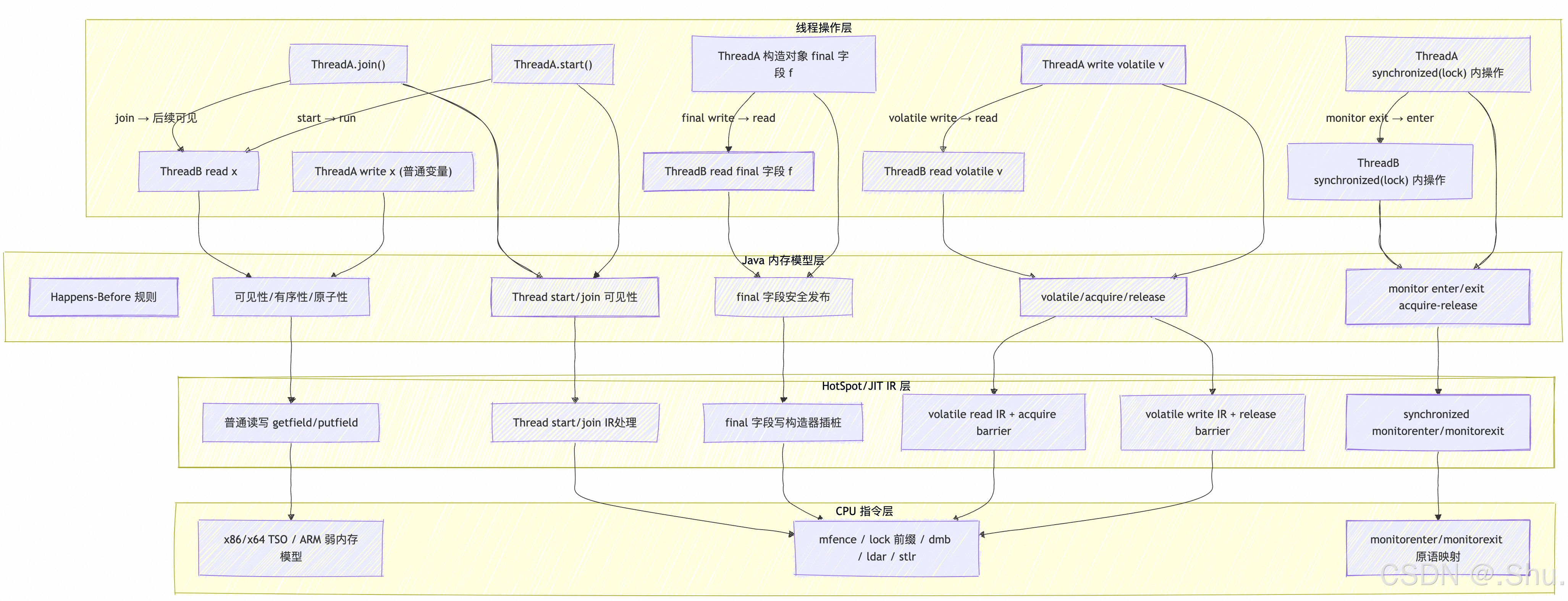
3、JMM 终极全景图!!!
总结
Java 内存模型(JMM)是一个规范,它定义了多线程环境下共享内存访问的行为。它通过抽象的主内存与工作内存概念,以及核心的 happens-before 规则,为开发者提供了一致性的保证。
其底层实现依赖于内存屏障。JVM(如 HotSpot)通过在解释执行和 JIT 编译时,在特定位置(如 volatile 访问、锁进入/退出)插入与平台相关的内存屏障指令(通过 OrderAccess 模块抽象),来强制实现 JMM 要求的可见性和有序性语义。
作为开发者,理解 JMM 有助于:
- 编写正确、高效的多线程程序。
- 理解
synchronized,volatile,final等关键字的内在原理。 - 理解
java.util.concurrent包中高级并发工具的工作机制。 - 对棘手的并发 Bug(如可见性、有序性问题)进行有效的诊断和调试。
JMM 是 Java 并发编程的基石,它将复杂的硬件差异抽象成一套统一的模型,让开发者能在更高的层面上专注于业务逻辑,而无需过多纠结于底层多变的硬件架构。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120396

 浙公网安备 33010602011771号
浙公网安备 33010602011771号