【流式处理系统】流处理系统交付语义详解:本质与实现原理
一、三种核心交付语义深度解析
1. At-Most-Once(至多一次)
本质:尽力交付,不保证数据一定被处理
实现原理:
- 数据源读取后立即标记为已消费(无论处理是否成功)
- 无重试机制,无状态持久化
- 类似"发后即忘"模式
典型实现:
// 伪代码示例:At-Most-Once实现
kafkaConsumer.setAutoCommit(true); // 自动提交offset
kafkaConsumer.setAutoOffsetReset("latest"); // 从最新位置开始
// 处理逻辑:无状态保存,无重试
processMessage(message); // 如果此处失败,消息永久丢失
适用场景:实时监控、传感器数据采集(允许少量数据丢失)
2. At-Least-Once(至少一次)
本质:保证数据不丢失,但可能重复处理
实现原理:
- 只有确认处理成功后才会提交消费位移
- 失败时重试机制确保数据最终被处理
- 可能导致重复处理(同一数据被处理多次)
典型实现:
// 伪代码示例:At-Least-Once实现
try {
processMessage(message); // 处理消息
storeOffset(message.offset); // 处理成功后才保存offset
} catch (Exception e) {
// 处理失败,不提交offset,下次会重新消费
seekToOffset(message.offset); // 重置到失败位置
}
挑战:需要处理幂等性问题(同样数据可能到来多次)
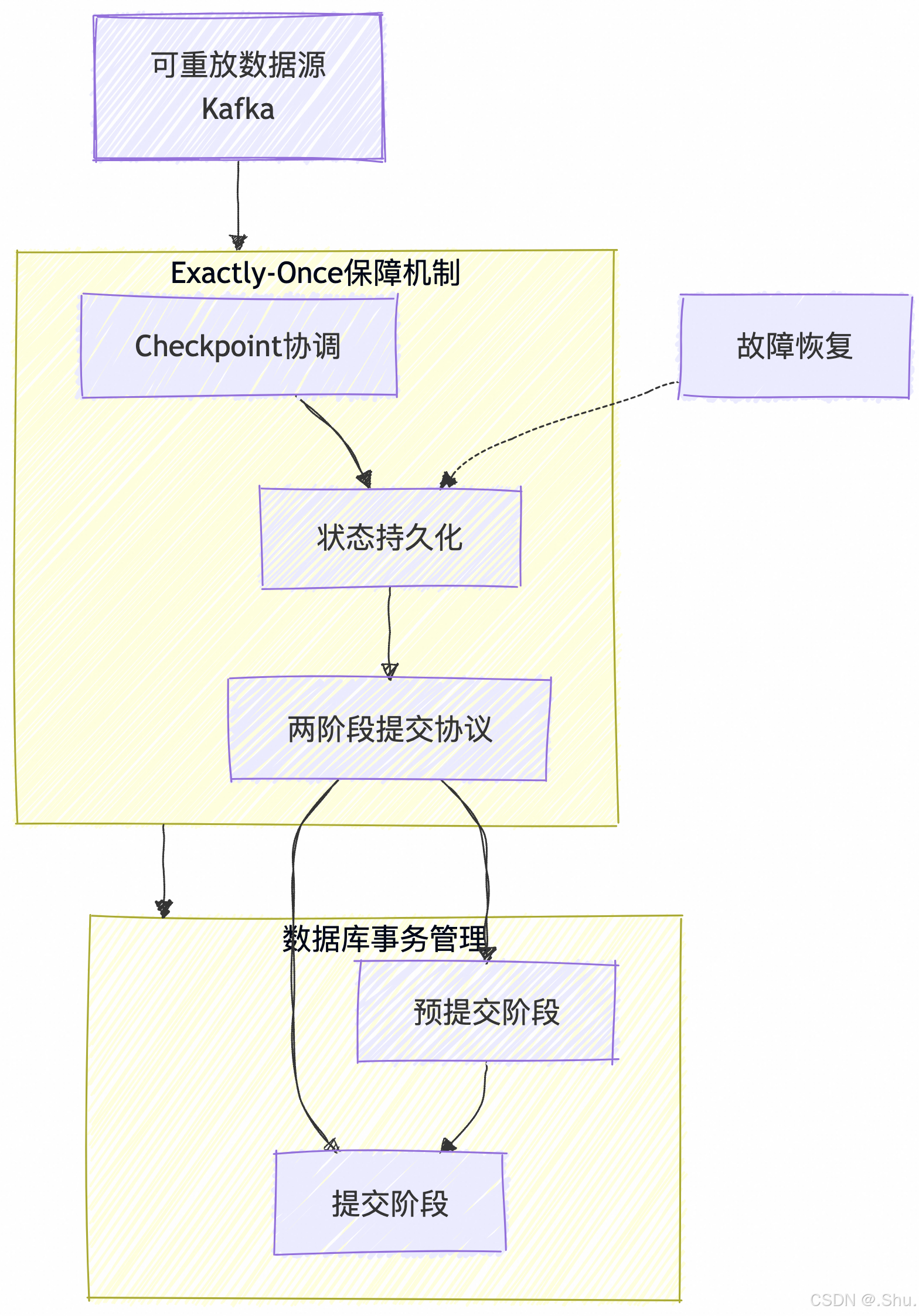
3. Exactly-Once(精确一次)
本质:从效果上保证每条数据只被处理一次
实现原理:
- 分布式快照:定期保存一致性的状态快照
- 事务性协调:使用两阶段提交协议
- 幂等性设计:确保重复操作不影响最终结果
二、Exactly-Once 的实现机制深度分析
1. 基于检查点(Checkpoint)的容错机制
Chandy-Lamport 算法核心思想:
- 检查点触发:JobManager 向所有算子发送检查点屏障(Barrier)
- 状态保存:算子接收到屏障后异步持久化当前状态
- 屏障对齐:确保所有算子达到一致性状态
- 确认完成:所有算子完成状态保存后确认检查点
// Flink检查点配置示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 启用检查点,每5秒一次,Exactly-Once模式
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 高级配置
env.getCheckpointConfig()
.setMinPauseBetweenCheckpoints(500) // 检查点间最小间隔
.setCheckpointTimeout(60000) // 检查点超时时间
.setMaxConcurrentCheckpoints(1) // 最大并发检查点数
.setTolerableCheckpointFailureNumber(3); // 可容忍的失败次数
2. 两阶段提交协议(2PC)实现
阶段一:预提交(Pre-commit)
- 所有算子完成当前批次处理
- 外部系统准备提交(但不真正提交)
- 状态保存到持久化存储
阶段二:提交(Commit)
- 所有算子确认状态保存成功
- 外部系统执行实际提交操作
- 如果任何环节失败,整体回滚
// 两阶段提交Sink示例(Kafka)
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("localhost:9092")
.setRecordSerializer(new SimpleStringSerializer())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("flink-")
.build();
// 使用事务性Sink
stream.sinkTo(sink);
3. 端到端Exactly-Once的实现要求
三大必要条件:
-
可重置的数据源:支持回退到特定位置重新消费
- Kafka:支持offset重置
- 文件系统:支持按行位置重置
-
幂等性状态存储:重复操作不影响最终状态
-- 幂等性SQL示例 INSERT INTO user_balances (user_id, balance) VALUES (?, ?) ON DUPLICATE KEY UPDATE balance = VALUES(balance); -
事务性输出:支持原子提交和回滚
- Kafka:事务性Producer
- 数据库:支持事务操作
三、不同流处理框架的实现对比
1. Apache Flink
实现特点:
- 基于分布式快照的轻量级容错
- 支持真正的流处理(非微批)
- 完善的端到端Exactly-Once支持
优势:
- 低延迟高吞吐
- 状态管理完善
- 生态完整
2. Apache Spark Streaming
实现特点:
- 基于微批处理(Micro-batching)
- 通过RDD的容错机制实现
- 每个批次内部实现Exactly-Once
局限性:
- 延迟相对较高
- 状态管理不如Flink灵活
3. Kafka Streams
实现特点:
- 基于Kafka本身的事务机制
- 使用变更日志主题(Changelog Topics)保存状态
- 与Kafka生态深度集成
优势:
- 无需额外基础设施
- 与Kafka无缝集成
四、性能与可靠性的权衡
1. 检查点间隔的影响
// 不同场景下的检查点配置策略
// 低延迟场景:频繁检查点
env.enableCheckpointing(1000); // 1秒一次
// 高吞吐场景:减少检查点频率
env.enableCheckpointing(10000); // 10秒一次
// 大状态场景:使用增量检查点
env.setStateBackend(new RocksDBStateBackend("hdfs://checkpoints/", true));
2. 资源开销分析
- 内存开销:状态越大,内存需求越高
- IO开销:检查点持久化带来磁盘/网络IO
- 计算开销:屏障对齐和状态序列化消耗CPU
3. 恢复时间优化策略
- 增量检查点:只保存变化的状态部分
- 本地恢复:优先从本地磁盘恢复状态
- 并行恢复:多个任务同时恢复
五、实际应用建议
1. 语义选择指南
| 场景 | 推荐语义 | 理由 |
|---|---|---|
| 实时监控 | At-Most-Once | 允许少量数据丢失,追求最低延迟 |
| 业务数据处理 | At-Least-Once | 保证数据不丢失,配合幂等性处理 |
| 金融交易 | Exactly-Once | 要求绝对的数据准确性 |
2. 配置最佳实践
# flink-conf.yaml 生产环境配置
state.backend: rocksdb
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints
state.savepoints.dir: hdfs://namenode:8020/flink/savepoints
state.backend.incremental: true
jobmanager.execution.failover-strategy: region
3. 监控与调优
- 监控检查点持续时间与间隔比例
- 关注背压(backpressure)指标
- 定期测试故障恢复时间
六、总结
流处理系统的交付语义本质上是数据可靠性与系统性能之间的权衡:
- At-Most-Once:性能最优,可靠性最低
- At-Least-Once:平衡点,需要处理幂等性
- Exactly-Once:可靠性最高,性能开销最大
现代流处理框架通过分布式快照、事务机制和幂等性设计实现了高效的Exactly-Once语义,但需要根据具体业务需求和技术约束做出合适的选择。
正确理解这些语义的本质和实现原理,对于设计和运维可靠的流处理系统至关重要。在实际应用中,往往需要结合业务需求、基础设施条件和性能要求来做出最合适的选择。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120383

 浙公网安备 33010602011771号
浙公网安备 33010602011771号