Redis 底层数据结构解析(六):特殊类型的巧妙实现 - Bitmap、Geo 和 HyperLogLog
1. 引言:Redis 特殊类型的设计哲学
Redis 不仅提供了基础的字符串、列表、哈希、集合和有序集合类型,还包含三种特殊的数据类型:Bitmap(位图)、Geo(地理空间)和 HyperLogLog(基数统计)。这些特殊类型并非通过全新的底层数据结构实现,而是基于已有的数据结构,通过精巧的算法和编码方式扩展出新的能力。
这种设计体现了 Redis 的重要哲学:在保持核心简单性的同时,通过组合和扩展提供丰富的功能。本文将深入剖析这三种特殊类型的实现原理,揭示它们如何基于 String、ZSet 等基础结构实现高级功能,以及它们在不同场景下的性能特征和最佳实践。
2. Bitmap:位操作的极致优化
2.1 Bitmap 的本质与实现
Bitmap 并不是一种独立的数据结构,而是基于 String 类型的位操作接口。Redis 将 String 值视为一个连续的位数组,每个字节的 8 个位都可以单独操作。
内存布局:
String值: "hello" -> [0x68, 0x65, 0x6C, 0x6C, 0x6F]
位表示:
h: 01101000 e: 01100101 l: 01101100 l: 01101100 o: 01101111
BITSET 命令实现(bitops.c):
void setbitCommand(client *c) {
robj *o;
uint64_t bitoffset;
ssize_t byte, bit;
int byteval, bitval;
long on;
// 解析偏移量和值
if (getBitOffsetFromArgument(c, c->argv[2], &bitoffset) != C_OK) return;
if (getLongFromObjectOrReply(c, c->argv[3], &on, NULL) != C_OK) return;
// 限制偏移量大小
if (bitoffset >> 3 >= PROTO_MAX_STRING_LENGTH) {
addReplyError(c, "BIT offset is too large");
return;
}
// 查找或创建字符串对象
if ((o = lookupStringForBitCommand(c, bitoffset)) == NULL) return;
// 计算字节和位偏移
byte = bitoffset >> 3;
bit = 7 - (bitoffset & 0x7);
// 获取当前字节值
byteval = ((uint8_t*)o->ptr)[byte];
bitval = (byteval >> bit) & 1;
// 更新位值
byteval &= ~(1 << bit);
byteval |= ((on & 0x1) << bit);
((uint8_t*)o->ptr)[byte] = byteval;
// 通知变更
signalModifiedKey(c, c->db, c->argv[1]);
server.dirty++;
addReply(c, bitval ? shared.cone : shared.czero);
}
2.2 位操作算法优化
Redis 对大规模位操作进行了算法优化,特别是 BITCOUNT 和 BITPOS 命令:
BITCOUNT 的实现:
long long redisPopcount(void *s, long count) {
long long bits = 0;
unsigned char *p = s;
uint32_t *p4;
// 使用SWAR算法进行批量位计数
static const unsigned char bitsinbyte[256] = {0,1,1,2,...};
// 4字节对齐处理
while((unsigned long)p & 3 && count) {
bits += bitsinbyte[*p++];
count--;
}
// 以4字节为单位处理
p4 = (uint32_t*)p;
while(count >= 4) {
uint32_t v = *p4++;
v = v - ((v >> 1) & 0x55555555);
v = (v & 0x33333333) + ((v >> 2) & 0x33333333);
bits += (((v + (v >> 4)) & 0xF0F0F0F) * 0x1010101) >> 24;
count -= 4;
}
// 处理剩余字节
p = (unsigned char*)p4;
while(count--) {
bits += bitsinbyte[*p++];
}
return bits;
}
2.3 Bitmap 的应用场景与性能
应用场景:
- 用户活跃度统计
- 布隆过滤器实现
- 特性开关管理
- 大规模布尔值存储
性能特点:
- 空间效率:每个用户仅需1位,100万用户只需125KB
- 时间效率:BITCOUNT O(n),但使用SWAR算法优化
- 内存分配:自动扩展,稀疏位图节省内存
3. Geo:地理空间的智能编码
3.1 Geo 的底层实现
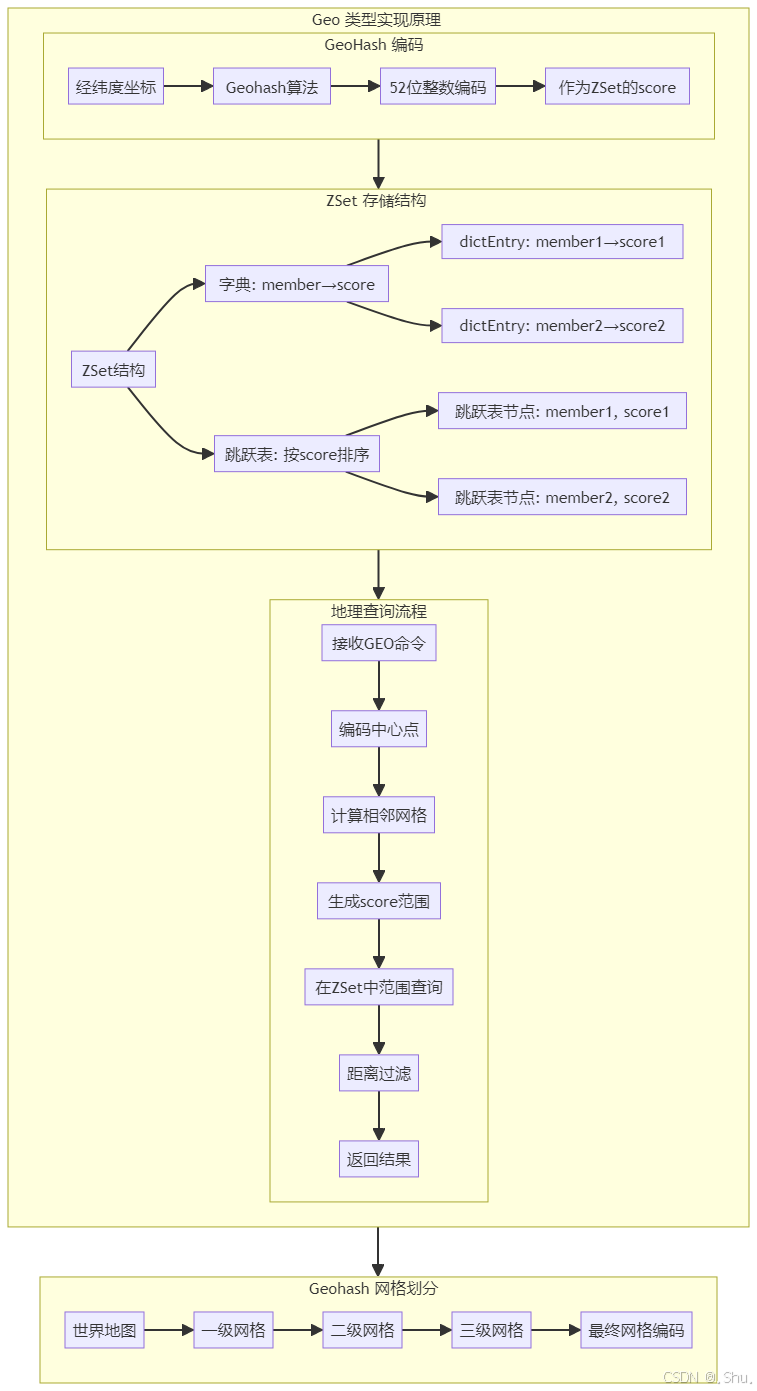
Geo 类型基于 ZSet(有序集合)实现,使用 Geohash 算法将二维经纬度编码为一维整数作为 score,member 存储地点名称。
Geohash 编码原理:
Geohash 将地理空间递归划分为网格,每个网格用二进制编码表示。经纬度交替编码,最终转换为 base32 字符串。
GEOADD 命令实现(geo.c):
int geoAddCommand(client *c) {
// 参数验证和解析
if ((c->argc - 2) % 3 != 0) {
addReplyError(c, "syntax error");
return C_OK;
}
int elements = (c->argc - 2) / 3;
int argc = 2 + elements * 2;
robj **argv = zcalloc(argc * sizeof(robj*));
// 创建参数数组
argv[0] = c->argv[1];
argv[1] = c->argv[2];
for (int i = 0; i < elements; i++) {
double longitude, latitude;
// 解析经纬度
if (getDoubleFromObjectOrReply(c, c->argv[3 + i*3], &longitude, NULL) != C_OK ||
getDoubleFromObjectOrReply(c, c->argv[4 + i*3], &latitude, NULL) != C_OK) {
zfree(argv);
return C_OK;
}
// 将经纬度转换为Geohash分数
GeoHashBits hash;
geohashEncodeWGS84(longitude, latitude, GEO_STEP_MAX, &hash);
// 创建ZADD参数
argv[2 + i*2] = createObject(OBJ_STRING, sdsnew(c->argv[2 + i*3]->ptr));
argv[3 + i*2] = createStringObjectFromLongLong(hash.bits);
}
// 调用ZADD命令
replaceRawObjectWithExpire(c->argv[0], sdsnew("zadd"));
zaddCommand(c);
zfree(argv);
return C_OK;
}
3.2 距离计算与范围查询
GEODIST 实现:
double geoDistance(double lon1, double lat1, double lon2, double lat2) {
// 使用Haversine公式计算球面距离
double delta_lon = degToRad(lon2 - lon1);
double delta_lat = degToRad(lat2 - lat1);
double a = sin(delta_lat/2) * sin(delta_lat/2) +
cos(degToRad(lat1)) * cos(degToRad(lat2)) *
sin(delta_lon/2) * sin(delta_lon/2);
double c = 2 * atan2(sqrt(a), sqrt(1-a));
return EARTH_RADIUS * c;
}
GEORADIUS 实现:
GEORADIUS 通过以下步骤实现:
- 计算中心点的 Geohash
- 确定查询范围的 Geohash 前缀
- 在 ZSet 中查找匹配前缀的候选点
- 精确计算距离并过滤结果
3.3 Geo 的性能优化
搜索优化:
void membersOfAllNeighbors(GeoHashRadius n, GeoHashFix52Bits bits, geoArray *ga) {
// 搜索所有相邻网格
GeoHashBits neighbors[9];
neighbors[0] = n.hash;
neighbors[1] = n.neighbors.north;
neighbors[2] = n.neighbors.south;
// ... 其他方向
for (int i = 0; i < sizeof(neighbors) / sizeof(*neighbors); i++) {
if (HASHISZERO(neighbors[i]))
continue;
// 在ZSet中查找该网格内的所有点
GeoHashFix52Bits min, max;
scoresOfGeoHashBox(neighbors[i], &min, &max);
zrangespec range = { .min = min, .max = max, .minex = 0, .maxex = 0 };
geoPointsInRange(ga, &range);
}
}
4. HyperLogLog:基数估计的概率算法
4.1 HyperLogLog 算法原理
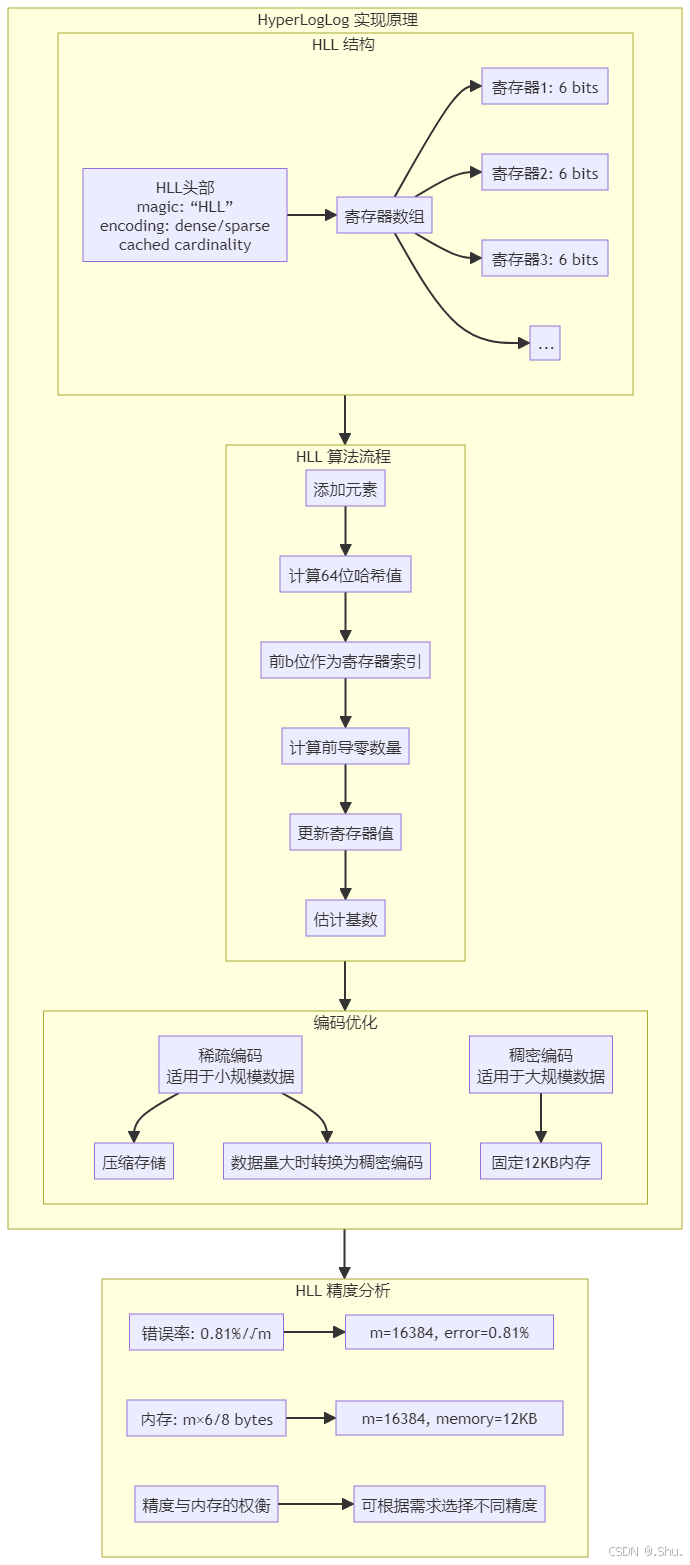
HyperLogLog 使用概率算法估计大规模数据集的基数(唯一元素数量),核心思想是:通过数据的哈希值中前导零的数量来估计基数。
算法步骤:
- 哈希函数将元素映射到64位整数
- 使用前 b 位确定寄存器索引(2^b 个寄存器)
- 使用剩余位计算前导零数量
- 取所有寄存器的调和平均数作为基数估计
4.2 Redis HLL 实现
HLL 结构定义:
struct hllhdr {
char magic[4]; // 魔数"HLL"
uint8_t encoding; // 编码方式:HLL_DENSE或HLL_SPARSE
uint8_t notused[3]; // 保留字段
uint8_t card[8]; // 缓存的计算结果
uint8_t registers[]; // 柔性数组,存储寄存器
};
PFADD 实现:
int hllAdd(robj *o, unsigned char *ele, size_t elesize) {
struct hllhdr *hdr = o->ptr;
long index;
uint8_t count;
// 计算哈希值
uint64_t hash = MurmurHash64A(ele, elesize, HLL_HASH_SEED);
// 获取寄存器索引和前导零数量
index = hash & HLL_REGISTER_MAX;
hash >>= HLL_BITS;
count = hllCountLeadingZeros(hash) + 1;
// 更新寄存器
if (count > hdr->registers[index]) {
hdr->registers[index] = count;
return 1; // 基数可能发生变化
}
return 0;
}
4.3 精度与内存优化
精度分析:
- 标准错误率:约 0.81%/√m(m 为寄存器数量)
- Redis 使用 16384 个寄存器(2^14),错误率约 0.81%
- 内存使用:仅 12KB(16384 × 6bit / 8)
稀疏编码优化:
对于小规模数据集,HLL 使用稀疏编码节省内存:
#define HLL_SPARSE_MAX 3000 // 稀疏编码的最大寄存器值
int hllSparseAdd(robj *o, unsigned char *ele, size_t elesize) {
// 小规模数据使用稀疏表示
if (hllCount(o) < HLL_SPARSE_MAX) {
// 使用压缩格式存储非零寄存器
// ...
} else {
// 转换为稠密表示
hllSparseToDense(o);
}
}
5. 性能对比与实战应用
5.1 性能特征总结
| 数据类型 | 内存效率 | 时间效率 | 精度 | 适用场景 |
|---|---|---|---|---|
| Bitmap | 极高 | 高 | 精确 | 布尔统计、特征标志 |
| Geo | 中等 | 中等 | 精确 | 地理位置、附近搜索 |
| HyperLogLog | 极高 | 高 | 概率估计 | 大规模基数统计 |
5.2 实战应用示例
Bitmap 实现用户活跃度统计:
class UserActivityTracker:
def __init__(self, redis_client):
self.r = redis_client
def mark_user_active(self, user_id, date=None):
if date is None:
date = datetime.now().strftime("%Y%m%d")
offset = user_id % 1000000 # 用户ID偏移量
self.r.setbit(f"activity:{date}", offset, 1)
def get_daily_active_users(self, date):
return self.r.bitcount(f"activity:{date}")
def get_user_activity(self, user_id, start_date, end_date):
# 计算连续活跃天数
pipe = self.r.pipeline()
for date in self._date_range(start_date, end_date):
pipe.getbit(f"activity:{date}", user_id % 1000000)
results = pipe.execute()
return sum(results)
Geo 实现附近地点搜索:
class LocationService:
def __init__(self, redis_client):
self.r = redis_client
def add_location(self, name, longitude, latitude):
self.r.geoadd("locations", longitude, latitude, name)
def find_nearby(self, longitude, latitude, radius_km, unit="km"):
return self.r.georadius("locations", longitude, latitude, radius_km, unit)
def find_within_bounds(self, min_lon, min_lat, max_lon, max_lat):
# 使用Geohash范围查询
return self.r.geosearch(
"locations",
longitude=min_lon,
latitude=min_lat,
width=max_lon-min_lon,
height=max_lat-min_lat
)
HyperLogLog 实现UV统计:
class UVStatistics:
def __init__(self, redis_client):
self.r = redis_client
def add_user_access(self, page_id, user_id, date=None):
if date is None:
date = datetime.now().strftime("%Y%m%d")
key = f"uv:{page_id}:{date}"
self.r.pfadd(key, user_id)
def get_daily_uv(self, page_id, date):
return self.r.pfcount(f"uv:{page_id}:{date}")
def get_weekly_uv(self, page_id, week_start):
# 合并一周的数据
keys = [f"uv:{page_id}:{date}" for date in self._week_dates(week_start)]
return self.r.pfcount(*keys)
def merge_monthly_uv(self, page_id, year_month):
# 合并月数据
keys = [f"uv:{page_id}:{date}" for date in self._month_dates(year_month)]
dest_key = f"uv:{page_id}:{year_month}"
self.r.pfmerge(dest_key, *keys)
return self.r.pfcount(dest_key)
6. 高级特性与最佳实践
6.1 Bitmap 的分片策略
对于超大规模位图,可以采用分片策略:
class ShardedBitmap:
def __init__(self, base_key, num_shards=1000):
self.r = redis.Redis()
self.base_key = base_key
self.num_shards = num_shards
def setbit(self, offset, value):
shard_id = offset % self.num_shards
shard_offset = offset // self.num_shards
key = f"{self.base_key}:shard:{shard_id}"
return self.r.setbit(key, shard_offset, value)
def bitcount(self, start=0, end=-1):
total = 0
pipe = self.r.pipeline()
for i in range(self.num_shards):
key = f"{self.base_key}:shard:{i}"
if start == 0 and end == -1:
pipe.bitcount(key)
else:
# 计算分片内的范围
shard_start = max(0, start - i * (2**32))
shard_end = min(2**32, end - i * (2**32))
if shard_start <= shard_end:
pipe.bitcount(key, shard_start, shard_end)
else:
pipe.bitcount(key)
results = pipe.execute()
return sum(results)
6.2 Geo 数据的过期策略
地理数据通常不需要永久存储,可以实现自动清理:
class GeoDataManager:
def __init__(self, redis_client, max_age_days=30):
self.r = redis_client
self.max_age_days = max_age_days
def add_location_with_ttl(self, name, lon, lat, ttl_hours=24):
self.r.geoadd("locations", lon, lat, name)
# 使用ZSet的score存储过期时间
expire_time = time.time() + ttl_hours * 3600
self.r.zadd("locations:expiry", {name: expire_time})
def cleanup_expired_locations(self):
# 定期清理过期数据
now = time.time()
expired = self.r.zrangebyscore("locations:expiry", 0, now)
if expired:
pipe = self.r.pipeline()
pipe.zrem("locations", *expired)
pipe.zrem("locations:expiry", *expired)
pipe.execute()
6.3 HyperLogLog 的精度控制
根据业务需求调整 HLL 精度:
class PrecisionControlledHLL:
def __init__(self, redis_client, precision=14):
self.r = redis_client
self.precision = precision # 寄存器数量的指数(2^14=16384)
def create_hll(self, key):
# 创建指定精度的HLL(需要自定义实现或使用不同key)
# Redis默认使用16384个寄存器,不支持动态调整
# 可以通过多个HLL实例模拟不同精度
pass
def estimate_error(self, count):
# 估计当前精度下的错误率
m = 2 ** self.precision
return 1.04 / math.sqrt(m) # 标准错误率公式
7. 监控与性能优化
7.1 内存使用监控
class SpecialTypeMonitor:
def __init__(self, redis_client):
self.r = redis_client
def monitor_bitmap_memory(self, pattern="*"):
results = []
cursor = 0
while True:
cursor, keys = self.r.scan(cursor, match=pattern, count=100)
for key in keys:
if self.r.type(key) == "string":
# 检查是否可能是bitmap
memory = self.r.memory_usage(key)
if memory > 1024: # 超过1KB的字符串可能是bitmap
results.append((key, memory))
if cursor == 0:
break
return results
def monitor_geo_memory(self):
# Geo类型使用ZSet存储
return self._monitor_zset_memory()
def monitor_hll_memory(self):
# HLL使用固定12KB内存
results = []
cursor = 0
while True:
cursor, keys = self.r.scan(cursor, match="*", count=100)
for key in keys:
if self.r.type(key) == "string":
# 检查HLL魔数
value = self.r.get(key)
if value and len(value) >= 4 and value[:4] == b"HLL":
results.append((key, len(value)))
if cursor == 0:
break
return results
7.2 性能优化建议
Bitmap 优化:
- 使用 BITFIELD 命令进行批量位操作
- 对稀疏位图使用分片策略
- 定期压缩长期不活跃的位图
Geo 优化:
- 对频繁查询的区域建立索引
- 使用 GEORADIUSSTORE 缓存查询结果
- 对静态地理数据启用压缩
HyperLogLog 优化:
- 对小规模数据使用稀疏编码
- 定期合并相关HLL计数器
- 使用 PFCOUNT 进行多键查询时,先检查键是否存在
8. 总结
Redis 的特殊数据类型展示了通过精巧的算法和编码方式在现有数据结构上实现高级功能的设计哲学。Bitmap 基于 String 类型实现了高效的位操作,Geo 基于 ZSet 实现了地理空间索引,HyperLogLog 使用概率算法实现了极低内存消耗的基数统计。
核心优势:
- 内存效率:特殊类型在各自领域提供了极致的内存优化
- 功能丰富:在简单数据结构上实现了复杂功能
- 性能优异:针对特定场景进行了深度优化
- 易于使用:简单的API接口掩盖了底层的复杂性
适用场景:
- Bitmap:布尔值统计、特征标志、布隆过滤器
- Geo:地理位置服务、附近搜索、地理围栏
- HyperLogLog:大规模基数统计、UV统计、去重计数
理解这些特殊类型的实现原理和适用场景,可以帮助开发者在合适的场景选择合适的数据类型,充分发挥 Redis 的性能优势,构建高效、可扩展的应用程序。
Redis 特殊类型实现原理图示
1. Bitmap 内存布局与操作流程图
2. Geo 类型基于 ZSet 的实现图
3. HyperLogLog 结构与算法流程图
4. 特殊类型应用场景对比图
这些图表从不同角度展示了 Redis 三种特殊类型的实现原理、内部结构和应用场景,希望能够帮助您更好地理解它们的设计精髓和适用场景。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120366

 浙公网安备 33010602011771号
浙公网安备 33010602011771号