MongoDB(WiredTiger 引擎)写入丢失 / crash 后的故障排查清单
🛠 故障排查清单(针对未被 majority ack 的写入丢失 / crash)
1. 确认问题范围
-
检查客户端写 Concern:
- 是否使用了
w:1或j:false? → 这种情况下,crash 后丢失未 flush 的写入是预期行为。 - 是否要求了
majority?如果丢失,需要进一步调查。
- 是否使用了
-
检查 MongoDB 日志(mongod.log):
- 查找 crash 前是否有
WT_LOG、journal commit、fsync或checkpoint相关输出。 - 注意异常日志(
E STORAGE、W WiredTiger)。
- 查找 crash 前是否有
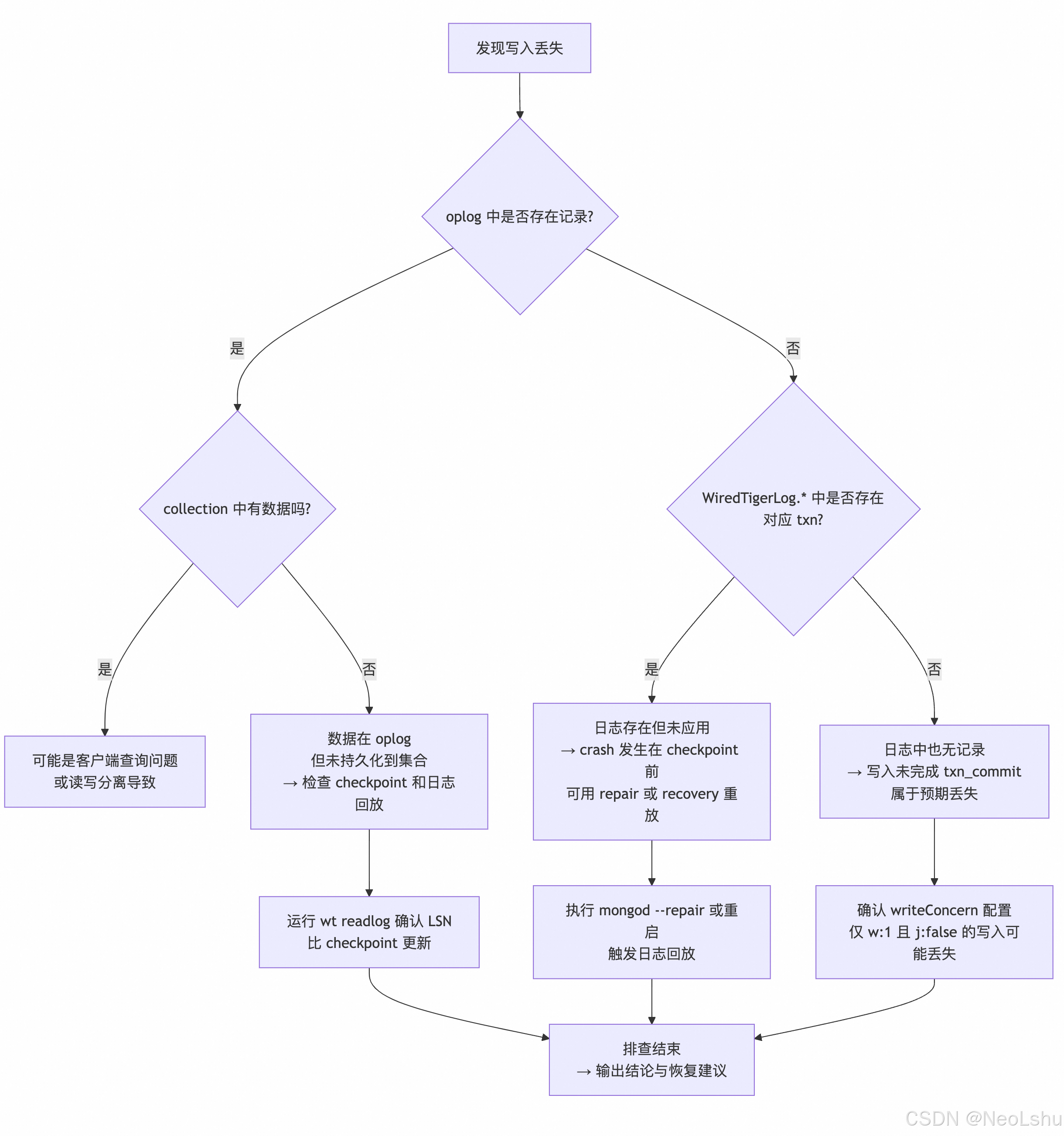
2. 检查 oplog(是否落盘)
-
在 Primary 上:
use local db.oplog.rs.find().sort({$natural:-1}).limit(10).pretty()- 确认丢失的写入是否存在于
oplog.rs中。 - 若 业务集合有写入但 oplog 没有,说明事务未提交成功(可能 crash 前 rollback)。
- 确认丢失的写入是否存在于
-
在 Secondary 上:
rs.printReplicationInfo() rs.printSecondaryReplicationInfo()- 检查 secondary 是否已拉取/应用丢失的 oplog entry。
- 如果 Primary oplog 没有,secondary 自然不会有。
3. 分析 WiredTiger Journal 文件
-
定位文件:
${dbPath}/journal/WiredTigerLog.*- 按编号递增,最新文件通常是
WiredTigerLog.NNNNN.
- 按编号递增,最新文件通常是
-
使用 WiredTiger 工具(MongoDB 自带
wt可执行程序,通常在 bin 目录下):-
查看 journal 内容:
wt -h /path/to/dbPath printlog > wiredtiger_log.txtprintlog会解码 journal 文件,输出事务记录(包括 txn id、commit、操作详情)。- 可以 grep 丢失文档
_id或 collection name。
-
按时间过滤:
grep "optype" wiredtiger_log.txt- 查找
commit记录,确认事务是否已写入日志。
- 查找
-
-
判断是否 flush:
- 如果在 log 中能看到事务记录,但 crash 后集合里没有 → 说明事务尚未 checkpoint,并且 journal replay 未执行(可能 log 损坏,或 recovery 被跳过)。
- 如果 log 里没有 → 事务压根没 commit,或 commit 前 crash。
4. 验证 Crash Recovery 是否正常执行
-
重启 mongod 时,MongoDB 会自动调用 WiredTiger recovery:
-
在
mongod.log中搜索:WiredTiger message [timestamp]: [recovery log scan ...] WiredTiger message [timestamp]: WiredTiger recovery complete -
确认 recovery 是否扫描了 journal 并应用 log。
-
-
如果发现 recovery 跳过了某些日志文件:
- 可能是 log 损坏 / 校验失败 → 可以尝试手动
wt -h <dbpath> salvage,但注意可能导致数据丢失或 collection 损坏。
- 可能是 log 损坏 / 校验失败 → 可以尝试手动
5. 检查 Checkpoint 状态
-
WiredTiger 会定期做 checkpoint:
-
在数据目录下有
WiredTiger.turtle、WiredTiger.wt和*.wt(表文件)。 -
在日志里搜索:
WiredTiger message [timestamp]: checkpoint ... -
如果 crash 发生在上次 checkpoint 之后、journal flush 之前 → 刚提交的事务可能丢失。
-
-
确认 checkpoint 时间,与写入时间对比,判断是否在 checkpoint 落盘前。
6. 判断丢失写入原因
-
丢失情况分类:
- 业务集合写入 + oplog 均丢失 → 事务未 commit 或 rollback。
- 业务集合有写入,但 oplog 丢失 → 非常严重,可能存储层 bug;需要看
printlog是否存在 oplog 插入的记录。 - 业务集合 + oplog 都写了,但 crash 后都丢失 → checkpoint 未完成,journal flush 未执行,属于未持久化数据。
- Secondary 已有 oplog,但 Primary 丢失 → Primary crash 未恢复数据,需要 re-sync。
7. 常用 WiredTiger 工具命令
-
打印日志:
wt -h /data/db printlog -
验证表:
wt -h /data/db verify collection-*.wt -
数据恢复尝试:
wt -h /data/db salvage(⚠️ 慎用,会尝试修复损坏文件,但可能导致文档丢失)
🔍 总结
- 第一步:确认丢失写入是否存在 oplog。
- 第二步:使用
wt printlog检查事务是否写入 WiredTigerLog。 - 第三步:核对 checkpoint 与 journal flush 时机。
- 第四步:检查 mongod 启动 recovery 是否 replay 日志。
- 最后:若发现 log 损坏或 recovery 未执行,需考虑 salvage/全量重建 Secondary。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120280

 浙公网安备 33010602011771号
浙公网安备 33010602011771号