【数据结构与算法】雪花算法(Snowflake)详解:原理、源码、场景与风险分析
雪花算法(Snowflake)详解
一、概念简介
**雪花算法(Snowflake)**是 Twitter 在 2010 年开源的分布式 唯一 ID 生成算法,其主要目标是生成 64 位全局唯一、有序、性能高的 ID,广泛用于分布式系统中的数据库主键、消息队列 ID 等场景。
核心特性
- 全局唯一:在分布式环境下生成不会重复。
- 趋势递增:ID 根据时间戳递增,便于索引排序。
- 高性能:生成速度快,理论上每节点每毫秒可生成数十万 ID。
- 无中心化依赖:无需单点协调,节点独立生成。
二、雪花算法原理
1. ID 结构
Twitter 原版 64-bit Snowflake ID 结构如下:
| Bit 位 | 含义 | 说明 |
|---|---|---|
| 1 | 符号位 | 固定 0,保证为正数 |
| 41 | 时间戳 | 毫秒级时间戳,通常减去自定义 epoch |
| 10 | 机器标识(节点 ID) | 数据中心 ID + 机器 ID |
| 12 | 序列号(Sequence) | 同一毫秒内的自增序号(0~4095) |
总和:1 + 41 + 10 + 12 = 64 位
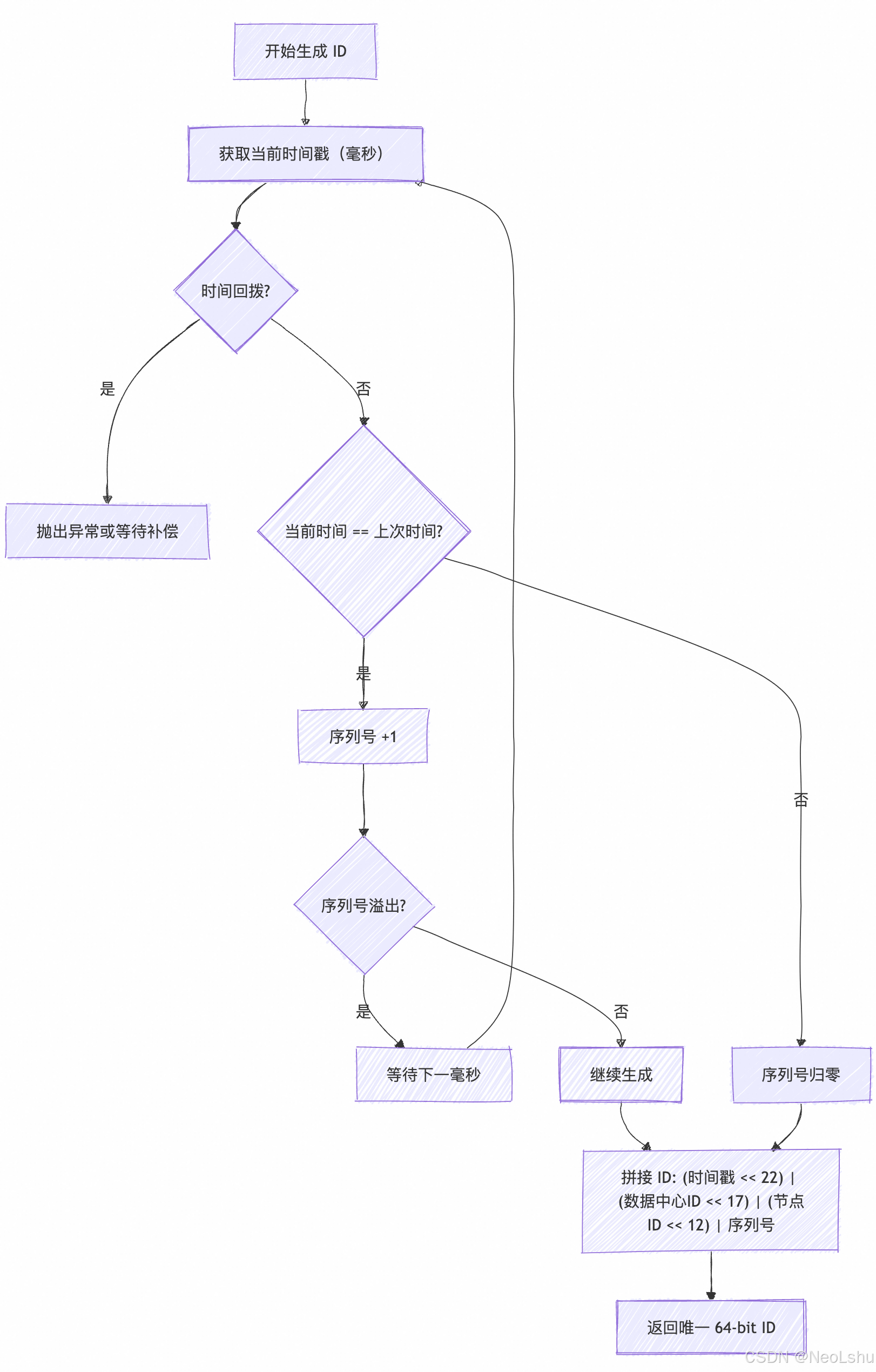
2. 工作原理
-
时间戳(41 bit):
- 保证生成的 ID 按时间递增。
- 可表示
2^41 / (1000*60*60*24*365) ≈ 69 年。
-
节点 ID(10 bit):
- 5 bit 数据中心 + 5 bit 机器节点(可自定义)。
- 保证不同节点生成 ID 不冲突。
-
序列号(12 bit):
- 1 毫秒内可以生成
2^12 = 4096个 ID。 - 如果序列号超限,需要等待下一毫秒。
- 1 毫秒内可以生成
3. 生成逻辑
生成 ID 的伪代码:
currentMillis = 当前时间戳(毫秒) - 自定义 epoch
if currentMillis == lastTimestamp:
sequence = (sequence + 1) & 4095
if sequence == 0:
等待下一毫秒
else:
sequence = 0
lastTimestamp = currentMillis
id = (currentMillis << 22) | (datacenterId << 17) | (workerId << 12) | sequence
三、Java 源码分析
以下为常见 Java 雪花算法实现(简化版):
public class SnowflakeIdGenerator {
private final long workerId;
private final long datacenterId;
private final long epoch = 1609459200000L; // 自定义起始时间 2021-01-01
private long sequence = 0L;
private long lastTimestamp = -1L;
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
private final long sequenceBits = 12L;
private final long maxWorkerId = ~(-1L << workerIdBits);
private final long maxDatacenterId = ~(-1L << datacenterIdBits);
private final long sequenceMask = ~(-1L << sequenceBits);
private final long workerShift = sequenceBits;
private final long datacenterShift = sequenceBits + workerIdBits;
private final long timestampShift = sequenceBits + workerIdBits + datacenterIdBits;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("workerId out of range");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId out of range");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards!");
}
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - epoch) << timestampShift)
| (datacenterId << datacenterShift)
| (workerId << workerShift)
| sequence;
}
private long waitNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}
核心点解析:
- 同步方法保证单节点线程安全。
- 序列号回绕处理:如果 1 毫秒内超过 4096,等待下一毫秒。
- 时间回拨保护:如果系统时钟回退,直接抛异常。
四、使用场景分析
✅ 适用场景
- 数据库主键 ID:尤其是分布式数据库,避免自增 ID 冲突。
- 消息队列消息 ID:保证消息全局唯一,可按时间排序。
- 分布式系统业务标识:订单号、支付流水号等。
❌ 不适用场景
- 跨数据中心严格顺序要求:不同节点间生成的 ID 只保证趋势递增,绝对顺序不可控。
- 对时间敏感的安全场景:ID 可预测,不适合加密或敏感标识。
五、风险与注意事项
1. 时间回拨风险
-
系统时间回退会导致生成重复 ID 或抛异常。
-
解决方案:
- 使用 NTP 时间同步。
- 通过“备用节点 ID”或逻辑时钟补偿。
2. 序列号溢出
-
单节点每毫秒最多 4096 个 ID,超出需要等待下一毫秒。
-
高并发场景需考虑:
- 增加节点数或增加序列号位数。
- 对批量 ID 分配使用缓冲。
3. 节点 ID 冲突
-
节点 ID 配置错误会导致全局重复 ID。
-
生产环境建议:
- 自动生成 workerId(例如通过数据库或配置中心)。
- 保证数据中心 + 机器 ID 唯一。
4. 可预测性
- 雪花算法 ID 根据时间生成,攻击者可大致推测生成规律。
- 如果用于敏感场景,需要额外加随机或加密处理。
✅ 总结
- 雪花算法是一种 高性能、分布式唯一 ID 生成方案,适合数据库主键、消息队列等场景。
- 核心依赖 时间戳 + 节点 ID + 序列号。
- 注意系统时间、序列号溢出、节点 ID 冲突以及安全性风险。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120278

 浙公网安备 33010602011771号
浙公网安备 33010602011771号