

读写文件中的文本格式数据
在所有用于存储数据的文件类型中,CSV 可能是使用最广泛的。在标准 CSV 文件中,
第 1 行是列的标题,后面每行都代表了一条数据记录,每列之间用逗号分开。下面就是一
个用 CSV 格式编写的学生记录的例子:
Name,Gender,Age,Major
Ken,Male,24,Finance
Ashley,Female,25,Statistics
Jennifer,Female,23,Computer Science
1.通过 RStudio IDE 导入数据
RStudio 提供了一个导入数据的接口。可以通过 Tools | Import Dataset | From Local File
选择一个本地文件夹内的文本文件,如 .csv 文件或 .txt 文件。然后,就可以调整参数并预
览生成的数据框了,如图 7-1 所示。
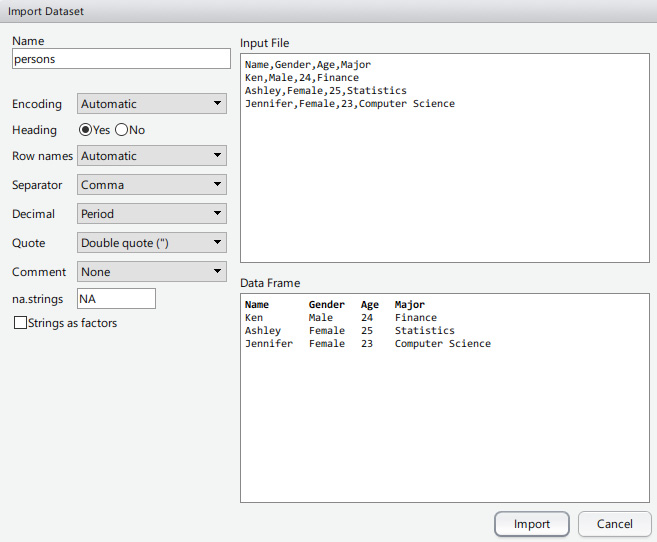
图 7-1
注意,只有想要把字符串类型的列转换成因子时,才需选中 Strings as factors。
文件导入器(the file importer)不是魔术师,它只是将文件路径和这些选项转换成了 R 语
言代码。当设置了数据导入参数,单击 import 按钮,它就会调用 read.csv( )函数。使用
这个交互式工具导入数据非常方便,第一次导入数据文件时,可以避免许多错误。
2.通过内置函数导入数据
编写脚本时,不能每次都靠这种交互式操作来导入文件。可以将导入过程中生成的代
码复制到脚本中,以便每次运行脚本时都能自动调用。因此,了解如何使用内置函数来导
入数据是非常重要的。
导入数据最简单的内置函数是 readLines( )函数,在前面几章中我们也提到过。这
个函数读取文本文件并逐行以字符向量的形式返回:
readLines("data/persons.csv")
## [1] "Name,Gender,Age,Major"
## [2] "Ken,Male,24,Finance"
## [3] "Ashley,Female,25,Statistics"
## [4] "Jennifer,Female,23,Computer Science"
默认情况下,它将会读取文件的所有行。如果只想预览前两行,可以运行如下代码:
readLines("data/persons.csv", n = 2)
## [1] "Name,Gender,Age,Major" "Ken,Male,24,Finance"
在实际导入数据时,readLines( )函数通常过于简单。它将每行数据读取为字符串,
而不是解析到一个数据框中。如果希望用上述代码的方式导入 CSV 文件中的数据,那么可
以直接使用 read.csv( )函数:
persons1 <- read.csv("data/persons.csv", stringsAsFactors = FALSE)
str(persons1)
## 'data.frame': 3 obs. of 4 variables:
## $ Name : chr "Ken" "Ashley" "Jennifer"
## $ Gender: chr "Male" "Female" "Female"
## $ Age : int 24 25 23
## $ Major : chr "Finance" "Statistics" "Computer Science"
如果希望保留字符串类型的值,则需要在函数中设置 stringsAsFactors = FALSE,
避免在调用函数时将字符串转换成因子。
这个函数提供了许多有用的参数以便实现自定义导入。例如,我们可以用 colClasses
明确指定列的类型,用 col.names 替换数据文件中的原始列名:
persons2 <- read.csv("data/persons.csv", colClasses = c("character", "factor",
"integer", "character"),
col.names = c("name", "sex", "age", "major"))
str(persons2)
## 'data.frame': 3 obs. of 4 variables:
## $ name : chr "Ken" "Ashley" "Jennifer"
## $ sex : Factor w/ 2 levels "Female","Male": 2 1 1
## $ age : int 24 25 23
## $ major: chr "Finance" "Statistics" "Computer Science"
注意,CSV 是数据分隔格式的一个特例。从技术角度来说,CSV 格式是一种数据分隔
格式,它用逗号分隔列,用换行符分隔行。一般来说,任何字符都可以用作列分隔符和行
分隔符。许多数据集使用制表符作为分隔格式,即用制表符(tab)分隔列。在这种情况下,
可以尝试通用版:read.table( )函数来导入数据,而且 read.csv( )也是基于它实现。
3.用 readr 包导入数据
由于一些历史原因,read.*函数表现不稳定,而且有时也不是很友好。readr 包是
一个好的选择,它可以快速、稳定地导入表格数据。
运行 install.packages("readr")安装这个包,然后调用一系列的 read_* 函
数导入表格数据:
persons3 <- readr::read_ _csv("data/persons.csv")
str(persons3)
## Classes 'tbl_df', 'tbl' and 'data.frame': 3 obs. of 4 variables:
## $ Name : chr "Ken" "Ashley" "Jennifer"
## $ Gender: chr "Male" "Female" "Female"
## $ Age : int 24 25 23
## $ Major : chr "Finance" "Statistics" "Computer Science"
因为 read_csv( )与内置的 read.csv( )很容易混淆,尽管它们的行为稍有不同。
所以,这里我们用的是 readr::read_csv( )而不是 library(readr),然后直接调
用 read_csv( )来读取文件。
另外,请注意,read_csv 的默认行为很智能,足以应对大多数情况。为了与内置函
数相对比,我们导入一个格式不规范的数据文件(data / persons.txt):
Name Gender Age Major
Ken Male 24 Finance
Ashley Female 25 Statistics
Jennifer Female 23 Computer Science
文件内容看起来是标准的表格格式,但每行的列间空格数是不相等的,因此,无法组
合使用 read.table( )与 sep = " ":
read.table("data/persons.txt", sep = " ")
## Error in scan(file, what, nmax, sep, dec, quote, skip, nlines,
na.strings, :line 1 did not have 20 elements
如果坚持使用 read.table( )导入数据,那么,为了设置能够控制函数行为的正确
参数,就可能浪费很多时间。但是,相同的输入,readr 包中 read_table( )函数的默
认处理方式就足够智能,因此可以节省时间:
readr::read_ _table("data/persons.txt")
## Name Gender Age Major
## 1 Ken Male 24 Finance
## 2 Ashley Female 25 Statistics
## 3 Jennifer Female 23 Computer Science
这就是为什么我强烈建议你使用 readr 中的函数将表格数据导入到 R 中的原因。
readr 中的函数是快速、智能和稳定的,而且也支持内置函数(更易用)的相关功能。了
解有关 readr 包的更多信息,请访问 https://github.com/hadley/readr。
4.将数据框写入文件
数据分析的标准过程是:从数据源导入数据,转换数据,运用适当的工具和模型,最
后创建并存储一些新数据以便决策使用。将数据写入文件的接口与用于读取数据的接口非
常相似——我们用 write.*函数将数据框导出到文件。
例如,我们可以创建任意一个数据框并将其存储在 CSV 文件中:
some_data <- data.frame(
id = 1:4,
grade = c("A", "A", "B", NA),
width = c(1.51, 1.52, 1.46, NA),
check_date = as.Date(c("2016-03-05", "2016-03-06", "2016-03-10","2016-03-11")))
some_data
## id grade width check_date
## 1 1 A 1.51 2016-03-05
## 2 2 A 1.52 2016-03-06
## 3 3 B 1.46 2016-03-10
## 4 4 <NA> NA 2016-03-11
write.csv(some_data, "data/some_data.csv")
要想检查 CSV 文件是否正确保留了缺失值和日期,可以从原始文本中读取输出的文件:
cat(readLines("data/some_data.csv"), sep = "\n")
## "","id","grade","width","check_date"
## "1",1,"A",1.51,2016-03-05
## "2",2,"A",1.52,2016-03-06
## "3",3,"B",1.46,2016-03-10
## "4",4,NA,NA,2016-03-11
虽然数据都是对的,但对于存储这样的数据,有时我们可能会有不同的标准。
write.csv( )函数允许修改写入行为。从上述输出结果来看,我们可能会认为其中包含
了一些不必要的元素。例如,我们通常不希望导出行名,因为 id 已经完成了这项工作,所
以再加行名就有点多余。同样,也不需要字符串两侧的引号,而且希望用-而不是 NA 来表
示缺失值。接下来,运行以下代码导出我们期望的数据框:
write.csv(some_data, "data/some_data.csv", quote = FALSE, na = "-", row.names
= FALSE)
现在,输出的数据是一个简化后的 CSV 文件:
cat(readLines("data/some_data.csv"), sep = "\n")
## id,grade,width,check_date
## 1,A,1.51,2016-03-05
## 2,A,1.52,2016-03-06
## 3,B,1.46,2016-03-10
## 4,-,-,2016-03-11
我们可以用 readr::read_csv( )导入这个自定义了缺失值和日期的 CSV 文件:
readr::read_ _csv("data/some_data.csv", na = "-")
## id grade width check_date
## 1 1 A 1.51 2016-03-05
## 2 2 A 1.52 2016-03-06
## 3 3 B 1.46 2016-03-10
## 4 4 <NA> NA 2016-03-11
注意,-指代缺失值,并且日期列也作为日期对象导入:
## [1] TRUE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号