Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow ——Chapter 2
1.项目整体分析:
本部分展示一个ML项目,假设是一家房地产公司的新聘数据科学家。下面是这个项目的步骤:
- 看大图
- 获取数据
- 发现和可视化数据以获得见解
- 准备用于机器学习算法的数据
- 选择一个模型并进行训练
- 微调您的模型
- 介绍您的解决方案
- 启动,监视和维护系统。
在学习机器学习时,最好尝试使用真实数据而不是人工数据集。本部分使用的示例数据集是“加利福尼亚住房价格”数据集,该数据集基于1990年加利福尼亚人口普查的数据。
项目任务是使用加利福尼亚人口普查数据建立该州房价模型。数据包括加利福尼亚州每个街区组的人口,中位数收入和房价中位数等指标。模型从这些数据中学习,并能够根据所有其他指标来预测任何地区的房价中位数。
机器学习项目的首要任务是明确业务目标到底是什么。目标将决定问题的框架,选择的算法,评估模型的性能指标以及调整模型的工作量。下图是该示例项目的目标:
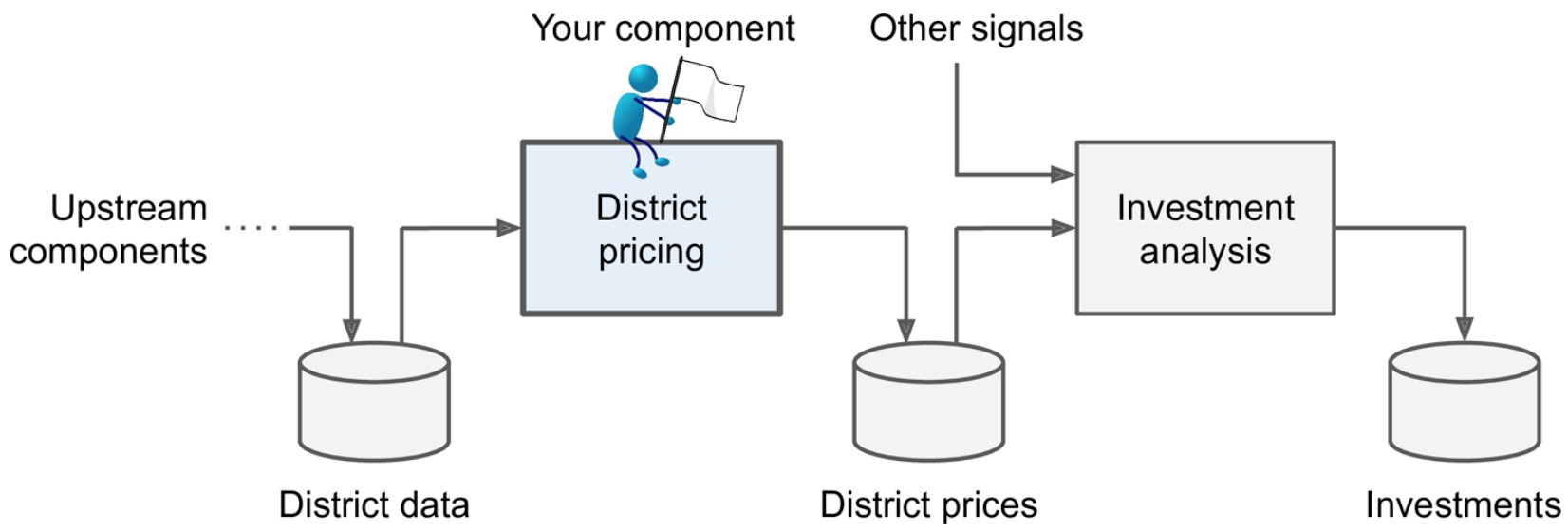
可以看到,该项目模型的输出(对某个地区房价中位数的预测)将与其他许多信号一起被馈送到另一个机器学习系统。
在设计这个系统前,需要回答这些问题:是监督学习,无监督学习还是强化学习?它是分类任务,回归任务还是其他?您应该使用批处理学习还是在线学习技术?
该项目属于:
supervised learning task
regression task
batch learning(数据源不是流式的)
评价指标:均方根误差(RMSE),计算方法:
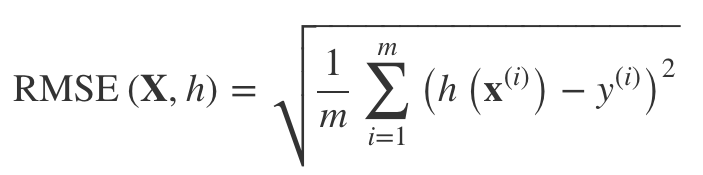
或者也可以使用MAE:
![]()
上边RMSE是欧式距离,而MAE是曼哈顿距离,当然还有普通的n阶。规范指数越高,它越关注大值而忽略小值。这就是为什么RMSE对异常值比MAE更敏感的原因。但是,当离群值呈指数形式稀有时(如钟形曲线),RMSE表现非常好,通常是首选。
2.获取数据:
我安装的Anaconda的多环境,该应用准备使用python3来完成,所以在python3的环境下,需要安装 pandas、matplotlib、scikit-learn等包,如下代码 :
$ conda list # 查看pip版本 $ python -m pip --version # 使用pip来安装包 $ python -m pip install matplotlib scipy scikit-learn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号