MR execution in YARN
Overview
YARN provides API not for application developers but for the great developers working on new computing engines. YARN make it easy and unified for resource management for the computing engines. It fills the gap between mputation and storage. NoSQL database like HBase use slider apdaters to YARN.
With YARN 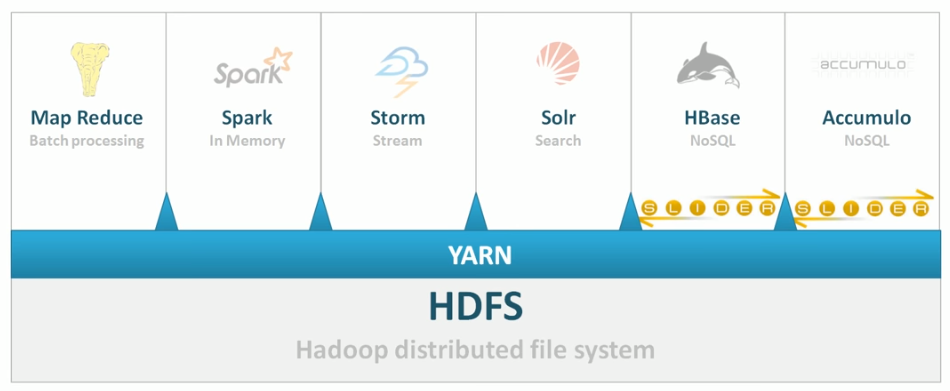
Withou YARN

Entities in YARN
The base of Distribution is HDFS and YARN. HDFS for managing storage. YARN for managing computing.
Client: who submits the job: connects to MR or HDFS framework.
YARN Resource Manager: allocate computing resource required by the job.
Scheduleer:job scheduling,locate the resources.
Application Manager:performan any monitoring or tracking of application/job status.
YARN Node Manager: on all slave nodes. launch / manager containers.
MR Application Master:carry out execution of the job associated with it. different between computing engines. It coordinates the tasks running and monitors the progress and aggregates it and since reports to its client . It is spawn under node manager on the instruction by RM. spawn for every job and end with the job done.
YARN Child: manages the run of the map and reduce tasks,send updates / progress to application master.
HDFS:i/o
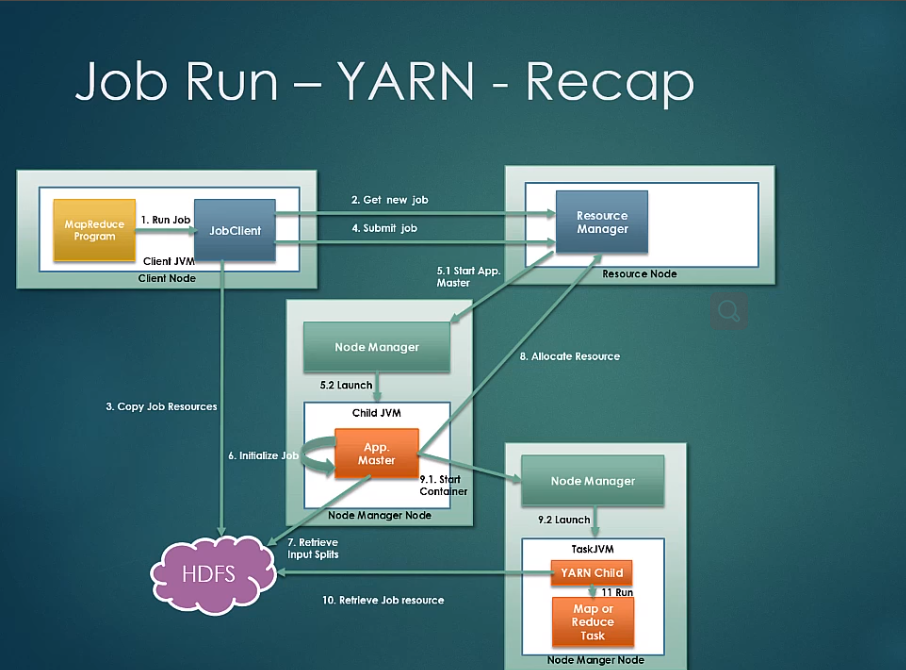
The process of job run in YARN
Job submission:Your program triggers the job client and the job client contacts the RM for the new job id. copy the job resource to HDFS with high replica and then submit the job.
Job Initialization: Then RM (the scheduler)picks up the job from the job queue(FIFO,capacity,fair) and contacts NM,sponsor new container (Linux kernel feature, a abstruct of resource like cpu,mem,disk,network bandwidth. doker uses it too) and launches AM for the job.
Job Assigement: AM creates new objects , it retrives the input splits from HDFS and crete one task per input split. AM then decides if the job is samll or not. If it is small job , run its jvm on a single node. If not,contacts RM locate computing resources.
Job Execution:RM considers data locality while assigning the resources(Scheduler at this time knows where the splits are located.It gathers this info from the heartbeats of NM. Based on it, it consider data locality when allocating resources. try as best, then consider the rack local nodes ,if still fails, it will pick random from available noedes).AM then communicates node managers which launches the yarn child(a java program the main class is YarnChild,seperate JVM from long running system demons from the suer code). yarn child retrieves the code and other resource from HDFS and then run the tasks(mr).Yan child sends the progress to AM(every 3 seconds) which aggregrates(each yarn client's information) the report and sends the report to the client.
Job Exmpletion:On job completion , yarn child and AM terminates themseves for the next job.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号