相机模型与相机标定原理
## 一、传感器
传感器是组成数字摄像头的重要组成部分可分为CCD(Charge Coupled Device,电荷耦合元件)、CMOS(Complementary Metal-Oxide Semiconductor,金属氧化物半导体元件)和CIS(Contact Image Sensor,接触式图像传感器)。
二、针孔相机模型
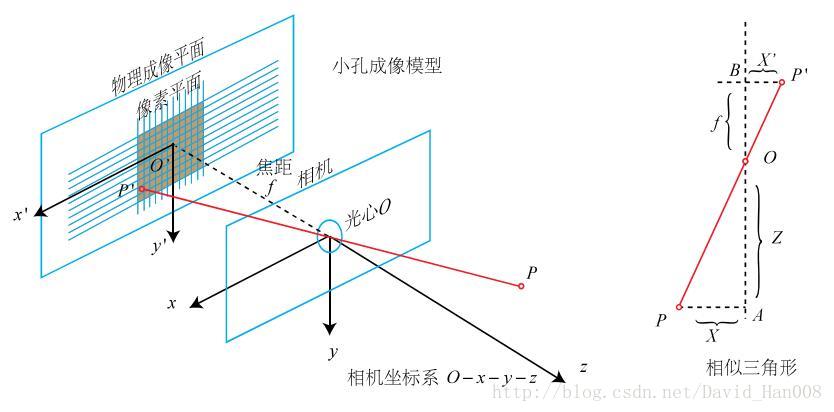
简单的针孔模型进行几何建模。设 \(O-x-y-z\) 为相机坐标系,让 z 轴指向相机前方,x向右,y向下。O为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点P,经过小孔O投影之后,落在物理成像平面 \(O−x′−y′\) 上,成像点为 \(P′\) 。设P的坐标为 \({[X,Y,Z]^T}\) ,\(P′\) 为 \([X′,Y′,Z′] ^T\),并且设物理成像平面到小孔的距离为 f (焦距)。那么,根据三角形相似关系,有:
其中负号表示成的像是倒立的。为了简化模型,把可以成像平面对称到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如图 中间的样子所示。这样做可以把公式中的负号去掉,使式子更加简洁:$$\frac{Z}{f}=\frac{X}{X'}=\frac{Y}{Y'}$$整理得:
上述两个式子描述了点\(P\)和它的像之间的空间关系。不过,在相机中,我们最终获得的是一个个的像素,这需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,我们设在物理成像平面上固定着一个像素平面\(o−u−v\)。我们在像素平面得到了\(P′\) 的像素坐标:\([u, v]^T\) 。像素坐标系通常的定义方式是:原点 \(o′\) 位于图像的左上角,\(u\)轴向右与\(x\)轴平行,\(v\)轴向下与\(y\)轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。我设像素坐标在\(u\)轴上缩放了\(α\)倍,在\(v\)上缩放了\(β\)倍。同时,原点平移了\([c_x,c_ y ]^T\)。那么,\(P′\)的坐标与像素坐标 \([u, v]^T\) 的关系为:
:$$\frac{Z}{f}=\frac{X}{X'}=\frac{Y}{Y'}$$
整理得:
像素坐标系通常的定义方式是:原点 \(o′\) 位于图像的左上角,\(u\)轴向右与\(x\)轴平行,\(v\)轴向下与\(y\)轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。设像素坐标在\(u\)轴上缩放了\(α\)倍,在\(v\)上缩放了\(β\)倍。同时,原点平移了\([c_x,c_ y ]^T\)。那么,\(P′\)的坐标与像素坐标 \([u, v]^T\) 的关系为:
令\(\alpha f=f_x\) ,\(\beta f=f_y\),得:
其中,\(f\)的单位为米,\(α\),\(β\)的单位为像素每米,所以\(f_x\),\(f_y\)的单位为像素。把该式写成矩阵形式,会更加简洁,不过左侧需要用到齐次坐标:
中间的量组成的矩阵称为相机的内参数矩阵(Camera Intrinsics)K。通常认为,相机的内参在出厂之后是固定的,不会在使用过程中发生变化。有的相机生产厂商会告诉你相机的内参,而有时需要你自己确定相机的内参,也就是所谓的标定。
除了内参之外,自然还有相对的外参。由于相机在运动,所以P的相机坐标应该是它的世界坐标(记为\(P_w\)),根据相机的当前位姿,变换到相机坐标系下的结果。相机的位姿由它的旋转矩阵R和平移向量t来描述。那么有:$$ZP_{uv}=Z{\left[ \begin{matrix}u \v \1 \end{matrix} \right]}=K(RP_w+t)=KTP_w$$描述了 P 的世界坐标到像素坐标的投影关系。其中,相机的位姿 R, t 又称为相机的外参数(Camera Extrinsics)。上式两侧都是齐次坐标。因为齐次坐标乘上非零常数后表达同样的含义,所以可以简单地把 \(Z\) 去掉:$$P_{uv}=KTP_w$$
三、畸变
为了获得好的成像效果,在相机的前方加了透镜。透镜的加入对成像过程中光线的传播会产生新的影响: 一是透镜自身的形状对光线传播的影响,二是在机械组装过程中,透镜和成像平面不可能完全平行,这也会使得光线穿过透镜投影到成像面时的位置发生变化。
由透镜形状引起的畸变称之为径向畸变。在针孔模型中,一条直线投影到像素平面上还是一条直线。可是,在实际拍摄的照片中,摄像机的透镜往往使得真实环境中的一条直线在图片中变成了曲线。越靠近图像的边缘,这种现象越明显。由于实际加工制作的透镜往往是中心对称的,这使得不规则的畸变通常径向对称。它们主要分为两大类,桶形畸变和枕形畸变,如图所示。
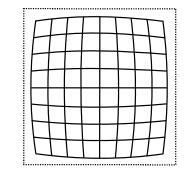
桶形畸变是由于图像放大率随着离光轴的距离增加而减小,而枕形畸变却恰好相反。
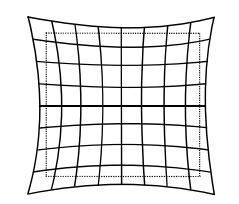
在这两种畸变中,穿过图像中心和光轴有交点的直线还能保持形状不变。
除了透镜的形状会引入径向畸变外,在相机的组装过程中由于不能使得透镜和成像面
严格平行也会引入切向畸变。如图所示
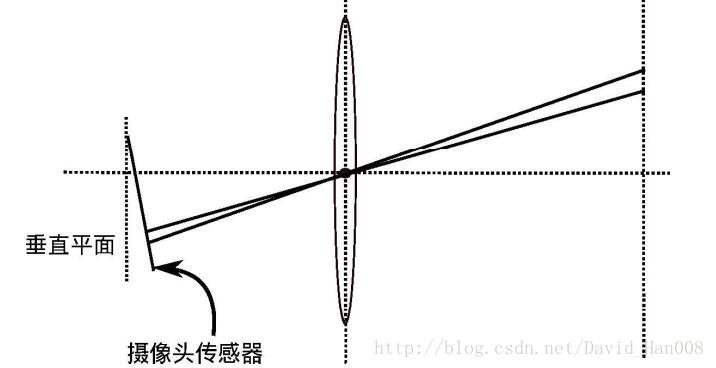
知道平面上的任意一点\(p\)可以用笛卡尔坐标表示为\([x,y]^T\),也可以把它写成极坐标的形式\([r,\theta]^T\) ,其中\(r\)表示点\(p\)离坐标系原点的距离,θ表示和水平轴的夹角。径向畸变可看成坐标点沿着长度方向发生了变化\(\delta r\),也就是其距离原点的长度发生了变化。切向畸变可以看成坐标点沿着切线方向发生了变化,也就是水平夹角发生了变化\(\delta\theta\)。对于径向畸变,无论是桶形畸变还是枕形畸变,由于它们都是随着离中心的距离增加而增加。可以用一个多项式函数来描述畸变前后的坐标变化:这类畸变可以用和距中心距离有关的二次及高次多项式函数进行纠正:
其中 \([x, y]^T\) 是未纠正的点的坐标,\([x_{corrected} , y_{corrected} ]^T\) 是纠正后的点的坐标,注意它们都是归一化平面上的点,而不是像素平面上的点。
对于畸变较小的图像中心区域,畸变纠正主要是\(k_1\)起作用。而对于畸变较大的边缘区域主要是\(k_2\) 起作用。普通摄像头用这两个系数就能很好的纠正径向畸变。对畸变很大的摄像头,比如鱼眼镜头,可以加入\(k_3\) 畸变项对畸变进行纠正。
另一方面,对于切向畸变,可以使用另外的两个参数 \(p_1\) ,$ p_2$ 来进行纠正:
对于相机坐标系中的一点\(P(X,Y,Z)\),我们能够通过五个畸变系数找到这个点在像素平面上的正确位置:
- 将三维空间点投影到归一化图像平面。设它的归一化坐标为$ [x, y]^T$ 。
- 对归一化平面上的点进行径向畸变和切向畸变纠正。
- 将纠正后的点通过内参数矩阵投影到像素平面,得到该点在图像上的正确位置。
在上面的纠正畸变的过程中,使用了五个畸变项。实际应用中,可以灵活选择纠正模型,比如只选择 \(k_1\) ,$ p_1$ , \(p_2\) 这三项等
最后,我们小结一下单目相机的成像过程:
- 首先,世界坐标系下有一个固定的点 \(P\) ,世界坐标为 \(P_w\) ;
- 由于相机在运动,它的运动由$ R\(,\) t$ 或变换矩阵$ T ∈ SE(3) \(描述。\)P\(的相机坐标为: \)P̃_ c = RP_ w + t$。
- 这时的 P̃ c 仍有 X, Y, Z 三个量,把它们投影到归一化平面 Z = 1 上,得到 P 的归一化相机坐标:$P_c = [X/Z, Y /Z, 1] ^T $ 。
- 最后,P 的归一化坐标经过内参后,对应到它的像素坐标:\(P_{uv} = KP_c\) 。
四、双目相机模型
针孔相机模型描述了单个相机的成像模型。然而,仅根据一个像素,我们是无法确定这个空间点的具体位置的。这是因为,从相机光心到归一化平面连线上的所有点,都可以投影至该像素上。只有当 P 的深度确定时(比如通过双目或 RGBD 相机),我们才能确切地知道它的空间位置。
测量像素距离(或深度)的方式有很多种,像人眼就可以根据左右眼看到的景物差异(或称视差)来判断物体与我们的距离。双目相机的原理亦是如此。通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。双目相机一般由左眼和右眼两个水平放置的相机组成。当然也可以做成上下两个目,但我们见到的主流双目都是做成左右的。在左右双目的相机中,我们可以把两个相机都看作针孔相机。它们是水平放置的,意味两个相机的光圈中心都位于 x 轴上。它们的距离称为双目相机的基线(Baseline, 记作 b),是双目的重要参数。
现在,考虑一个空间点 \(P\) ,它在左眼和右眼各成一像,记作$P_L $, \(P_R\)。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只有在 \(x\) 轴上有位移,因此 \(P\) 的像也只在 \(x\) 上有差异。我们记它在左侧的坐标为 \(u_L\) ,右侧坐标为 \(u_R\) 。$$\frac{z-f}{z}=\frac{b-u_L+u_R}{b}$$
稍加整理,得
这里 \(d\) 为左右图的横坐标之差,称为视差(Disparity)。根据视差,我们可以估计一个像素离相机的距离。视差与距离成反比:视差越大,距离越近 。同时,由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由$ f b $确定。我们看到,当基线越长时,双目最大能测到的距离就会变远;反之,小型双目器件则只能测量很近的距离。
五、相机标定
相机标定一般是通过棋盘图

-
检测每张图片中的棋盘图案的角点;
-
通过使用线性最小二乘法估算相机投影矩阵P;
-
根据P矩阵就解内参矩阵K和外参矩阵R,t;
-
通过非线性优化,提高K,R,t矩阵的精度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号