


注意力机制与Transformers
零、预训练 & 词向量
0.1 预训练
- 预训练 = 生成词向量 + 迁移到下游任务
- 预训练的过程,就是在 大量文本 上学习每个单词的最佳词向量,让其捕捉语义信息
- 训练完成后,模型可以将新数据中的单词转换成合理的词向量,以便用于下游任务
- Word2Vec得到的是静态词向量,不能区分不同语境下的一词多义
- BERT,GPT得到的是动态词向量,能根据上下文调整词的意义
- 预训练完的语言模型,本质上就是一个能为任何文本生成高质量词向量的系统,这就是 NLP 预训练的核心价值
0.2 静态 & 动态 词向量
-
静态词向量:预训练阶段,模型计算出 "apple" 的固定词向量,比如 (0,1,12),之后进行下游任务中,"apple" 的词向量就会被赋予(0,1,12)
-
动态词向量
- 预训练时,模型学习的是如何根据上下文生成词向量,而不是给每个单词分配一个固定的向量
- 词向量是根据上下文动态变化的,即同一个单词在不同语境下词向量不同!
Sentence 1: "I eat an apple." → apple 的词向量是 (0.2, 1.1, 11.5) Sentence 2: "Apple released iOS." → apple 的词向量是 (5.6, 0.9, 2.1)- 因为 BERT 不是单独看 "apple" 这个词,而是结合整个句子计算它的词向量。
- 所以,在新的任务中,BERT 仍然会根据上下文重新计算词向量,而不是简单复用原来的词向量。
0.3 NLP相关问题
- nlp是什么:研究人与计算机之间,使用自然语言进行通信的理论和方法
- nlp相关领域
- 文本分类:情感分类、主题分类
- 生成式任务:根据一段文本,生成另一段文本
- 翻译:汉译英
- 文本摘要:提取文章主题
- 对话系统:gpt
- 问答系统:gpt
- 语音识别
一、Attention
1.1 人类的注意力机制
- 从众多信息中选择出对处理当前任务目标更为关键的信息
1.2 本质思想
-
思想类似人类的注意力机制,即从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略不重要的信息。
-
attention的其他作用
- LSTM克服了RNN长距离缺乏依赖的问题,但单词超过200时就会失效
- attention进一步解决了长距离依赖(超长距离),且具有并行计算能力
- 弹幕数据集其实这点影响不大,因为大多都是短文本
-
Q、K、V
- 核心思想:动态计算不同位置之间的相关性,赋予输入序列中不同位置不同的权重,从而捕捉长距离的依赖关系
- 直观理解
- Query:表示查询向量,告诉我们要关注什么
- Key:表示键向量,帮助Query找到匹配的信息
- Value:表示值向量,存储最终输出的信息
- 类比搜索引擎
- Query:搜索的关键词(eg:搜索什么是attention)
- Key:网页的关键词标签(eg:”深度学习“,”注意力机制")
- Value:网页的实际内容
- Q,K,V的计算到底干了一件什么事:通过Query和Key计算注意力权重,然后用权重去加权

-
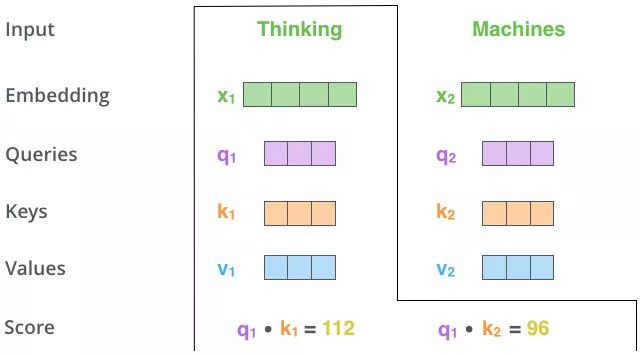
计算过程
- 首先做Q和K的点乘,得到结果Si
- 点积可以衡量两个向量的相似程度
- 若点积值较大,则Q和K的方向接近,应该分配更大的注意力权重
- 若点积值较小,则Q和K的方向差异较大,应该分配更小的注意力权重
- 再将Si进行Softmax处理,得到概率ai
- 为什么Softmax要除以一个$/sqrt k$:稳定梯度,防止梯度消失和梯度爆炸
$$
\alpha_i=softmax(\frac{f(Q,K_i)}{\sqrt{d}_k})
$$- 最后针对算出的权重ai,对V中所有Values加权求和,得到attention向量(Attention Value= a1V1 + a2V2 + ... + amVm)
- 首先做Q和K的点乘,得到结果Si
-
关于最后的结果Attention向量的理解
- Attention 向量是最终的加权表示,综合了输入序列的所有重要信息
- 它是 上下文感知的表示,可以动态关注不同部分,而不是固定地使用某个局部信息
- 让模型知道,上下文哪里更重要,哪里更不重要
1.3 Self Attention模型
整体架构:即QK点乘,Softmax,对V加权
- Attention是一种思想,Self Attention是Attention的一个具体做法
- 给定一个输入X,通过Self Attention得到一个Z,这个Z就是对X的新的表征(词向量),Z这个词向量相比较X拥有了句法特征和语义特征

-
QKV矩阵的由来:有输入向量X,以及三个可学习的矩阵参数WQ、WK、WV,分别用X右乘上述矩阵得到Q,K,V
-
Self Attention计算流程
-
QKV获取

-
QK点乘
3.Softmax

4.对V加权求和
-

1.4 Self Attention VS RNN、LSTM
- RNN和LSTM都是依次序列计算,对于远距离依赖,需要若干时间的步骤累积才能将二者联系,且距离越远有效捕获可能性越小
- 自注意力机制在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征
1.5 Masked Self Attention模型
整体架构:对比自注意力机制,就是多了一层Mask

- Mask的作用及直观理解:不给模型看到未来的信息, mask 就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息
- 在做完 softmax 之后,横轴结果合为 1

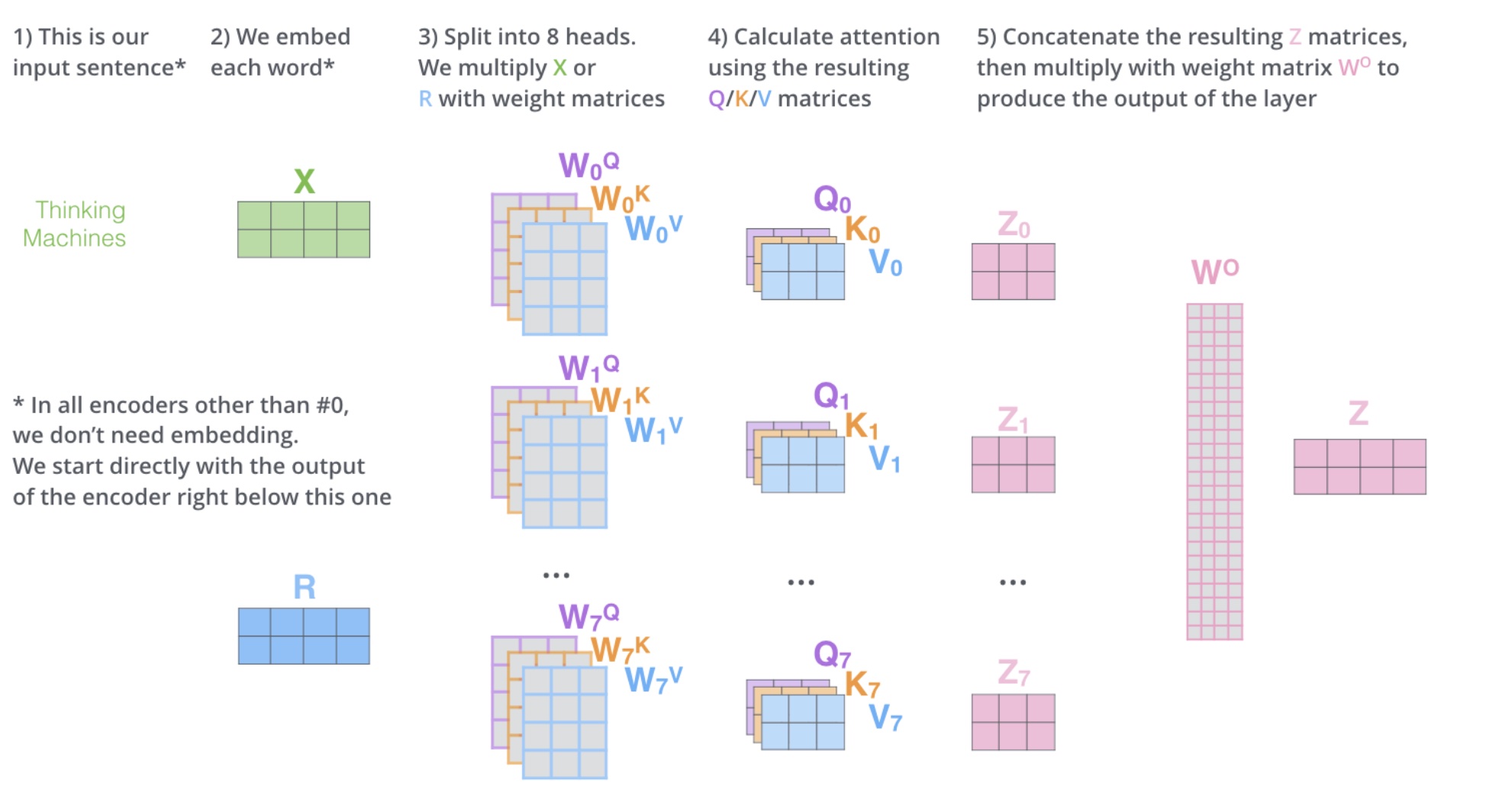
1.6 Multi-Head Self Attention模型

- head,即深度/层数,多头的个数用h表示,一般h = 8
- 如何多头
- 对于输入X,不是直接拿X去得到Z,而是把X分成8块,得到Z0-Z7
- 然后将Z0-Z7拼起来,再做一次线性变换(改变维度),得到Z
- 多头将X切分为8块,这样原先在一个位置上的X,去了空间上的8个位置,通过对8个点寻找,找到更合适的位置(用更多的矩阵去提取特征)
二、Positional Encoding
- 位置编码出现的必要性 - Attention的缺点
- Attention可以并行,即在计算词向量时,词与词之间不存在顺序关系,打乱一句话,这句话里的每个词最后计算得出的词向量依然不会变,即无位置关系
- 所以通过位置编码的形式给词加一个位置
- 为什么RNN,LSTM不需要位置编码:因为它们本来就是依次从前往后计算的,词与词之间的顺序关系是存在的
- 看图理解:即对于输入x1,给他加一个位置编码t1,得到新的x1,这样处理之后Xi之间就会存在位置关系
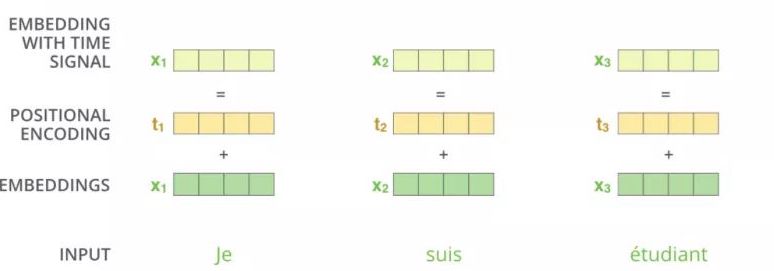
- 如何加位置编码
- pos表示位置,i表示维度,dmodel表示位置向量的向量维度(512)
- 即偶数位置使用sin处理,奇数位置使用cos处理
- 通过把单词的词向量X,和位置编码进行叠加,这种方法就成为位置嵌入
$$
PE_{(pos,2i)}=sin(pos/10000{2i/d_{\mathrm{model}}})\PE_{(pos,2i+1)}=cos(pos/10000{2i/d_{\mathrm{model}}})
$$
- 原理先不看,直接记结论:某个单词的位置信息是其他单词位置信息的线性组合 ,这种线性组合就意味着位置向量中蕴含了相对位置信息。
三、Transformer
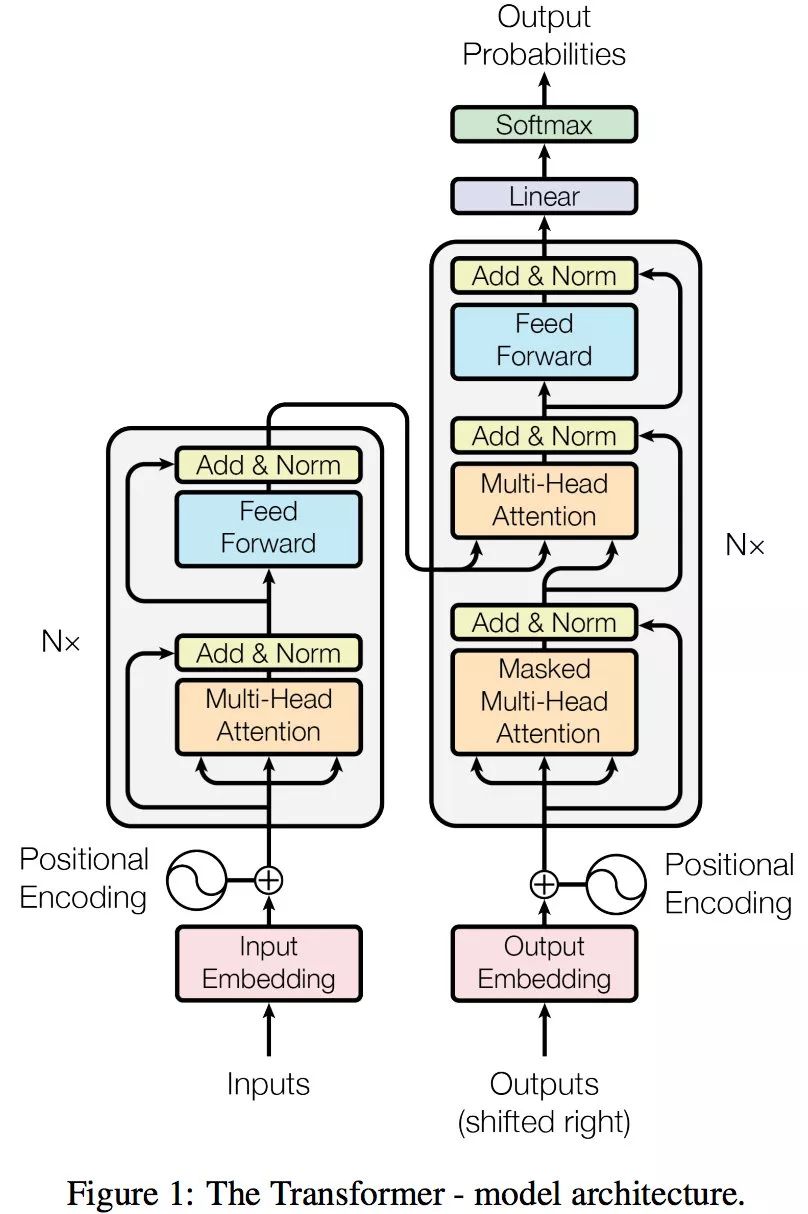
3.1 结构
-
引用seq(编码器)2seq(解码器)模型(序列to序列)
-
主要就是两部分,即编码器 + 解码器
-
编码器:把输入序列变成一个词向量
-
解码器:得到编码器输出的词向量,生成翻译的结果(单词)
-
抽象来看,就是下面这样
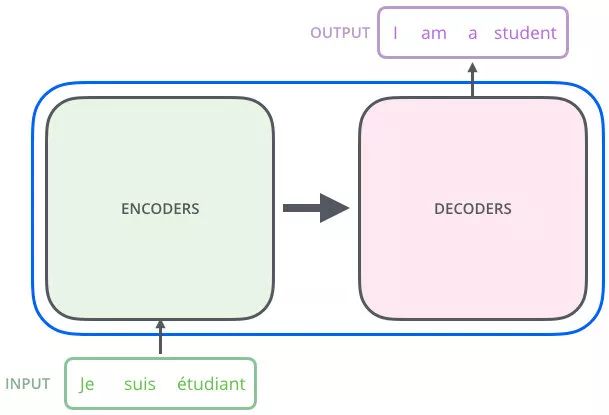
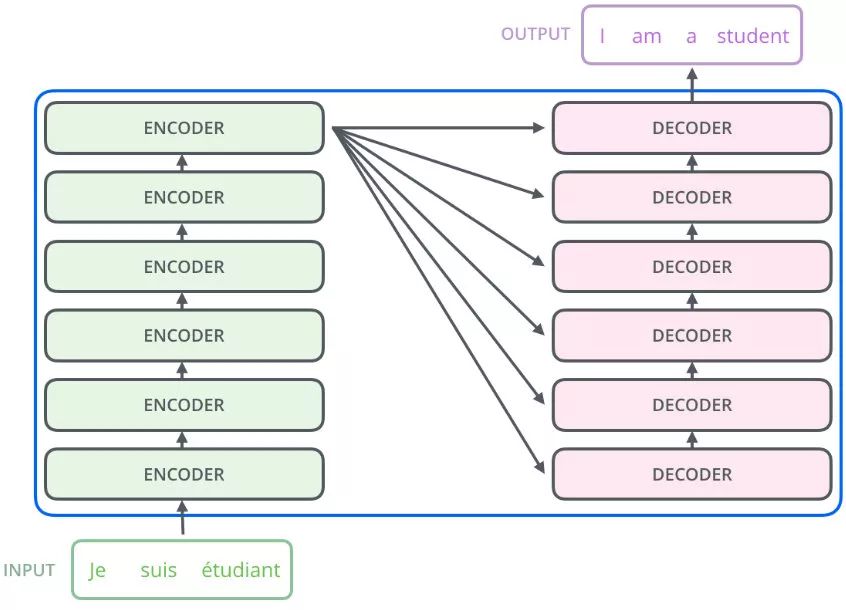
- 在实际的Transformer中,编码器里面又有N个小编码器,一般N=6
3.2 Encoder
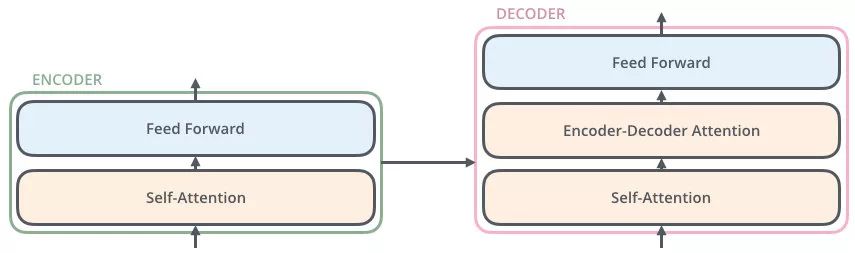
- 从总结构图可以看出,每个Encoder有两部分组成,即多头注意力和feedforward,在每一层之后都会加一个Add&Norm,即残差网络+归一化
- 整个解码器的作用:拿到初始词向量,经过Attention和FeedForward非线性变化,最终输出的词向量,相比初始词向量更具语义信息,包含了这个词与句子中其余词的关系

-
整个过程可以概括为
-
X1为thinking的词向量(可以是独热编码,Word2vec等等),给X1加一个位置编码得到黄色的X1
-
输入到Self Attention中,(X1和X2)拼接起来做注意力机制,得到Z1(Z1是X1和(X1,X2)做注意力机制得到的词向量,表征的仍然是thinking),Z1拥有了位置特征,句法特征,语义特征
-
之后经过残差网络(避免梯度消失)以及归一化
-
最后经过feedforward(两次线性变换+ReLU),在最后一层Encoder后输出最终词向量r1
-
注意x,z,r的维度都是一样的,论文中为512维
-
3.3Decoder
还是这个图
- 可以看到每个decoder包含三个子层,即自注意力、Encoder-Decoder Attention计算和FeedForward
- 关于为什么第一层的多头注意力机制需要Masked
- 以及为什么需要计算Encoder-Decoder Attention
- 详见Transformer动态流程演示
3.4 Transformer的输出结果
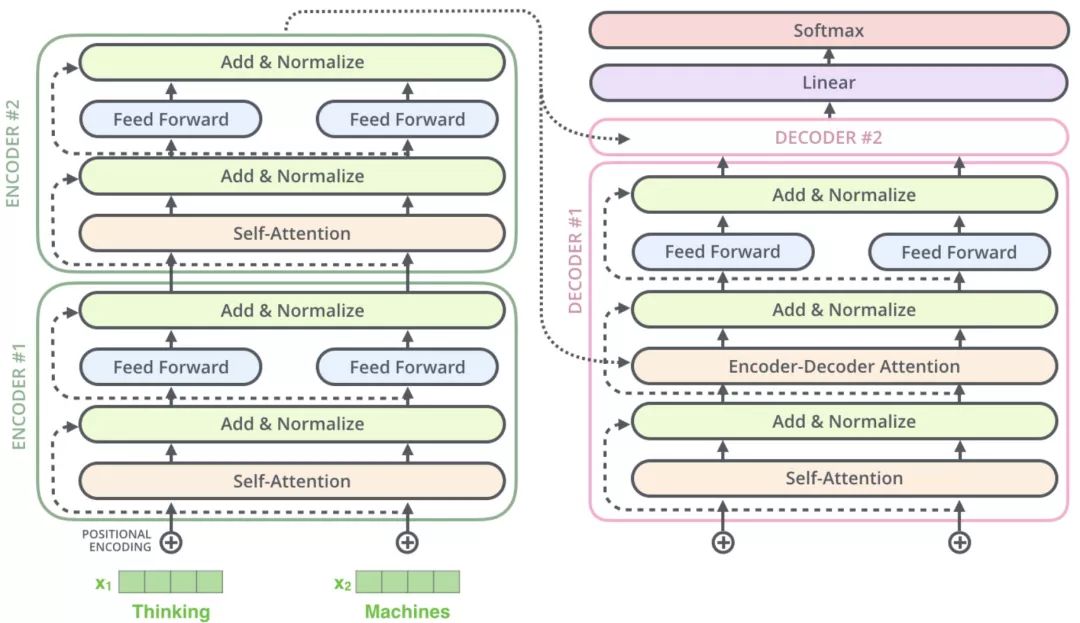
- 可以看到编码器生成的词向量会传递给解码器
- 解码器得到词向量后,输出一个向量
- 这个向量会经过一层线性层,最终再经过Softmax
- 线性层即全连接层,比如你的词汇表有1000个词,而输出向量的维度有1500,此时就需要一个线性层将1500维->1000维
- 经过Softmax,得分最高级概率最大,最终输出概率最大的词
3.5 Transformer动态流程
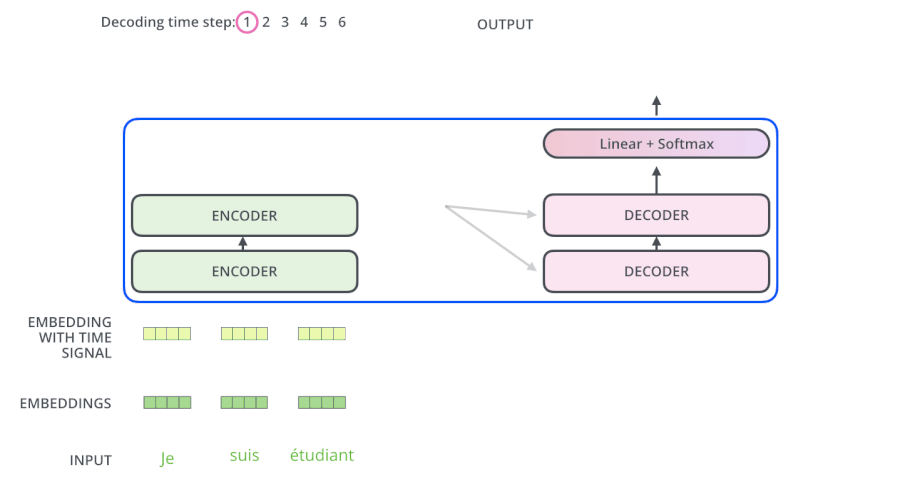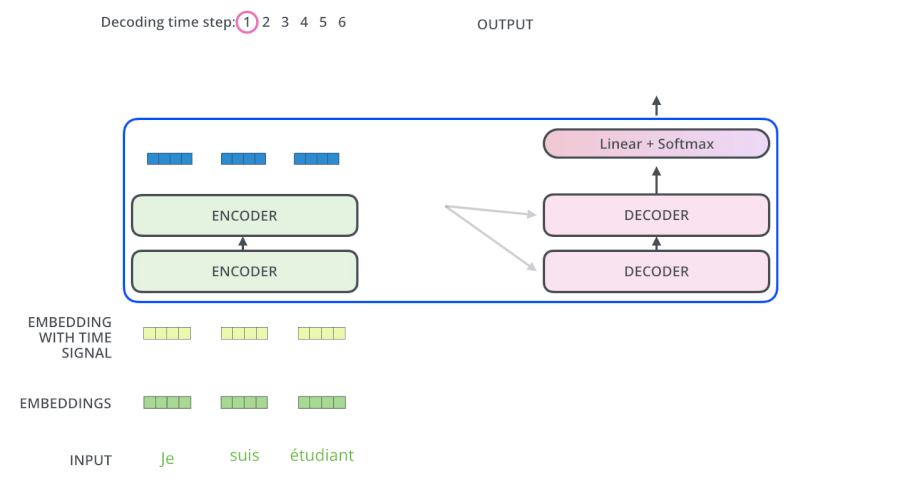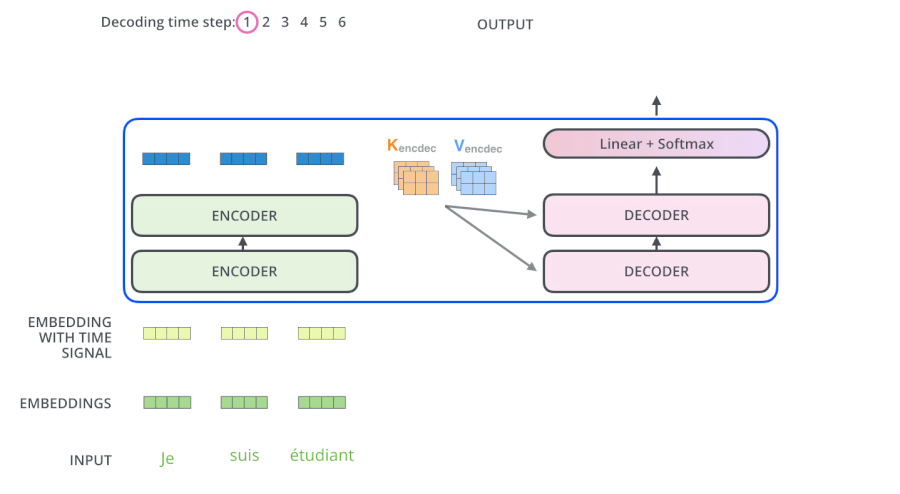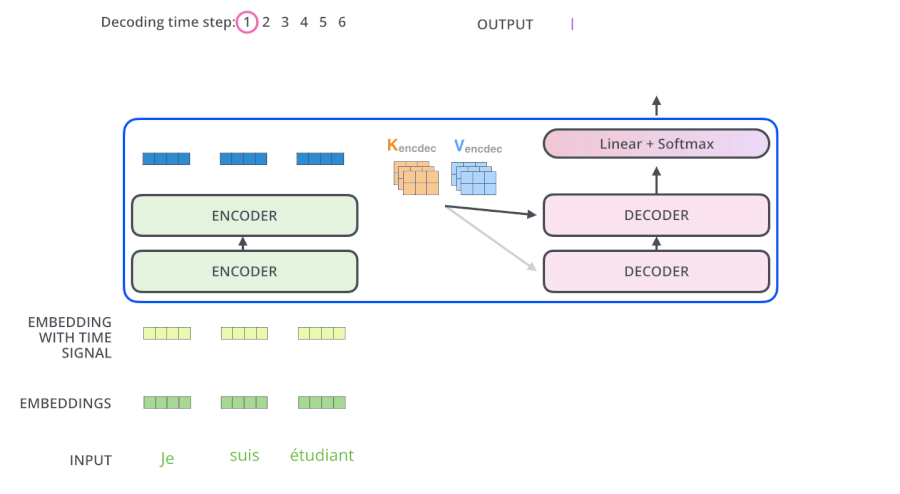
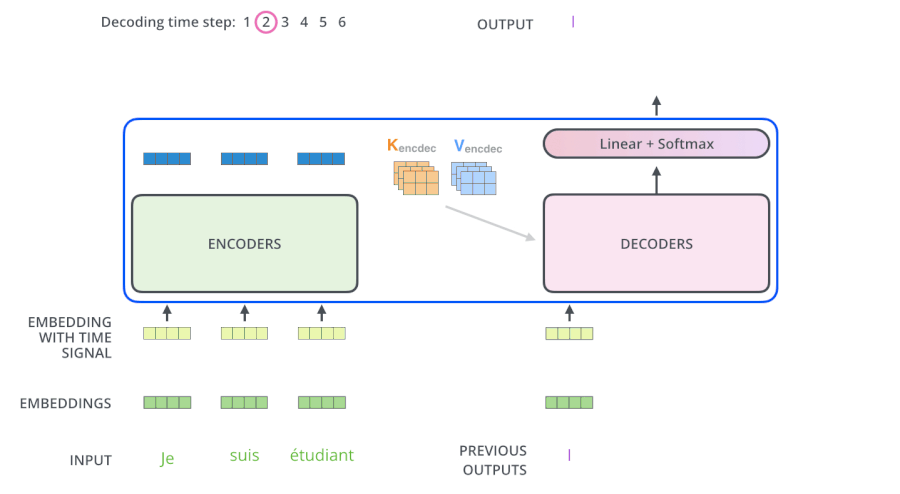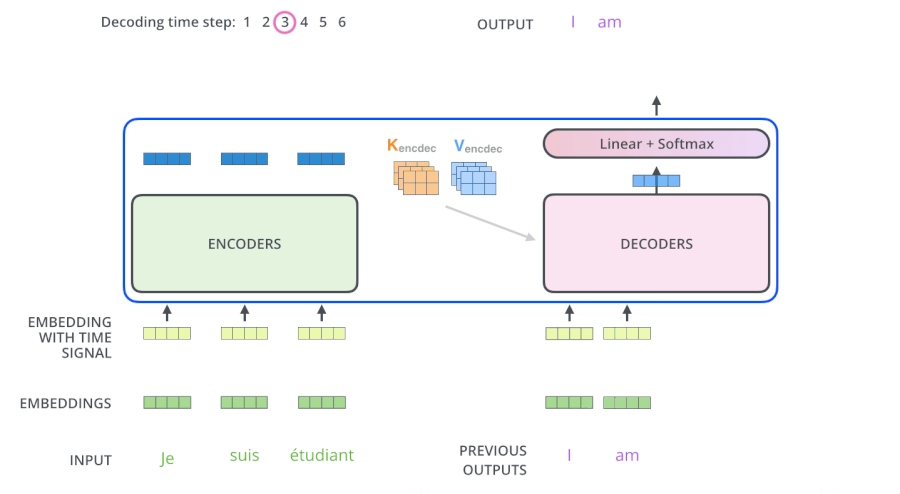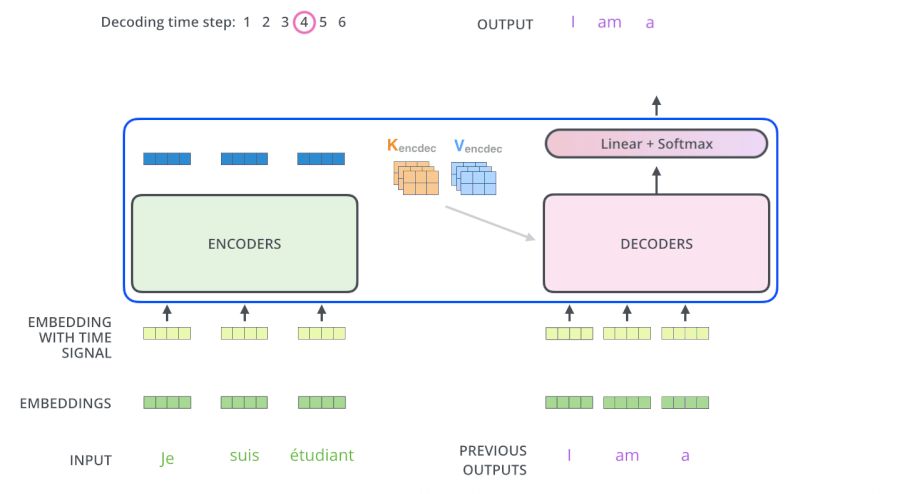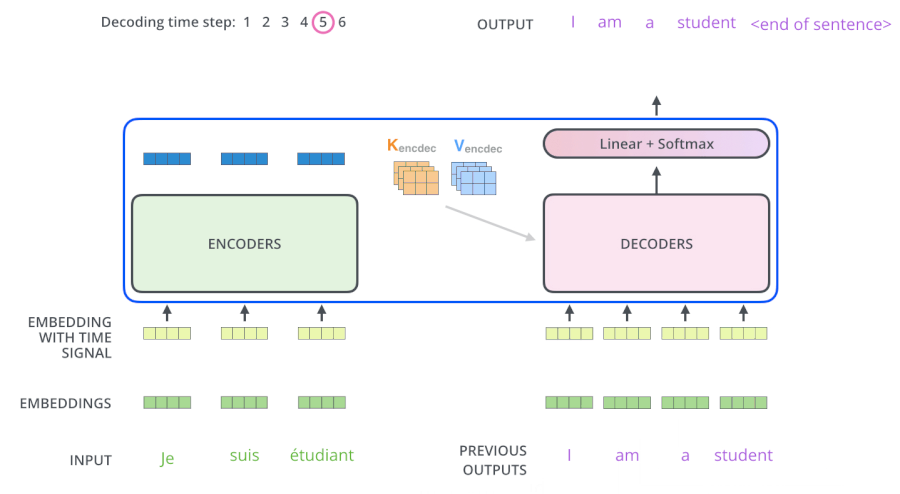
3.6 为什么解码器的Attention要做Mask
- 直接原因:为了解决训练阶段和测试阶段的不匹配(防止过拟合)
- 在 每一步解码时,模型只能利用 已经生成的部分 预测下一个单词,不能偷看未来单词,否则就相当于直接把答案输入模型了,模型会学得特别“投机取巧”。
- 训练阶段:解码器会有输入,这个输入就是目标语句,比如还是翻译任务,源语句是“我是一名学生”,目标语句是"I am a student",在训练阶段中,"I am a student"会输入到解码器(每一次都会把句子的所有信息告诉解码器)
- 测试阶段:解码器也会有输入,但测试的时候不知道目标语句是什么,只会每生成一个词,就会多一个词放入目标语句,比如在计算am的注意力时,能看到的只有“I”这个词。即计算单词依赖度时,只使用当然单词即其之前单词的词向量,看不到后面单词
- 所以Mask解决了:在训练阶段时,也像测试阶段一样,生成第一个词时啥也不告诉你,生成第二个词时,告诉你第一个词....
3.7 为什么Encoder给予的是KV矩阵⭐
-
观察结构图,可以发现一个解码器中有两个Attention层,第一层为Mask多头,第二层为多头,这两层Attention的QKV也都是不同的
-
第一层Mask多头,其QKV是由目标语句的词向量分别乘可训练的矩阵WQ、WK、WV得到的
-
第二层多头,KV矩阵是编码器给予的,Q矩阵是上一层(Masked Self-Attention)的输出
-
之前说过Q是查询变量,在这个例子中,就是已经生成的词
-
K = V是源语句
-
当我们生成词的时候,通过已经生成的词和源语句做自注意力,就是确定源语句中哪些词对接下来词的生成更重要


 浙公网安备 33010602011771号
浙公网安备 33010602011771号