scrapy框架使用一(理论部分)
1.scrapy框架使用步骤
快捷键 shift+鼠标右键 可以直接在文件夹处打开powershell,从而指令命令
1.创建scrapy项目 命令:scrapy startproject 爬虫名
2.明确要爬取的目标 在items.py文件里面定义要爬取的字段
3.制作爬虫 命令:scrapy genspider 爬虫文件名 '域名'(真正写爬虫代码的地方)--》要在项目的一级目录(包含全局配置文件的目录)下面使用这个命令 直接在这个文件里面写spider的内容
4.管道处理 piplines.py定义本地存储形式
5.执行项目 命令: scrapy crawl 爬虫标识名(在spider的主要文件里面本例是m.py里面)
[ 6.执行项目并生成json文件 命令 scrapy crawl 爬虫标识名 -o *.json (和5只用一个就行) ]
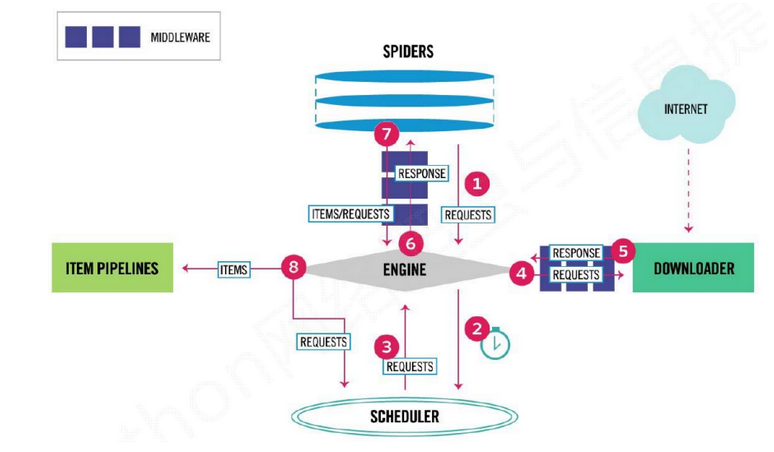
2.scrapy框架结构图(每一过程都要经过scrapy engine爬虫引擎)
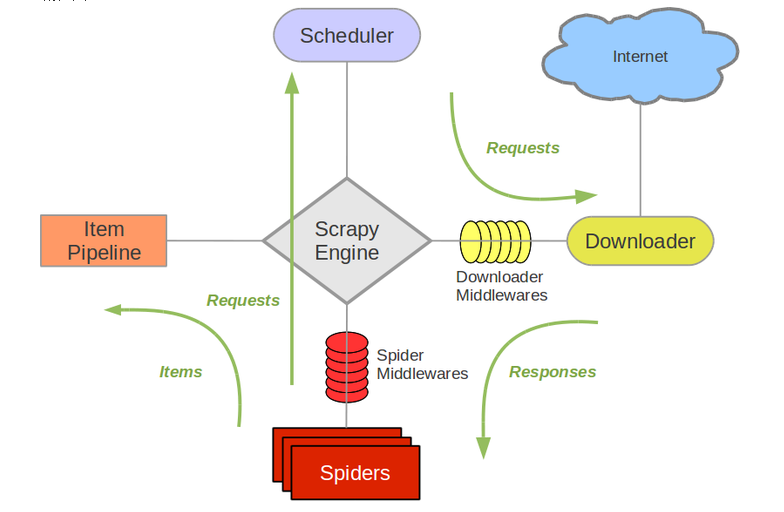
执行流程图:
Scrapy框架模块功能
- Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。一般都是队列,用来排序request请求
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
我们实际操作的只有spider部分,items.py部分,piplines.py部分,请求的发起,和响应都有框架控制,
我么的工作:我们只负责控制输入url,和直接使用爬取的结果response,以及定义结果保存形式和保存位置。
spider部分是scrapy框架创建第三步生成的文件,用来写request请求,start_urls,name,allow_domain3个字段。
3.生成的scrapy项目文件结构如下:以一个实例为基准
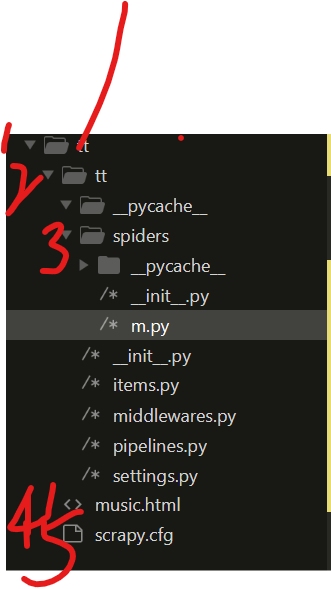
文件结构
项目名
项目名
__py_cache__
spiders (里面的在scrapy第三步的命令生成的·文件放着里面,这个是m.py--》》用来写request参数的文件)
__pycache__
__init__.py
m.py
scrapy.cfg (全局配置文件)
music.html (可能是piplines.py生成的用来保存结果的文件) ------>>>> 不是必须有的,一般这个都是结果生成的
第一部分 1 是创建scrapy第一步生成的项目名 scrapy startproject tt
第二部分 2和5,是创建完项目就自动生成的,
第三部分 3 是中的m.py是创建scrapy的第三步生成的文件,用来提供request的url参数,爬虫标识名name,域名allow_domain,和也是爬虫的主文件(主要要写的地方) scrapy genspider m '域名'
第四部分 4 是用来存放结果,在程序执行中生成的文件(自己创建的)
注意事项:要使用管道的话,要在settings.py里面配置,管道的配置 不配置settings.py这里,管道不好使。

这里配置管道的优先级,当有多个管道时,(每个管道就是piplines.py里面的一个类),优先级从0-1000,数字越小优先级越高,这里默认是300.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号