
吴恩达:深度学习作业2相关
深度学习小知识点:(欠拟合与过拟合)
1.出现欠拟合应该怎样解决:(欠拟合就是模型没能很好的捕捉到数据的特征,不能很好地拟合数据)
欠拟合的情况如图所示:
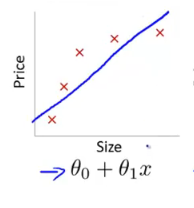
a.增加特征项,出现欠拟合的原因一般是特征项不够造成的,只有增加更多的特征,网络才能学习到数据中更多的信息,一般的可以描述特征的包括“上下文特征”,“位置特征”等一些其它的特征。在日常的工作中,可以从其它的任务那得到灵感,模仿其它的工作中所用的特征项,然后把这个特征项用在自己的任务中,说不定会有提升。
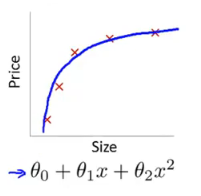
b.添加多项式特征。例如上图,此时拟合的函数是一个一次的函数,我们可以添加一个二次项和一个三次项,使拟合曲线变为下图所示的这样,提升模型的泛化能力。
c.减少正则化参数。因为一般防止过拟合就会增加正则化参数。所以现在欠拟合就应该减少正则化参数。
2.出现过拟合应该怎样解决:(过拟合是指模型为了把训练集中的数据每个都划分正确,学习到了噪声数据的特征。)
过拟合的情况如图所示:
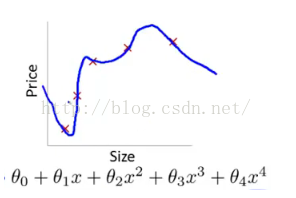
a.清洗数据。造成过拟合的原因有可能是训练数据中混入了噪声数据,所以对数据进行重新清洗,可能会缓解过拟合的现象。
b.增大数据的训练量。过拟合很可能是由于数据数量过少造成的,难以学到有用的特征,反而学到了噪声数据的特征,所以可能增大数据量。
c.采用正则化。正则化方法包括L0,L1,L2正则化,L2正则化又被称为权值衰减(weight_decay),正则一般是在目标函数后加范数,,,
d.采用dropout.dropout是指在训练的时候随机让某些神经元暂时不工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号