
【System Beats!】第六章 存储器层次结构
随机访问存储器(Random-Access Memory/RAM)
- 定义:允许通过特定地址在常数时间内读写数据的存储器类型
- 有以下特点:
- 速度非常快
- 断电后无法恢复
- 常用于运行时产生数据的存储
- 可以以任意顺序访问存储的数据
- 常说的内存就是RAM的一种
- 通常被组织为芯片(clip),每个芯片包含多个存储单元(Cell),每个存储单元存储一个bit。
静态随机访问存储器(SRAM)
- 每个位存储在一个双稳态存储器单元里。
- 双稳态:可以无限期稳定在0/1状态下,不需要补充电荷(持续性)或者刷新。
- 注意是有亚稳态的,这种情况下收到微小扰动就会失衡。
- 每个存储单元由六个晶体管构成。
- 若有干扰扰乱电压,干扰消除时会恢复原值。
- 速度最快(仅次于寄存器堆)
- 价格最高(晶体管更多)
- 常用于高速缓存存储器。
动态随机访问存储器(DRAM)
- 使用电容和一个晶体管放大器(访问晶体管)实现,每个位存储为对一个电容的充电。
- 电荷会逐渐丧失,需要定期刷新来补充电荷。
- 有的系统也使用纠错码,将计算机的字多编码几位。
- 对干扰敏感,电容电压被扰乱后,不会恢复(例如暴露在光照下)。
- 具有较高的存储密度
- 速度相对于SRAM较慢
- 价格相对SRAM较低
- 访问时间相对SRAM较长
- 主要应用于主存、帧缓冲区等。
非易失性存储器
- 随机访问存储器在断电后数据会丢失,即它们是易失的。
- 非易失性存储器被称为只读存储器(Read-Only Memory/ROM),尽管它们有的可读可写。
- 常用于存储固件,即数据的持久性存储,如BIOS(Basic Input-Output System),通常直接烧录在主板上。
- 存储于其中的程序被称为固件,计算机系统通电后会运行存储于其中的固件。
- 部分组件需要它翻译的程序等等。
- 常见的ROM类型:
- 可编程ROM(Programmable ROM/PROM):可以通过高电流熔断熔丝一次性编程。
- 可擦写可编程ROM(Erasable Programmable ROM/EPROM):有透明石英窗口,通过紫外线(UV)或者X射线擦写,最多可擦写1000次。
- 电子可擦除ROM(Electrically Erasable PROM/EEPROM):无须物理独立编程设备,直接在印制电路板上编程,擦写次数大约为10万次。
- 闪存(Flash Memory):广泛应用于固态硬盘(Solid State Disk/SSD)等外部存储设备。
DRAM的组织形式
- DRAM芯片被分为 \(d\) 个超单元(Supercell)。
- 每个超单元被分为 \(w\) 个DRAM单元(Unit)。
- 通常,一个超单元存储一个字节(Byte),每个单元存储1位(bit)。
- 一个 \(d \times w\) 的DRAM总共存储了 \(dw\) 位信息。
- 超单元被组织为一个 \(r \times c\) 的长方形序列,其中 \(d = rc\) 。
- 通过行和列的索引进行寻址。
- 每个引脚携带一个一位的信号。
- 通常通过
address引脚传入地址,在DRAM单元序列中通过data引脚输出数据。 - 通常重复利用
address引脚进行二维访存(非线性是为了降低芯片上地址引脚数量)。 - 读内存:
- 内存控制器将行地址(RAS/Row Access Strobe) \(i\) 发送到DRAM,然后是列地址(CAS/Column Access Strobe) \(j\) 。
- RAS和CAS共享相同的DRAM地址作引脚。
- 收到RAS后,将该行的数据加载到行缓冲区中,然后通过CAS从行缓冲区提取所需的数据作响应。
- DRAM把超单元 \((i,j)\) 的内容发回到控制器作为响应。
- 为了提高性能,内存模块通常会将多个DRAM芯片并行化,每个芯片存储1字节。
- 当处理一个字时,可以同时访问多个芯片,提高数据吞吐量。
- 8个8M \(\times\) 8的64MB内存模块:
- 8个DRAM芯片
- 每个芯片由8M个超单元组成
- 每个超单元携带8位数据
- 总容量 \(8 \times 8M \times 8 \ bit=64MB\)
增强的DRAM
- 快页模式DRAM(FPM DRAM):
- 允许对同一行连续访问可以直接从行缓冲区得到服务。
- 当访问同一行的多个超单元时,只需要将该行的数据加载到缓冲区一次。
- 之后的数据访问可以直接从缓冲区中获取,无须重新加载。
- 拓展数据输出DRAM(EDO DRAM):
- 相对FPM DRAM,改进了CAS信号的时序,使得数据传输更紧密,提升了访问速度。
- 同步DRAM(SDRAM):
- FPM和EDO DRAM都是异步的,就与内存控制器使用一组显式控制信号来说。
- 通过时钟信号同步操作(始终上升沿),避免CPU和存储器之间的协调问题。
- 支持行地址和列地址的分离访问,提升了内存访问效率。
- 双倍数据速率同步DRAM(DRR SDRAM):
- 通过在时钟的上下沿都进行数据读写,实现每个周期读写两倍的数据。
- DDR2、DDR3及之后的版本采用了预取技术,进一步提高性能。现在最先进的是DDR5版本。
- 视频RAM(VRAM):
- 用于图形系统的帧缓冲区中。
- 输出是依次对内部缓冲区的整个内容进行移位得到的。
- 允许对内存并行地读写。
访问主存
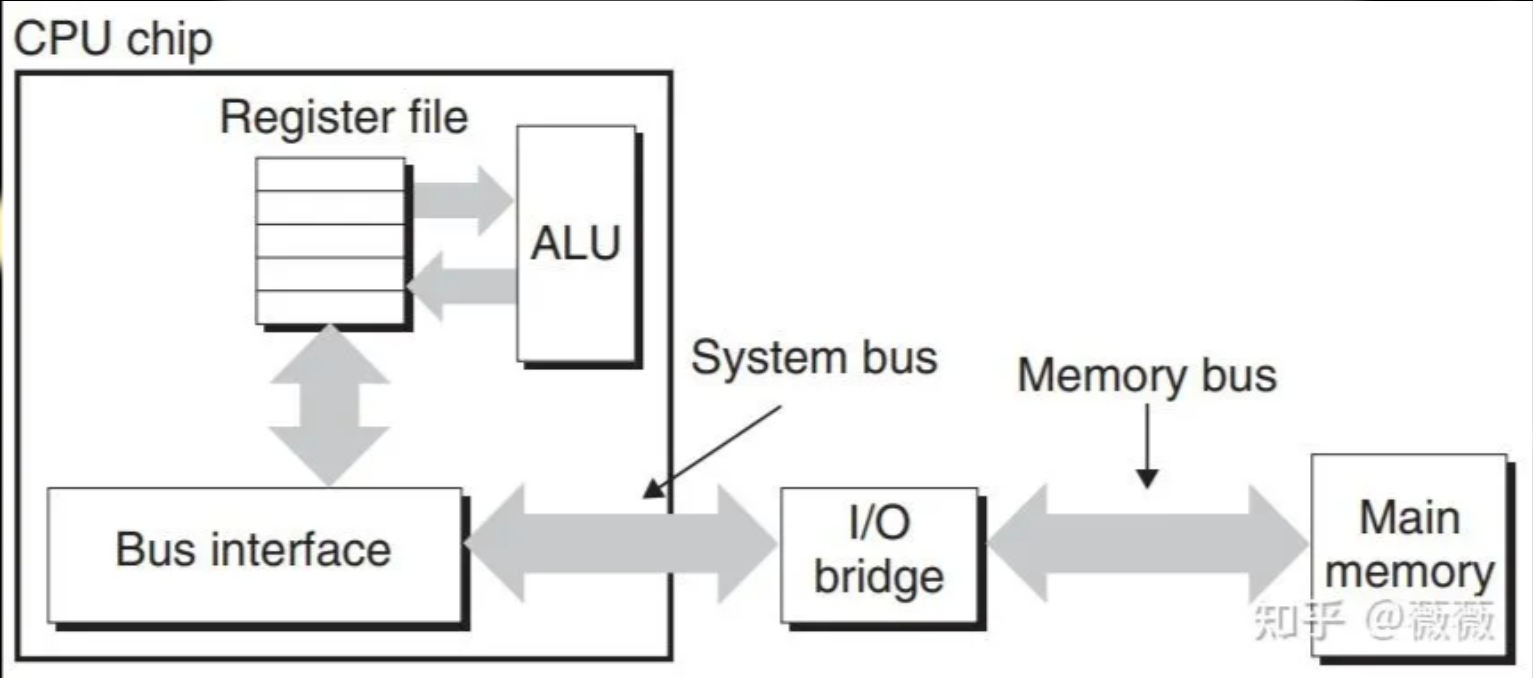
- 总线(Bus)是一条并行电路,由多条并行导线构成,用于在计算机各个部件中传输指令、数据、地址和控制信号。
- CPU和主存之间的数据传送被称为总线事务,分为读事务和写事务。
- 数据和地址信号可以共享同一组导线,也可以使用不同的。
- 两个以上的设备也能共享同一组总线。
- 控制线携带的信号会同步事务,并标识出当前正在被执行的事务的类型。
- 系统总线(System Bus):连接CPU和I/O桥接器。
- 内存总线(Memory Bus):连接I/O桥接器和主存。
- I/O总线:将I/O设备连接到I/O桥上,它们共享I/O总线。
- 读事务:
- CPU上的总线接口(Bus Interface)发起读事务。
- CPU将地址 \(A\) 放到系统总线上,I/O桥接器将信号传递到内存总线。
- 主存感知到内存总线上的地址信号,从内存总线读地址,从DRAM取出数据字,将数据写到内存总线。
- I/O桥将内存总线信号翻译为系统总线信号,沿着系统总线传递。
- CPU感知到系统总线上的数据,从总线上读数据,将数据复制到寄存器。
- 写事务:
- CPU将地址放到系统总线上,内存从系统总线读出地址,等待数据到达。
- CPU将数据复制到系统总线,通过I/O桥接器翻译。
- 主存从内存总线读出数据,并将其存储到DRAM中。
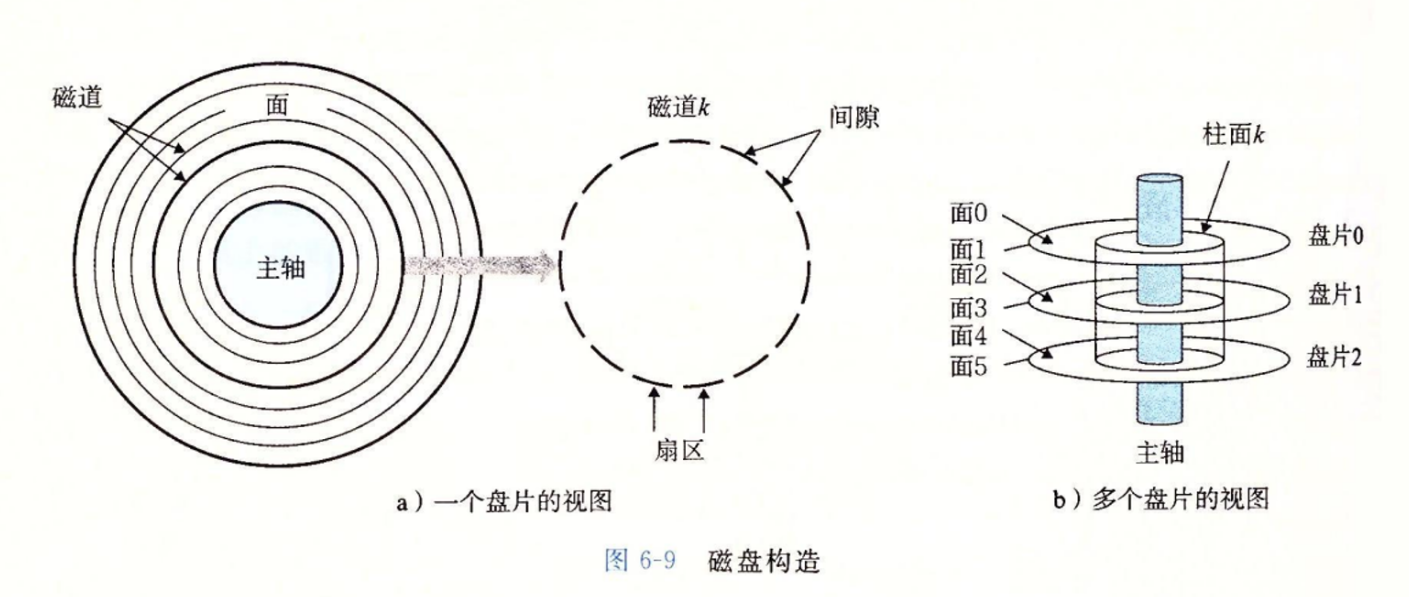
磁盘(Magnetic Disk)/机械硬盘
- 非易失性存储器,断电后数据不丢失。
- 容量数量级:
GB-TB。 - 访问时间:
ms级别。 - 使用磁信号存储数据,由多个
盘片组成。 - 每个盘片有两面称为
表面,都有数据可读写。 - 中央有一个旋转的
主轴,使得盘片以固定旋转速率旋转。 - 磁道:盘面上同一半径的圆周,每一盘面有多个磁道。
- 扇区:每个磁道被分为多个扇区,每个扇区包含相等数量的数据位(通常512字节)。
- 扇区中间有间隙,不存储数据位,用于表示扇区的格式化位。
- 磁盘由一个多个叠放在一起的盘片组成的,它们被封装在一个密封的包装里。
- 整个装置被称为磁盘驱动器,简称为磁盘/旋转磁盘。
- 柱面:所有表面上半径相同的磁道集合构成一个柱面,磁盘上所有的读写头都位于同一柱面上。
磁盘容量
- 一个磁盘可以记录的最大位数称为它的最大容量,简称为容量。
- 决定容量的因素:
- 记录密度(位/英寸):磁道一英寸的段中可以放入的位数。
- 磁道密度(道/英寸):从盘片出发半径上一英寸的段内可以有的磁道数。
- 面密度(位/平方英寸):记录密度和磁道密度的乘积。
- 传统方法:每个磁道都分为相同数量的扇区,则扇区数目由最内磁道决定的,同时外周磁道会有很多空隙。
- 若每个磁道的扇区数都不相同,读写的复杂度会急剧上升。
- 多区记录方法:
- 将柱面分为若干组
- 每组内部采用相同的扇区数,不同组间扇区数可能不同。
- 能有效利用空间。
- 磁盘容量=盘片数 \(\times\) 盘片表面数 \(\times\) 磁道数 \(\times\) 扇区数 \(\times\) 扇区比特数
- 制造商通常以千兆字节(GB)或者兆兆字节(TB)为单位表达磁盘容量。
- DRAM/SRAM容量:
- \(K=2^{10}\)
- \(M=2^{20}\)
- \(G=2^{30}\)
- \(P=2^{40}\)
- 磁盘和网络等I/O设备容量计量单位:
- \(K=10^3\)
- \(M=10^6\)
- \(G=10^9\)
- \(T=10^{12}\)
- 即内存(含)及以上(更快):使用2的幂次作为单位
- 内存以下(更慢):使用10的幂次作为单位
磁盘读写
- 对于高速旋转的磁盘来说,任何灰尘都有巨大的冲量,称为读\写头冲撞。
- 寻道(Seek):磁盘的读写头移动到对应的柱面/磁道上。
- 旋转(Rotation):磁盘转动到文件的初始位置。
- 数据转移(Transfer):读写头开始读入数据,同时磁盘保持旋转。
- 对扇区的访问时间主要分为以下三部分:
- 寻道时间(\(T_{seek}\)):传动臂定位所需的时间,依赖于读写头以前的位置以及传动臂移动速度。
- 旋转时间(\(T_{rotate}\)):定位到磁道后等待目标扇区的第一个位,依赖于读写头到达目标扇区时的位置以及磁盘旋转速度。
- 最差情况为 \(\frac{1}{\mathrm{RPM}} \times 60s/min\)。
- 传送时间(\(T_{transfer}\)):读写时间,依赖于传送速度以及每条磁道的扇区数目。
- 寻道和旋转的时间通常占据大部分时间,且这两者时间相当。
逻辑磁盘块
- 对操作系统隐藏物理磁盘的复杂性,因此创造出逻辑块。
- 编号为 \(0,1,\ldots,B-1\)。
- 磁盘控制器维护逻辑块与物理磁盘扇区的关系。
- 磁盘控制器会将一个逻辑块号翻译为(盘面,磁道,扇区)的三元组。
- 磁盘控制器需要对磁盘进行格式化,然后才能在该磁盘上存储数据。
- 格式化填写扇区间隙,标识表面有故障的柱面并且不使用他们。
- 留有一些备用的柱面,因此磁盘的实际容量略小于最大容量。
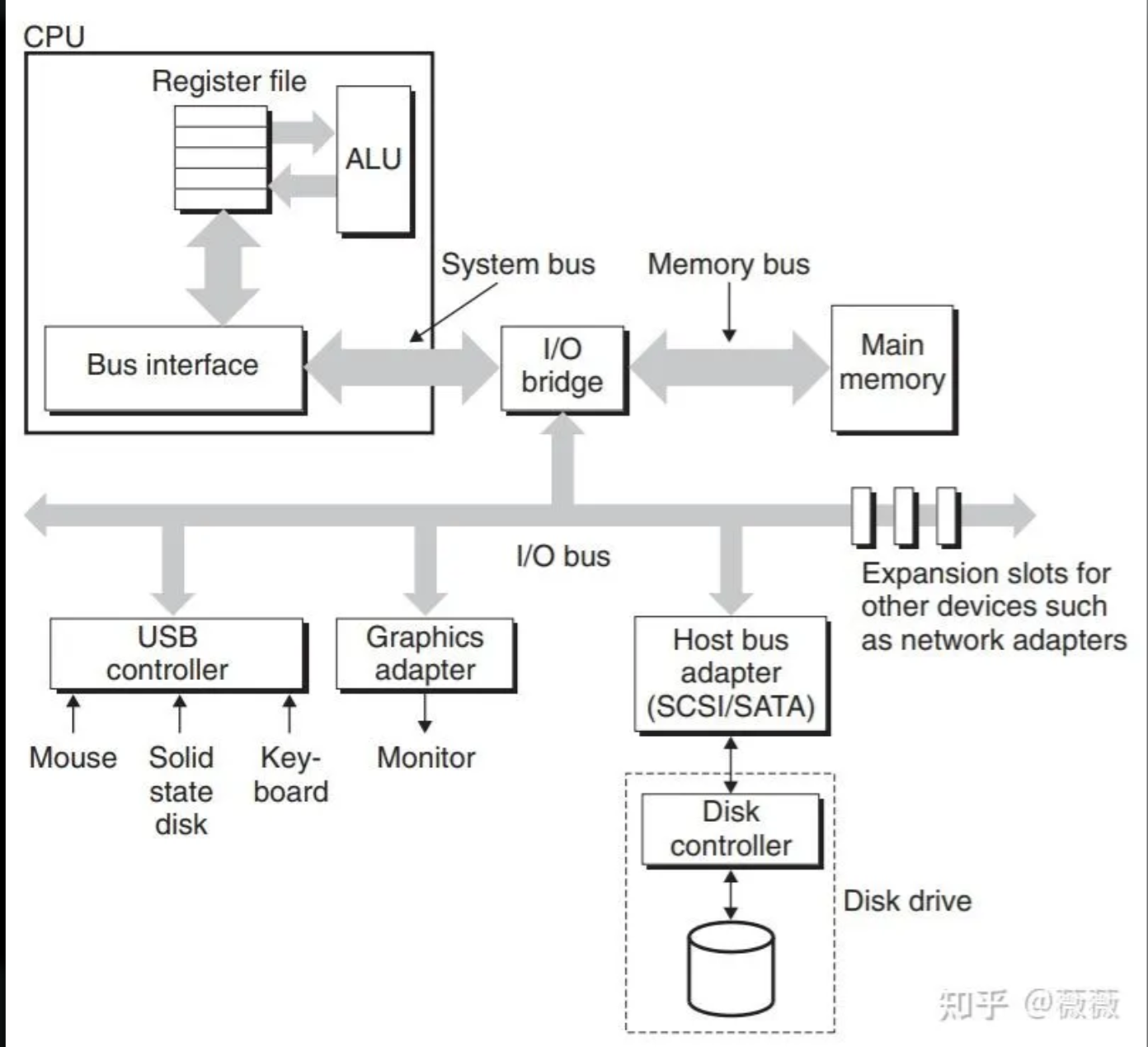
连接I/O设备
- I/O设备,例如鼠标键盘等,都是通过I/O总线(例如Intel的外围设备互联(PCI)总线)连接到CPU和主存的。
- 常见的I/O设备包括USB控制器、图形适配器和硬盘控制器。
- I/O总线与底层CPU无关,比系统总线和内存总线慢。
- 三种不同类型的设备连接到主线:
- 通用串行主线(Universal Serial Bus/USB)控制器:连接到USB总线的设备的中转站。
- 图形卡/适配器:包含硬件、软件逻辑,代表CPU在显示器上画像素。
- 主机总线适配器:将一个或多个磁盘连接到I/O总线,使用特殊的主机总线接口定义的通信协议。
- 两个常用的磁盘接口:
- SCSI:更快,更贵,可以支持多个磁盘驱动器。
- SATA:更慢,更便宜,只能支持一个驱动器。
- 还有网络适配器等,它可以将适配器插入到主板上空的拓展槽中,以连接到I/O总线。
- 这些插槽提供了到总线的直接电路连接。
- PCI模型中,系统中所有设备共享总线,一个时刻只能有一台设备访问这些线路。
- 现代系统中,PCI已经被PCEe取代,是一组高速串行、通过开关连接的点到点链路。
- 不同总线之间的区别对应用程序来说是不可见的。
访问磁盘
- CPU使用内存映射I/O(Memory-mapped I/O)技术向I/O设备发射命令。
- 地址中有一块地址是为与I/O设备通信保留的,每个这样的地址被称为一个I/O端口(I/O Port)。
- 一个设备连接到总线时,它与一个或多个端口关联。
- 外存设备(硬盘、SSD等),与CPU之间的读写操作不同步,因此需要通过中断机制(Interrupt)来通知CPU操作完成。
- 磁盘读:
- CPU发送一个关键字,告诉磁盘发起一个读。
- 包括其他参数,比如读完成时是否中断CPU。
- 再指明应该读的逻辑块号。
- 最后指明应该存储磁盘扇区内容的主存地址。
- 磁盘进行读时,CPU会执行其他工作。
- 磁盘收到读命令时,将逻辑块号翻译为扇区地址,读取其内容。
- 随后直接传送到主存,无须CPU干涉。
- 这被称为直接内存访问(Direct Memory Access,DMA),提高数据传送效率。
- 这种数据传送被称为DMA传送。
- DMA传送完成后,磁盘控制器给CPU发送一个中断信号。
- 它会发送到CPU芯片的一个外部引脚上,会导致CPU停止当前正在做的工作。
- 它会跳转到一个操作系统例程,这记录下I/O已经完成,控制返回到CPU中断的地方。
- 随着CPU、SRAM、DRAM以及外存之间频率差异的增大,存储器层次结构的设计变得尤为重要。
固态硬盘(SSD)
- 是一种基于闪存的存储技术,传统旋转磁盘的替代品,通常贵于传统旋转磁盘。
- 一个SSD封装由一个或多个闪存芯片和闪存翻译层组成,闪存芯片相当于机械驱动器,闪存翻译层相当于磁盘控制器。
- 闪存由多个闪存块(Block)组成,每个快包含多个闪存页。
- 闪存页(Page),每个页包含 \(512B \sim 4kB\)数据。
- 读SSD速度比写SSD快,顺序访问比随机访问快。
- 数据以页为单位读写,只有在一页所属的块被擦除(通常全置1)后,才能写入。
- 写操作之间需要先复制页内容(如果有的话)到新块,再擦除旧块。
- 一旦一个块被擦除了,其中的页不需要再次擦除就可以直接写。
- 优点:SSD没有移动部件,功耗较低,抗震性较强。
- 缺点:SSD的写入次数有限,每个Block大约只能承受10万次擦写,并且成本比机械硬盘贵。
- 价格:SRAM>DRAM>SSD>磁盘
局部性
- 程序倾向于使用刚用过的数据以及其附近的数据,前者为时间局部性,后者为空间局部性。
- 请看以下代码:
int sum(int v[N]){
int i,sum=0;
for(i=0;i<N;i++) sum+=v[i];
return sum;
}
- 每次循环都写入一个累加变量,体现时间局部性。
- 访问的数组在内存中处在相邻地址,体现空间局部性。
- 指令也是数据的一种,因此指令也有局部性。
- 即:指令按顺序执行,例如
for循环,具有良好的时间(循环体、循环变量复用)和空间局部性(循环内部指令连续)。 - 步长为 \(k\) 的引用模式:每隔 \(k\) 个元素进行访问,步长越短,空间局部性越强。(注意行访问优于列访问)
- 循环次数越多越好,循环体越小越好。
存储器层次结构
- 随着CPU、SRAM、DRAM以及外存之间频率差异的增大,存储器层次结构的设计变得尤为重要。
- 综合存储技术和局部性,得到存储器层次结构:
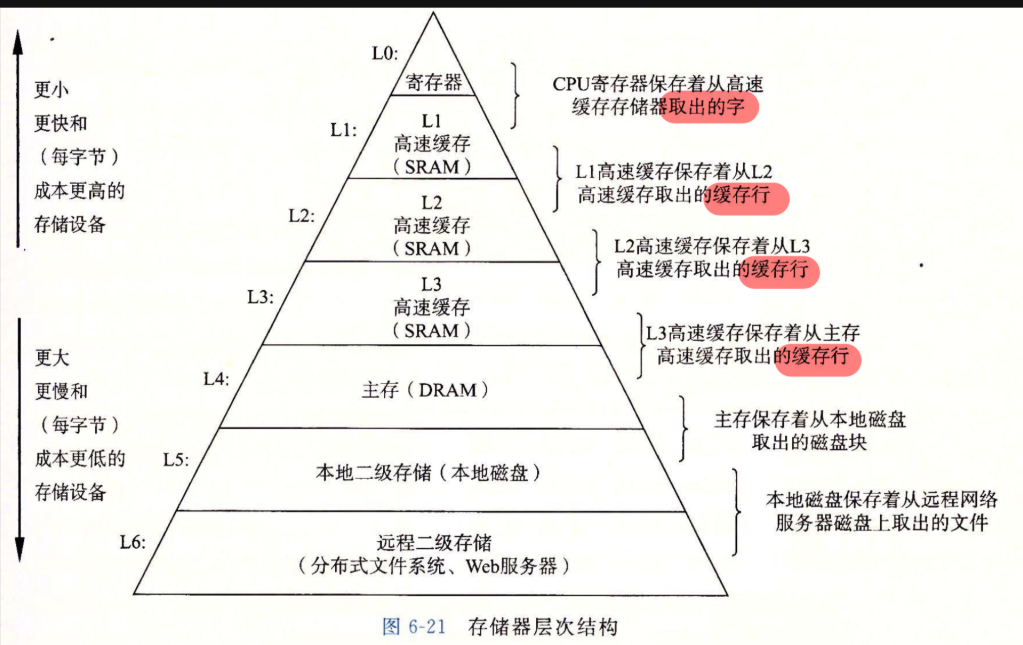
- 越靠近CPU的存储器,速度越快,单位比特成本越高,容量越小。
- 越远离CPU的存储器,速度越慢,单位比特成本越低,容量越大。
- 该架构遵循局部性原理,随着层级升高,访存的时间成本增大,因此块的大小也变大。
- 在该层次结构中,还可能存在磁带等等层级。
- 使用 \(L_k\) 作为 \(L_{k+1}\) 的缓存
- 缓存命中:能找到,就不需要访问 \(L_{k+1}\)
- 缓存不命中:找不到,去访问 \(L_{k+1}\),此时需要复制,耗时较长。
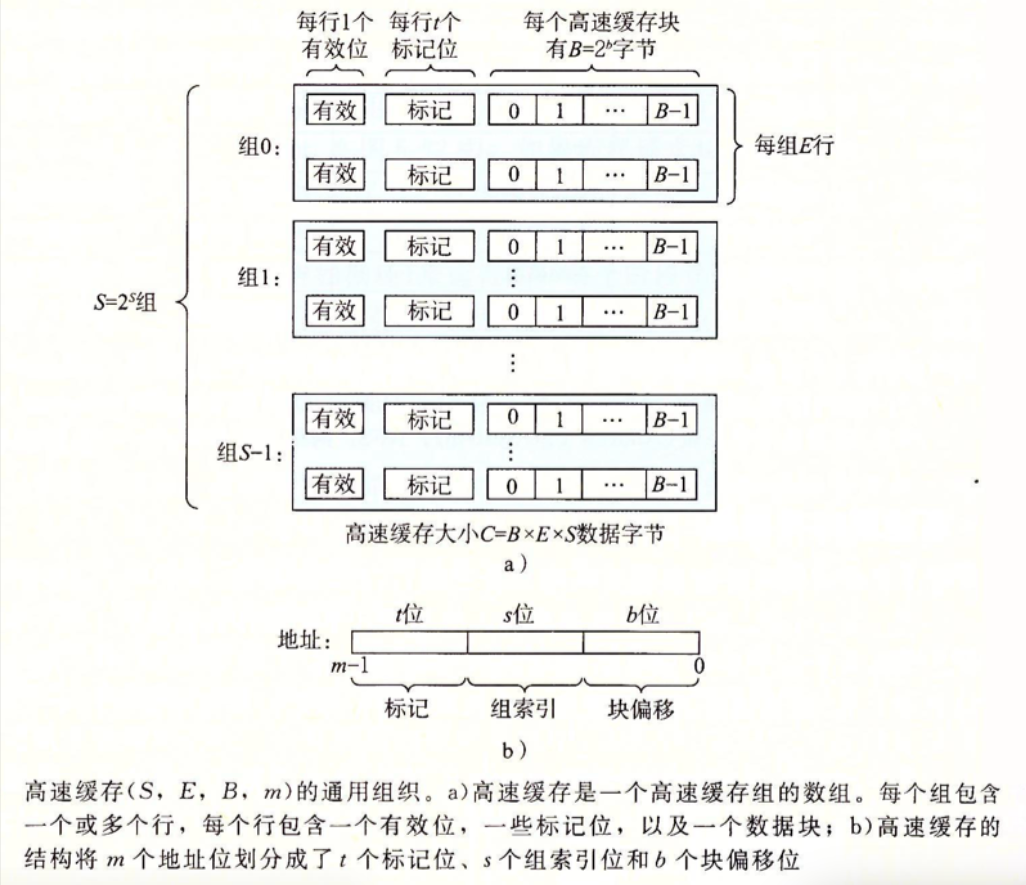
高速缓存/Cache
- 是存储在更大、更慢的设备中的数据对象的缓冲区域,使用其的过程称为缓存。
- 它需要记录块中的数据,以及对应于主存中的哪个块。
- 在Cache中通过行(Line)组织数据。
- 一条缓存行由一个有效位记录其中数据是否有效。
- 由标记(Tag)记录其对应主存中的哪个块。
- 其余部分存储块中的数据。
- 数据是以块大小为传送单元在缓存和下层之间来回复制的,越远离CPU块越大。
缓存的组织
- 一个计算机系统,每个存储器地址有 \(m\) 位,形成 \(M=2^m\) 个不同的地址。
- 高速缓存的组数:\(S=2^s\),决定地址索引字段长度。
- 高速缓存的相联度:\(E\),每组包含的缓存行数。
- 高速缓存的块大小:\(B=2^b\),决定块便宜的字段长度。
- 每个行有1个有效位(Tag bit):指明该行是否包含有意义的信息。
- 每个行有\(t=m-(b+s)\)个标记位,用于标识存储在该高速缓存行中的地址。
- 每个行有\(b\)个数据块,\(B=2^b\)字节,用于存储实际数据。
- 总容量(Capacity): \(C=B \times E \times S\) 字节,不包含标记位和有效位。
- 缓存地址:
- 一个地址,总共 \(m\) 位,从高位到低位划分:
- 标记位:t
- 组索引:s
- 块偏移:b
- 小写符号是位数,大写符号是总数。
- 注意行和块其实指的是同一块区域,两者为了方便有时候会混用。
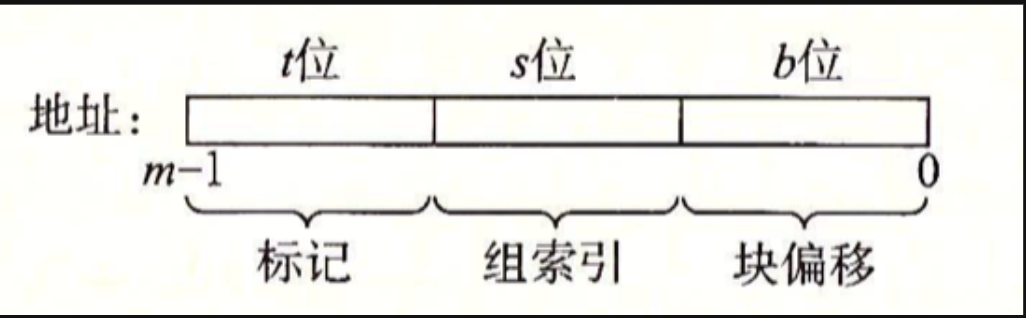
- 缓存地址划分的原因:
- 块偏移:希望两个相邻的字节在同一个块内,空间局部性更好。
- 组索引:希望相邻的块可以放在不同的组内,减少冲突不命中。
- 标记:利用地址的唯一性,将剩下的位数作为标记,用于区分分在同一组的块。
- 这被称为中间比特索引,符合局部性原则。
- 即将相邻的数据块映射到不同的组中,避免挤占同一个组。
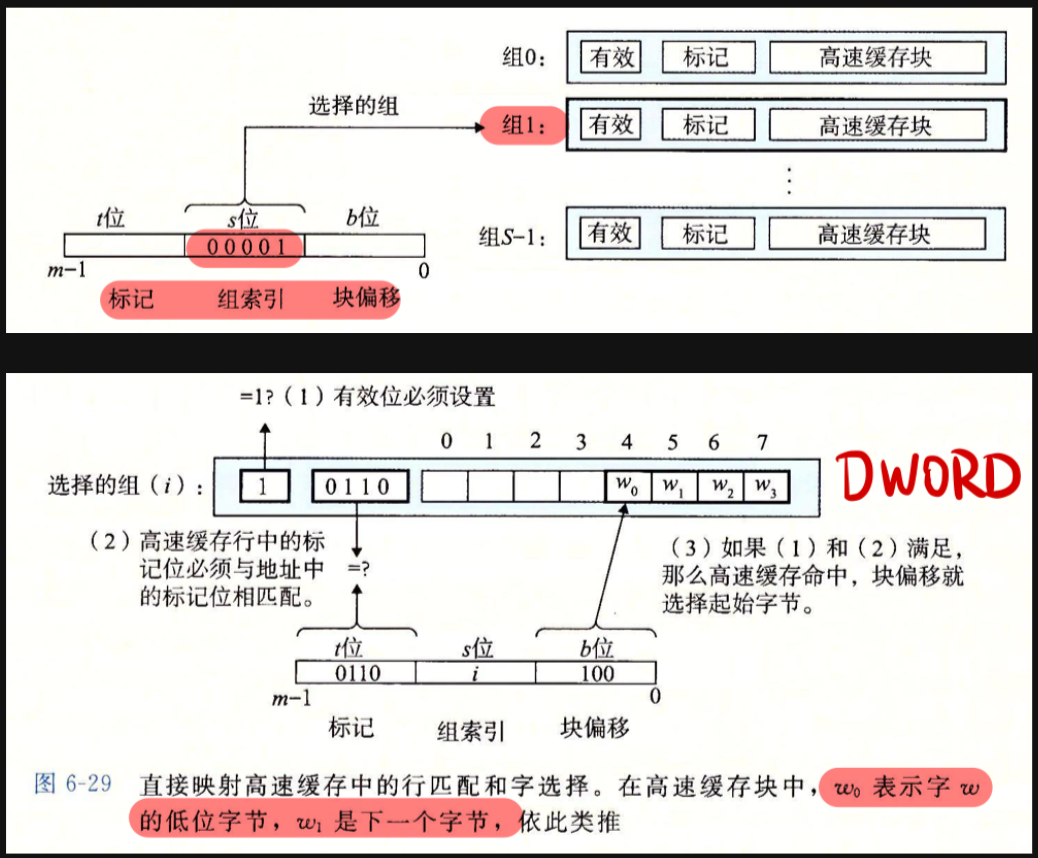
缓存寻址:
- 地址解码:提取索引位、标记位和块偏移。
- 组选择:根据索引定位目标缓存组。
- 行匹配:并行比对所有行有效位有效并且标记为匹配的缓存行。
- 字抽取:若存在命中,则返回该行数据。
- 行替换/驱逐:选择一个现有的块/行驱逐,从低一级存储器中读取新数据放入缓存。
缓存不命中的替换策略:
- 最近最少使用(Least Recently Used,LRU):替换最后一次访问时间最久远的行,硬件成本高。
- 最不常使用(Least Frequently Used,LFU):替换过去某个时间窗口内引用次数最少的行。
- 先进先出(First In First Out):替换最早进入缓存的数据,实现简单而低效。
- 随机替换:随机选择一个进行替换,适用于高相联度场景。
- 三者的具体效果取决于实际情况。
缓存不命中的种类:
- 冷不命中/强制性不命中:数据块从未进入缓存,短暂性,在暖身后不会出现。
- 可以通过判断有效位全为0来实现。
- 缓存暖身:提前把可能会用到的数据加载到缓存中,避免初期频繁的缓存不命中。
- 冲突不命中:由于冲突性放置策略的存在,缓存块的预期位置被其他数据块占据(实际上放得下,工作集小于缓存容量)。
- 这在直接映射中尤为显著
- 冲突性放置策略:
- 随机放置:非常灵活,但也非常昂贵。
- 通过模运算映射等:价格较低,但容易引起冲突不命中。
- 容量不命中:工作集太大了,缓存无法处理这个工作集。
- 抖动:当多个数据频繁被访问,但是无法同时放入缓存中,系统不断在缓存和主存间进行的频繁数据替换。
- 解决方式:可以在数组末尾放置字节填充,从而改变下一个数组的地址(组索引等)。
缓存映射策略:
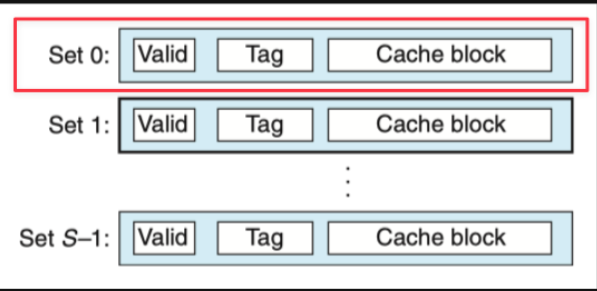
- 直接映射:
- \(E=1\),每个组仅有一行,不止一个组。
- 每个缓存组的这条缓存行负责缓存若干个固定的主存块。
- 相比其他映射策略,硬件最简单。
- 非常容易发生冲突不命中,循环访问同余数地址时,会产生抖动。
- 组相联高速缓存:
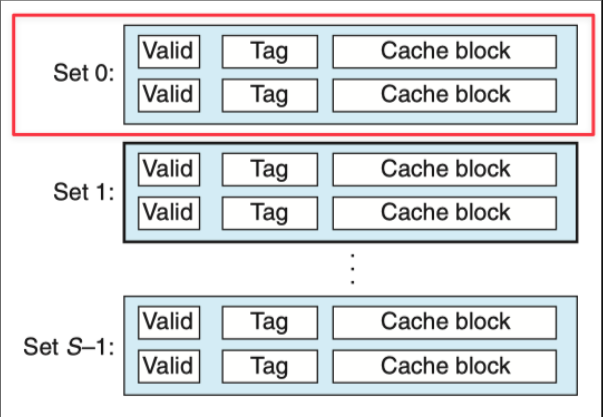
- \(1<E<\frac{C}{B}\)
- 一个缓存组内有多个缓存行,内存块可映射到组内任意行。
- 不止一个组。
- \(E\) 被称为路数,即 \(E\) 路数相连。
- 全相联高速缓存
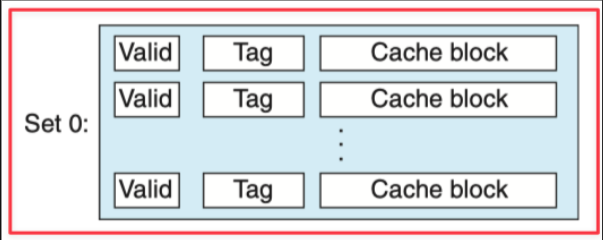
- \(E=\frac{C}{B}\)
- 只有一个组, \(s=0\)
- 所有行可以任意放置,最灵活,最不容易发生冲突不命中。
- 由于需要并行匹配所有行的标记位,硬件难度大,速度慢。
- 通常应用于TLB等小容量关键缓存。
缓存写策略
- 向缓存中写入数据,也分为命中和不命中两种情况。
- 写命中:
- 直写(Write-Through):将新的块同时写入缓存和低一层的存储器中。
- 缺点:每次写都会引起总线流量,而很多写是暂时的,占用大量时间。
- 写回(Write-Back):只写入缓存中的行,每个缓存行额外维护一个修改位(Dirty Bit)。
- 如果有数据提前写入时置为1,若某行需要被替换,检查其修改位,若为1将其数据写回主存。
- 思想类似于延迟标记线段树、懒删除堆。
- 优点:减少主存访问次数,提高性能。
- 缺点:控制电路实现复杂。
- 写未命中:
- 写分配(Write-Allocate):从主存中加载目标块到缓存中,更新这个缓存块。
- 它试图利用写的空间局部性,但每次不命中都会导致一个块从低一层传送到高速缓存。
- 非写分配(Not-Write-Allocate):避开缓存,直接把这个字写到低一层中。
- 直写通常与非写分配分配,写回通常于与写分配搭配。
- 存储器层次结构中较低层倾向于使用写回。
- 写回写分配与处理读的方式对称,它试图利用局部性,可以减少访存次数。
- 现代处理器在L1-L3缓存中普遍使用写回+写分配组合策略,可以减少大量总线传输量。
高速缓存参数的性能影响
- 性能的量化指标,即命中率:\(H=\frac{N_{hit}}{N_{total}}\)
- 不命中率:\(M=1-H\)
- 命中时间:从高速缓存传送一个字到CPU的时间。
- 不命中处罚:因为不命中所需要的额外时间。
- 多级缓存体系下,提高很少的命中率,性能就可能大幅提升。
- 高速缓存大小/C:
- 高度缓存越大,命中率越高。
- 高速缓存越大,命中时间越长,运行相对更慢。
- 块大小/B:
- 较大的块,可以提高空间局部性,提高命中率。
- 较大的块,可能导致时间局部性变差,减少命中率,不命中处罚也更大。
- 相联度/E:
- 相联度较高,降低高速缓存因为冲突不命中出现抖动的可能性。
- 相联度较高,更加复杂,会造成较高的成本,并且很难加速。
- 每一行需要更多的标记位和LRU状态位,命中时间增加了。
- 同时,不命中处罚也增加了,不命中时找到合适的缓存行会花费更多时间。
- 原则是命中时间和不命中处罚之间的折中。
- 写策略:
- 直写高速缓存容易实现,可以使用独立于高速缓存的写缓冲区,用于更新内存。
- 因为不会触发内存写,因此读不命中开销不大。
参考机(Intel Core i7)的缓存
- 其CPU芯片由四个核心组成,采用三级缓存,主要配置如下:
- 块大小统一为64B。
- L1 Cache分为
i-cache和d-cache,分别存储指令和数据,只有d-cache直连到寄存器。 - L1 Cache为32KB,8路,访问4周期。
- L2 Cache:256KB,8路,访问10周期。
- L3 Cache:8MB,16路,访问40-75周期。
编写高速缓存友好的代码
- 让最常见的情况运行得快。
- 尽量减少每个循环内部的缓存不命中数量。
存储器山
- 程序从存储系统中读数据的速率称为读吞吐量/读带宽。
- 吞吐量以兆字节/秒作为单位。
- 反复改变工作集大小(size)和步长(stride),能得到一个读带宽的时间和空间局部性的二维函数,即存储器山。
- 每个计算机都有表明其存储器系统的唯一的存储器山。

存储器山的性能影响
- 步长(Stride)
- 小步长访问,空间局部性好,缓存命中率高,带宽利用率高。
- 步长增加时,空间局部性下降,缓存命中率降低,带宽利用率下降,吞吐量降低。
- 工作集大小(Size)
- 小工作集大小,数据更容易装入上级缓存,缓存命中率高,时间局部性好。
- 工作集大小增加,若超过某一级缓存容量,则更多数据需要从更低级存储读取。
- 使得传输速率下降,吞吐量减低,缓存命中率低,时间局部性差。
- 硬件预取机制
- 指在块被实际访问之前,提前将其加载进高速缓存中。
- 自动识别顺序的、步长为1的引用模式,
- 提前将数据块取到缓存中,减少访问延迟。
- 提高读吞吐量,在步长较小的情况下效果最佳。
重新排列循环以提高空间局部性
- 可以以矩阵相乘为例子,还是注意连续访问。
- 在
Cache Lab中非常重要! - 分块策略:提高内循环的时间局部性。
- 将一个程序中的数据结构组织成的大的片,称为块。
- 构造程序,使得能够将一个片加载到L1中,并且在这个片中进行所需的读写。
- 然后丢掉它,加载下一个片。
- 使得代码更难阅读和理解,可以在没有预取的系统上提高性能。
在程序中利用局部性
- 局部性好的程序从缓存中获取数据,局部性差的程序从DRAM主存中获取数据。
- 建议:
- 将注意力集中在内循环中。
- 按照数据对象存储顺序,步长为1读数据,增大空间局部性。
- 一旦读入一个数据对象,尽可能多使用它,提高时间局部性。
后记
- 终于写完了,累死我了。
- 期中加油啊~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号