

docker compose 部署 zookeeper 高可用故障转移
架构图
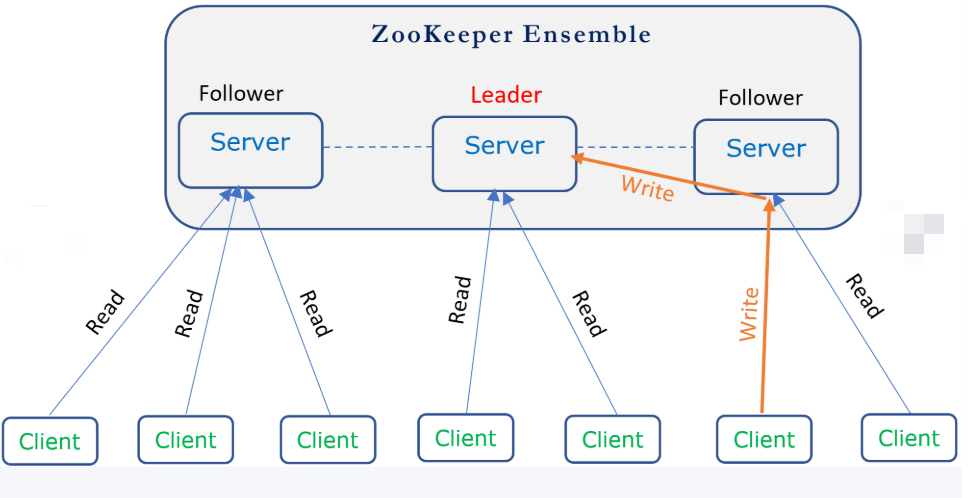
部署zookeeper一主两从
一、创建 Overlay 网络
集群之间走host网络模式 (也可以直接走ip 不影响)
# 在主机 A 上初始化 Swarm(管理节点) docker swarm init --advertise-addr <主机A_IP> # 在主机 B 上加入集群(工作节点) docker swarm join --token <TOKEN> <主机A_IP>:2377
A节点创建overlay网络
docker network create -d overlay \ --subnet=10.200.100.0/24 \ --gateway=10.200.100.1 \ --attachable \ my-net
A节点创建容器 加入到这个my-paasmes新建的网络中。
docker run -d --network=my-paasmes --ip=10.200.100.10 nginx:1.24
B 节点 正常是看不到刚创建的my-paasmes 网络的,有容器使用my-paasmes网络才会显示
B节点 创建一个容器 去ping主节点
docker run -it --rm --network=my-paasmes alpine ping 10.200.100.10一边ping 一边查看docker网络 可以发现, 这个网络有了(新开一个窗口)
二、准备zk集群yml文件
此yml文件是一台启动三个。可以拆开挨个启动即可
version: "3.1" services: zoo1: image: zookeeper:3.9.3 restart: always container_name: zoo1 ports: - "2181:2181" environment: ZOO_MY_ID: 1 ZOO_TICK_TIME: 1000 ZOO_INIT_LIMIT: 3 ZOO_SYNC_LIMIT: 1 maxClientCnxns: 600 standaloneEnabled: false ZOO_MAX_CLIENT_CNXNS: 200 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181 ZOO_AUTOPURGE_PURGEINTERVAL: 1 ZOO_AUTOPURGE_SNAPRETAINCOUNT: 3 volumes: - ./zookeeper/zoo1/data:/data - ./zookeeper/zoo1/datalog:/datalog networks: - my-net
zoo2:
image: zookeeper:3.9.3
restart: always
container_name: zoo2
ports:
- "2182:2181"
environment:
ZOO_MY_ID: 2
ZOO_TICK_TIME: 1000
ZOO_INIT_LIMIT: 3
ZOO_SYNC_LIMIT: 1
maxClientCnxns: 600
standaloneEnabled: false
ZOO_MAX_CLIENT_CNXNS: 200
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_AUTOPURGE_PURGEINTERVAL: 1
ZOO_AUTOPURGE_SNAPRETAINCOUNT: 3
volumes:
- ./zookeeper/zoo2/data:/data
- ./zookeeper/zoo2/datalog:/datalog
networks:
- my-net
zoo3:
image: zookeeper:3.9.3
restart: always
container_name: zoo3
ports:
- "2183:2181"
environment:
ZOO_MY_ID: 3
ZOO_TICK_TIME: 1000
ZOO_INIT_LIMIT: 3
ZOO_SYNC_LIMIT: 1
maxClientCnxns: 600
standaloneEnabled: false
ZOO_MAX_CLIENT_CNXNS: 200
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_AUTOPURGE_PURGEINTERVAL: 1
ZOO_AUTOPURGE_SNAPRETAINCOUNT: 3
volumes:
- ./zookeeper/zoo3/data:/data
- ./zookeeper/zoo3/datalog:/datalog
networks:
- my-net
networks:
my-net:
driver: overlay
external: true
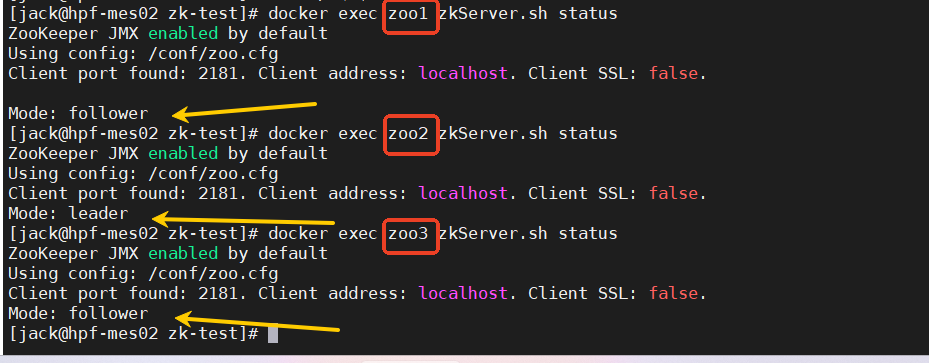
三、验证是否生效高可用
可以看到 主节点是leader 在zoo2 ,从节点follower在zoo1 zoo3
docker exec zoo1 zkServer.sh status docker exec zoo2 zkServer.sh status docker exec zoo3 zkServer.sh status
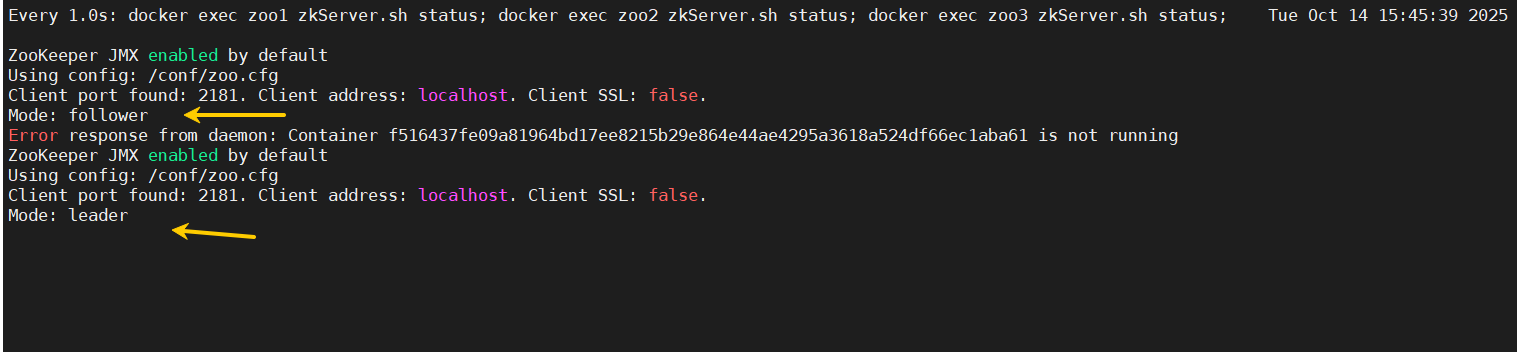
停止主节点(zoo2容器) 在进行查看
docker stop zoo2
这条命令是动态查看集群状态,同时看zoo1 zoo2 zoo3 一个程序停掉,肯定会有一个报错
watch -n 1 'docker exec zoo1 zkServer.sh status; docker exec zoo2 zkServer.sh status; docker exec zoo3 zkServer.sh status; '
这里可以看到 zoo2 报错了。 zoo3变成了leader 主节点
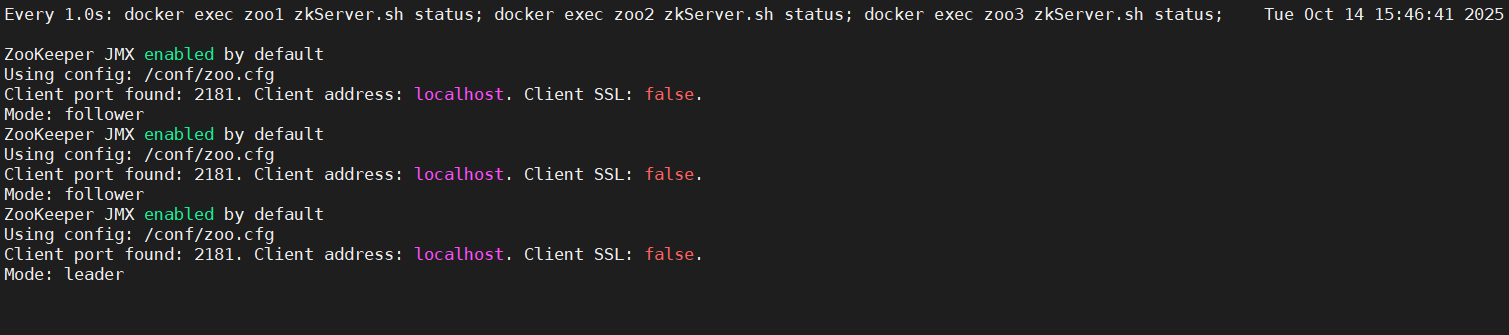
然后启动zoo2容器发现, zoo2 变成了从节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号