
#页面结构

#源代码
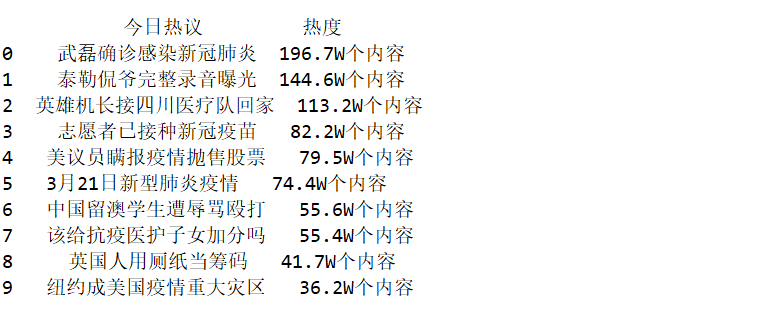
import requests from bs4 import BeautifulSoup import pandas as pd from pandas import DataFrame url="https://tophub.today/n/Om4ejxvxEN" headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}# r=requests.get(url) r.encoding=r.apparent_encoding data=r.text soup=BeautifulSoup(data,'html.parser') print(soup.prettify()) a = request.Request(url, headers=headers) b = request.urlopen(a).read().decode('utf-8') title=re.compile(r'itemid="[0-9]*">(.*?)</a>') num=re.compile(r'<td>(.*?)</td>') titles=title.findall(b)[0:10] nums=num.findall(b)[0:10] m={"今日热议":titles,"热度":nums} file=pd.DataFrame(m) print(file)
#输出结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号