


6. RDD综合练习:更丰富的操作
补交第五次作业,链接 https://www.cnblogs.com/n1254088/p/16115063.html
集合运算练习
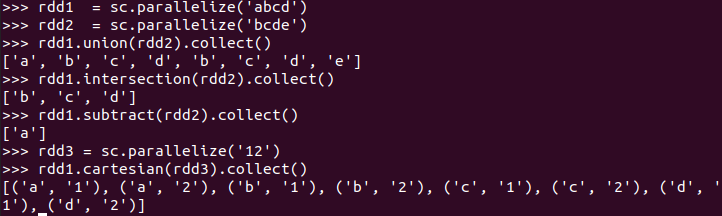
union(), intersection(),subtract(), cartesian()
>>> rdd1 = sc.parallelize('abcd') >>> rdd2 = sc.parallelize('bcde') >>> rdd1.union(rdd2).collect() >>> rdd1.intersection(rdd2).collect() >>> rdd1.subtract(rdd2).collect() >>> rdd3 = sc.parallelize('12') >>> rdd1.cartesian(rdd3).collect()
内连接与外连接
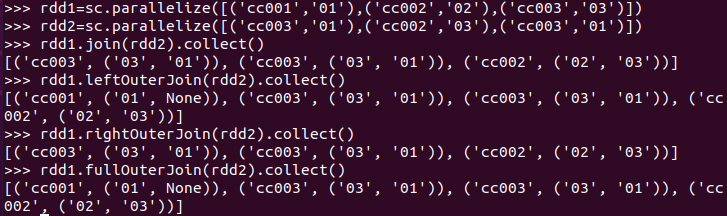
join(), leftOuterJoin(), rightOuterJoin(), fullOuterJoin()
多个考勤文件,签到日期汇总,出勤次数统计
>>> rdd1=sc.parallelize([('cc001','01'),('cc002','02'),('cc003','03')])
>>> rdd2=sc.parallelize([('cc003','01'),('cc002','03'),('cc003','01')])
>>> rdd1.join(rdd2).collect()
>>> rdd1.leftOuterJoin(rdd2).collect()
>>> rdd1.rightOuterJoin(rdd2).collect()
>>> rdd1.fullOuterJoin(rdd2).collect()
三、综合练习:学生课程分数
网盘下载sc.txt文件,通过RDD操作实现以下数据分析:
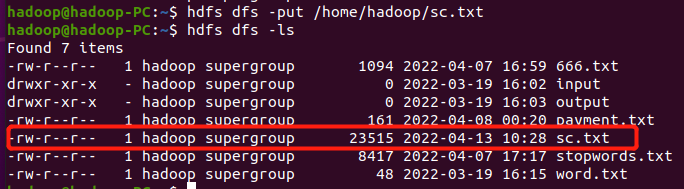
持久化 scm.cache()
>>> lines = sc.textFile("hdfs://localhost:9000/user/hadoop/sc.txt") >>> scm=lines.map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])]) >>> scm.cache()

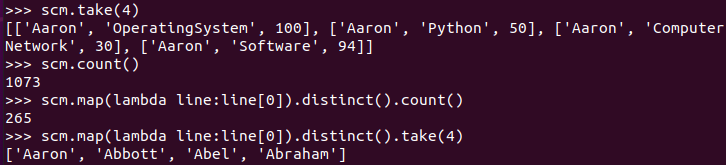
总共有多少学生?map(), distinct(), count()
>>> scm.take(4) >>> scm.count() >>> scm.map(lambda line:line[0]).distinct().count() >>> scm.map(lambda line:line[0]).distinct().take(4)
开设了多少门课程?
>>> scm.map(lambda line:line[1]).take(10) >>> scm.map(lambda line:line[1]).distinct().take(10) >>> scm.map(lambda line:line[1]).distinct().take(10) >>> scm.map(lambda line:line[1]).distinct().count()

生成(姓名,课程分数)键值对RDD,观察keys(),values()
>>> nb = scm.map(lambda a:(a[0],(a[1],a[2]))) >>> nb.keys().take(5) >>> nb.values().take(5)

每个学生选修了多少门课?map(), countByKey()
>>> name = scm.map(lambda line:(line[0],(line[1],line[2]))) >>> name.take(4) >>> name.keys().take(6) >>> name.values().take(6) >>> name.countByKey()
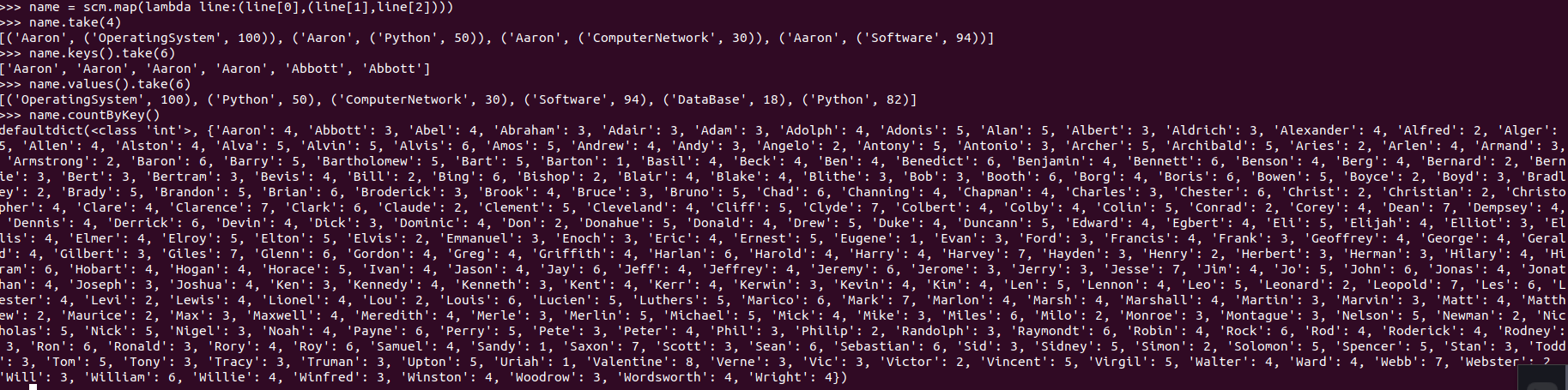
每门课程有多少个学生选?map(), countByValue()
>>> name.values().countByKey()

有多少个100分?
>>> name.values().values().countByValue()[100]

Tom选修了几门课?每门课多少分?filter(), map() RDD
>>> scm.filter(lambda line:line[0]=='Tom').map(lambda line:line[1]).collect() >>> scm.filter(lambda line:line[0]=='Tom').map(lambda line:line[2]).collect()

Tom选修了几门课?每门课多少分?map(),lookup() list
>>> name.lookup('Tom') >>> scm.filter(lambda line:line[0]=='Tom')

Tom的成绩按分数大小排序。filter(), map(), sortBy()
>>> scm.filter(lambda line:'Tom' in line).sortBy(lambda line:line).sortBy(lambda line:line[2],False).collect()

Tom的平均分。map(),lookup(),mean()
>>> name_score = scm.map(lambda line:(line[0],line[2]))
>>> import numpy as np
>>> np.mean(list(map(int,name_score.lookup('Tom'))))

生成(课程,分数)RDD,观察keys(),values()
>> score = scm.map(lambda line:(line[1],line[2])) >>> score.take(3) >>> score.keys().take(6) >>> score.values().take(6)
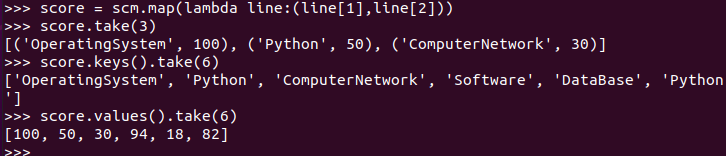
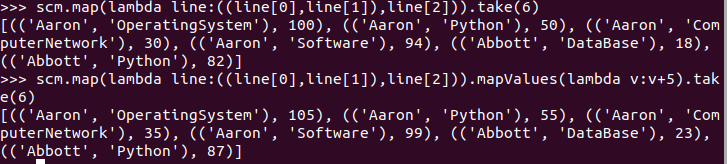
每个分数+5分。mapValues(func)
>>> scm.map(lambda line:((line[0],line[1]),line[2])).take(6) >>> scm.map(lambda line:((line[0],line[1]),line[2])).mapValues(lambda v:v+5).take(6)
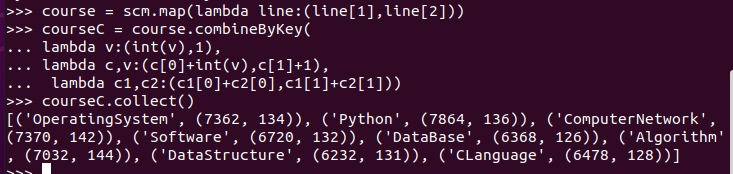
求每门课的选修人数及所有人的总分。combineByKey()
>>> course = scm.map(lambda line:(line[1],line[2])) >>> courseC = course.combineByKey( ... lambda v:(int(v),1), ... lambda c,v:(c[0]+int(v),c[1]+1), ... lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) >>> courseC.collect()
求每门课的选修人数及平均分,精确到2位小数。map(),round()
>>> courseC.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1], 2))).collect()

求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
>>> course = scm.map(lambda line:(line[1],(line[2],1))) >>> result = course.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).map(lambda a:(a[0],a[1][1],round(a[1][0]/a[1][1]))).collect() >>> result

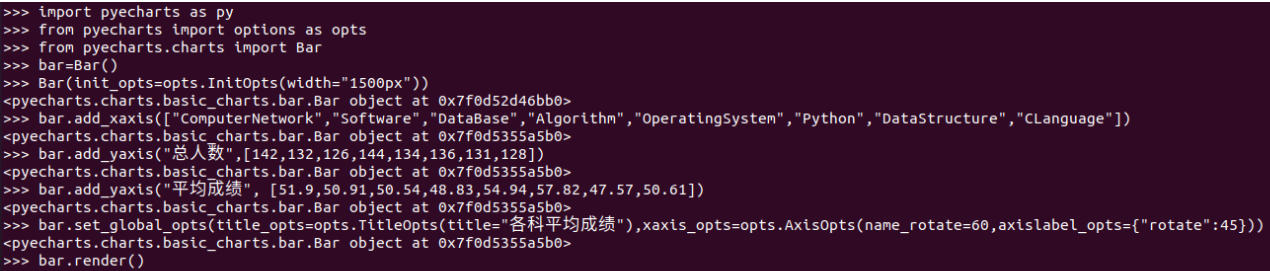
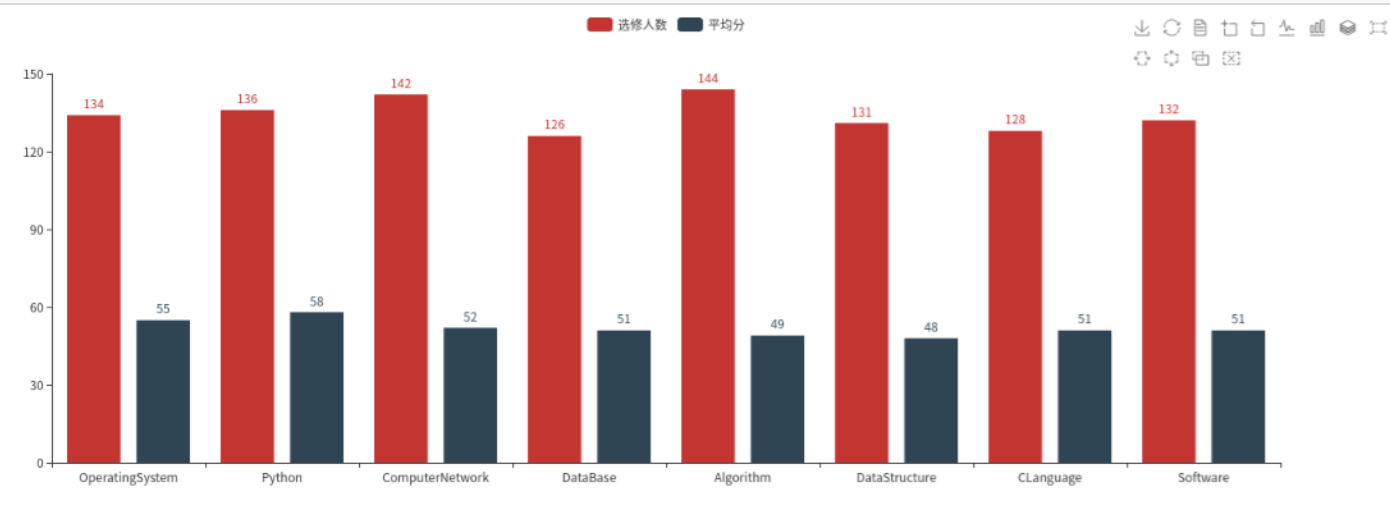
结果可视化。 pyecharts.charts,Bar()
course_name = [i[0] for i in result] course_pnum = [i[1] for i in result] course_mean = [i[2] for i in result] from pyecharts.charts import Bar from pyecharts import options as opts bar = ( Bar(init_opts=opts.InitOpts(width="1500px")) .add_xaxis(course_name) .add_yaxis("选修人数", course_pnum) .add_yaxis("平均分", course_mean) .set_global_opts(title_opts=opts.TitleOpts(title="课程详情"), toolbox_opts=opts.ToolboxOpts(),xaxis_opts=opts.AxisOpts( axislabel_opts={"interval":"0"})) ) bar.render('course.html')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号