【Java并发工具类】ReadWriteLock
前言
前面介绍过ReentrantLock,它实现的是一种标准的互斥锁:每次最多只有一个线程能持有ReentrantLock。这是一种强硬的加锁规则,在某些场景下会限制并发性导致不必要的抑制性能。互斥是一种保守的加锁策略,虽然可以避免“写/写”冲突和“写/读”冲突,但是同样也避免了“读/读”冲突。
在读多写少的情况下,如果能够放宽加锁需求,允许多个执行读操作的线程同时访问数据结构,那么将提升程序的性能。只要每个线程都能确保读到最新的数据,并且在读取数据时不会有其他的线程修改数据,那么就不会发生问题。在这种情况下,就可以使用读写锁:一个资源可以被多个读操作访问,或者被一个写操作访问,但两者不能同时进行。
Java中读写锁的实现是ReadWriteLock。下面我们先介绍什么是读写锁,然后利用读写锁快速实现一个缓存,最后我们再来介绍读写锁的升级与降级。
什么是读写锁
读写锁是一种性能优化措施,在读多写少场景下,能实现更高的并发性。读写锁的实现需要遵循以下三项基本原则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个线程正在执行写操作,此时禁止读线程读共享便利。
读写锁与互斥锁的一个重要区别就是:读写锁允许多个线程同时读共享变量,而互斥锁是不允许的。读写锁的写操作时互斥的。
下面是ReadWriteLock接口:
public interface ReadWriteLock{
Lock readLock();
Lock writeLock();
}
其中,暴露了两个Lock对象,一个用于读操作,一个用于写操作。要读取由ReadWriteLock保护的数据,必须首先获得读取锁,当需要修改由ReadWriteLock保护的数据时,必须首先获得写入锁。尽管这两个锁看上去是彼此独立的,但读取锁和写入锁只是读写锁对象的不同视图。
与Lock一样,ReadWriteLock可以采用多种不同的实现方式,这些方式在性能、调度保证、获取优先性、公平性以及加锁语义等方面可能有些不同。读取锁与写入锁之间的交互方式也可以采用多种方式实现。
ReadWriteLock中有一些可选实现包括:
- 释放优先:当一个写入操作释放写入锁时,并且队列中同时存在读线程和写线程,那么应该优先选择读线程,写线程,还是最先发出请求的线程?
- 读线程插队:如果锁是由读线程持有,但有写线程正在等待,那么新到达的读线程能否立即获得访问权,还是应该在写线程后面等待?如果允许读线程插队到写线程之前,那么将提高并发性,但却可能造成写线程发生饥饿问题。
- 重入性:读取锁和写入锁是否是可重入的?
- 降级:如果一个线程持有写入锁,那么它能否在不释放该锁的情况下获得读取锁?这可能会使得写入锁被“降级”为读取锁,同时不允许其他写线程修改被保护的资源。
- 升级:读取锁能否优先于其他正在等待的读线程和写线程而升级为一个写入锁?在大多数的读-写锁实现中并不支持升级,因为如果没有显式的升级操作,那么很容易造成死锁。(如果两个读线程试图同时升级为读写锁,那么二者都不会释放读取锁。)
ReentrantReadWriteLock
ReentrantReadWriteLock是ReadWriteLock的一个实现,它为读取锁和写入锁都提供了可重入的加锁语义。与ReentrantLock相似,ReentrantReadWriteLock在构造时也可以选择是一个非公平的锁(默认)还是一个公平的锁。
在公平的锁中,等待时间最长的线程将优先获得锁。如果这个线程是由读线程持有,而另一个线程请求写入锁,那么其他读线程都不能获得读取锁,直到写线程使用完并且释放了写入锁。
在非公平的锁中,线程获得访问许可的顺序是不确定的。写线程降级为读线程是可以的,但从读线程升级为写线程则是不可以的(容易导致死锁)。
实现一个快速缓存
下面使用ReentrantReadWriteLock来实现一个通用的缓存工具类。
实现一个Cache<K,V>类,类型参数K代表缓存中key类型,V代表缓存里的value类型。我们将缓存数据存储在Cache类中的HashMap中,但是HashMap不是线程安全的,所以我们使用读写锁来保证其线程安全。
Cache工具类提供了两个方法,读缓存方法get()和写缓存方法put()。读缓存需要用到读取锁,读取锁的使用方法同Lock使用方式一致,都需要使用try{}finally{}编程范式。写缓存需要用到写入锁,写入锁和读取锁使用类似。
代码参考如下:(代码来自参考[1])
class Cache<K,V> {
final Map<K, V> m = new HashMap<>();
final ReadWriteLock rwl = new ReentrantReadWriteLock();
final Lock r = rwl.readLock(); // 读取锁
final Lock w = rwl.writeLock(); // 写入锁
// 读缓存
V get(K key) {
r.lock(); // 获取读取锁
try {
return m.get(key);
}finally {
r.unlock(); // 释放读取锁
}
}
// 写缓存
V put(K key, V value) {
w.lock(); // 获取写入锁
try {
return m.put(key, v);
}finally {
w.unlock(); // 释放写入锁
}
}
}
缓存数据的初始化
使用缓存首先要解决缓存数据的初始化问题。缓存数据初始化,可以采用一次性加载的方式,也可以使用按需加载的方式。
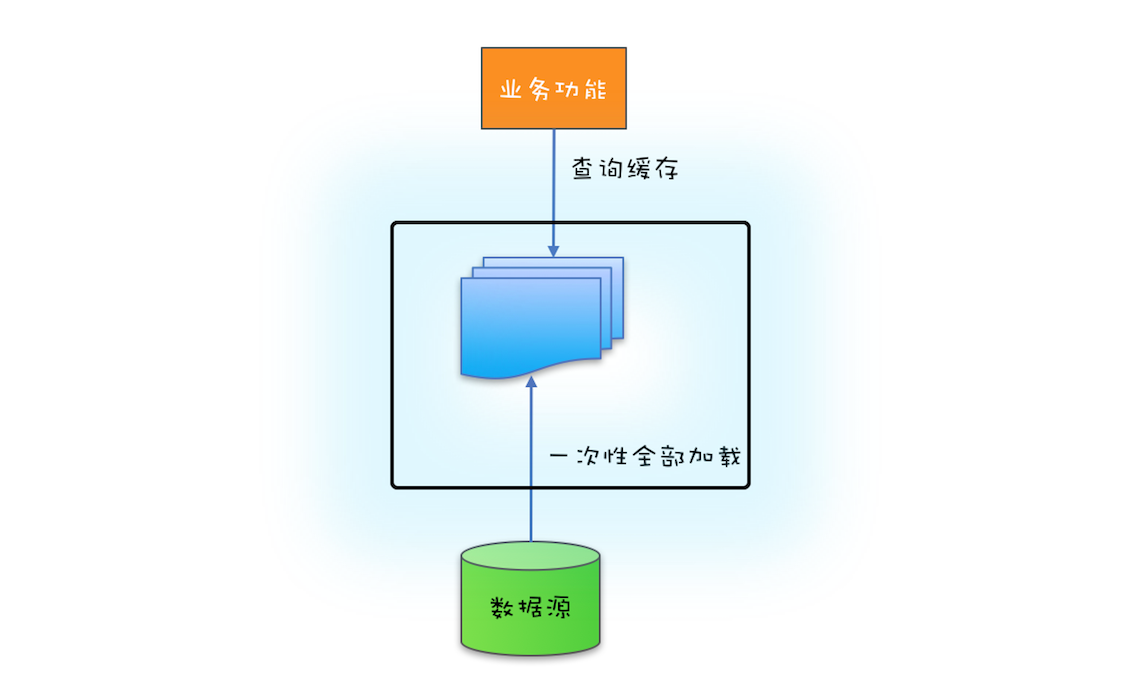
如果源头数据的数据量不大,就可以采用一次性加载的方式,这种方式也最简单。只需要在应用启动的时候把源头数据查询出来,依次调用类似上面代码的put()方式就可以了。可参考下图(图来自参考[1])
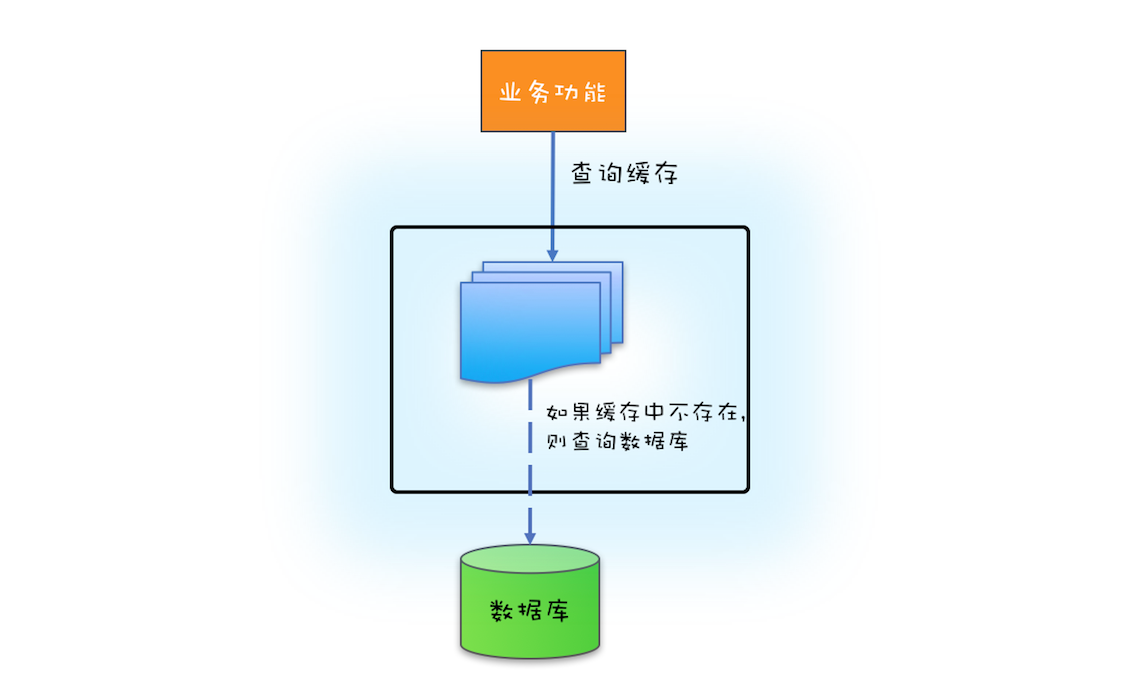
如果源头数据量非常大,那么就需要按需加载,按需加载也叫做懒加载。指的是只有当应用查询缓存,并且数据不在缓存里的时候,才触发加载源头相关数据进行缓存的操作。可参考下图(图来自参考[1])
实现缓存的按需加载
下面代码实现了按需加载的功能(代码来自参考[1])。
这里假设缓存的源头时数据库。如果缓存中没有缓存目标对象,那么就需要从数据库中加载,然后写入缓存,写缓存是需要获取写入锁。
class Cache<K,V> {
final Map<K, V> m = new HashMap<>();
final ReadWriteLock rwl = new ReentrantReadWriteLock();
final Lock r = rwl.readLock(); // 读取锁
final Lock w = rwl.writeLock(); // 写入锁
V get(K key) {
V v = null;
//读缓存
r.lock(); // 获取读取锁
try {
v = m.get(key);
} finally{
r.unlock(); // 释放读取锁
}
//缓存中存在目标对象,返回
if(v != null) {
return v;
}
//缓存中不存在目标对象,查询数据库并写入缓存
w.lock(); // 获取写入锁 ①
try {
//再次验证 其他线程可能已经查询过数据库
v = m.get(key);
if(v == null){
//查询数据库
v=省略代码无数
m.put(key, v);
}
} finally{
w.unlock(); //释放写入锁
}
return v;
}
}
当缓存中不存在目标对象时,需要查询数据库,在上述代码中,我们在执行真正的查库之前,又查看了缓存中是否已经存在目标对象,这样做的好处是可以避免重复查询提升效率。我们举例说明这样做的益处。
在高并发的场景下,有可能会有多线程竞争写锁。假设缓存是空的,没有缓存任何东西,如果此时有三个线程 T1、T2 和 T3 同时调用get()方法,并且参数 key 也是相同的。那么它们会同时执行到代码①处,但此时只有一个线程能够获得写锁。
假设是线程 T1,线程 T1 获取写锁之后查询数据库并更新缓存,最终释放写锁。
此时线程 T2 和 T3 会再有一个线程能够获取写锁,假设是 T2,如果不采用再次验证的方式,此时 T2 会再次查询数据库。T2 释放写锁之后,T3 也会再次查询一次数据库。
而实际上线程 T1 已经把缓存的值设置好了,T2、T3 完全没有必要再次查询数据库。
读写锁的升级与降级
上面读取锁的获取释放与写入锁的读取和释放是没有嵌套的。如果我们改一改代码,将再次验证并更新缓存的逻辑换个位置放置:
//读缓存
r.lock(); // 获取读取锁
try {
v = m.get(key);
if (v == null) {
w.lock(); // 获取写入锁
try {
//再次验证并更新缓存
//省略详细代码
} finally{
w.unlock(); // 释放写入锁
}
}
} finally{
r.unlock(); // 释放读取锁
}
上述代码,在获取读取锁后,又试图获取写入锁,即我们前面介绍的锁的升级。但是,ReadWriteLock是不支持这种升级,在代码中,读取锁还没有释放,又尝试获取写入锁,将导致相关线程被阻塞(读取锁和写入锁只是读写锁对象的不同视图),永远没有机会被唤醒。
虽然锁的升级不被允许,但是锁的降级却是被允许的。(下例代码来自参考[1])
class CachedData {
Object data;
volatile boolean cacheValid;
final ReadWriteLock rwl = new ReentrantReadWriteLock();
final Lock r = rwl.readLock(); // 读取锁
final Lock w = rwl.writeLock(); //写入锁
void processCachedData() {
// 获取读取锁
r.lock();
if (!cacheValid) {
r.unlock(); // 释放读取锁,因为不允许读取锁的升级
w.lock(); // 获取写入锁
try {
// 再次检查状态
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 释放写入锁前,降级为读取锁 降级是可以的
r.lock();
} finally {
w.unlock(); // 释放写入锁
}
}
// 此处仍然持有读取锁,要记得释放读取锁
try {
use(data);
} finally {
r.unlock();
}
}
}
小结
读写锁的读取锁和写入锁都实现了java.util.concurrent.locks.Lock接口,所以除了支持lock()方法外,tryLock(),lockInterruptibly()等方法也都是支持的。但是需要注意,只有写入锁支持条件变量,读取是不支持条件变量的,读取锁调用newCondition()会泡池UnsupporteOperationException异常。
我们实现的简单缓存是没有解决缓存数据与源头数据同步的,即保持与源头数据的一致性。解决这个问题的一个简单方案是超时机制:当缓存的数据超过时效后,这条数据在缓存中就失效了;访问缓存中失效的数据,会触发缓存重新从源头把数据加载进缓存。也可以在源头数据发生变化时,快速反馈给缓存。
虽说读写锁在读多写少场景下性能优于互斥锁(独占锁),但是在其他情况下,性能可能要略差于互斥锁,因为读写锁的复杂性更高。所以,我们要根据场景来具体考虑使用哪一种同步方案。
参考:
[1]极客时间专栏王宝令《Java并发编程实战》
[2]Brian Goetz.Tim Peierls. et al.Java并发编程实战[M].北京:机械工业出版社,2016

 浙公网安备 33010602011771号
浙公网安备 33010602011771号