Glibc内存管理-ptmalloc2
一、linux的内存布局
1、32位模式下内存的经典布局
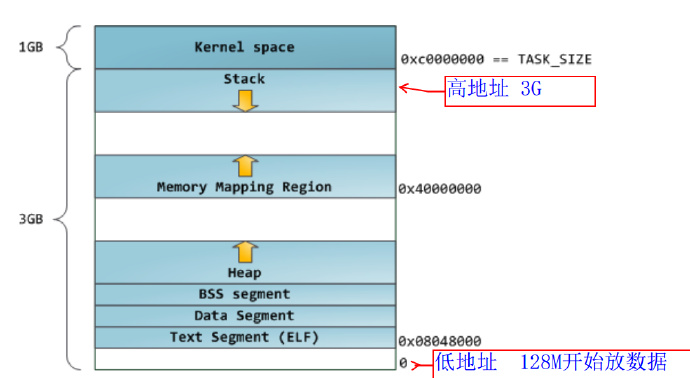
注:这种内存布局模式是linux内核2.6.7以前的默认内存布局形式
说明:
(1)在32的机器上,loader将可执行文件的各个段次依次载入到从0x80048000(128M)位置开始的空间中。程序能够访问的最后地址是0xbfffffff(3G)的位置,3G以上的位置是给内核使用的,应用程序不能直接访问。
(2)内存布局从低地址到高地址依次为:txet段、data段、bss段、heap、mmap映射区、stack堆栈区。
(3)heap和mmap是相对增长的,也就意味着heap只有1G的虚拟地址空间可供使用。
(4)stack区域不需要映射的,用户可以直接访问该区域。这也是利用堆栈溢出进行攻击的基础。
2、32位模式下内存的默认布局
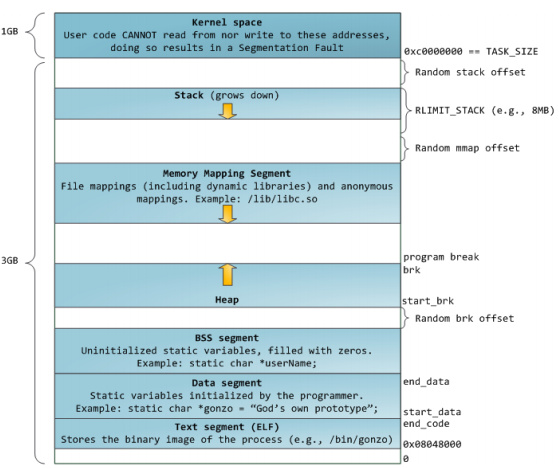
注:这种内存布局是linux内核2.6.7之后32位机器的默认内存布局方式。
说明:(1)这种内存布局方式加入了几个Random offset的随机偏移,这样的话内存溢出的攻击就不会那么容易了。
(2)栈是自顶向下扩展的,但是栈是有边界的栈大小就有了限制(linux小t乃下可以使用ulimit -s 命令进行查看其大小)。堆是自底向上扩展的,mmap映射区自顶向下扩展。故mmap和heap是相对扩展的,直至消耗尽虚拟地址空间中的剩余区域,这种结构便于C运行库使用mmap映射区和堆进行内存分配。
3、64位模式下内存的默认布局
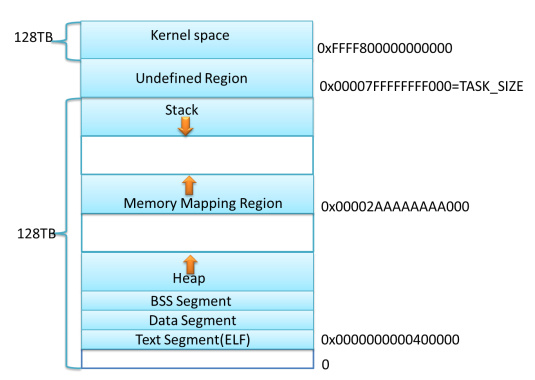
说明:这种内存布局方式沿用的32位模式下内存的经典布局,但是栈和mmap的映射区域不再是从一个固定的地方开始,每次启动时的值都不一样。这样一来,使得使用缓冲区溢出攻击变得更加困难。
二、操作系统内存分配的相关函数
1、总括
heap和mmap映射区域是可以提供给用户程序使用的虚拟内存空间,获得该区域的内存的操作有:
(1)对于heap操作,操作系统提供了brk()系统调用,c运行库提供了sbrk()库函数。
(2)对于mmap映射区的操作,操作系统提供了mmap()和munm()系统调用。
(3)linux内存管理的基本思想:内存延迟分配。即只有在真正访问一个地址的时候才建立这个地址的物理映射。linux内核在用户申请内存的时候,只是给它分配了一个虚拟地址,并没有分配实际的物理地址,只有当用户使用这块内存的时候,内核才会分配具体的物理地址给用户使用。
2、heap操作的相关函数
(1)brk()是系统调用、sbrk()是库函数。c语言的动态内存分配基本函数是malloc(),在linux上的实现是:malloc()函数调用库函数sbrk(),sbrk()的实质是调用brk()函数。brk()是一个简单的系统调用,只是简单的改变mm_struct结构体的成员变量brkd的值。
(2)函数原型:
#include
int brk(void * addr);
void * sbrk(intptr_t increment); //当参数increment为0时,sbrk()返回的是进程当前的brk值,increment为正数时扩展brk值,当increment为负数时收缩brk值
(3)mm_struct结构中的成员变量
start_code 和 end_code 是进程代码段的起始和结束地址、
start_data 和 end_data 是进程数据段的起始和终止地址。
start_stack 是进程堆栈段的起始地址。
start_brk 是进程动态内存分配的起始地址(堆的起始地址)。
brk 是进程动态内存分配当前的终止地址(堆的当前最后地址)。
3、Mmap映射区域操作的相关函数
(1)mmap()函数将一个文件或者其他对象映射进内存。文件被映射到多个页上,如果文件大小不是所有页大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。
(2)函数原型
#include
void * mmap(void * addr,size_t length,int prot,int flags,int fd,off_t offset)
int munmap(void *addr,size_t length);
参数:start — 映射区的开始地址。
length — 映射区的长度。
prot — 期望的内存保护标志。
flags — 指定映射对象的类型,映射选项和映射页是否可以共享。
fd — 有效的文件描述符。
offset — 被映射对象内容的起点。
三、Ptmalloc 简介
1、ptmalloc 的背景介绍
早期的ptmalloc出现在Doug Lea中,它有一个重要的问题是在处理多线程并发请求内存时需要保证分配和回收的正确和高效。因此,改进后的Glibc的malloc可以支持多线程—ptmalloc。
2、 分配器简介
分配器处于内核和用户程序之间。它的工作机制是这样的:它响应用户的分配请求,向操作系统申请内存,然后将内存返回给用户程序。为了保证高效,分配器一般都会预先分配一块大于用户请求的内存,然后管理这块内存。用户释放掉的内存也不是立即返回给操作系统的,分配器会管理这些释放掉的空闲空间以应对用户以后的内存分配请求。
分配器不仅需要管理分配的内存块,还需要管理空间的内存块。当响应用户的请求时,分配器会首先在空闲空间中寻找一块合适的内存返回给用户,在空闲空间中找不到的清苦下才会重新分配一块新的内存。
3、ptmalloc的设计假设
(1)具有长生命周期的大内存分配使用mmap。
(2)特别大的内存分配总是使用mmap.
(3)具有短生命周期的内存分配使用sbrk。
(4)尽量只缓存临时使用的空闲小内存块,当大内存块或者是生命周期较长的大内存块在释放时都直接归还给操作系统。
(5)需要长期存储的程序不合适用ptmalloc来管理。
(6)对空闲的小内存块只会在malloc和free的时候进行合并。free时空闲内存块可能放入内存池中,而不是立即归还给操作系统。
(7)为了支持多线程,多个线程可以同一个分配区中分配内存,ptmalloc假设线程A释放掉一块内存后,线程B申请类似大小的内存,但是A释放的内存跟B需要的内存不一定完全相等。
四、ptmalloc内存管理数据结构
1、Main_arena与non_main_arena(主分配区和非主分配区)
(1)为什么会出现主分配区和非主分配区?
- Doug_Lea实现的内存分配器中只有一个主分配区,每次分配内存都必须对主分配区加锁,分配完成后再释放锁。在多线程的环境下,对主分配区的锁的竞争很激烈,严重影响了malloc的分配效率。改进后的Glibc的malloc可以支持多线程,增加了非主分配区支持,主分配区和非主分配区形成一个环形链表进行管理。每一个分配区使用互斥锁使多线程对于该分配区的访问互斥。
- 主分配区和非主分配区形成一个环形链表进行管理。
- 每一个分配区利用互斥锁使线程对于该分配区的访问互斥。
- 每个进程只有一个主分配区,也可以允许有多个非主分配区。
- ptmalloc根据系统对分配区的争用动态增加分配区的大小,分配区的数量一旦增加,则不会减少。
- 主分配区可以使用brk和mmap来分配,而非主分配区只能使用mmap来映射内存块
- 申请小内存时会产生很多内存碎片,ptmalloc在整理时也需要对分配区做加锁操作
(2)主分配区和非主分配的区别
<1>每个进程只有一个主分配区,可以有多个非主分配区,ptmalloc根据系统对分配区的争用情况动态的增加非主分配区的个数,分配区的数量一旦增加了就不会再减少。
<2>主分配区可以访问进程的heap和mmap映射区域,也就是说主分配区可以使用sbrk()和mmap()向操作系统申请虚拟内存。非主分配区只能访问进程的mmap映射区域,非主分配区每次使用mmap()向操作系统批发HEAP_MAX_SIZE(32位-1M,64位-64M)大小的虚拟内存,当用户向非主分配区请求分配内存时再切成小块零售出去。系统调用的效率比较低,直接从用户空间分配内存效率会比较高。所以ptmalloc在必要的情况下才会调用mmap()向操作系统申请内存。
<3>主分配区可以访问heap区域,如果用户不调用sbrk()或者brk()函数,分配程序就可以保证分配到连续的虚拟内存,因为一个进程只有一个主分配区使用sbrk()分配heap区域的虚拟内存。如果主分配区的内存时通过mmap()向系统申请的,当free该内存时,主分配区会直接调用munmap()将内存归还给操作系统。
<4>malloc()函数的实质
当线程需要使用malloc函数分配内存空间时,该线程会先查看线程的私有变量中是否已经存在有一个分配区,如果存在,尝试对分配区加锁,如果加锁成功就使用这个分配区分配内存。如果失败,该线程就搜索循环链表试图获得一个没有加锁的分配区来分配内存。如果所有的分配区都加锁,那么malloc会开辟一个新的分配区,把该分配区添加到循环链表中并加锁,使用这个分配区进行分配内存操作。在释放操作中,线程同样试图获得待释放内存块所在的分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行释放操作。
2、Malloc实现原理
因为brk、sbrk、mmap都属于系统调用,若每次申请内存,都调用这三个,那么每次都会产生系统调用,影响性能;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果高地址的内存没有被释放,低地址的内存就不能被回收。
所以malloc采用的是内存池的管理方式(ptmalloc),Ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,当我们申请和释放内存的时候,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。这样做的最大好处就是,使用户申请和释放内存的时候更加高效,避免产生过多的内存碎片。
3、chunk的结构
1.struct malloc_chunk { 2. INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ 3. INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ 4. 5. struct malloc_chunk* fd; /* double links -- used only if free. */ 6. struct malloc_chunk* bk; 7. 8. /* Only used for large blocks: pointer to next larger size. */ 9. struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ 10. struct malloc_chunk* bk_nextsize; 11.};
(1)chunk的使用:用户请求分配的空间在ptmalloc中都使用一个chunk来表示。用户调用free函数释放掉的内存也不是立即就返回操作系统,它们会被表示成一个chunk。ptmalloc中使用特定的数据结构管理这些空闲的chunk。
(2)chunk的格式
ptmalloc在给用户分配的空间的前后加上一些控制信息,用这样的方式来记录分配的信息。一个正在使用中的chunk如下图所示:
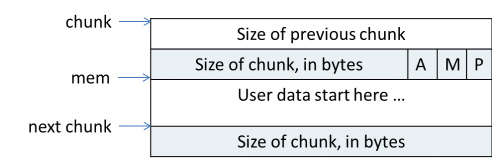
图1 使用中的chunk
说明:
<1>chunk指针指向chunk开始的地址;mem指针指向用户内存块开始的地址。
<2> p=0时,表示前一个chunk为空闲,prev_size才有效。
<3> p=1时,表示前一个chunk正在使用,prev_size无效。 p主要用于内存块的合并操作。
<4> ptmalloc分配的第一个块总是将p设为1,以防止程序引用到不存在的区域。
<5> M=1 为mmap映射区域分配;M=0为heap区域分配。
<6> A=1 为非主分区分配;A=0 为主分区分配。
空闲chunk在内存中的结构:
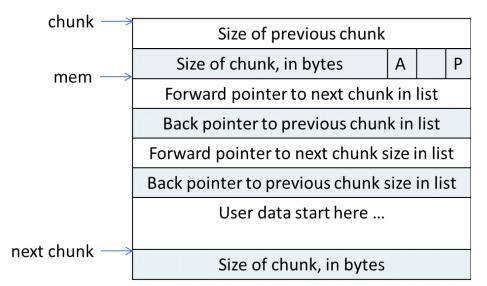
图2 空闲的chunk
说明:
<1> 空闲的chunk会被放置到空闲的链表bins上。当用户申请内存malloc的时候,会先去查找空闲链表bins上是否有合适的内存。
<2> fp和bp分别指向前一个和后一个空闲链表上的chunk
<3>fp_nextsize和bp_nextsize分别指向前一个空闲chunk和后一个空闲chunk的大小,主要用于在空闲链表上快速查找合适大小的chunk。
<4>fp、bp、fp_nextsize、bp_nextsize的值都会存在原本的用户区域,这样就不需要专门为每个chunk准备单独的内存存储指针了。
4、chunk的组织-BINS
用户释放掉的内存并不是马上就归还给操作系统,ptmalloc会统一管理heap和mmap映射区中的空闲的chunk,当用户进行下一次请求分配时,ptmalloc会试图从空闲的内存中挑选一块给用户,这样可以避免频繁的系统调用,降低了内存分配的开销。ptmalloc将大小相似的chunk用双向循环链表连接起来,这样的一个链表称为bin。ptmalloc中一共维护了128个bin,并使用一个数组来存储这些bin(数组实际存储的是指针)。
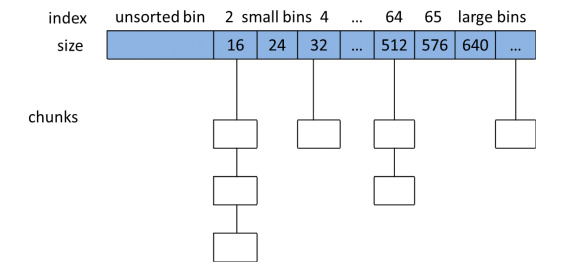
图3 bins结构图
(1)fast bins:fast bins是small bins的高速缓冲区。fast bin使用单向链表实现。当程序运行需要申请和释放一些较小的内存空间。一般对于不大于max_fast(在SIZE_SZ为4B
的平台默认是64B)的chunk释放后就会先被放到fast bins中,fast bins中有七个chunk空闲链表(bin),每个bin的chunk大小依次为16B、24B、32B、40B.....64B。fast bins中的chunk并不改变它的使用标志P,这样就无法合并他们。当需要给用户分配小于或者是等于max_fast大小的内存时,ptmalloc会首先在fast bins中查找,然后才会去Bins中查找空闲的chunk。有时候ptmalloc也会遍历fast bins中的chunk,将相邻的空闲的chunk进行合并,并将合并后的chunk加入到unsorted bin中,然后将unsorted bin中的chunk加入到bin中。
(2)unsorted bin:相当于small bins和large bins的一个缓冲区,unsorted bin是bins数组中的第一个,用双向链表管理chunk,空闲的chunk不排序,所有的chunk在回收时都要先放到unsorted bin中。进行malloc操作时,如果fast_bins中没有找到合适的chunk,则ptmalloc就会在unsorted bin中查找空闲的chunk,如果unsorted bin中没有合适的chunk,就会把unsorted bin中所有chunk分别加入到所属的bin中,然后再在bin中查找合适的chunk。Bins数组中元素bin[1]用来存储unsorted bin的链表头。
(3)small bins:数组中从2号下标开始的到64号下标的62个bin称为small bins。同一个small bin中的chunk具有相同的大小,两个相邻的small bin中的chunk大小在SIZE_SZ为4B的平台上相差 8bytes,在SIZE_SZ为8B的平台上相差 16bytes。small bin 中chunk按照最近使用顺序进行排列,最后释放的chunk被连接到链表的头部,而申请的chunk是从链表尾部开始的。
(4)large bins:在SIZE_SZ为4B的平台上,大于等于512B的空闲的chunk由large bin管理。large bins一共包含63个bin,每个bin中的chunk大小不是一个固定的等差数列,而是分成6组bin,每组bin是一个固定的等差数列。每组bin数量依次为32、16、8、4、2、1,公差依次为64B、512B、4096B、32768B、262144B等。
(5)top chunk:并不是所有的chunk都会被放到bins上。top chunk相当于分配区的顶部空闲内存,当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
<1>对于非主分配区。非主分配区会预先从mmap区域分配一块较大的空闲内存模拟sub_heap,通过管理sub_heap来响应用户的需求,因为内存是按照从低地址到高地址进行分配的,在空闲内存的最高处,必然存在着一块空闲的chunk,叫做top chunk。
top chunk的使用:当bins和fast bins都不能满足分配需求的时候,ptmalloc会设法在top chunk中分配一块内存给用户,如果top chunk 本身不够大,分配程序会重新分配一个sub_heap,并将top chunk迁移到新的sub_heap上,新的sub_heap与已有的sub_heap用单向链表连接起来,然后在新的top chunk中分配所需要的内存以满足分配的需要。top chunk的大小会随着分配和回收不停变化。
<2>对于主分配区。主分配区是唯一能够映射进程heap区域的分配区,它可以通过sbrk()来增大和收缩进程heap的大小。ptmalloc在开始的时候会预先分配一块较大的空闲内存。主分配区的top chunk在第一次调用malloc时会分配一块空间作为初始化的heap。
(6)mmaped chunk:当需要分配的chunk足够大,fast bins和bins都不能满足要求,甚至top chunk都不能满足分配需求时,ptmalloc会使用mmap来直接使用页映射机制来将页映射到进程空间。这样分配的chunk在被free时将直接解除映射,于是就将内存归还给操作系统,再次对这样的内存区的引用将导致错误。
五、ptmalloc响应用户内存分配步骤
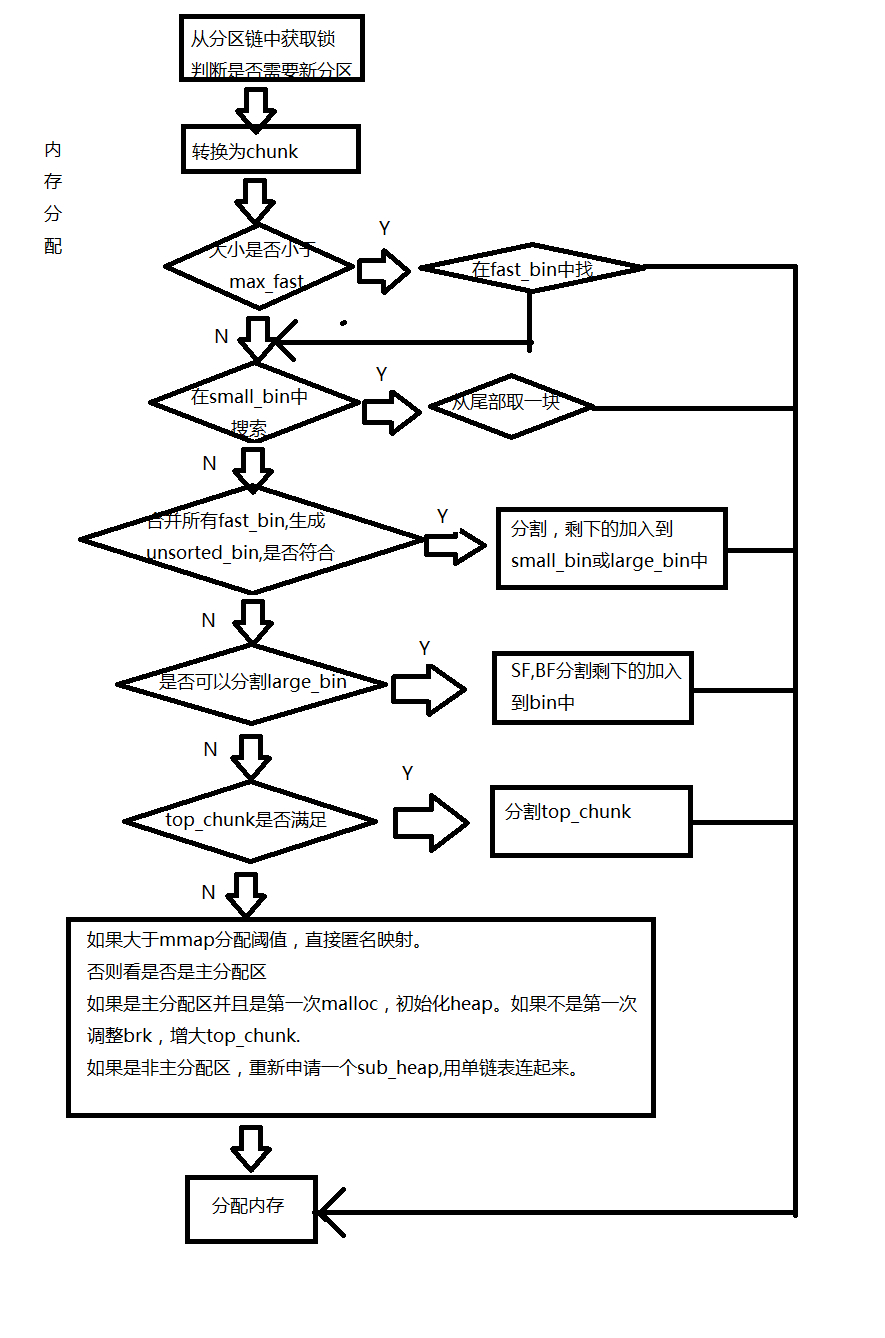
(1)获取分配区的锁。目的是为了防止多个线程同时访问同一个区域,在进行分配之前需要取得分配区域的锁。
(2)将用户的请求大小转换成实际需要分配的chunk空间的大小。
(3)判断所需分配的chunk的大小是否满足chunk_size<= max_size,如果是则转到第4步,否则,转第5步。
(4)首先尝试在fast bins中取一个所需大小的chunk分配给用户。如果可以找到,则分配结束,否则,转到下一步。
(5)判断所需要的大小是否处在small bins 中,如果在small bins中则转下一步,否则,转第7步。
(6)根据所需要分配的chunk的大小,找到具体所在的某个small bin,从该bin的尾部摘取一个恰好满足大小的chunk。若成功,则分配结束,否则,转下一步。
(7)到了这一步说明需要分配的是一块大内存,或者是small bin中找不到合适的chunk,于是,ptmalloc会遍历所有的fast bins中的chunk,将相邻的chunk进行合并,并连接到unsorted bin中,然后遍历unsorted bin中的chunk。如果unsorted bin中只有一个chunk,并且这个chunk大于等于需要分配的大小,这种情况下就直接将该chunk切割,分配结束。否则将根据chunk的空间大小将其放入到相应的small bins 或者 large bins 中。否则,进行下一步。
(8)到了这一步说明分配的是一块很大的内存,或者是在unsorted bin和small bins中都没有找到合适的chunk,fast bins和unsorted bin中所有的chunk都清除干净了,从large bins中找到一个合适的chunk,从中划分一块所需大小的chunk,并将剩下的部分连接回bins中,如果操作成功就结束分配,否则,转下一步。
(9)如果搜索bins都没有找到合适的chunk,那么需要操作top chunk来进行分配了。判断top chunk大小是否满足所需要的chunk的大小,如果是,则从top chunk中分出一块来。
(10)到了这一步说明top chunk也不能满足分配需求。所以有两个选择,如果是主分配区,调用sbrk(),增加top chunk 的大小,如果是非主分配区,调用mmap()来分配一个新的sub_heap,增加top chunk大小,或者是使用mmap()来直接分配。需要根据chunk的大小来决定使用哪种方法。如果所需要分配的chunk大小大于等于mmap分配阀值,则转下一步使用mmap分配原则,否则转12步。
(11)使用mmap系统调用为程序的内存空间映射一块chunk_size align 4KB大小的空间。然后将内存指针返回给用户。
(12)判断是否是第一次调用malloc,若是主分配区,则需要进行一次初始化工作,分配一块大小为(chunk_size + 128kb)slign大小的空间作为初始化的heap。若已经初始化过了,主分配区则调用sbrk()增加heap空间,非主分配区则在top chunk 中切割一个chunk,使之满足分配需求,并将用户指针返回给用户。
六、ptmalloc响应用户内存回收步骤
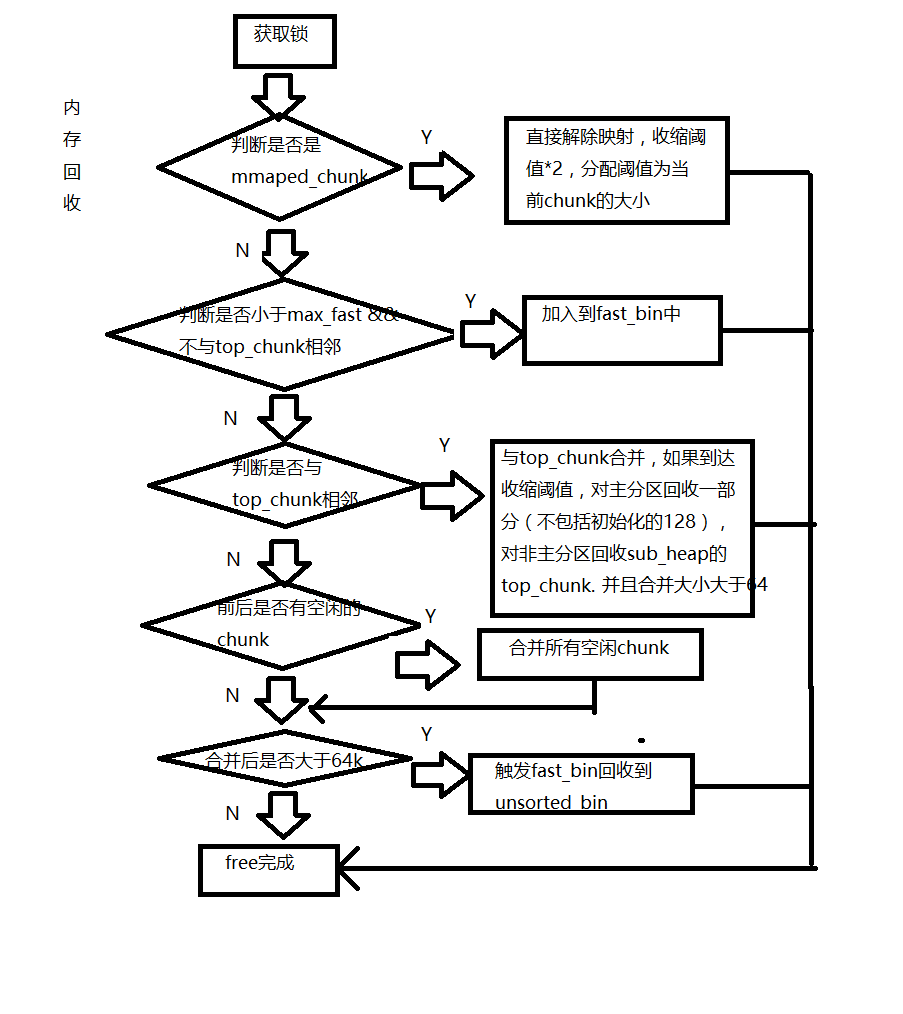
free()函数接受一个指向分配区域的指针作为参数,释放指针指向需要释放的chunk。
(1)free()函数首先需要获取分配区的锁来保证线程安全。
(2)判断传入的指针是否为0,如果为0,则什么都不做,直接return。否则转下一步。
(3)判断所需释放的chunk是否为mmaped chunk,如果是,则调用munmap()释放解除空间映射,该空间不再有效。
(4)判断chunk的大小和所处的位置,若chunk_size<= max_fast,并且chunk并不处于heap的顶部,也就是说不与top chunk相邻,则转到下一步,否则转到第6步。
(5)将chunk方到fast bins中,chunk放入到fast bins中时,并不修改该chunk使用状态位P,也不与相邻的chunk进行合并。只是放进去。这一步做完之后释放就结束了,程序从free()函数中返回。
(6)判断前一个chunk是否正在使用中,如果前一个块也是空闲块,则合并。并转下一步。
(7)判断当前释放的chunk的下一个块是否为top chunk,如果是,则转第9步,否则转下一步。
(8)判断下一个chunk是否处于使用中,如果下一个chunk也是空闲的,则合并,并将合并后的chunk放到unsorted bin中。注意,这里在合并过程中,要更新chunk的大小,以反映合并后的chunk的大小。并转到第10步。
(9)如果执行到这一步,说明释放了一个与top chunk相邻的chunk。则无论它有多大,都将它和top chunk合并,并更新top chunk的大小等信息。转下一步。
(10)判断合并后的chunk的大小是否会大于max_fast(默认是64kb),如果是的话,则会触发进行fast bins的合并操作,fast bins中的chunk将被遍历,并与相邻的chunk进行合并,合并后的chunk会被放到unsorted bin中。fast bins将变为空,操作完成后进入到下一步。
(11)判断 top chunk的大小是否大于mmap收缩阀值(默认是128kb),如果是的话,对于主分配区,则会试图归还top chunk中的一部分给操作系统。但是最先分配的128KB空间是不会归还给操作系统的,ptmalloc会一直管理这部分内存,用来响应用户的分配请求。如果是非主分配区,会进行sub_heap收缩,将top chunk的一部分返回给操作系统,如果 top chunk是整个sub_heap,会将整个sub_heap归还给操作系统。做完这一步后,释放结束,从free()函数退出。
七、配置选项概述
以下提供的配置选项可通过mallopt()进行设置。
1、M_MXFAST:用于设置fast bins中保存的chunk的最大大小,默认值为64B。最大80B。
2、M_TRIM_THRESHOLD:用于设置mmap收缩阈值,默认值为128KB。
3、M_MMAP_THRESHOLD:M_MMAP_THRESHOLD用于设置mmap分配阈值,默认值为128KB。当用户需要分配的内存大于mmap分配阈值,ptmalloc的malloc()函数其实相当于mmap()的简单封装,free函数相当于munmap()的简单封装。
4、M_MMAP_MAX:M_MMAP_MAX用于设置进程中用mmap分配的内存块的地址段数量,默认值为65536。
5、M_TOP_PAD:该参数决定了,当libc内存管理器调用brk释放内存时,堆顶还需要保留的空闲内存数量。该值缺省为 0。
四、怎样防止Glibc内存暴增?
1、后分配的内存先释放。因为ptmalloc收缩内存是从top chunk开始的,如果 top chunk相邻的chunk不能释放,top chunk以下的都无法释放。
2、ptmalloc不合适用于管理长声明周期的内存,特别是持续不定期分配和释放长生命周期的内存,这将导致ptmalloc内存暴增。
3. 多线程分阶段执行的程序不适合用ptmalloc,这种程序的内存更适合用内存池管理。
4. 尽量减少程序的线程数量和避免频繁分配/释放内存。频繁分配,会导致锁的竞争,最终导致非主分配区增加,内存碎片增高,并且性能降低。
5. 防止内存泄露,ptmalloc对内存泄露是相当敏感的,根据它的内存收缩机制,如果与top chunk相邻的那个chunk没有回收,将导致top chunk一下很多的空闲内存都无法返回给操作系统。
6. 防止程序分配过多内存,或是由于Glibc内存暴增,导致系统内存耗尽,程序因OOM被系统杀掉。预估程序可以使用的最大物理内存大小,配置系统的/proc/sys/vm/overcommit_memory,/proc/sys/vm/overcommit_ratio,以及使用ulimt –v限制程序能使用虚拟内存空间大小,防止程序因OOM被杀掉。
参考:Glibc内存管理
http://www.valleytalk.org/wp-content/uploads/2015/02/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%901.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号