动态追踪学习
动态追踪技术原因
当碰到内核线程的资源使用异常时,很多常用的进程级性能工具,并不能直接用到内核线程上。这时,我们就可以使用内核自带的 perf 来观察它们的行为,找出热点函数,进一步定位性能瓶颈。不过,perf 产生的汇总报告并不直观,所以我通常也推荐用火焰图来协助排查。
其实,使用 perf 对系统内核线程进行分析时,内核线程依然还在正常运行中,所以这种方法也被称为动态追踪技术。
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
以往,在排查和调试性能问题时,我们往往需要先为应用程序设置一系列的断点(比如使用GDB),然后以手动或者脚本(比如 GDB 的 Python 扩展)的方式,在这些断点处分析应用程序的状态。或者,增加一系列的日志,从日志中寻找线索。
不过,断点往往会中断应用的正常运行;而增加新的日志,往往需要重新编译和部署。这些方法虽然在今天依然广泛使用,但在排查复杂的性能问题时,往往耗时耗力,更会对应用的正常运行造成巨大影响。
此外,这类方式还有大量的性能问题。比如,出现的概率小,只有线上环境才能碰到。这种难以复现的问题,亦是一个巨大挑战。
而动态追踪技术的出现,就为这些问题提供了完美的方案:它既不需要停止服务,也不需要修改应用程序的代码;所有一切还按照原来的方式正常运行时,就可以帮你分析出问题的根源。
同时,相比以往的进程级跟踪方法(比如 ptrace),动态追踪往往只会带来很小的性能损耗(通常在 5% 或者更少)。
动态追踪
说到动态追踪(Dynamic Tracing),就不得不提源于 Solaris 系统的 DTrace。DTrace 是动态追踪技术的鼻祖,它提供了一个通用的观测框架,并可以使用 D 语言进行自由扩展。
DTrace 的工作原理如下图所示。它的运行常驻在内核中,用户可以通过 dtrace 命令,把 D 语言编写的追踪脚本,提交到内核中的运行时来执行。DTrace 可以跟踪用户态和内核态的所有事件,并通过一些列的优化措施,保证最小的性能开销。
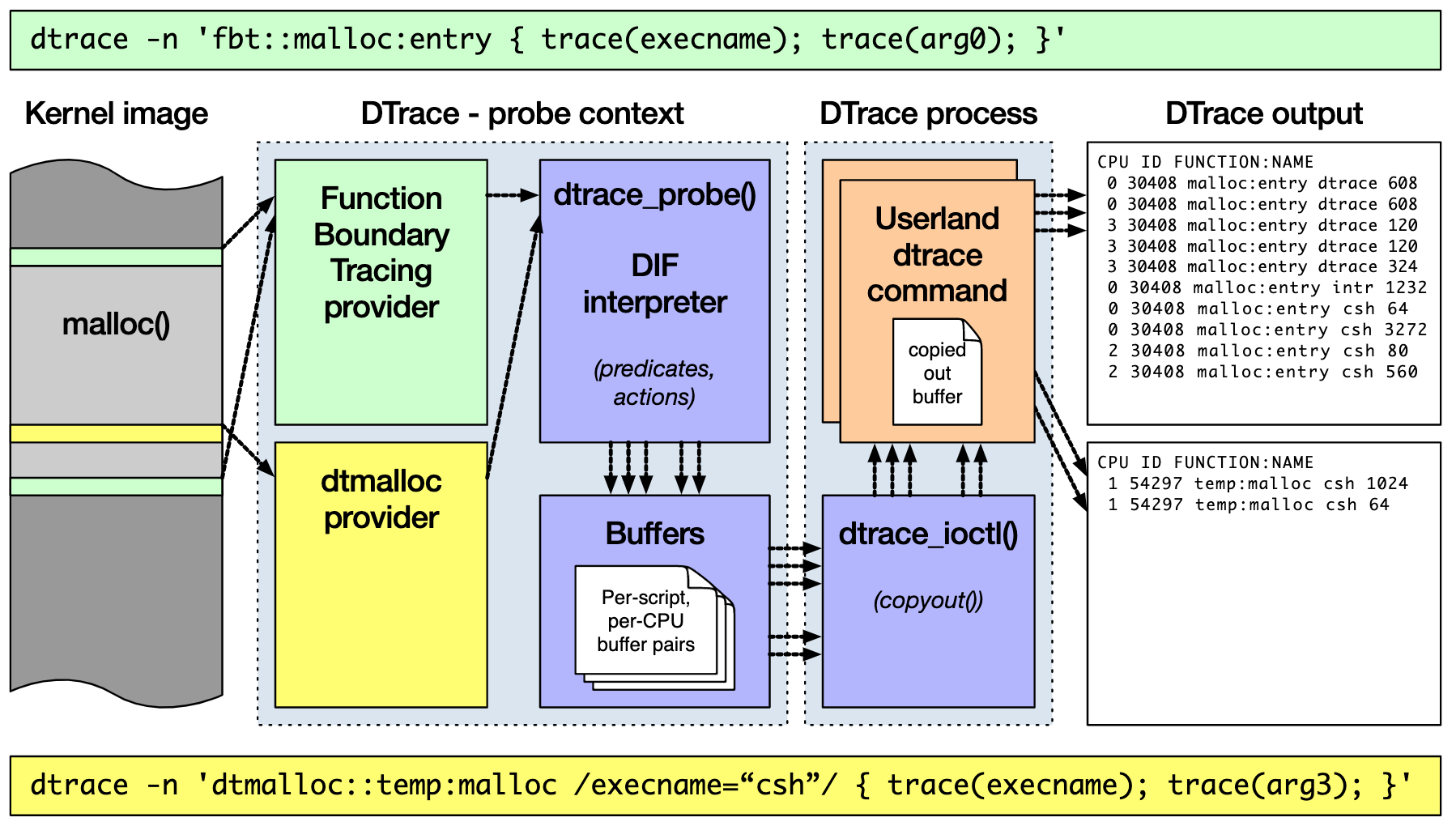
虽然直到今天,DTrace 本身依然无法在 Linux 中运行,但它同样对 Linux 动态追踪产生了巨大的影响。很多工程师都尝试过把 DTrace 移植到 Linux 中,这其中,最著名的就是 RedHat 主推的 SystemTap。
同 DTrace 一样,SystemTap 也定义了一种类似的脚本语言,方便用户根据需要自由扩展。不过,不同于 DTrace,SystemTap 并没有常驻内核的运行时,它需要先把脚本编译为内核模块,然后再插入到内核中执行。这也导致 SystemTap 启动比较缓慢,并且依赖于完整的调试符号表。
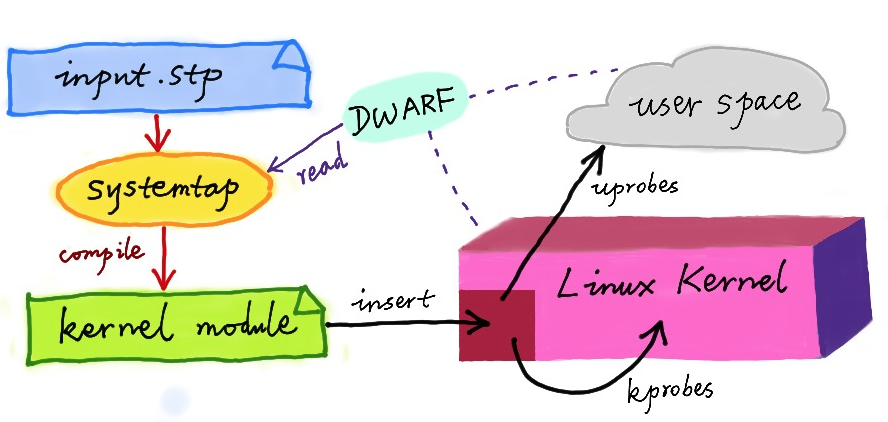
总的来说,为了追踪内核或用户空间的事件,Dtrace 和 SystemTap 都会把用户传入的追踪处理函数(一般称为 Action),关联到被称为探针的检测点上。这些探针,实际上也就是各种动态追踪技术所依赖的事件源。
动态追踪的事件源
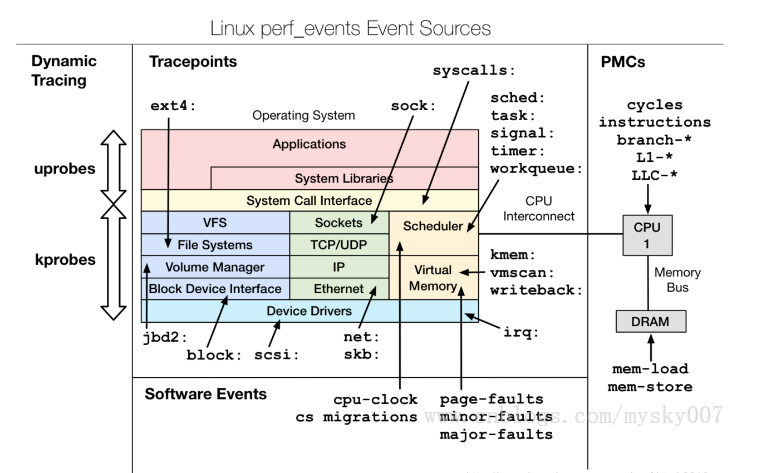
根据事件类型的不同,动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类。它们的关系如下图所示:其中,硬件事件通常由性能监控计数器 PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。
静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时,才会被执行到;未开启时并不会执行。常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(Userland Statically Defined Tracing)探针。
- 跟踪点(tracepoints),实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许事后再添加处理函数。比如在内核中,最常见的静态跟踪方法就是 printk,即输出日志。Linux 内核定义了大量的跟踪点,可以通过内核编译选项,来开启或者关闭。
- USDT 探针,全称是用户级静态定义跟踪,需要在源码中插入 DTRACE_PROBE() 代码,并编译到应用程序中。不过,也有很多应用程序内置了 USDT 探针,比如 MySQL、PostgreSQL等。
动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的 kprobes 和用于用户态的 uprobes。
- kprobes 用来跟踪内核态的函数,包括用于函数调用的 kprobe 和用于函数返回的kretprobe。
- uprobes 用来跟踪用户态的函数,包括用于函数调用的 uprobe 和用于函数返回的uretprobe。
注意,kprobes 需要内核编译时开启 CONFIG_KPROBE_EVENTS;而 uprobes则需要内核编译时开启 CONFIG_UPROBE_EVENTS。
动态追踪机制
而在这些探针的基础上,Linux 也提供了一系列的动态追踪机制,比如 ftrace、perf、eBPF 等。
ftrace 最早用于函数跟踪,后来又扩展支持了各种事件跟踪功能。ftrace 的使用接口跟我们之前提到的 procfs 类似,它通过 debugfs(4.1 以后也支持 tracefs),以普通文件的形式,向用户空间提供访问接口。
这样,不需要额外的工具,你就可以通过挂载点(通常为 /sys/kernel/debug/tracing 目录)内的文件读写,来跟 ftrace 交互,跟踪内核或者应用程序的运行事件。
perf 是我们的老朋友了,我们在前面的好多案例中,都使用了它的事件记录和分析功能,这实际上只是一种最简单的静态跟踪机制。你也可以通过 perf ,来自定义动态事件(perf probe),只关注真正感兴趣的事件。
eBPF 则在 BPF(Berkeley Packet Filter)的基础上扩展而来,不仅支持事件跟踪机制,还可以通过自定义的 BPF 代码(使用 C 语言)来自由扩展。所以,eBPF 实际上就是常驻于内核的运行时,可以说就是 Linux 版的 DTrace。
ftrace
ftrace 通过 debugfs(或者 tracefs),为用户空间提供接口。所以使用 ftrace,往往是从切换到 debugfs 的挂载点开始。
cd /sys/kernel/debug/tracing $ ls README instances set_ftrace_notrace trace_marker_raw available_events kprobe_events set_ftrace_pid trace_options ...
如果这个目录不存在,则说明你的系统还没有挂载 debugfs,你可以执行下面的命令来挂载它:
mount -t debugfs nodev /sys/kernel/debug
ftrace 提供了多个跟踪器,用于跟踪不同类型的信息,比如函数调用、中断关闭、进程调度等。具体支持的跟踪器取决于系统配置,你可以执行下面的命令,来查询所有支持的跟踪器:
cat available_tracers hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
这其中,function 表示跟踪函数的执行,function_graph 则是跟踪函数的调用关系,也就是生成直观的调用关系图。这便是最常用的两种跟踪器。
除了跟踪器外,使用 ftrace 前,还需要确认跟踪目标,包括内核函数和内核事件。其中,
- 函数就是内核中的函数名。
- 而事件,则是内核源码中预先定义的跟踪点。
同样地,可以执行下面的命令,来查询支持的函数和事件:
cat available_filter_functions $ cat available_events
ls 命令会通过 open 系统调用打开目录文件,而 open 在内核中对应的函数名为do_sys_open。
第一步就是把要跟踪的函数设置为 do_sys_open:
echo do_sys_open > set_graph_function
第二步,配置跟踪选项,开启函数调用跟踪,并跟踪调用进程:
echo function_graph > current_tracer $ echo funcgraph-proc > trace_options
第三步,也就是开启跟踪:
echo 1 > tracing_on
第四步,执行一个 ls 命令后,再关闭跟踪:
ls $ echo 0 > tracing_on
实际测试代码如下:
# cat available_tracers blk function_graph wakeup_dl wakeup_rt wakeup function nop # cat available_events|head kvmmmu:kvm_mmu_pagetable_walk kvmmmu:kvm_mmu_paging_element kvmmmu:kvm_mmu_set_accessed_bit kvmmmu:kvm_mmu_set_dirty_bit kvmmmu:kvm_mmu_walker_error kvmmmu:kvm_mmu_get_page kvmmmu:kvm_mmu_sync_page kvmmmu:kvm_mmu_unsync_page kvmmmu:kvm_mmu_prepare_zap_page kvmmmu:mark_mmio_spte # echo do_sys_open > set_graph_function # echo funcgraph-proc > trace_options -bash: echo: write error: Invalid argument # echo function_graph > current_tracer # echo funcgraph-proc > trace_options # echo 1 > tracing_on # ls available_events dynamic_events kprobe_events saved_cmdlines set_ftrace_pid timestamp_mode trace_stat available_filter_functions dyn_ftrace_total_info kprobe_profile saved_cmdlines_size set_graph_function trace tracing_cpumask available_tracers enabled_functions max_graph_depth saved_tgids set_graph_notrace trace_clock tracing_max_latency buffer_percent events options set_event snapshot trace_marker tracing_on buffer_size_kb free_buffer per_cpu set_event_pid stack_max_size trace_marker_raw tracing_thresh buffer_total_size_kb function_profile_enabled printk_formats set_ftrace_filter stack_trace trace_options uprobe_events current_tracer instances README set_ftrace_notrace stack_trace_filter trace_pipe uprobe_profile # echo 0 > tracing_on
第五步,也是最后一步,查看跟踪结果:
cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-12276 | | do_sys_open() {
0) ls-12276 | | getname() {
0) ls-12276 | | getname_flags() {
0) ls-12276 | | kmem_cache_alloc() {
0) ls-12276 | | _cond_resched() {
0) ls-12276 | 0.049 us | rcu_all_qs();
0) ls-12276 | 0.791 us | }
0) ls-12276 | 0.041 us | should_failslab();
0) ls-12276 | 0.040 us | prefetch_freepointer();
0) ls-12276 | 0.039 us | memcg_kmem_put_cache();
0) ls-12276 | 2.895 us | }
0) ls-12276 | | __check_object_size() {
0) ls-12276 | 0.067 us | __virt_addr_valid();
0) ls-12276 | 0.044 us | __check_heap_object();
0) ls-12276 | 0.039 us | check_stack_object();
0) ls-12276 | 1.570 us | }
0) ls-12276 | 5.790 us | }
0) ls-12276 | 6.325 us | }
...
实际测试代码如下:
# cat trace|head -n 100
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-9986 | | do_sys_open() {
0) ls-9986 | | getname() {
.......
0) ls-9986 | | dput() {
0) ls-9986 | | _cond_resched() {
0) ls-9986 | 0.184 us | rcu_all_qs();
0) ls-9986 | 0.535 us | }
0) ls-9986 | 0.954 us | }
0) ls-9986 | 9.782 us | }
在最后得到的输出中:
- 第一列表示运行的 CPU;
- 第二列是任务名称和进程 PID;
- 第三列是函数执行延迟;
- 最后一列,则是函数调用关系图。
你可以看到,函数调用图,通过不同级别的缩进,直观展示了各函数间的调用关系。
当然,我想你应该也发现了 ftrace 的使用缺点——五个步骤实在是麻烦,用起来并不方便。不过,不用担心, trace-cmd 已经帮你把这些步骤给包装了起来。这样,你就可以在同一个命令行
工具里,完成上述所有过程。
你可以执行下面的命令,来安装 trace-cmd :
# Ubuntu $ apt-get install trace-cmd # CentOS $ yum install trace-cmd
安装好后,原本的五步跟踪过程,就可以简化为下面这两步:
trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd report
...
ls-12418 [000] 85558.075341: funcgraph_entry: | do_sys_open() {
ls-12418 [000] 85558.075363: funcgraph_entry: | getname() {
ls-12418 [000] 85558.075364: funcgraph_entry: | getname_flags() {
ls-12418 [000] 85558.075364: funcgraph_entry: | kmem_cache_alloc() {
ls-12418 [000] 85558.075365: funcgraph_entry: | _cond_resched() {
ls-12418 [000] 85558.075365: funcgraph_entry: 0.074 us | rcu_all_qs();
ls-12418 [000] 85558.075366: funcgraph_exit: 1.143 us | }
ls-12418 [000] 85558.075366: funcgraph_entry: 0.064 us | should_failslab();
ls-12418 [000] 85558.075367: funcgraph_entry: 0.075 us | prefetch_freepointer();
ls-12418 [000] 85558.075368: funcgraph_entry: 0.085 us | memcg_kmem_put_cache();
ls-12418 [000] 85558.075369: funcgraph_exit: 4.447 us | }
ls-12418 [000] 85558.075369: funcgraph_entry: | __check_object_size() {
ls-12418 [000] 85558.075370: funcgraph_entry: 0.132 us | __virt_addr_valid();
ls-12418 [000] 85558.075370: funcgraph_entry: 0.093 us | __check_heap_object();
ls-12418 [000] 85558.075371: funcgraph_entry: 0.059 us | check_stack_object();
ls-12418 [000] 85558.075372: funcgraph_exit: 2.323 us | }
ls-12418 [000] 85558.075372: funcgraph_exit: 8.411 us | }
ls-12418 [000] 85558.075373: funcgraph_exit: 9.195 us | }
...
实际测试代码如下:
# trace-cmd report|head -n 100
CPU 0 is empty
cpus=2
ls-10015 [001] 3232.717769: funcgraph_entry: 1.802 us | mutex_unlock();
ls-10015 [001] 3232.720548: funcgraph_entry: | do_sys_open() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname_flags() {
ls-10015 [001] 3232.720549: funcgraph_entry: | kmem_cache_alloc() {
ls-10015 [001] 3232.720550: funcgraph_entry: | _cond_resched() {
ls-10015 [001] 3232.720550: funcgraph_entry: 0.206 us | rcu_all_qs();
ls-10015 [001] 3232.720550: funcgraph_exit: 0.724 us | }
ls-10015 [001] 3232.720550: funcgraph_entry: 0.169 us | should_failslab();
ls-10015 [001] 3232.720551: funcgraph_entry: 0.177 us | memcg_kmem_put_cache();
ls-10015 [001] 3232.720551: funcgraph_exit: 1.792 us | }
ls-10015 [001] 3232.720551: funcgraph_entry: | __check_object_size() {
ls-10015 [001] 3232.720552: funcgraph_entry: 0.167 us | check_stack_object();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.207 us | __virt_addr_valid();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.212 us | __check_heap_object();
ls-10015 [001] 3232.720553: funcgraph_exit: 1.286 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 3.744 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 4.134 us | }
trace-cmd 的输出跟上述 cat trace 的输出是类似的。
通过这个例子我们知道,想要了解某个内核函数的调用过程时,使用 ftrace ,就可以跟踪到它的执行过程。
perf
perf 的功能
- perf 可以用来分析 CPU cache、CPU 迁移、分支预测、指令周期等各种硬件事件;
- perf 也可以只对感兴趣的事件进行动态追踪
- 先对事件进行采样,然后再根据采样数,评估各个函数的调用频率
perf例子
1.内核函数 do_sys_open 的例子
很多人只看到了 strace 简单易用的好处,却忽略了它对进程性能带来的影响。
从原理上来说,strace 基于系统调用 ptrace 实现,这就带来了两个问题:
- 由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
- ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制和进程挂起,会影响目标进程的行为。
在性能敏感的应用(比如数据库)中,我并不推荐你用 strace (或者其他基于 ptrace 的性能工具)去排查和调试。
在 strace 的启发下,结合内核中的 utrace 机制, perf 也提供了一个 trace 子命令,是取代 strace 的首选工具。
相对于 ptrace 机制来说,perf trace 基于内核事件,自然要比进程跟踪的性能好很多。
第二个 perf 的例子是用户空间的库函数
# 为/bin/bash添加readline探针
$ perf probe -x /bin/bash 'readline%return +0($retval):string’
# 采样记录
$ perf record -e probe_bash:readline__return -aR sleep 5
# 查看结果
$ perf script
bash 13348 [000] 93939.142576: probe_bash:readline__return: (5626ffac1610 <- 5626ffa46739) arg1="ls"
# 跟踪完成后删除探针
$ perf probe --del probe_bash:readline__return
BPF
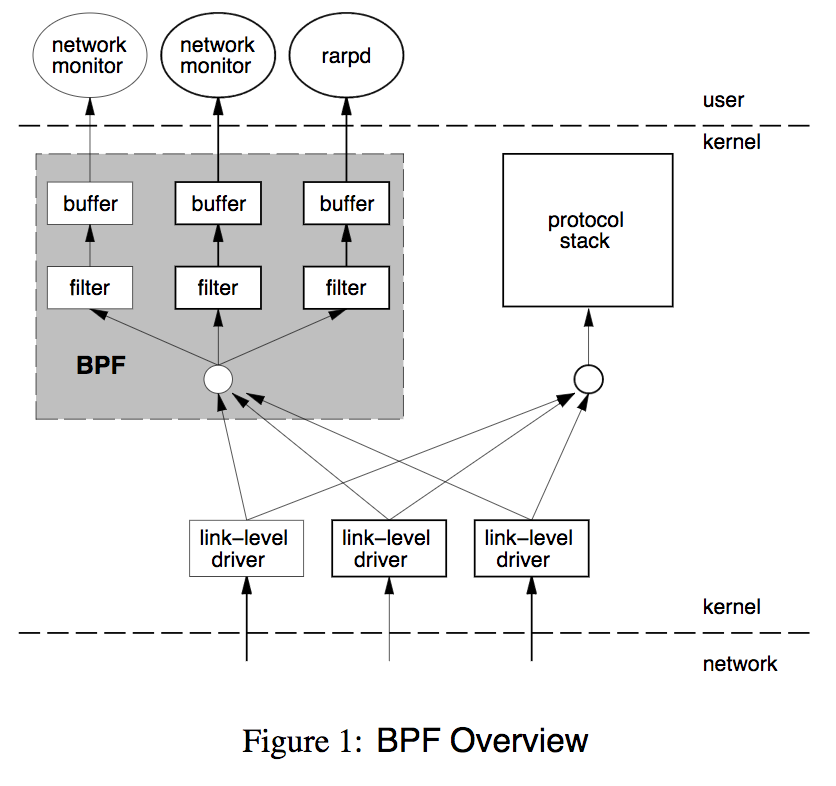
上图是BPF的位置和框架,需要注意的是kernel和user使用了buffer来传输数据,避免频繁上下文切换。BPF虚拟机非常简洁,由累加器、索引寄存器、存储、隐式程序计数器组成
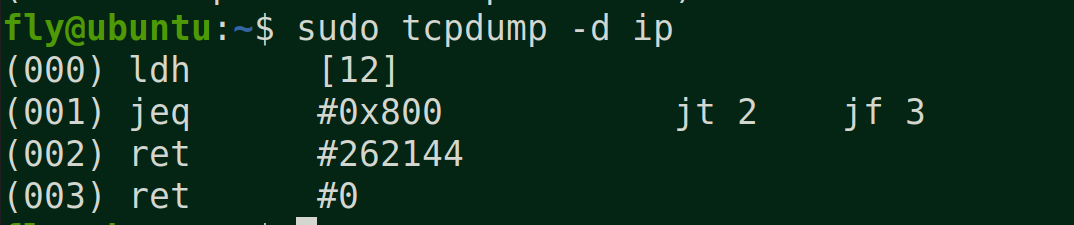
BPF只使用了4条虚拟机指令,就能提供非常有用的IP报文过滤
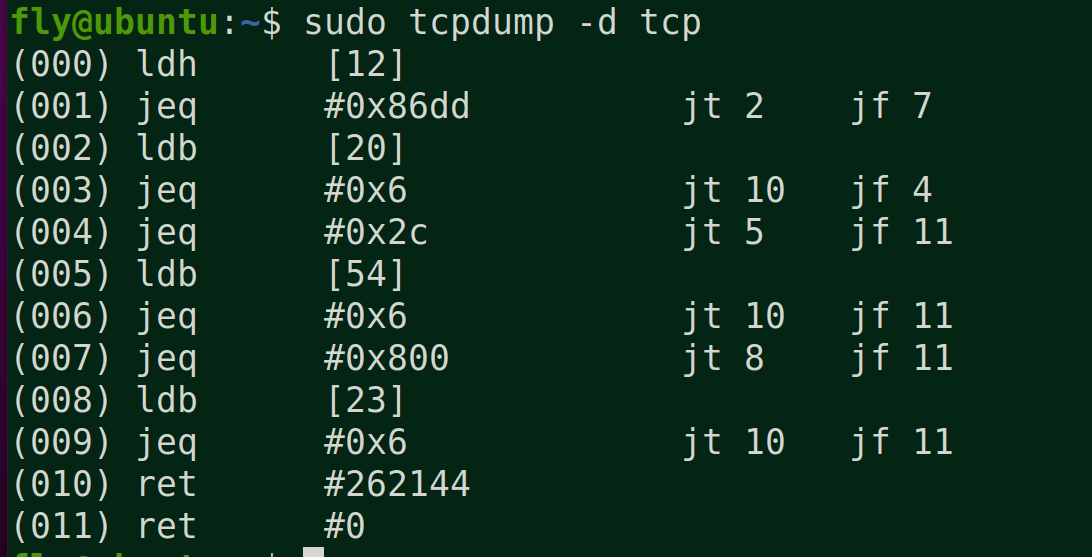
1 (000) ldh [12] // 链路层第12字节的数据(2字节)加载到寄存器,ethertype字段 2 (001) jeq #0x86dd jt 2 jf 7 // 判断是否为IPv6类型,true跳到2,false跳到7 3 (002) ldb [20] // 链路层第20字节的数据(1字节)加载到寄存器,IPv6的next header字段 4 (003) jeq #0x6 jt 10 jf 4 // 判断是否为TCP,true跳到10,false跳到4 5 (004) jeq #0x2c jt 5 jf 11 // 可能是IPv6分片标志,true跳到5,false跳到11 6 (005) ldb [54] // 我编不下去了... 7 (006) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11 8 (007) jeq #0x800 jt 8 jf 11 // 判断是否为IP类型,true跳到8,false跳到11 9 (008) ldb [23] // 链路层第23字节的数据(1字节)加载到寄存器,next proto字段 10 (009) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11 11 (010) ret #262144 // 返回true 12 (011) ret #0 // 返回0
应用
tcpdump 就是使用的bpf 过滤规则
eBPF
eBPF 就是 Linux 版的 DTrace,可以通过 C 语言自由扩展(这些扩展通过 LLVM 转换为 BPF 字节码后,加载到内核中执行)。相对于BPF做了一些重要改进,首先是效率,这要归功于JIB编译eBPF代码;其次是应用范围,从网络报文扩展到一般事件处理;最后不再使用socket,使用map进行高效的数据存储。
根据以上的改进,内核开发人员在不到两年半的事件,做出了包括网络监控、限速和系统监控。
目前eBPF可以分解为三个过程:
- 以字节码的形式创建eBPF的程序。编写C代码,将LLVM编译成驻留在ELF文件中的eBPF字节码。
- 将程序加载到内核中,并创建必要的eBPF-maps。eBPF具有用作socket filter,kprobe处理器,流量控制调度,流量控制操作,tracepoint处理,eXpress Data Path(XDP),性能监测,cgroup限制,轻量级tunnel的程序类型。
- 将加载的程序attach到系统中。根据不同的程序类型attach到不同的内核系统中。程序运行的时候,启动状态并且开始过滤,分析或者捕获信息
源码路径:
bpf的系统调用: kernel/bpf/syscall.c
bpf系统调用的头文件:include/uapi/linux/bpf.h
入口函数: int bpf(int cmd, union bpf_attr *attr, unsigned int size)
eBPF命令 BPF_PROG_LOAD 验证并且加载eBPF程序,返回一个新的文件描述符。 BPF_MAP_CREATE 创建map并且返回指向map的文件描述符 BPF_MAP_LOOKUP_ELEM 通过key从指定的map中查找元素,并且返回value值 BPF_MAP_UPDATE_ELEM 在指定的map中创建或者更新元素(key/value 配对) BPF_MAP_DELETE_ELEM 通过key从指定的map中找到元素并且删除 BPF_MAP_GET_NEXT_KEY 通过key从指定的map中找到元素,并且返回下个key值
eBPF 追踪的工作原理:
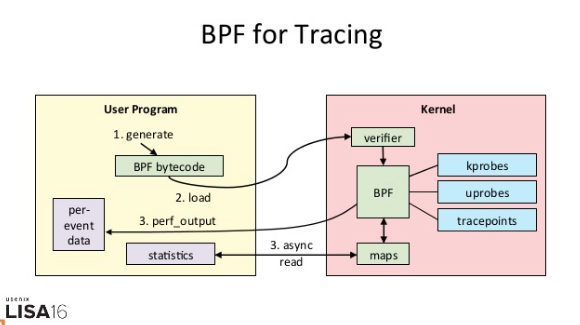
eBPF 的执行需要三步:
- 从用户跟踪程序生成 BPF 字节码;
- 加载到内核中运行;
- 向用户空间输出结果
SystemTap 和 sysdig
SystemTap 也是一种可以通过脚本进行自由扩展的动态追踪技术。
在 eBPF 出现之前,SystemTap 是 Linux 系统中,功能最接近 DTrace 的动态追踪机制
所以,从稳定性上来说,SystemTap 只在 RHEL 系统中好用,在其他系统中则容易出现各种异常问题。
当然,反过来说,支持 3.x 等旧版本的内核,也是 SystemTap 相对于 eBPF 的一个巨大优势。
sysdig 则是随着容器技术的普及而诞生的,主要用于容器的动态追踪。
sysdig 汇集了一些列性能工具的优势,可以说是集百家之所长。
这个公式来表示 sysdig 的特点: sysdig = strace + tcpdump + htop + iftop + lsof + docker inspect
如何选择追踪工具
- 在不需要很高灵活性的场景中,使用 perf 对性能事件进行采样,然后再配合火焰图辅助分析,就是最常用的一种方法;
- 而需要对事件或函数调用进行统计分析(比如观察不同大小的 I/O 分布)时,就要用 SystemTap 或者 eBPF,通过一些自定义的脚本来进行数据处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号