VLA相关论文简介-摘要-说明
1. 前言
关于VLA相关论文的简单浏览和整理。
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
2. 正文
2.1 RT-1
RT-1是一个重新设计的网络结构,主体是预训练的视觉模型加上用解释器处理过的语言指令,两部分再一起通过transformer架构输出机器人的动作指令,学习范式是模仿学习,训练数据是在google实验室中的两个厨房环境记录的操控移动机械臂完成抓取与放置动作时的记录,数据包括文字指令、过程中的机器人视觉图像、每一帧图像对应的机器人的动作指令(底盘速度,机械臂末端速度),这个数据库在后面反复用到,可以叫做RT-1数据库。因为数据相对局限,RT-1只能接受在数据库中出现过的指令,指令的基本结构为“动作 + 目标物体 + 目标位置”,在RT-1数据库中这些基本结构可以互相交换排列组合,但超出这个范围RT-1就无能为力了。
机器人指令结构: “动作 + 目标物体 + 目标位置”
例子: 把可乐从冰箱放到桌子上

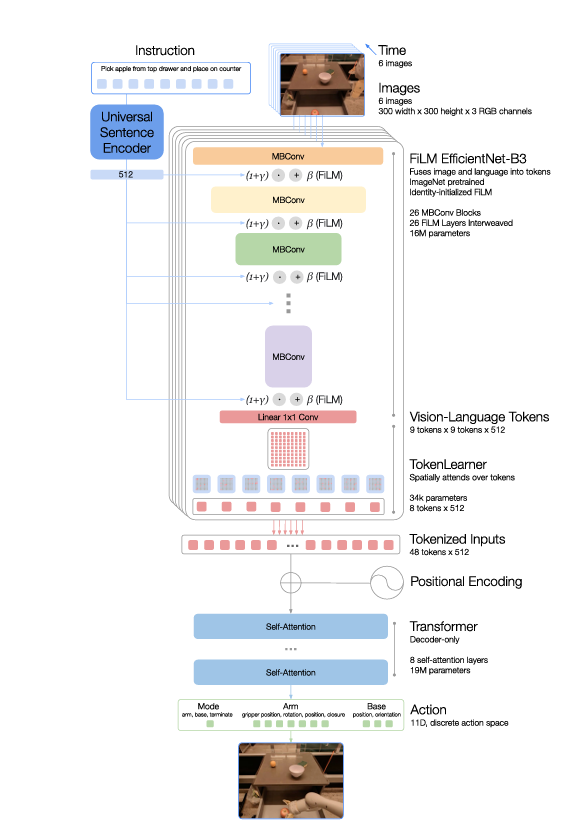
2.2 RT-2
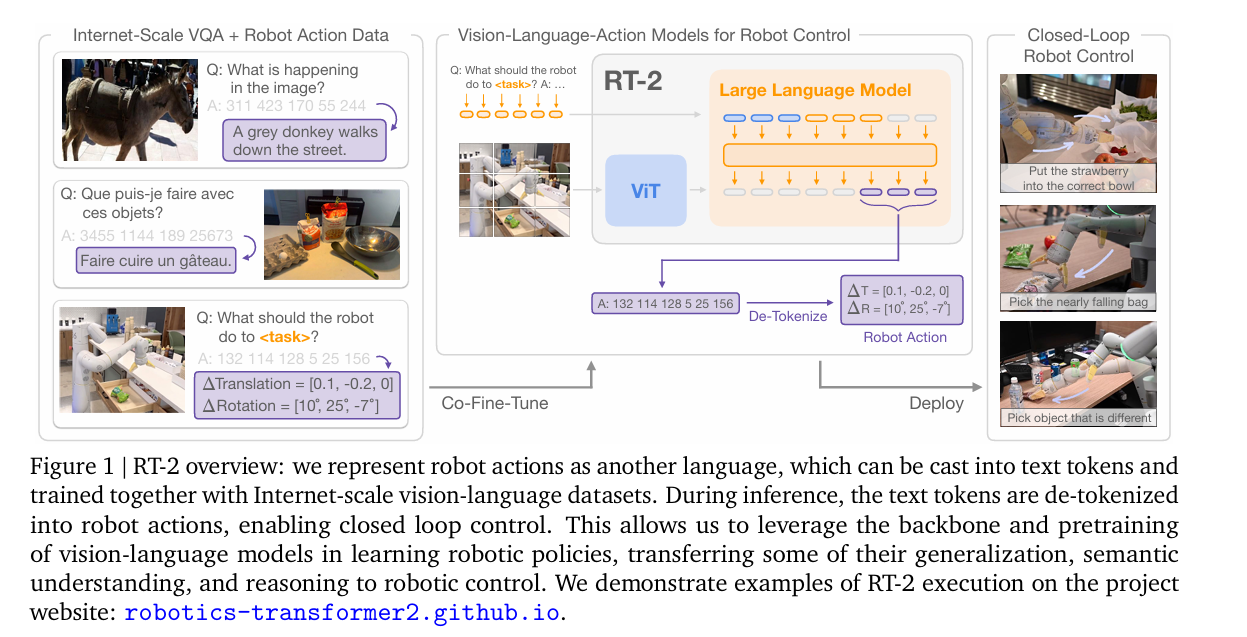
为了快速地扩展RT-1对外界环境的认知,RT-2出现了。RT-2抛弃了RT-1的设计,采用了利用网络上海量图文数据预训练出的图文模型,这些模型的规模可以最大达到55B的参数量,远远超过RT-1的35M的规模。这些图文模型被训练来回答关于图片的问题,原本的输出是文字,RT-2创造性的将机器人动作重新编码,使得编码为“文字”的机器人动作作为图文模型的输出,下图是一个例子,在完全不改动原始图文模型结构的情况下,利用RT-1数据库来finetune预训练的图文模型,由此得到了RT-2模型
为什么叫VLA,这篇论文是鼻祖了

2.3 RT-X
https://arxiv.org/pdf/2310.08864
到目前为止,RT-2机器人的动作还局限于RT-1数据库中简单的抓取,移动,放置三个动作。没错,下一步,RT-X把提高扩展的目标放在了指令中的“动作”。通过在全球机器人实验室收集机械臂操作的数据集,历时大半年,一共得到了大大小小60多个不同实验室的数据集,集合在一起取名叫Open X Embodiment
3. 后记
这篇博客暂时记录到这里,日后我会继续补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号