【论文概述】带臂机器人运动控制任务(包括四足、双轮足等)
1. 前言
本文对带臂机器人的运动控制任务做一个简要总结
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
2. 正文
2.1 《Versatile Multi-Contact Planning and Control for Legged Loco-Manipulation》
作者单位:ETH
Arxiv: 17 Aug 2023
相关博客:https://yhykid.github.io/2024/11/03/2024-11-7组会分享/
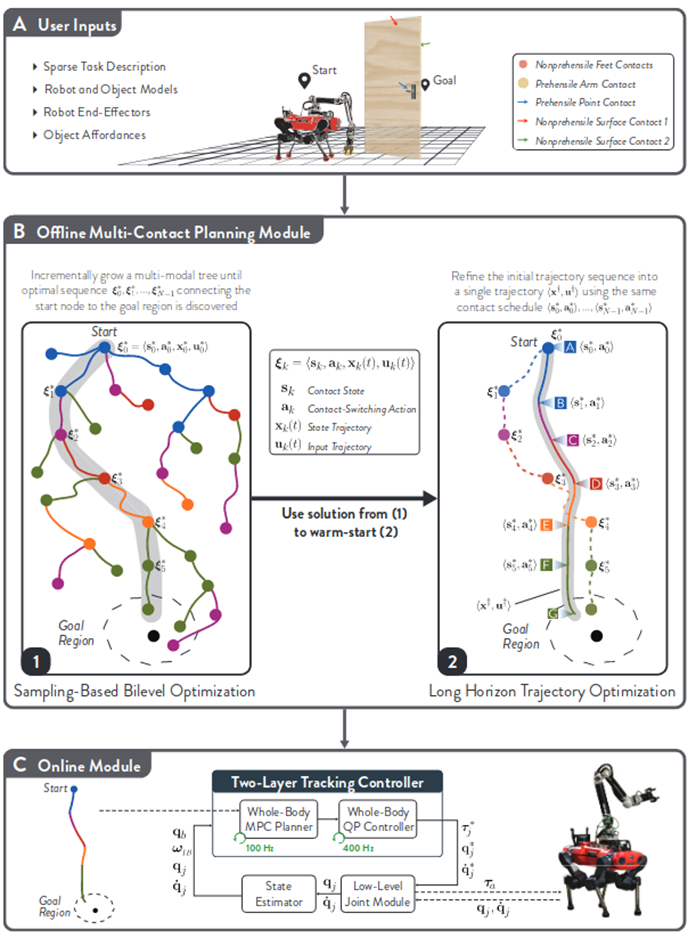
问题先验:
- 强化学习,虽然消除了对精确模型的需求,但是人工设计奖励函数和较长的训练时间仍然困扰着人们,对这一方法的改进是使用模仿学习,但是每一个专家轨迹只对应特定的任务,无法实现其通用性
- 轨迹优化(TO),但是移动操作是一个混合规划问题(决策变量的离散和连续),所以计算会非常困难
- 基于采样的方法和图搜索方法(如运动基元 RRT 等)只能针对特定任务进行设计,而无法保证通用性
主要定义:
1.用户输入:定义机器人和目标的模型,任务描述和 affordance。也就是确定一下任务的规则,比如开门任务中,门上哪些部分是可抓握的或者是可以用足端推动的
2.离线规划器:使用基于采样的图搜索方法来找到可行但是次优的轨迹,并将求解的可行轨迹用于热启动轨迹优化来后处理得到连续最优轨迹。
较复杂的动力学模型来建模(最小但高保真 SRB),输入机器人和目标物体的状态(关节角位姿等),输出末端执行器的接触力和关节角速度
虽然一个由多个平滑轨迹组成的序列(即一个轨迹规划方案)在其单独的部分上都是平滑的,但整体上却可能不平滑。这尤其会发生在轨迹序列的生成过程中存在随机因素的情况下。所以我们使用轨迹优化后处理来增强轨迹的质量。目的是平滑轨迹并消除多余的 action。这会导致更小的力,更鲁棒的行为,提高了任务的成功性和稳定性。
3.在线跟踪模块:对于静态环境,设计一个跟踪器是很容易的,但是我们的环境是动态的,所以为了保证安全性和减小误差,对于离线规划器计算出来的轨迹,我们使用了两层的控制器来跟踪。第一层是以跟踪轨迹为主要目的的 MPC,他在这里充当一个滤波器的作用,对于不符合规定的动作轨迹进行筛除,并且这个 MPC 是独立于任务的。第二层是一个全身控制器,用来跟踪 MPC 输出的关节角及角速度
2.2 《UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers》
作者单位:斯坦福大学、哥伦比亚大学、Google deepmind
年份:2024.7
相关博客:https://blog.csdn.net/v_JULY_v/article/details/142769965
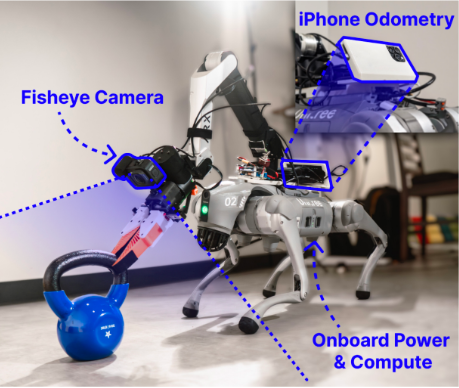
上图机器人系统由一个12自由度的Unitree Go2四足机器人和一个6自由度的ARX5机械臂组成,二者均由Go2的电池供电
UMI-on-legs主要由两部分组成:
- diffusion policy:UMI的腕部摄像头视图作为输入,在摄像头坐标系中输出末端执行器姿态目标序列;
- LOW-LEVEL的WBC,通过输出腿部和手臂关节位置来跟踪末端执行器姿态目标。
(1) a high-level diffusion-based manipulation
policy [2] which takes as input wrist-mounted camera views and outputs sequences of end-effector pose
targets into the future in the camera frame, and (2) a low-level whole-body controller which tracks end
effector pose targets by outputting joint position targets for both the legs and arm.
用iphone做里程计
2.3 《Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots》
作者单位:1Stanford University, 2 Columbia University, 3Toyota Research Insititute
一作:chicheng大佬(提出diffusion pollicy的那个大佬)
主要内容:
- 一套基于UMI夹爪的框架,兼具数据的采集和处理过程

- policy输入观测空间为RGB 图像、相对 EE 姿势和夹持器宽度
比较好奇的是UMI是怎么仅利用RGB相机和镜面反射就可以获得ee pos的呢??
原文提到使用的是OBR-SLAM的方法,是一种视觉SLAM,文章最后还用MoCap来校验精度:

视觉SLAM应该能根据鱼眼相机和IMU获得相对上一帧的相对位姿。
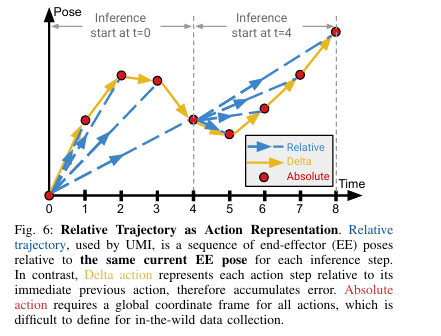
末端执行器 (EE) 姿势是 UMI 观察和动作空间的核心。为了避免依赖于特定于实施例/部署的坐标,我们表示相对于抓手的当前 EE 姿势的所有 EE 姿势。
相对pos(文章使用)、增量pos和绝对pos
利用 Vision Transformer (ViT)作为视觉编码器,因为与 ResNet相比,它具有强大的容量,这对于需要复杂感知的任务至关重要能力。

2.4 《Helpful DoggyBot: Open-World Object Fetching using Legged Robots and Vision-Language Models》
项目链接:https://helpful-doggybot.github.io/
作者单位:斯坦福大学 wuqi fuzipeng chengxuxin三个大佬同台了,指导老师wangxiaolong也很厉害
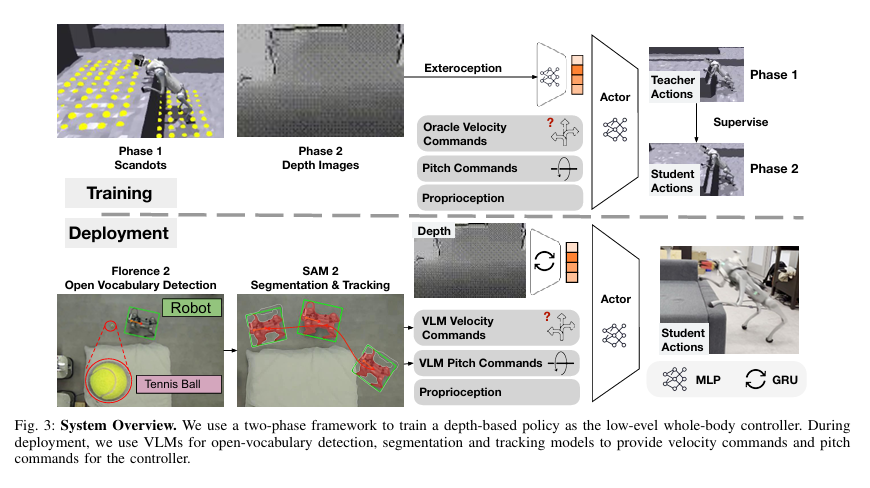
狗嘴里叼东西。作者的整体框图并不是很难理解:先用深度图像和激光雷达的scandots进行第一次训练,然后将结果通过两阶段蒸馏的方式训练处一个学生网络,但该网络只包含输入的深度视觉信息以及结合VLM的指令信息(当然这就不是重点了)。
2.5 《Open X-Embodiment: Robotic learning datasets and RT-X models》
作者太多了,引用一长串,那你也得写

- 大语言模型基于大量的语料库,而机器人领土使用大量的数据存在一些困难。
- 最大的开源机器人数据集:全球机器人实验室机械臂操作的数据集,汇总和收集来自全球不同实验室机器人数据集的项目。
- Open-X-Embodiment数据集内容为多个团队在示教操作下记录轨迹数据和对应时刻的观测图像,并统一到了Rlds数据格式(eposide->step->observation/action)
3. 后记
这篇博客暂时记录到这里,日后我会继续补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号