【H2O系列】关于H2O和OmniH2O代码安装及代码解读摘要
0. 前言
这篇博客主要用于过程记录H2O代码部分的参数解读部分。
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
[NOTE]:这篇博客笔者也有疏忽的地方,仅供参考!!!!
1. 论文&项目
项目地址:https://omni.human2humanoid.com/
我自己总结的论文摘要:https://www.cnblogs.com/myleaf/p/18727733
论文题目:
OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
2.2 Dataset
2.2.1 dataset简介
文章要求两个数据集代码:SMPL和AMASS
SMPL是人体骨骼点以及mesh参数化的数据集,只包含个体,不包含motion
AMASS是包含SMPL的,包含了人体动作的motions
- 性质:SMPL是生成3D人体网格的模型,AMASS是包含SMPL参数的运动捕捉数据集。
- 功能:SMPL用于建模,AMASS用于提供运动数据。
- 应用场景:SMPL用于生成静态或动态人体模型,AMASS用于分析和合成人体运动。
AMASS是一个由不同的光学标记运动捕捉数据集统一表示在一个公共框架和参数化下的大型人体运动数据库¹。它包含了超过40小时的运动数据,涵盖了300多个主体和11000多个运动¹。它使用了SMPL²人体模型,它是一种基于混合形状和姿态空间的生成式人体模型,可以用少量的参数来描述人体的形状和姿态²。
AMASS使用了一种新的方法MoSh++⁴,它可以将运动捕捉数据转换为由刚性身体模型表示的逼真的3D人体网格⁴。这种方法可以适用于任意的标记集,同时恢复软组织动力学和逼真的手部运动⁴。AMASS数据集是经过严格筛选和质量控制的,它提供了人体运动的丰富和多样的样本,可以用于训练和评估人体姿态和形状估计的方法。
AMASS数据库是一个JSON格式的文件,它存储了每个运动捕捉数据集的元数据和SMPL人体模型的参数。每个文件的文件名是由数据集名称、主体编号和运动编号组成的,例如CMU_01_01.json表示来自CMU数据集的第一个主体的第一个运动1
下图中的一些参数在代码里也有用到,乍看下可能不是很理解为什么,这回总结了下比较容易看懂。。

2.2.2 dataset代码
SMPL:需要注册
https://smpl.is.tue.mpg.de/login.php
下载解压完是这些:
修改名字备用:
AMASS:也需要注册
模型格式:

https://amass.is.tue.mpg.de/register.php
详情参考自:https://blog.csdn.net/qq_53930200/article/details/137646272
2.2.3 PHC
Perpetual Humanoid Control for Real-time Simulated Avatars
H2O的共一作者,铺垫工作是人体retargeted的。。。。。
项目地址:https://github.com/ZhengyiLuo/PHC/

2. 论文代码
在主要代码的xxx_teleop_env.py里面有很多对观测值的处理:
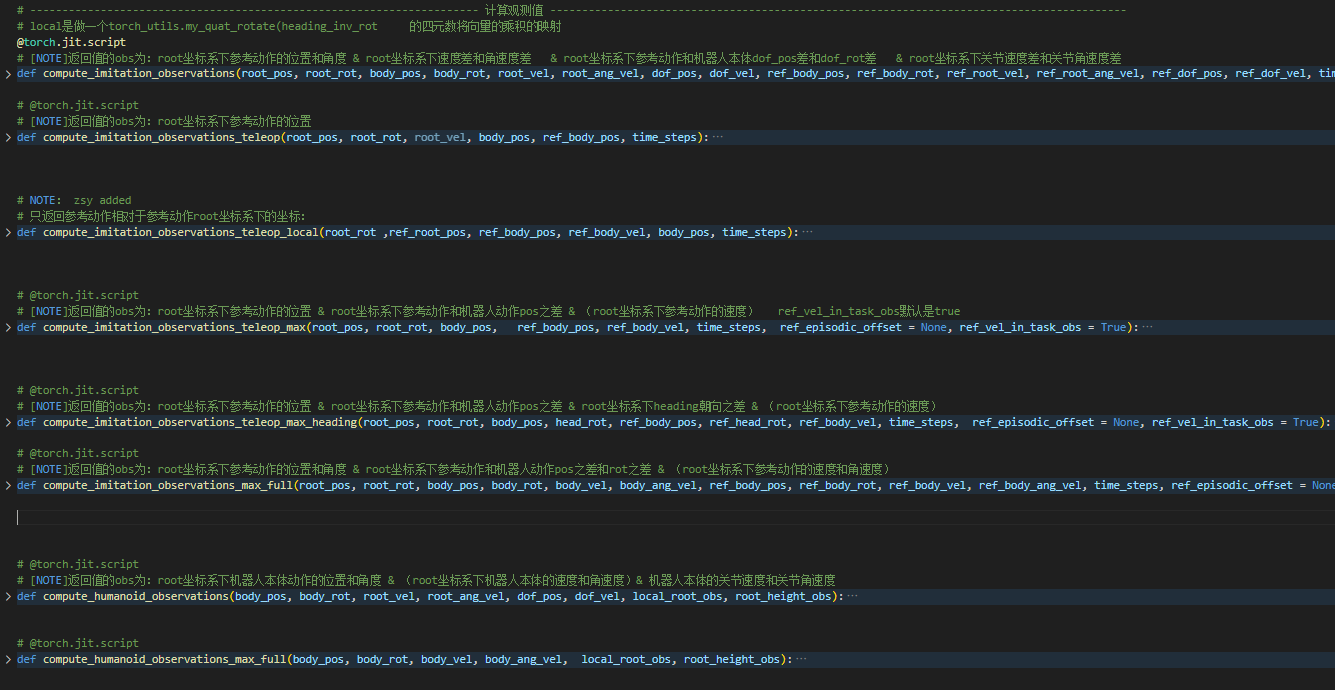
我这里作一个简单的总结:
local_ref_body_pos是ref_body_pos和root_pos的差值
diff_local_body_pos是ref_body_pos和body_pos的差值
body_pos[:,0,:]是root_pos
下面将一些函数的观测值进行列出:
个人认为这些观测值的内容主要是进行坐标系的变换,比如ref的部分从global坐标系变换到pelvis坐标系下,也就是上半身的坐标系。
-----2025.3.1更新:验证我的想法了,确实是这个样子。普通的dof_pos都是相对于其父类的,但下面这些操作相当于将观测值从父类坐标系下转换到了root坐标系下(这里的root可以指的是机器人pelvislink,也就会盆骨的那个位置)
我是从函数里面发现的,一个值,乘以了一个坐标系的root_rotation_base,就会被映射到那个坐标系,而这个映射正是:
而操作就比如:
或者
这里作者是只字未提的,只能靠猜测和推理。初来一看直接被干蒙了。。。。。
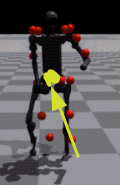



笔者注:这里其实是在做坐标系变换的任务,因为参考动作时世界坐标系的,在机器人的本体看来一些数据比较奇怪,所以需要将世界坐标系折算的本体坐标系,这样即便是机器人本体发生位移,相对参考坐标也不会受到影响,当然也可以采取目标动作的相对坐标,这样就不需要考虑坐标系转换的事情了 --2025.5.7更新
2.1 compute_imitation_observations:
obs.append(diff_local_body_pos_flat.view(B, time_steps, -1)) # 1 * timestep * J * 3
obs.append(torch_utils.quat_to_tan_norm(diff_local_body_rot_flat).view(B, time_steps, -1)) # 1 * timestep * J * 6
obs.append(diff_local_root_vel.view(B, time_steps, -1)) # timestep * J * 3
obs.append(diff_local_root_ang_vel.view(B, time_steps, -1)) # timestep * J * 3
obs.append(local_ref_body_pos.view(B, time_steps, -1)) # timestep * J * 3
obs.append(local_ref_body_rot.view(B, time_steps, -1)) # timestep * J * 6
obs.append(dof_diff.view(B, time_steps, -1)) # timestep * J * 3
obs.append(dof_vel_diff.view(B, time_steps, -1)) # timestep * J * 3
2.2 compute_imitation_observations_teleop:
obs.append(local_ref_body_pos.view(B, time_steps, -1)) # timestep * J * 3
2.3 compute_imitation_observations_teleop_max:
obs.append(diff_local_body_pos_flat.view(B, time_steps, -1)) # 1 * timestep * J * 3
obs.append(local_ref_body_pos.view(B, time_steps, -1)) # timestep * J * 3
2.4 compute_imitation_observations_teleop_max_heading:
obs.append(diff_local_body_pos_flat.view(B, time_steps, -1)) # 1 * timestep * J * 3
obs.append(local_ref_body_pos.view(B, time_steps, -1)) # timestep * J * 3
obs.append(diff_local_heading_rot_flat.view(B, time_steps, -1)) # 1 * timestep * J * 3
2.5 compute_imitation_observations_max_full:
obs.append(diff_local_body_pos_flat.view(B, time_steps, -1)) # 1 * timestep * J * 3
obs.append(torch_utils.quat_to_tan_norm(diff_local_body_rot_flat).view(B, time_steps, -1)) # 1 * timestep * J * 6
obs.append(diff_local_vel.view(B, time_steps, -1)) # timestep * J * 3
obs.append(diff_local_ang_vel.view(B, time_steps, -1)) # timestep * J * 3
obs.append(local_ref_body_pos.view(B, time_steps, -1)) # timestep * J * 3
obs.append(local_ref_body_rot.view(B, time_steps, -1)) # timestep * J * 6
2.6 compute_humanoid_observations:
obs_list += [local_body_pos, local_body_rot_obs, local_body_vel, local_body_ang_vel, dof_pos, dof_vel] # [23x3-3,23x6,1x3,1x3,23x1,23x1]
2.7 compute_humanoid_observations_max_full:
obs_list += [local_body_pos, local_body_rot_obs, local_body_vel, local_body_ang_vel] # [23x3-3 , 23x6 ,23x3 , 23x3 ] = 342
3. 正文2
def compute_self_and_task_obs(self, ):这个函数里记录了关于不同观测值的调用,下面我来简单的总计一下:
对比一下不同version的观测值的不同。
3.1 v1
self_obs = compute_humanoid_observations(body_pos, body_rot, root_vel, root_ang_vel, dof_pos, dof_vel, True, True) # 122
task_obs = compute_imitation_observations(root_pos, root_rot, body_pos, body_rot, root_vel, root_ang_vel, dof_pos, dof_vel, ref_body_pos, ref_body_rot, ref_root_vel, ref_root_ang_vel, ref_joint_pos, ref_joint_vel, 1)
obs = torch.cat([self_obs, task_obs, self.projected_gravity, self.actions], dim = -1)
3.2 v-min
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, delta_base_pos, delta_heading,
ref_dof_pos, ref_dof_vel, ref_base_vel, ref_base_ang_vel,ref_base_gravity,
self.actions], dim = -1)
3.3 v-min2
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, delta_base_pos, delta_heading,
ref_dof_pos, self.actions], dim = -1)
3.4 v-teleop
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, delta_base_pos, delta_heading, # 19dim + 19dim + 3dim + 3dim + 3dim + 2dim + 1dim
task_obs, # 3xselected_dim = 18dim
self.actions], dim = -1) # 19dim
3.5 v-teleop-clean
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim + 3dim
task_obs, # 3xselected_dim = 18dim
self.actions], dim = -1) # 19dim
3.6 v-teleop-superclean
obs = torch.cat([dof_pos, dof_vel, # 19dim + 19dim
task_obs, # 3xselected_dim = 18dim
self.actions], dim = -1) # 19dim
3.7 v-teleop-extend
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim + 3dim
task_obs, # 3xselected_dim = 18dim
self.actions], dim = -1) # 19dim
3.8 v-teleop-extend-nolinvel
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, # 3xselected_dim = 24dim
self.actions], dim = -1) # 19dim
3.9 v-teleop-extend-max
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.10 v-teleop-extend-max_no_vel
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions,
history_to_be_append], dim = -1) # 19dim
else:
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.11 v-teleop-extend-vr-max
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions,
history_to_be_append], dim = -1) # 19dim
else:
obs = torch.cat([dof_pos, dof_vel, base_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.12 v-teleop-extend-vr-max-nolinvel
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions,
history_to_be_append], dim = -1) # 19dim
else:
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.13 v-teleop-extend-vr-max-nolinvel-heading
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions,
history_to_be_append], dim = -1) # 19dim
else:
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.14 v-teleop-extend-max-full
obs = torch.cat([ self_obs,
task_obs, #
self.actions], dim = -1) # 342 + 552 + 19 = 913
3.15 v-teleop-extend-max-nolinvel
obs = torch.cat([dof_pos, dof_vel, base_ang_vel, base_gravity, # 19dim + 19dim + (no 3dim) + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.16 v-teleop-extend-max-acc
obs = torch.cat([dof_pos, dof_vel, base_acc, base_ang_vel, base_gravity, # 19dim + 19dim + 3dim + 3dim + 3dim
task_obs, #
self.actions], dim = -1) # 19dim
3.17 num_privileged_obs
if self.cfg.env.num_privileged_obs is not None:
# privileged obs
# 总共正好77
self.privileged_info = torch.cat([
self._base_com_bias,#3
self._ground_friction_values[:, self.feet_indices],#2
self._link_mass_scale,#len(self.cfg.domain_rand.randomize_link_body_names)#8
self._kp_scale,#19
self._kd_scale,#19
self._rfi_lim_scale,#19
self.contact_forces[:, self.feet_indices, :].reshape(self.num_envs, 6),#6
torch.clamp_max(self._recovery_counter.unsqueeze(1), 1),#1
], dim=1)
# 所以这步在原来基础上加了77维,e.g.:913 + 77 = 990
privileged_obs_buf = torch.cat([obs_buf_denoise, self.privileged_info], dim=1)
4.代码&解决&logs
4.1
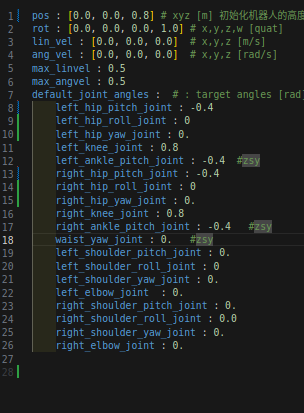
G1机器人关节和默认关节的比较:
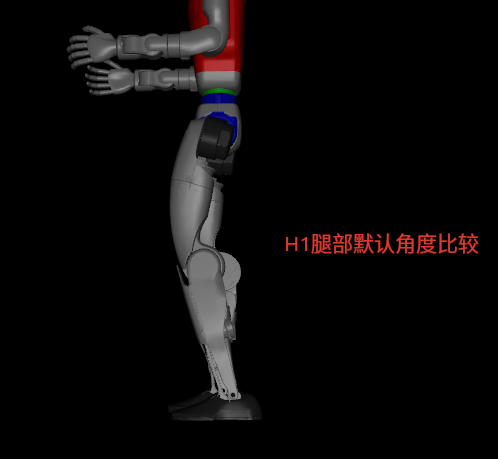
所以需要更改default的joint,因为原来是H1的关节角度。
4.2
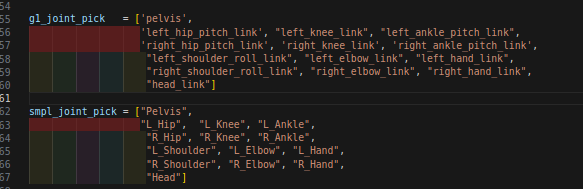
SMPL只映射了腿,手臂和pelvis盆骨,和torso啥的没关系。。。以及手或者头。。

这是;训练的测试图,可以看到还有一定的差距

这样对比就可以解决我最开始疑惑的点了,到底在文件中修不修改torso_linK为waits_yaw_link,现在看来可能不需要了。因为key_points追踪的是pelvis,这是H1和G1共有的。
不过头部;略微有点高了。。。。
4.3
改变了高度和手部的长度后,感觉抖动有明显的改善。。。

4.4 motion
初步理清了motion的一些量的具体涵义。。
在/home/zhushiyu/文档/H2O_Git_version/h2o/H2O/human2humanoid-main/phc/phc/utils/motion_lib_g1.py文件目录下:
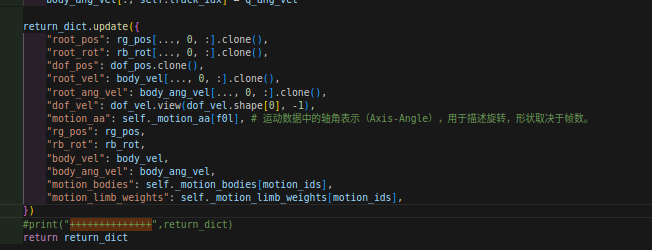
这些是load_motion的主要返回值。。
- '
root_pos': tensor([[-0.4469, 1.0703, 0.8083]] - '
root_rot': tensor([[ 0.0281, -0.0135, 0.2446, 0.9691]] - '
dof_pos': tensor([[-0.0842, 0.2612, -0.0268, 0.1347, 0.0000, 0.0384, -0.3478, -0.1618, 0.2350, 0.0000, 0.1514, -1.0371, 0.9073, 0.3638, 0.7175, -1.3636, -0.3033, 0.4266, 0.4514]] - '
root_vel': tensor([[0.0178, 0.0134, 0.0032]] - '
root_ang_vel': tensor([[-0.0021, 0.0019, 0.0455]]
上面这些是pelvis的估计,也就是盆骨的位置的估计。 - '
dof_vel': tensor([[ 0.0724, -0.0061, -0.0271, -0.0121, 0.0000, 0.1166, 0.0555, 0.0856,
-0.0610, 0.0000, -0.0454, 0.0103, -0.0722, -0.0209, -0.0070, 0.0695,
0.0324, -0.0042, 0.0509]], device='cuda:0' - '
motion_aa': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], - '
rg_pos': tensor([[[-0.4468, 1.0705, 0.8083],
[-0.4762, 1.1334, 0.7089],
[-0.4983, 1.1821, 0.6812],
[-0.4639, 1.2430, 0.5756],
[-0.5133, 1.2829, 0.3925],
[-0.5613, 1.3588, 0.1062],
[-0.4149, 1.0202, 0.7027],
[-0.3908, 0.9758, 0.6698],
[-0.3337, 0.9648, 0.5573],
[-0.3547, 0.9058, 0.3739],
[-0.3861, 0.8180, 0.0887],
[-0.4468, 1.0705, 0.8083],
[-0.5105, 1.1327, 1.1037],
[-0.5242, 1.1703, 1.1095],
[-0.5137, 1.2721, 1.0949],
[-0.4983, 1.3527, 1.0962],
[-0.3898, 0.9729, 1.0954],
[-0.3566, 0.9508, 1.1022],
[-0.2674, 1.0011, 1.0883],
[-0.2042, 1.0535, 1.0885]]] - '
rb_rot': tensor([[[ 0.0280, -0.0131, 0.2451, 0.9690],
[ 0.0385, -0.0545, 0.2437, 0.9676],
[ 0.1838, -0.1065, 0.2554, 0.9432],
[ 0.1850, -0.1038, 0.2434, 0.9464],
[ 0.1453, 0.0434, 0.2690, 0.9511],
[ 0.1453, 0.0434, 0.2690, 0.9511],
[ 0.0233, 0.0054, 0.2456, 0.9691],
[-0.1227, -0.1199, 0.2253, 0.9591],
[-0.1128, -0.1293, 0.1483, 0.9739],
[-0.1405, 0.0708, 0.1224, 0.9799],
[-0.1405, 0.0708, 0.1224, 0.9799],
[ 0.0269, -0.0155, 0.3173, 0.9478],
[ 0.2945, -0.4384, 0.1961, 0.8262],
[ 0.5352, -0.3563, 0.3216, 0.6952],
[ 0.4610, -0.4478, 0.4426, 0.6253],
[ 0.2767, -0.2003, 0.5760, 0.7426],
[ 0.1148, -0.6396, 0.3088, 0.6945],
[ 0.1065, -0.6433, 0.3012, 0.6958],
[ 0.0318, 0.6512, -0.4414, -0.6165],
[-0.1295, -0.4975, 0.4228, 0.7463]]] - '
body_vel': tensor([[[ 0.0178, 0.0134, 0.0032],
[ 0.0144, 0.0116, 0.0031],
[ 0.0115, 0.0102, 0.0029],
[ 0.0087, 0.0088, 0.0012],
[ 0.0058, 0.0033, 0.0008],
[ 0.0044, -0.0027, -0.0006],
[ 0.0204, 0.0148, 0.0034],
[ 0.0212, 0.0151, 0.0035],
[ 0.0142, 0.0191, -0.0005],
[ 0.0069, 0.0132, 0.0023],
[ 0.0078, 0.0073, 0.0040],
[ 0.0178, 0.0134, 0.0032],
[ 0.0189, 0.0141, 0.0033],
[ 0.0191, 0.0142, 0.0035],
[ 0.0216, 0.0139, 0.0033],
[ 0.0238, 0.0134, 0.0032],
[ 0.0190, 0.0142, 0.0033],
[ 0.0190, 0.0142, 0.0032],
[ 0.0187, 0.0146, 0.0029],
[ 0.0185, 0.0149, 0.0026]]] - '
body_ang_vel': tensor([[[-2.1039e-03, 1.8841e-03, 4.5471e-02],
[-8.3861e-03, 1.4360e-02, 4.5459e-02],
[-2.9610e-02, 3.4142e-03, 3.7804e-02],
[-2.7399e-02, 1.5296e-02, 1.2052e-02],
[-1.9519e-02, 2.5494e-03, 6.2424e-03],
[-1.9519e-02, 2.5494e-03, 6.2424e-03],
[-2.8170e-02, 5.0234e-02, 4.7453e-02],
[ 2.3433e-03, 6.7622e-02, 5.4932e-02],
[-1.9520e-02, 8.2082e-02, 1.2913e-01],
[-6.9687e-03, 3.7918e-02, 1.4132e-01],
[-6.9687e-03, 3.7918e-02, 1.4132e-01],
[-1.8195e-03, 5.0354e-03, -1.5386e-03],
[ 8.8561e-03, -8.9086e-03, -7.8141e-03],
[-1.5617e-03, -8.9112e-03, -2.2340e-02],
[ 3.5846e-03, 6.9349e-03, -2.3747e-02],
[ 4.2980e-02, 6.2602e-05, -3.1284e-02],
[ 2.7790e-03, -5.5849e-04, 3.6141e-04],
[ 2.6334e-03, 2.8605e-04, 7.0803e-04],
[ 2.7811e-03, -3.3474e-04, 2.5788e-04],
[ 9.7772e-03, -9.8729e-03, 1.0061e-02]]] - '
motion_bodies': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]] - '
motion_limb_weights': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]
4.5
从amass文件查看到的高度信息:
这是训练出来的高度信息:

所以对比来看,确实是高度相等,导致训练的时候的高度机器人跟不上。。。
4.6
获得人体的顶点和关节角度:
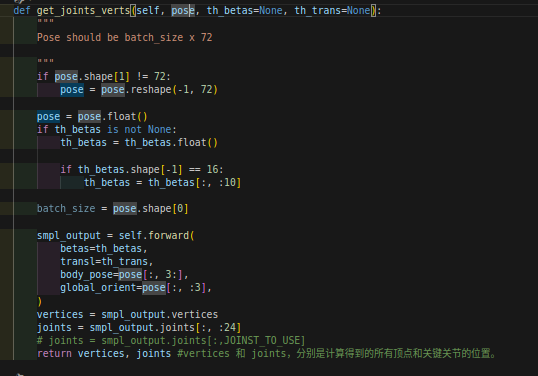
一共72个poses,前三个是global的pos_angle,后69个是每23个关节的3个pos,这里是按照axis-angle来计算的,不是四元数。
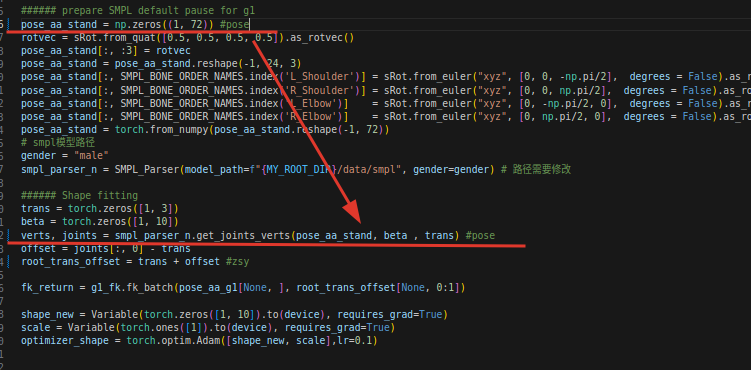
4.7
现阶段遇到一个很难以解决的问题:就是,我根本没办法统一retarget的过程中的忽略物理引擎的关键点位置和RL过程中的关键点的位置,因为retarget的过程关键点可能是飘在空中的,而RL中关键点也是飘在空中的,而RL中的机器人是具有重力的,这就导致机器人会自然而然的往下降落,甚至抬起一只脚去跟随关键点,来拿到奖励,我没找到办法去统一。如果我试图去修正了,那么其他的motion可能也会受到影响。这确实是个很难解决的问题。。。
4.8
cfg.env.test值和下面的值有关系,采样时间
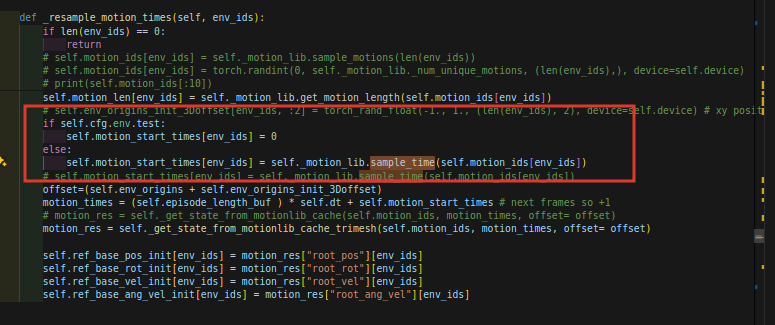
在处理motion时,_motion_lengths会将current_motions append进去,形成一个大Motions
这篇博客暂时记录到这里,日后我会继续补充。
4.9
初步搞懂了play的逻辑,也就是说我们初始会训一个很大的模型出来,这个模型是通过AMASS数据集很多数据学习出来的。
之前一直迷惑的地方是:如果我要play这个模型的话,是不是我就要连续play出来这个模型下的所有动作???那我要怎么指定特定的我要play的动作阿?
现在终于知道如何做了。可以在play的时候单独load motion_files的时候,指定你想表现出的motion,这样就可以指定了:
比如说在控制台单独引入一个load:
motion.motion_file=resources/motions/g1/g1_test.pkl
不过你load_run的内容其实就只是一个模型:
load_run=25_02_26_12-36-51_g1_ACCAD_10000_TEACHER
具体动作可以后头额外加Motion_file的地址。。。。
4.10
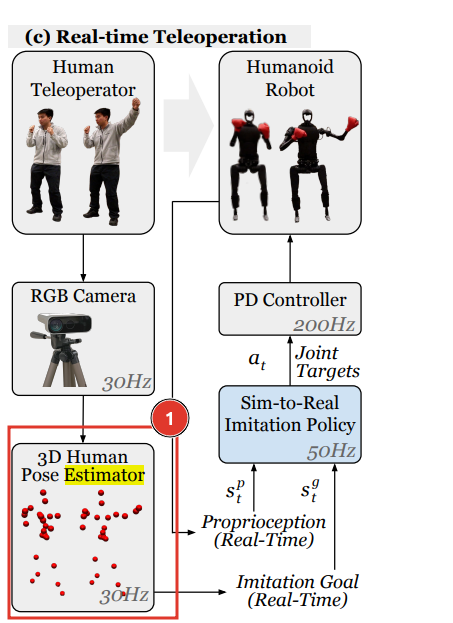
圈1的地方好像用到了human estimator,但这个模块好像用到了CV的处理办法。。。之后还会细看。
难道是还要再做一个实时的retargeted??????
代码里根本没实现这个地方!
后来猜想可能就是没做这个地方,直接拿来用的。因为看演示视频动作的幅度都很大的。
4.11
在rgb相机的关键点提取的地方也不甚了解,这个地方是怎么做的?
HybrIK是作者提到的一种rgb2smpl的方法,但是我却跑不通,很奇怪。
4.12
动作的数据集是经过筛选的,但具体是怎么筛选的,难道是人工发挥主观能动性筛选的吗,我这里也无从得知。因为作者根本没提供相应的验证代码。。。。
我认为我也可以手动筛选。。。
4.13

终于看懂了这个地方是在做什么,因为urdf每一个关节的位置都是相对于父类算出来的,所以这里是在父类的旋转上作用到子类,得到相对于父类的偏转位置,然后再加到父类位置上。
4.14
4.14.1 这是奖励函数的:

在选中关节奖励里面:(是这样的),也就是说学生网络也是这个:
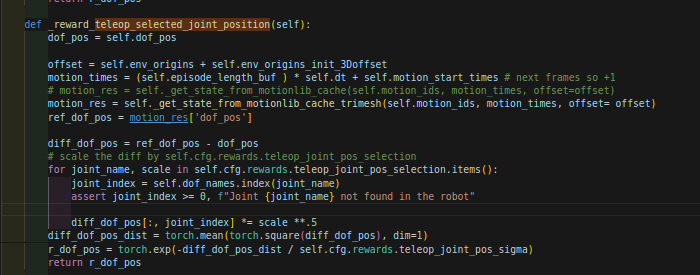
注意是joint,也就是奖励跟踪的点。
4.14.2 而motion里面是这个:但学生网络这个给清空了。在控制台train输入的时候:teleop_selected_keypoints_names = []
注意是link
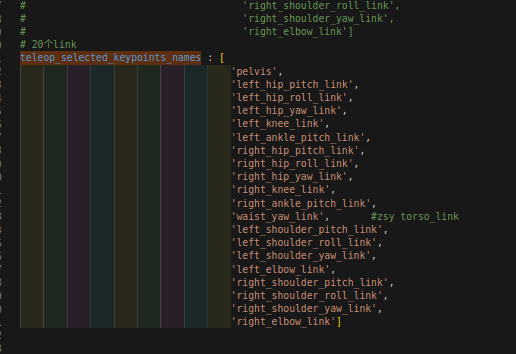
4.14.3 而在train.distill_model_config里面还有这个量!!!!
注意也是link

但是这里是这么操作的:

也就是说在train.teleop_selected_keypoints_names是赋值给motion.teleop_selected_keypoints_names的!!!
4.14.4 _track_bodies_extend_id 和 selected_keypoints_idx
这是 _track_bodies_extend_id 的值,增加了extend的关节:

这是 selected_keypoints_idx 的值:

二者这里就有点区别。
因为Student训练里面对motion.teleop_selected_keypoints_names有一个清空[ ]的操作,所以观测值就减少了。就只有extend的关节了。。
说白了Student相比Teacher就selected_link关节少了,rewards里面的selected_joint是没变的。。。
4.14.5 obs
这个Link
- 学生就只能观测到少的link,而且没有特权信息了,只能利用历史信息。。。。
- 而教师可以观测到所有的link,
4.15
heading应该指的是朝向的角度(rad)
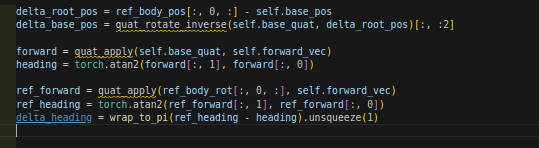
4.16
想对比一下各个模式的demo的命令输入有什么不同。。。
4.17 sim2sim不再神秘
去上交的G1,得到了SDK文件,回来想着去进行sim2real,却发现接口很对不上,这就导致我又回到公司去写sim2real的脚本。。。
把宇树官方的sim2sim的脚本进行了一波大改,算是完全理清了整体sim2sim的脉络,就是接口输入换了一下而以。。。。
4.18
因为sim2sim和仿真的数据对不齐,所以需要绘制数据的大致曲线做一个简要的判断。
下图是issacgym训练的数据,能看到值的大值范围是多少,然后我再找下mujoco的数据显示。
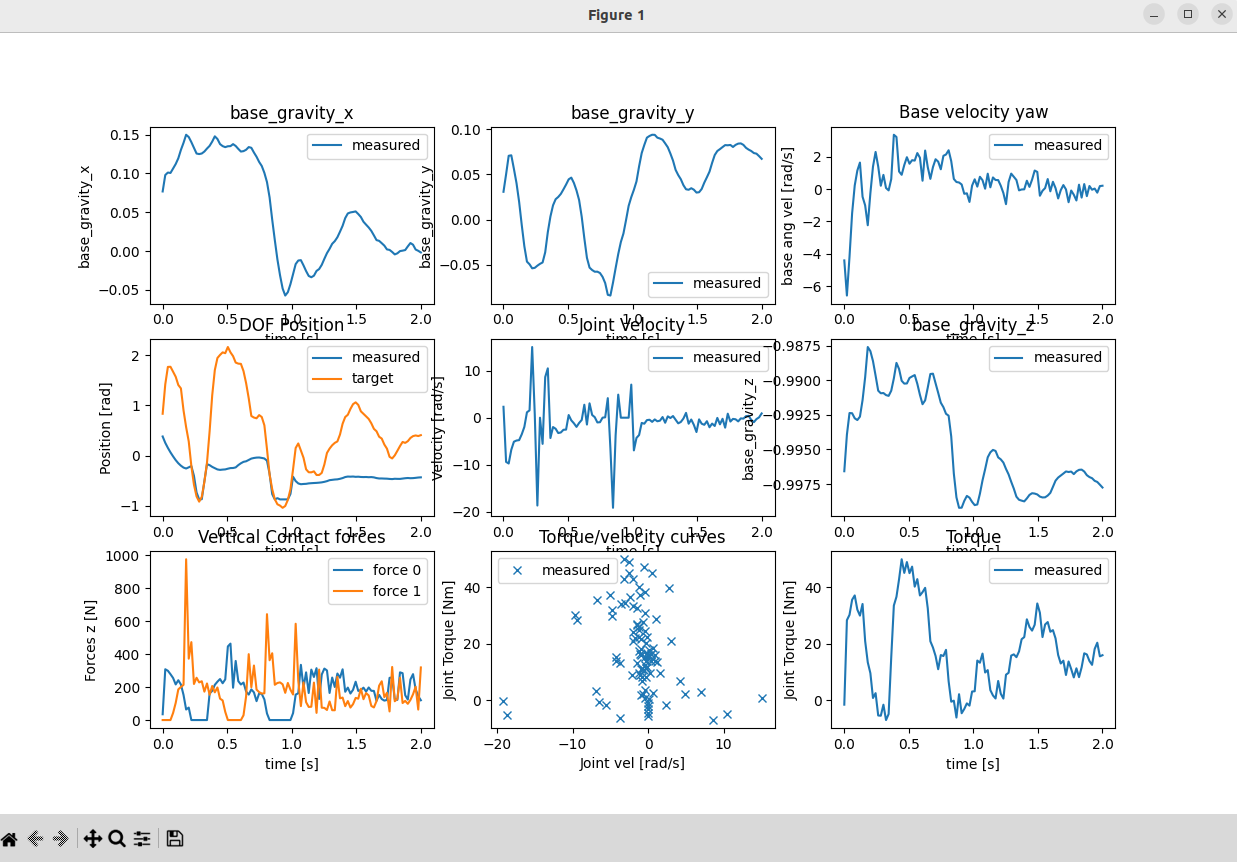
我再看看仿真里的actions
4.19
发现:
这个用的是for循环,理论上频率会更高,所以pd控制器的频率为200HZ,最外层循环按照dt = 0.005 * 4 = 0.02s,即50hz

在mujoco仿真中:是这样的:
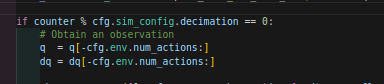
但是所不一样的是:
最外层循环按照dt = 0.005s,即200hz
而最内层是一个if,所以频率更低了是20hz,所以这时PD控制器在最外层了,其他在最内层循环了。
4.20
mujoco的gvec输出观测一下:
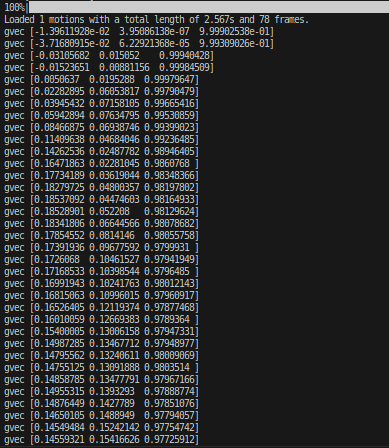
做了相关的变化操作后同样输出这个:

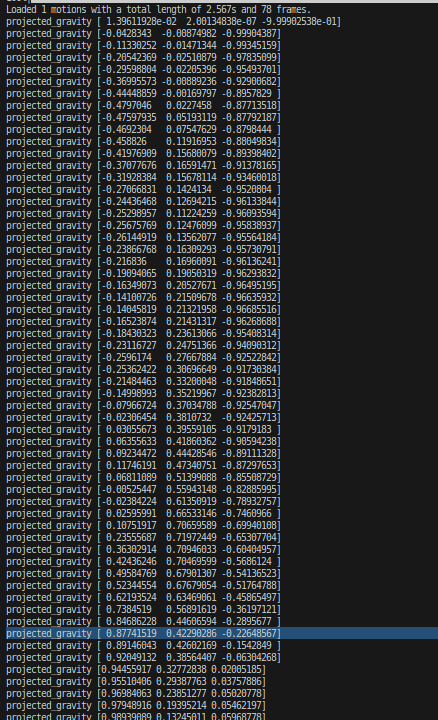
最后决定输入obs的观测值计划使用projected_gravity
4.21
最后再来检查一下观测值的scale:(PS这是issac gym里面的量)可以发现全市1阿
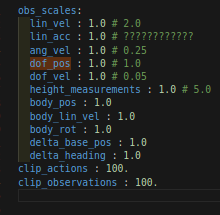
我觉得我有必要把两者的虚拟环境对齐一下了:
4.21.1 ref_pos
这是仿真环境的ref_pos:
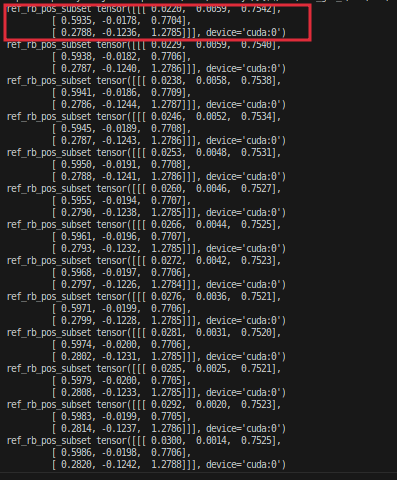
这是mujoco的ref_pos:
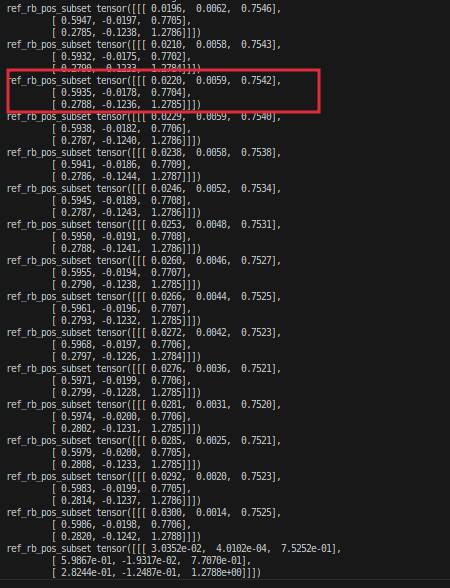
发现二者基本对齐了,只不过就差了两镇
4.21.2 ref_vel
这是仿真环境的ref_vel:
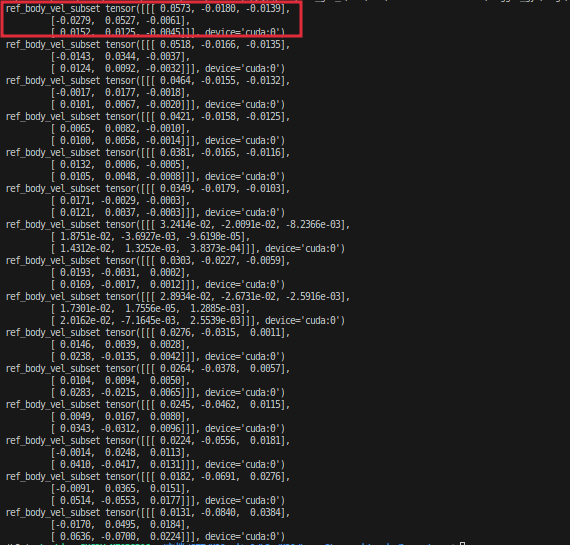
这是mujoco的ref_vel:
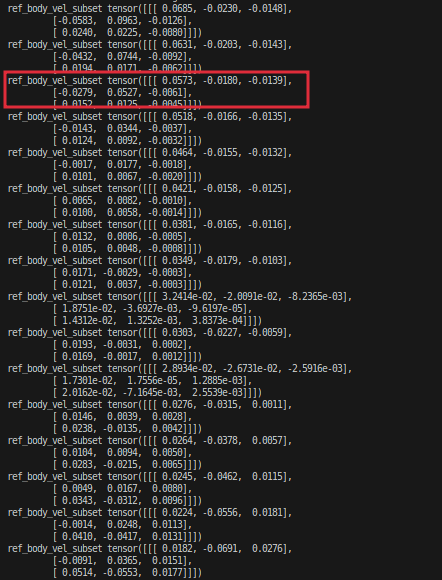
同样差两帧全部就对齐了。。。说明这个地方应该没什么问题。。
4.21.3 root_rot
这个地方需要重点检查一下:(两个都是初始的值哦)
issac gym的imu的数据:
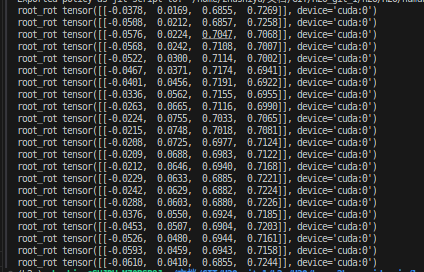
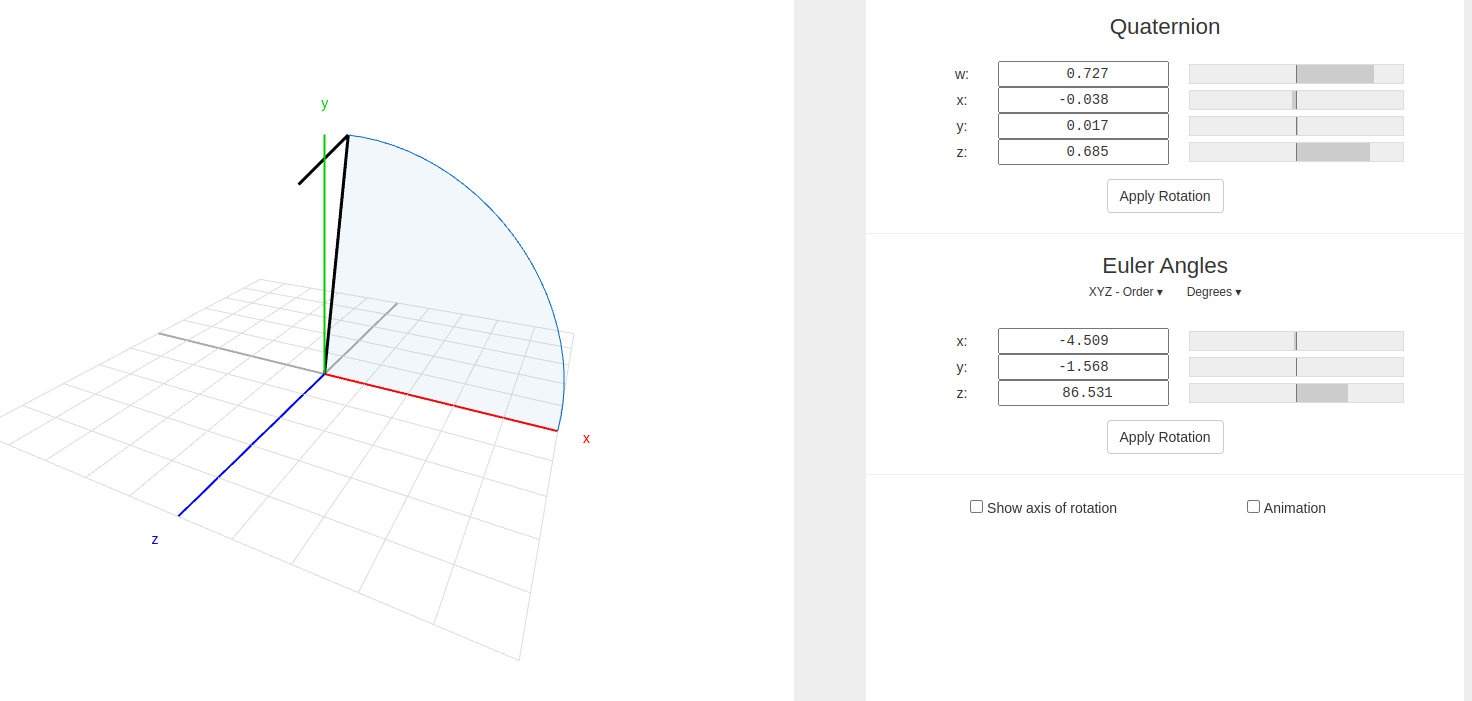
mujoco的imu读取的大概数据

或者

为什么mujoico初始时的是x轴的方向
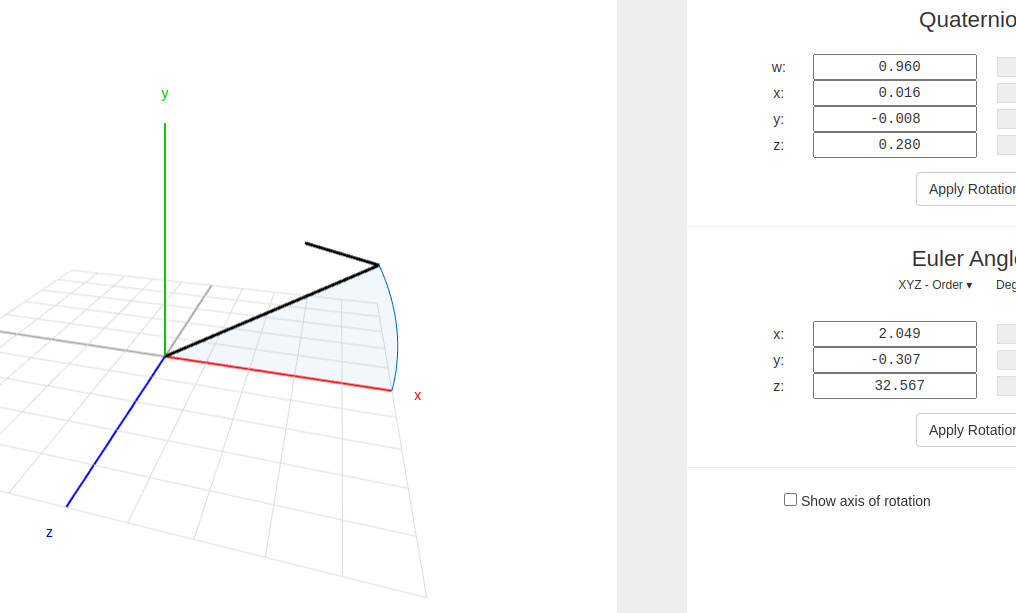
可以看到两者的值完全不对,猜测是不是这里的问题????所以解决一下:
我很惊奇的发现motion的轴是这样的:
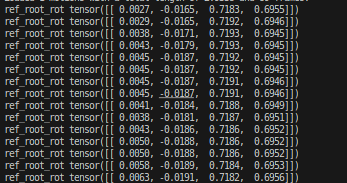
4.22 问题解决
最后发现了观测值没有对齐导致的mujoco仿真和isaac 训练对不上
当发现sim2sim的时候出现异常比如胡乱飞舞或者剧烈都懂跳起了街舞,这时第一个要想的事情就是观测值有没有对齐!!!
5 后记 之我在用的VSCODE插件
这些插件用的挺习惯的,有一说一的。。。。。
5.1 主题:
下面这种代码格式
5.2 插件:
- urdf实时显示

展示
- 彩虹缩进

- 好看的侧边栏文件主题:

这俩都是u

- numpy的.npz格式文件在线观看和pdf阅读器
- 通义千问
艾,本地大模型,就那样吧,内网也用不了。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号