legged-robot关于locomotion、Navigation任务主要文章速览
0. 前言
目前legged robot包括locomotion(怎么走)、navigation(往哪走)、人形机器人的whole body control以及基于机械臂的manipulation的任务。
本文章特此记录
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
警告⚠:这篇文章没有一句水话
1. 先验
1.1 四足机器人的机械结构:
- 液压驱动(液压系统的基本原理是利用密封管道内的液体,在不同压力的作用下产生力和运动)
- 电机驱动 (电机驱动的运动是通过调节电机的速度和扭矩来操纵关节的运动,操作时通常需要电池或其他形式的电源)
- 气体驱动 (气动驱动的四足机器人利用压缩空气或气体来驱动执行器,如气缸或气动肌肉,通过调节气体的压力实现运动)
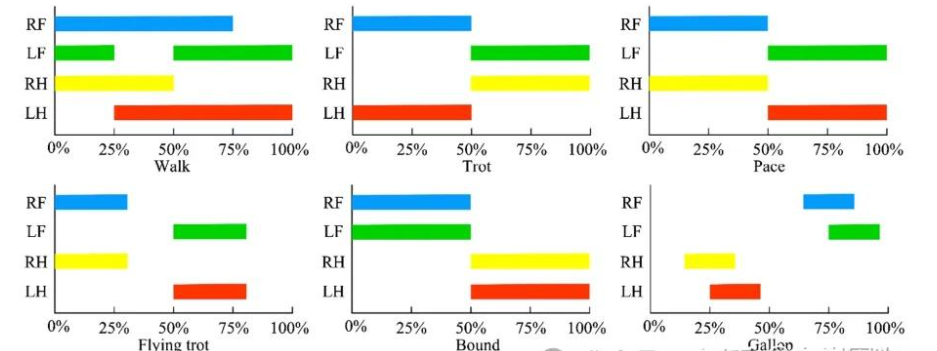
1.2 步态设计
这里写下四足机器人的运动控制步态:
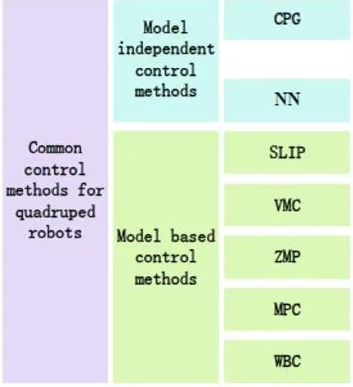
1.3 传统运动控制方法
这些都是不基于深度学习等方法的,都是基于传统运动控制的方法。
这里MPC是最耳熟能详的方法了,其他的就是了解。
下图包括基于模型和不基于模型的:
2. 正文
笔者记录一些论文的核心关键点,也就是主要框架,其他讲故事和实验的方面我就不再提及,因为这个地方主要看你的文笔好不好了,和技术没啥关系。
笔者这里就不贴出每个论文的跳转链接了,大家可以根据标题的名字自行搜索!
笔者速刷ArXiv,凝练一些关键词,细节部分可以自行品尝原文!!!
顺序不分先后。
2.1 Learning Quadrupedal Locomotion over Challenging Terrain
Science Robotics 2020
2020.Oct
Robotic Systems Lab, ETH Zurich, Zurich, Switzerland
这篇工作的主要特点是仅利用了四足机器人的本体信息(proprioceptive feedback),使用强化学习进行仿真环境训练和 zero-shot 的 sim-to-real 真实环境迁移,得到了能够在许多 challenging terrain 上成功的行走策略。
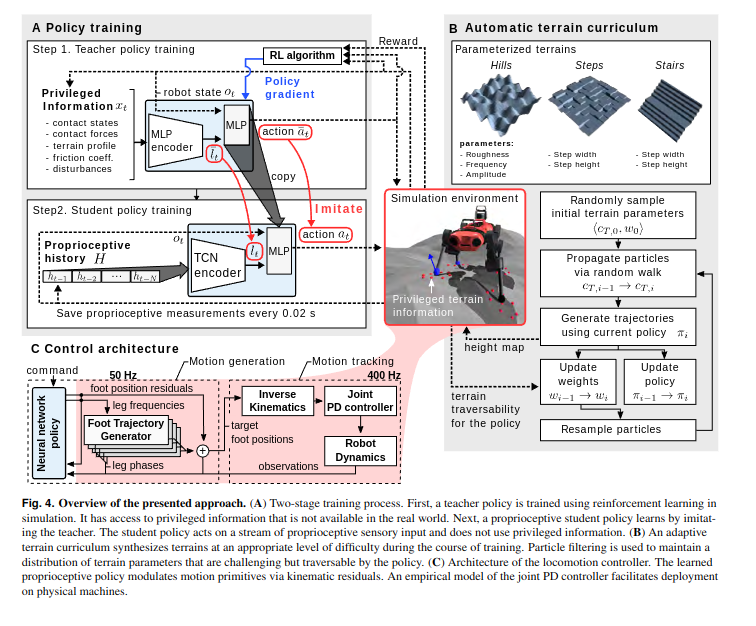
这篇工作提出privileged观测,也就是特权观测,这个观测值比如:接触力度、地形轮廓、摩擦系数等,这些参数不是很好能在现实中获得,因为如果要获得就得加上很多的传感器,很冗余。这些观测输入给教师网络进行第一次训练。随后学生进行第二次训练。两阶段的学习任务。
还有环境自适应的课程算法。能够逐渐调整地形难度
这基本就是之后locomotion任务的基础框架了
2.2 Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild
Science Robotics, 19 Jan 2022, Vol 7, Issue 62
https://arxiv.org/abs/2201.08117
2022.1.20
这篇工作和上一篇工作的主要区别在于使用了感知信息(视觉、雷达)使四足能够获得更加完备的信息。
仿真使用RaiSim
听说这篇论文的工作量都可以发好几篇论文了
分析论文的相关博客: https://zhuanlan.zhihu.com/p/583242760
Abstract
迄今为止最强大和最通用的腿式运动解决方案完全依赖于本体感受。这严重限制了运动速度,因为机器人必须先物理地感受地形,然后才能相应地调整步态。在这里,我们提出了一种稳健且通用的解决方案,用于将外部感受和本体感受整合到腿部运动中
propriception obs 本体观测值
exteroception obs 外体观测值:包括高城图
priviledged obs
具体如下图所是:
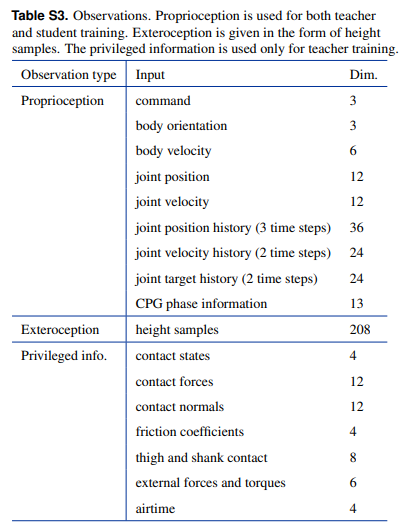
2.2.1 Main idea
门用来控制有多少的外部数据进入其中:


高层图加噪

不同的噪声等级
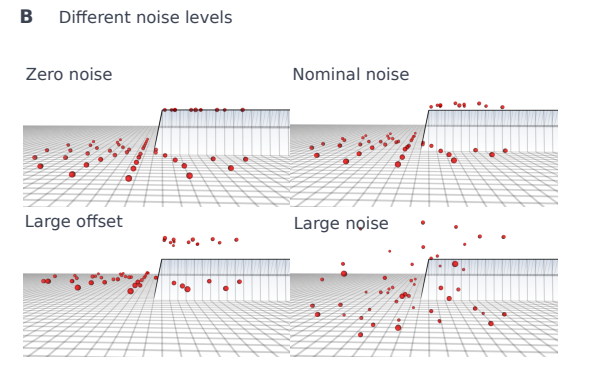
2.2.2 Teacher Policy
达到的效果是:既满足了现实世界中实体传感器的不可抗局限性,同时满足了策略本身
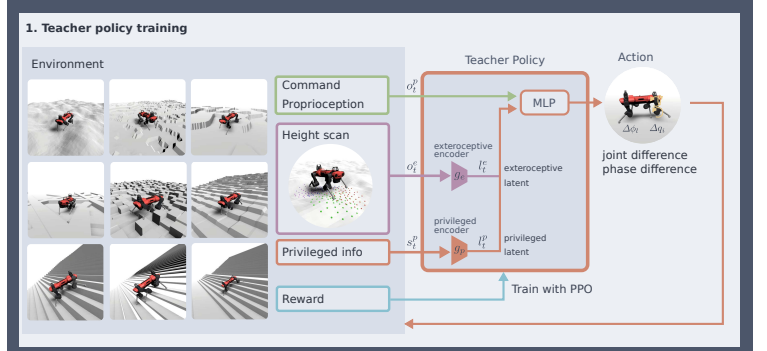
2.2.3 Student Policy
后面和之前的文章是一样的,计算重建损失函数和behavior损失函数:
不过重建损失是显式的。
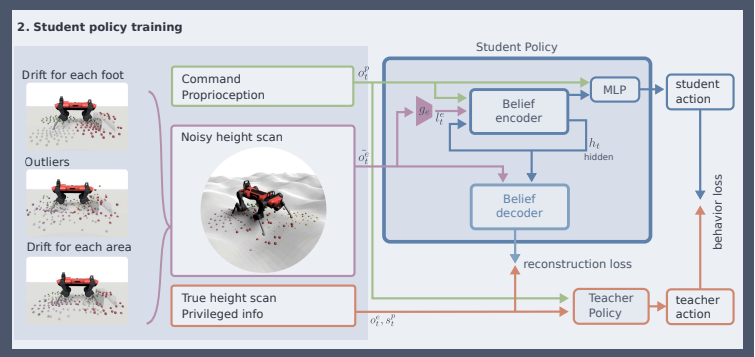
2.2.4 部署
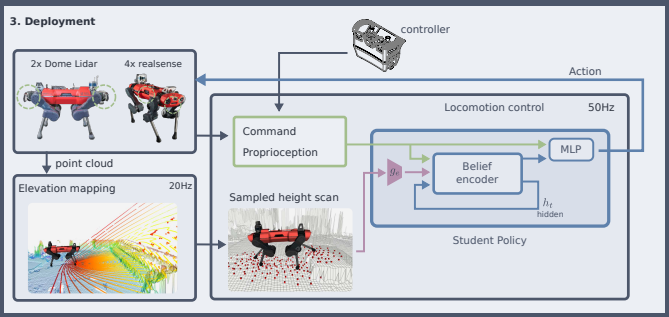
2.3 Extreme Parkour with Legged Robots 【】
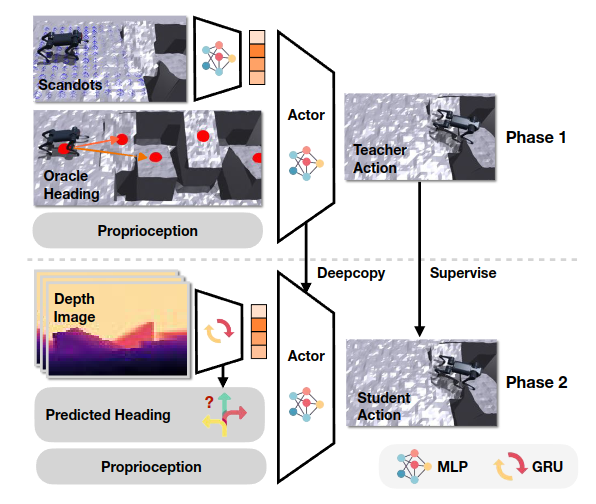

特权观测:scandots、环境参数、通过waypoints引导的waypoints
2.4 Legged Locomotion in Challenging Terrains using Egocentric Vision
Egocentric:自我的、以自己为中心的
Conference on Robot Learning (CoRL), 2023.
scandots的首先提出

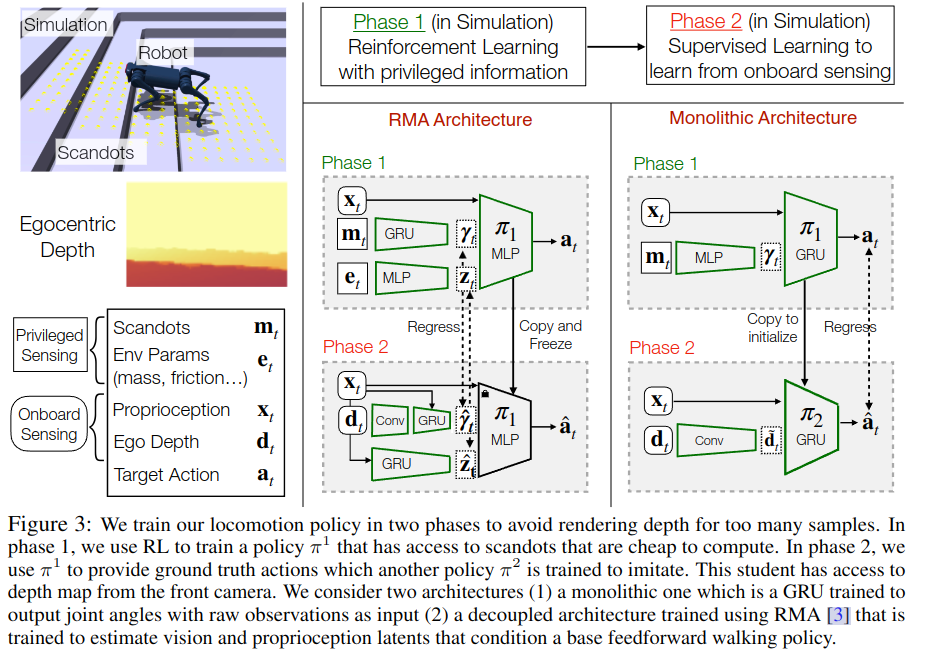
分两个阶段训练我们的运动策略,以避免太多样本的渲染深度。在第 1 阶段,我们使用 RL 训练策略 π1,该策略可以访问计算成本低的扫描点。在第 2 阶段,我们使用 π1 来提供另一个策略 π2 被训练来模仿的基本事实动作。这个学生可以访问来自前置摄像头的深度图。我们考虑两种架构 (1) 一个整体架构,它是一个 GRU,经过训练,可以输出与原始观察关节角度作为输入 (2) 使用 RMA [3] 训练的解耦架构,该架构经过训练以估计以基本前馈步行策略为条件的视觉和本体感觉潜伏期。
monolithic整体的
Mono结构
2.5 ANYmal Parkour: Learning Agile Navigation for Quadrupedal Robots【】
2023.6.26
还是ETH的
2.5.1 整体结构
- 感知模块:
感知模块接收来自机载摄像头和激光雷达的点云测量数据,并计算机器人周围地形的估计,以及表示场景belief state的紧凑潜在向量 - 定位模块:
5种action - 导航模块:
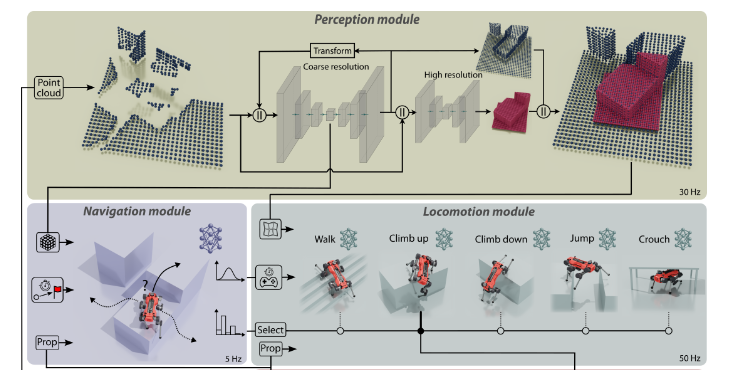

2.5.2 任务
1. locomotion任务
MPC,模型预测控制(MPC)可用于穿越需要精确脚位的具有挑战性的地形,但是在滑移或不完全地形感知的情况下,MPC往往失败
DRL,现在主流的方式,但仍然不能够开发他的全部潜力?????
Agile locomotion,
值得注意的例子包括跳跃和攀爬[2],做猫一样的落地动作[14],[15],从跌倒中恢复[16],[17],以及用足球运球[18],[19]。
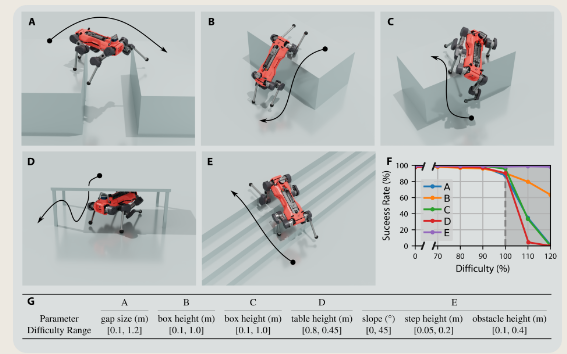
2. navigation任务
通过从感知模块的潜在空间中提取3D信息,规划器能够根据其对地形的瞬时测量来选择子目标。
导航策略必须学习如何正确地组合每个技能的位置、航向和定时命令,以达到预期的效果。
这里可以看原始图像更高青:
根据高度不同,展示了机器人会如何决策:
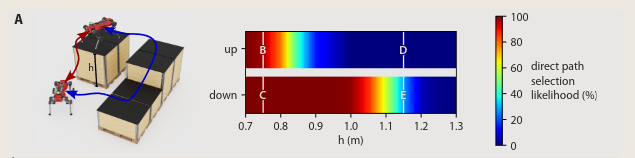
整体:

作者还比较了不同的地形情况下,他们的方法和人工的手段进行比较:

3. Perception任务
it is equipped with a total of six Intel Realsense depth cameras (two in the front, two in the back, one left, one right), and a Velodyne Puck LiDAR
ROS控制
NVIDIA Jetson Orin部署percption
导航和运动策略从感知模块接收到的最后一条消息来推断它们各自的网络
第一列对应于测量结果,第二列对应于作为点云可视化的基线地图,最后一列对应于我们的重建

方法产生了一个多分辨率输出,将高分辨率输出(机器人周围2米的细化过程)涂成红色,将粗分辨率输出涂成蓝色,以便更好地区分。
雷达获取点云地形图
coarse:粗糙的
2.5.3 方法
1) Perception Module:
encoder-decoder的方法
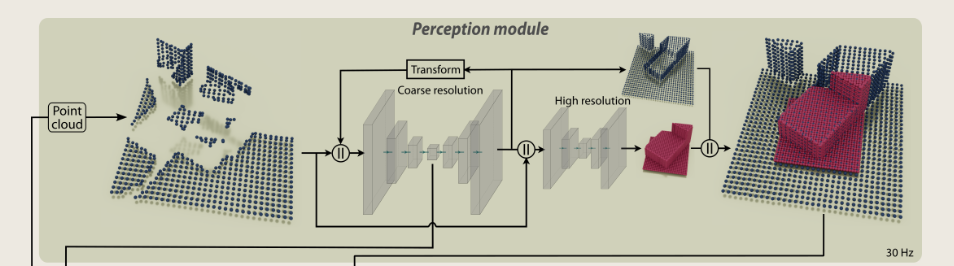
事实上,靠近机器人,地图更小,分辨率更高,因为这个区域对运动至关重要。距离越远,分辨率越低,以获得更广阔的视野。这些区域的导航模块只需要对场景进行近似配置,即可进行路径规划和策略选择,因此分辨率较低就足够了。
voxel(立体像素)
高分辨率网络使用粗分辨率网络最后一层的特征作为输入,以及点云测量。注意,它没有使用自回归反馈,因为时间信息已经包含在它的输入中
2) Locomotion Module:

作为输入,策略接收当前本体感觉状态、周围地形的局部地图、中间命令,并向电机输出位置命令。
这些技能是分开训练的,共享观察和行动空间,但需要不同的奖励和终止条件,以便有效地训练
使用的是基于位置的命令,而不是基于track vel的命令:训练设置与[2]非常相似,并使用基于位置的命令。机器人必须在给定的时间内到达目标位置,而不是跟踪速度命令
除了位置和时间命令外,我们还添加了一个航向目标,指定了机器人在轨迹结束时必须采用的偏航方向。
当导航模块接收到地图的完整3D表示时,由于运动策略的高更新率和训练期间相应的计算成本,这对于运动策略来说是不切实际的。他们在机器人周围使用2.5D高程图,这可以直接从感知模块的点云输出中计算出来
3) Navigation Module:
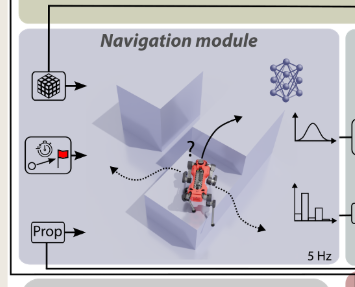
它由运行5赫兹navigation module的外环和运行50赫兹locomotion module的内环组成。
训练的时候,locomotion的inner loop被冻住。
At every high-level time step, the navigation policy receives the relative position of the final goal, the remaining time to accomplish the task, the robot's base velocity, orientation, and the latent tensor of the perception module
在每个高级时间步长,导航策略接收最终目标的相对位置、完成任务的剩余时间、机器人的基本速度、方向和感知模块的潜在张量
2.6 《RMA: Rapid Motor Adaptation for Legged Robots》
2021.1.8
Fu ziPeng 大佬的作品,但他是二作,一作好像是挂的听说。。。(小声bb)
提出了RMA模型,可以根据以往的历史信息来学习
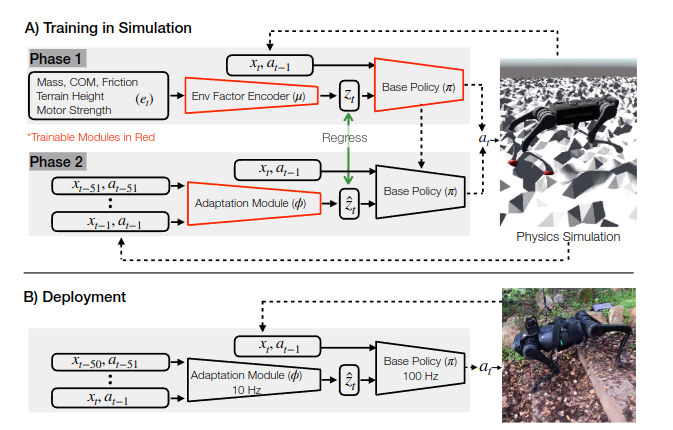
两阶段训练,base policy:100HZ和adaptive policy:10HZ
非常经典的框架结构:两个encoder,第一个教师encoder先训练一遍,然后更新;
第二个encoder训练一遍,用教师网络的policy,然后两个latent只做MSE loss更新学生的历史encoder,部署的时候就部署学生的encoder,10HZ,然后POLICY是100HZ的,非常经典。。。
2.7 Learning to walk in minutes using massively parallel deep reinforcement learning
CoRL 2022
机器人并行训练,github的legged-gym被世人传唱。
train框架
sim2sim
sim2real
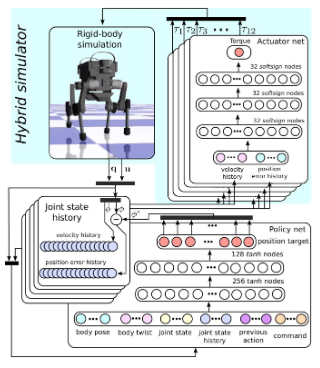
*2.8 Learning Agile and Dynamic Motor Skills for Legged Robots
2019年的,太早了,最早的编码测试时刻
2.9 《Robot Parkour Learning》
庄子文大佬的文章,之前有幸线上听过他的讲座。
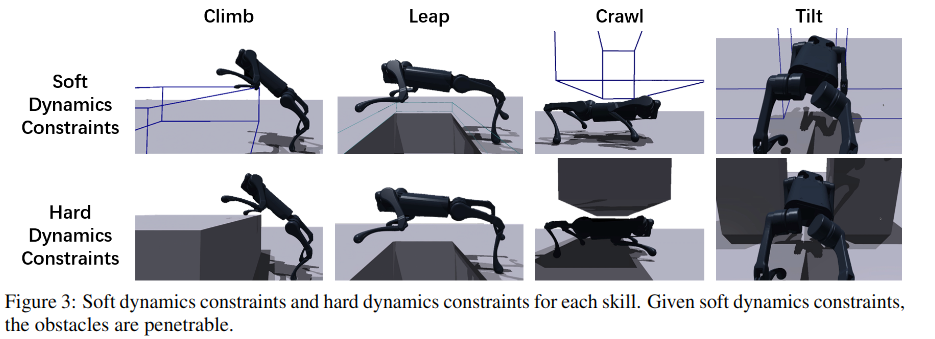
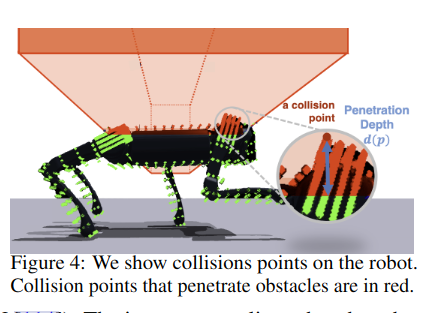
把障碍物变成虚拟形象,在训练中增强学习效果。
2.10 《DreamWaQ: Learning Robust Quadrupedal Locomotion With Implicit Terrain Imagination via Deep Reinforcement Learning》
2023.3.3
这篇论文首先提出了使用VAE放到网络里去预测,而不是只一个encoder,VAE不懂的可以去看笔者的博客:https://www.cnblogs.com/myleaf/p/18682945
这篇工作的思想是通过历史数据输入到VAE的encoder里面得到latent,然后latent经过Decoder得到下一时刻的观测值信息,也就是当前时刻的priv obs可以这么简单理解(毕竟代码也是这么实现的,尽管作者没开源代码),损失函数包括重建损失和下一时刻的 MSE loss。
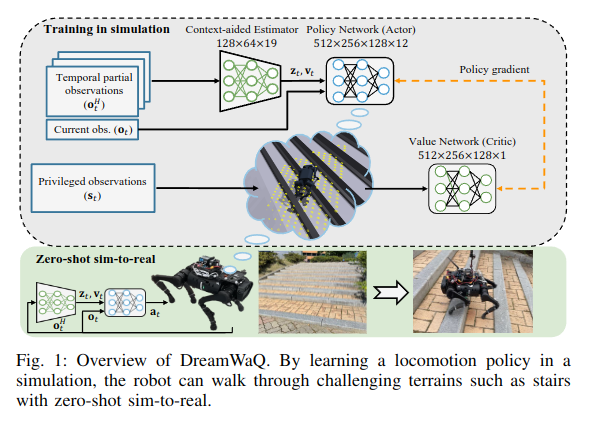

笔者复现了代码,但感觉效果并不是特别好。。。。
我才看懂论文里这个w/o是啥意思,是without的意思。。。。w/是with的意思。。。。。
2.11 《Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion》
2022.3
IEEE Robotics And Automation Letters
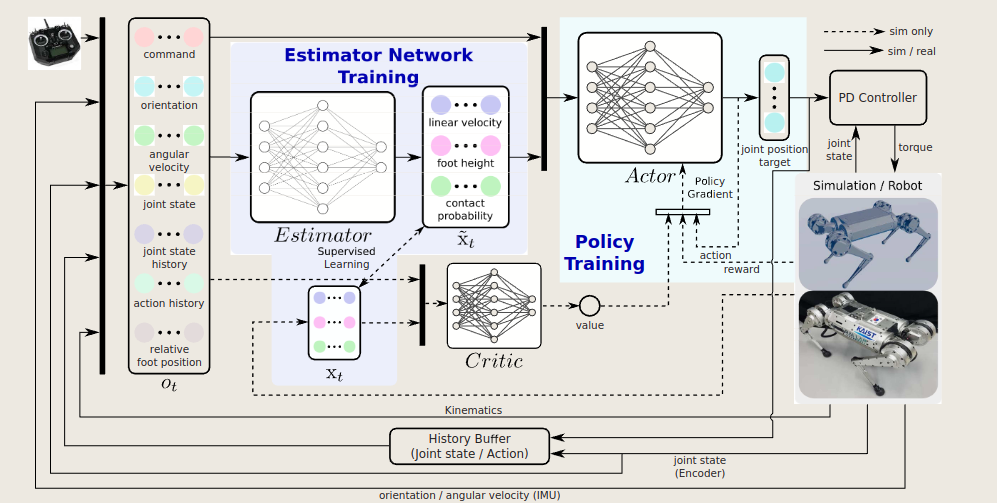
这篇论文就是很好的Estimator的实例,通过一个编码器将历史信息编码,得到的数据就是我想要预测的数据,这个数据直接和priv的数据做loss(请注意,priv的数据可没有经过encoder)所以相当于是一个显式的估计了,知道这一点就可以了,这就是这篇论文的宗旨。
2.12 《CTS: Concurrent Teacher-Student Reinforcement Learning for Legged Locomotion》
2024.9.1
IEEE ROBOTICS AND AUTOMATION LETTERS
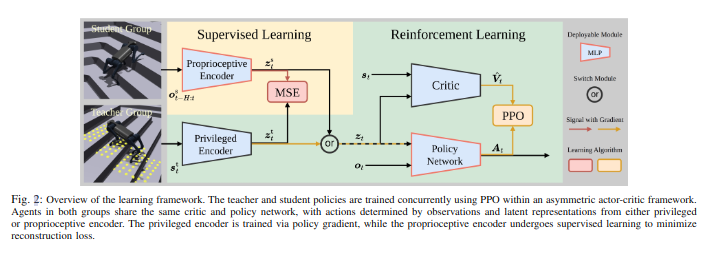
教师和学生并行训练,将两阶段合并为一个阶段。我们直接来看结构:
为了学习最优策略,机器人需要从可用的观测ot中推断出其当前状态st。由于环境的部分可观察性,通常不可能从单个观察中推断出实际状态。因此,推理问题 p(st|ot, ot−1, · · · , ot−n) 需要观察的历史序列。
文章通过将并行代理分为两组,称为教师组和学生组,同时训练教师和学生策略,然后使用上图所示的非对称演员-评论家框架,其中教师策略包括特权编码器和Policy Network,学生策略包括本体感知编码器和Policy Network。
两组中的代理都使用近端策略优化 (PPO) 进行训练,而它们共享相同的策略网络 πθ 和评论家网络 Vφ。
最近的工作利用变分自动编码器 (VAE) 或师生学习来隐式推断状态或与任务相关的信息。文章整合了这两种方法的优点,并采用近端策略优化 (PPO) 进行训练。
然后再来关注一下二者的损失函数:
PPO损失函数:(这些就是PPO算法里面的公式,不属于本片作者的工作范畴,他就是引用了下,略过)
1、actor的
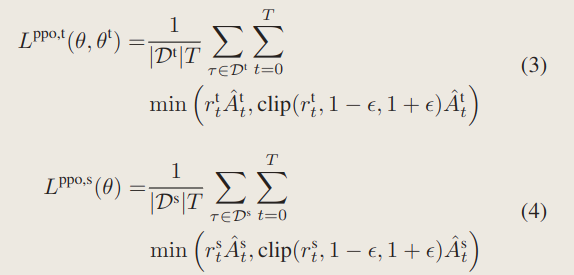
2、critic的
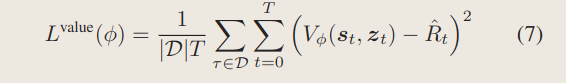
3、PPO算法

关于PPO算法还不懂得可以看我之前写的博客
4、TS网络的损失函数:
直接把隐变量作MSE:
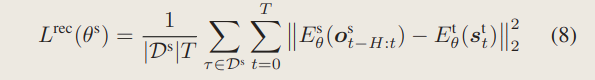
他这个网络结构也比较清晰哈哈:

*2.13 A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning
由于样本效率低下,深度强化学习应用主要集中在模拟环境上

不建议newer看原文,找不到要点,这篇不建议看,扫一下目录就行
2.14 Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors
2023.8
看了b站视频,效果很惊艳!跑的很快
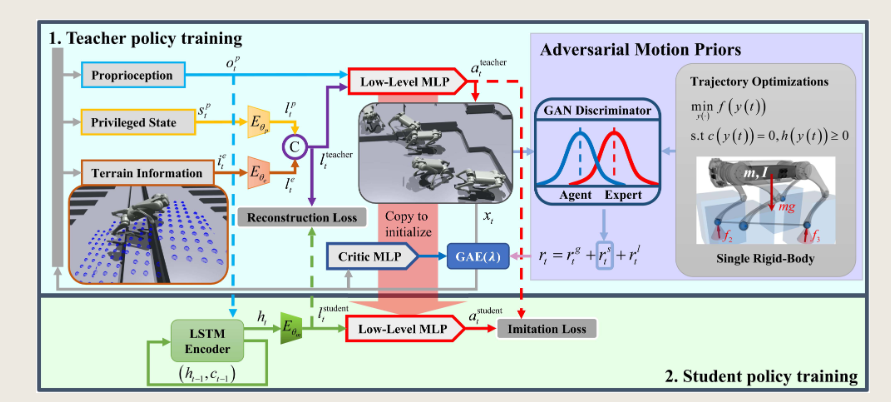
这些工作只显示了在具有挑战性的地形上低速或中等速度的运动,而没有测试自然地形上的高速运动,所以文章提点来进行实操。
legged movements in the experiments of the papers employing RL methods are unnatural and jerky:现有文章的效果腿部不自然
AMP是动画领域,使用GAN来模仿生成逼真动作的一个方法。下面引用自AMP这篇论文:
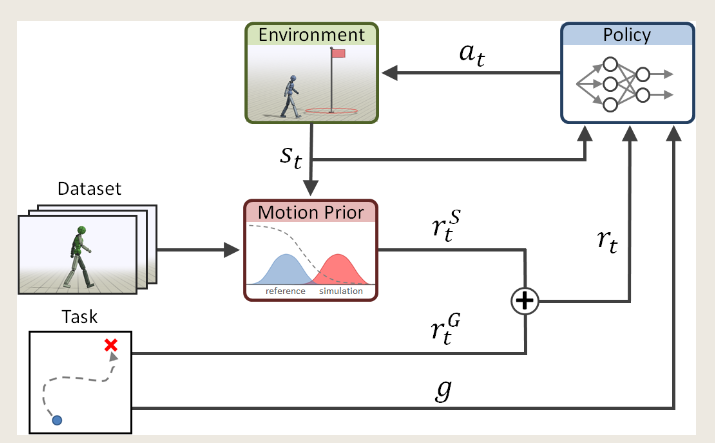
Generative adversarial imitation learning (GAIL) -------GAN(Generative adversarial network)
这里简单介绍下AMP
AMP主要利用了对抗的方式,利用state-to-state方式进行训练,尽可能的缩小数据集里的state-to-state pair和现实里通过policy生成的state-to-state pair之间的差距
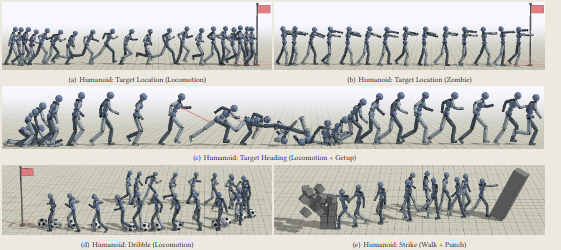
最终可以完成很多不可思议的操作

我们再回到这篇论文:
AMP应该是用在了后面的这个地方:
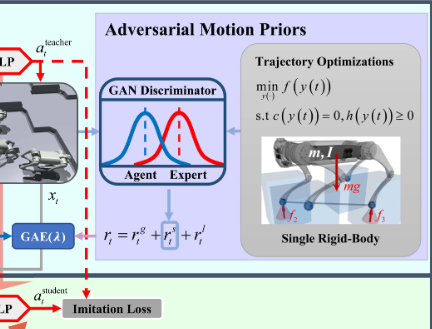
通过一个轨迹的优化,相当于AMP的Dataset,继而通过GAN将state-to-state pair和真实的的做GAN discriminator,得到的结果作为一个奖励函数,最后做一个加权。
其中奖励函数包括:目标奖励函数、风格奖励函数和正则化奖励函数(应该是用来方式过拟合)
- 风格奖励函数:
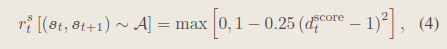
- 判别器的目标函数:
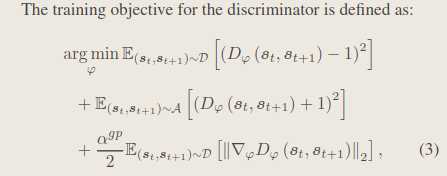
接下来可以来查看这个数据集是怎么构建的:
引自《Gait and Trajectory Optimization for Legged Systems Through Phase-Based End-Effector Parameterization》
ICRA 2018 主要是基于轨迹优化的方法生成各式腿足机器人的多种步态TO
提出了一种TOWR的方法,能够实现产生这种Dataset用来学习
最终通过这种方式进行优化,这是第一个阶段:

论文里经常出现roll out这个词:

2.15 《A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning》
解读论文:
https://zhuanlan.zhihu.com/p/140939491
2011年的论文:
经常会在locomotion任务iu的论文里看到这样一句话:

于是总是来到这个所谓的 DAgger,这下不得不仔细看看了。
这个不属于策略,这是一种方法,我看前面的论文总是提到这种方法,因此我就记录在这里了
DAgger (Dataset Aggregation) 旨在解决模仿学习的两个问题:
- 传统的学习一个classifier或regressor的方式,不适用于序列决策过程。因为t时刻的预测会影响t+1, ..., t+n时刻的状态,这违背了统计学中的 iid(独立同分布假设);
- 误差累积。
算法流程:
一开始我们令\(\beta_1 = 1\),即用expert policy获取初始数据。然后再随着训练过程指数级衰减这个系数\(\beta_i = p^{i-1}\) :
带上角标E的是专家expert策略

说白了一句话:DAgger在每一次迭代中利用当前的policy收集数据,然后利用所有的数据集训练下一次的policy。
regret 指预测者(forecaster)的累计损失与专家(expert)之间的差,其用于度量预测者在事后有多后悔没有跟随专家的指导。
2.16 Walk These Ways: Tuning Robot Control for Generalization with Multiplicity of Behavior
2022.12.6
https://github.com/Improbable-AI/walk-these-ways
2022.dec.6
Conference on Robot Learning (CoRL)
多步态
解析论文:
https://blog.csdn.net/qq_23096319/article/details/137370675
Abstract
学习一个单一的策略,该策略编码一个结构化的运动策略家族,以不同的方式解决训练任务,从而产生行为多样性(MoB)
不同的策略有不同的概括方式,可以在新的任务或环境中实时选择,而无需耗时的再培训
发布了一个快速,强大的开源MoB运动控制器----Walk These Ways,可以执行不同的步态与可变的脚摆,姿势和速度,解锁不同的下游任务:蹲伏、跳跃、高速跑步、楼梯穿越、支撑对推搡、有节奏的舞蹈等

MoB的任务框架:

2.17 《Hybrid Internal Model: Learning Agile Legged Locomotion with Simulated Robot Response》
2024.1.2
two-phase training paradigm 两阶段的学习范式,其实训练只需要一阶段就足够了(执行一次)
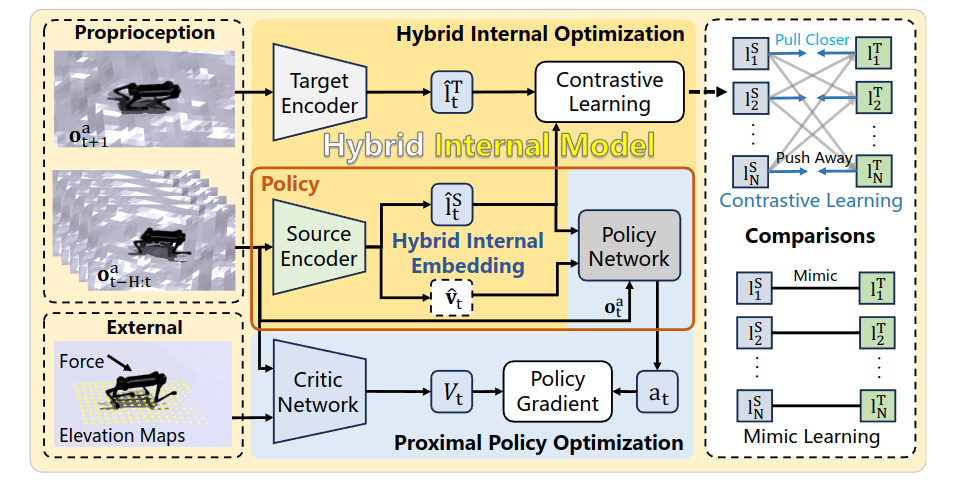
故事讲的不错,将高程图和地面摩擦等作为系统扰动,受到经典IMC的启发,Internal Model Control (PID)的启发。当然这都不重要。。。
论文里小小的总结了一下前人的这些方法,同时基于模仿学习的训练方法可以被分为两个类别The mimic learning methods can be categorized into two main frameworks: adaptation and teacher-student.:
1、Teacher-Student refers to (Miki et al., 2022a) 基于T-S的方法
2、MONO means (Agarwal et al., 2023)
3、AMP means Adversarial Motion Priors (Wu et al., 2022; Escontrela et al., 2022)
4、RMA means Rapid Motor Adaptation (Kumar et al., 2021) 基于Adaption的方法
这里是重点
文章的整体框架结构为:两个encoder,一个encoder编码特权观测信息,得到latent1,然后此后这个encoder不再更新;另一个encoder编码历史信息得到隐式的latent2和显式的速度v(当然也可以是别的),然后这个隐式的latent2和latent1做对比学习的loss,显式的和特权观测值的obs_v作MSE loss,最后对比学习的loss和MSE loss都用来更新编码历史信息的encoder,这里很关键的一个部分是对比学习的部分:

这里采用了一个聚类的思路,代码我也看过了,理解起来也很清晰,我来讲一下:

以往的是mimic learning也就是一对一的模仿计算loss,类似于前面提到的MSE,这里确实创新性的将无监督的聚类方法引入其中,具体实现是对于当前时刻的latent2,不光要和当前时刻的latent1的“距离”近,还要和之前的所有的latent1的“距离”要远,这就是CV领域正样本对和负样本对的理解,作者在论文中这样提到,采用对比学习计算方法能够让机器人自主学会分类各个地形:

论文代码也写的很清晰!!!
2.13 DayDreamer: World Models for Physical Robot Learning
CoRL 2022
这是model-based的方法
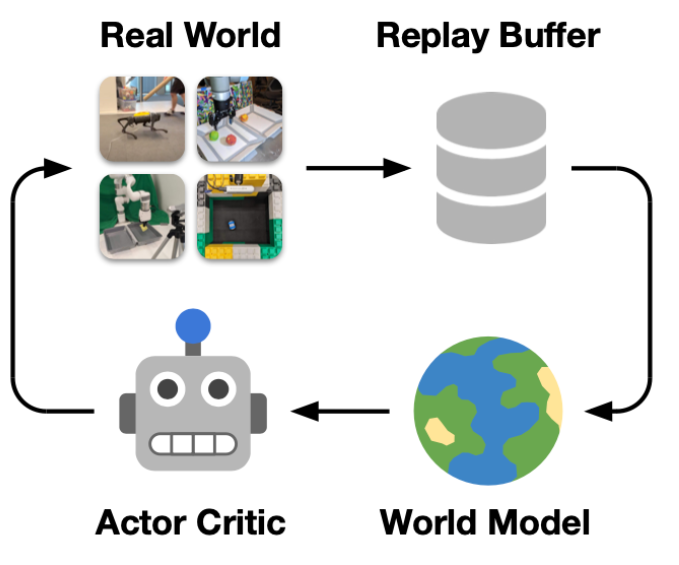
agent和环境进行交互,得到的数据先学一个World Model,给定state和action预测next state
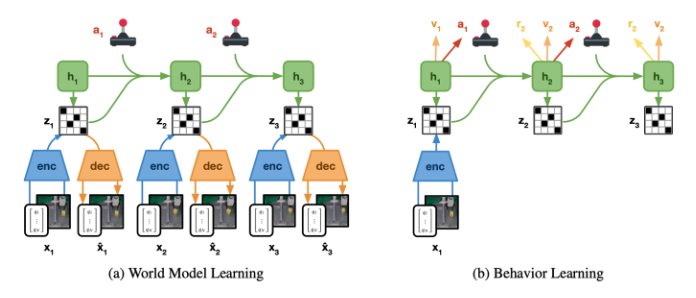
agent和环境进行交互,得到的数据先学一个World Model,给定state和action预测next state,当然都是在latent space里的,所以上图a有一个encoder和decoder去训练这个embedding state。
而你会发现这里还有个h,h是rnn的state,然后这个state是个概率状态,所以z是从h里sample出来的。
实际训练的时候就用右边图b这种方式在latent space里训练policy。
然后根据Plan2explore,实际在训练时会训练两个policy,一个policy用于给world model收集数据,另一个policy用于完成某种任务。因此在world model里面会有两种reward function,一种是Intrinsic reward,用于探索world以提供更高质量的数据给world model,一种是task reward用于训练完成任务的policy。
但作者在文章里似乎就用了DreamerV2,没有Intrinsic reward
在实验部分作者准备了四种不同的机器人:

选这四个机器人是因为可以包括连续和离散的动作空间,参数和视觉观测空间,绸密和稀疏的奖励函数
2.18 Coupling Vision and Proprioception for Navigation of Legged Robots
CVPR 2022
2.19 Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers
ICLR 2022
2.20 Learning a Unified Policy for Whole-Body Control of Manipulation and Locomotion
本文的目标是将四足机器人本身的运动和机械臂的操作作为一个整体来进行控制,控制器可以同时输出四足的运动策略和机械臂的操作策略
2.21 Rapid Locomotion via Reinforcement Learning
mit 2022.5.5 arxiv

狗子的快速移动,高兴到让狗子的腿部变形,4m/s,快堪比轮子了。。
used RL to train Mini Cheetah to learn high-speed movements over natural terrains.
2.22 论文22《Exploration by Random Network Distillation》
https://zhuanlan.zhihu.com/p/48737609
Random Network Distillation, RND
2018 10 30
我们的目标是找到一种方法对于每一个状态都返回一个值,告诉我们它与之前见到过的状态有多少的相似程度。本文的方法基于一个观察,如果在神经网络训练中,如果有类似的数据出现在训练中,那么其预测误差将会显著减小。

(1)方法:
通过对奖励项做一个探索性的修正:

文章引入了两个网络,一个随机初始化的目标网络target,这个网络不会被训练,即参数是固定的;而训练一个预测网络predictor网络用agent收集的数据训练,目标网络接受观测值,而预测网路io用梯度下降的方法也接受观测值,这两个值做一个MSE:
这个过程将随机初始化的神经网络蒸馏为一个经过训练的神经网络。



这样就训练出了一个density estimator,,然后对于一个新的样本,如果预测误差小,就说明这个样本之前前国,那么就给很小的奖励;反之,说明没见过,于是基于较高的奖励。这样我们就可以随时知道一个新的状态和之前的状态分离的远不远了。
(2)原理
利用了神经网络的预测误差:
- 训练数据量和分布:如果类似的数据见得少,那么这种数据的预测误差大;这是我们希望利用的性质,而后面其他的误差来源都是我们不希望见到的,尽可能去避免它们。
文章的伪代码实现:

2.23 论文23《Deep Whole-Body Control: Learning a Unified Policy for Manipulation and Locomotion》
同样是Fu大佬的工作,作用在带机械臂操作的四足机器人身上,

文章思路大致是这样的:通过priv encoder根据priv obs生成隐变量z1,通过prop obs encoder根据prop obs生成隐变量z2,二者作一个蒸馏(即模仿学习),就好比是隐式的一阶段的蒸馏,但是这里最能体现Fu大佬的工作的一点是,它实现了学生网络对教师网络的反向蒸馏(其实可以暂时这么理解),其采用一个loss,分频率对学生网络和教师网络分别进行更新,在文章中作者教师网络的更新频率为学生网络的20倍,学生网络只在一个episode结束才更新而教师网络是随着PPO网络一起更新的,作者代码里面用到了detach和一个循环flag去很好的完成了这件事情,具体不再展开,请去作者的开源处获得咨询:https://github.com/MarkFzp/Deep-Whole-Body-Control
- 作者还提到了arm和leg的分开的A-C网络结构,然后还有一个点是计算了两个优势函数,文章说这样会更好,至于部署那就是常规思路了,跟我之前介绍的几乎是一个样子的。
2.24 论文24《Arm-Constrained Curriculum Learning for Loco-Manipulation of the Wheel-Legged Robot》
2024 IROS

主要工作点:
- 轮足机器人的全身控制,效果很好(至少从视频里来看的话)
- constraint Critic
- 代码开源(但最关键的RSL_RL作者没给,导致根本训不出来)
- 说是reward aware curriculumn learning,其实也没看出来有啥效果,反正这个方向工作比较少,大家就当做参考得了
2.25 论文25 《UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers》
神中神,谁能想到这是一篇是22年的文章。。。。

GO2上用iphone作为里程计,也是很有生活了。。

另外UMI是Chicheng大佬的作品,没错就是diffusion policy的那篇工作的一作,nb
https://umi-on-legs.github.io/
3. 后记
这篇博客暂时记录到这里,日后我会继续补充---
别再催更了谢谢。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号