

python爬取数据出现 File "X:\PythonProject\TestForPython\TestOne.py", line 22, in <module> json_dat = json.loads(rest)错误的解决方法
终于想起密码系列,虽然并没啥人看就是了
进入正题
刚开始鼓捣python爬虫的时候,会遇到一个问题,爬取数据的时候出现
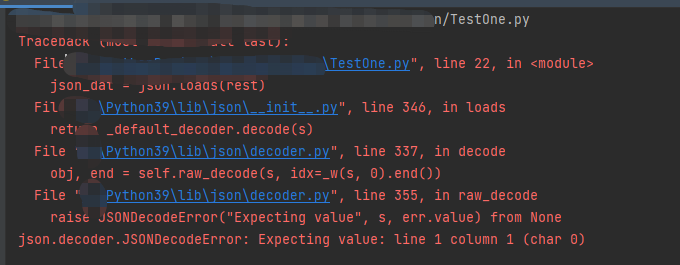
所示错误,然而作为刚接触python的小白,怎么办呢?百度咯,但是百度也需要具有信息辨识能力,所以很多真的小白这时候就抓虾了,
import jsonfrom wsgiref import headers import requests import openpyxl wk = openpyxl.Workbook() sheet = wk.create_sheet() # headers = { # 'Cookie': '__jdu=1346460638; shshshfpa=aa75bf58-3171-da18-191f-360a98550d67-1615295563; shshshfpb=jdSJQET/ 567e3SyfaIge6w==; PCSYCityID=CN_510000_510700_510722; areaId=22; ipLoc-djd=22-1960-1971-0; unpl=V2_ZzNtbUtfRUB2WkQAehEMUGIBG1wRVkVFdAtBUi8dVAU0AhddclRCFnUUR1FnGVwUZwYZWEtcQhBFCEdkeB5fA2AFEFlBZxpFK0oYEDlNDEY1WnxZRldAFXEIQlF6KWwGZzMSXHJXQRByDUFVfBtVNVcEIm1yX0YXdQpHZHopXTUlV05UR1dFEX1FRlZ+HlkCZgQQVHJWcxY=; __jdv=76161171|haosou-search|t_262767352_haosousearch|cpc|5512151540_0_897d2c3e09ad4380b07a0267e591b041|1618123685846; jwotest_product=99; shshshfp=370134af12e8d4990426035ce77fea65; __jda=122270672.1346460638.1615295561.1618123686.1618316905.4; __jdc=122270672; 3AB9D23F7A4B3C9B=ECYFDQGNCHZ4FKKSZ4PXJPYIXZGU6WCH5HBFC73MQG7DXDFPZNWPOS2JZNE4MZ5P6WXF5YGJ5PXJR27Y2ICR7BETIQ; JSESSIONID=D22413E458DDFF04ECB0945F5D387987.s1; shshshsID=1b3bdf824b9cf0c83e80d44d9dcae9db_2_1618317153636; __jdb=122270672.3.1346460638|4.1618316905', # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75' # } resp = requests.get( 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006811828&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1') # ,headers=headers) resp.content.decode("GBK") contents = resp.text rest = contents.replace('fetchJSON_comment98(', '').replace(');', '') json_dat = json.loads(rest) comments = json_dat['comments']for item in comments: color = item['productColor'] print(color) sheet.append([color]) wk.save('E:/pythonProject/py_1953.xlsx')
解决办法就是添加代码中注释掉的部分,因为既然有爬虫,那么很多网页都会做反爬虫处理,手动添加headers的目的就是为了将我们的访问模拟成普通访问,不至于被限制访问爬取数据。
headers:
User-Agent:用户数据和浏览器信息
Cookie:存储在本地追踪踪会话状态的加密文本信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号