




http://blog.csdn.net/tenfyguo/article/details/7476567
http://www.cnblogs.com/my_life/articles/7248429.html
一、什么是系统平均负载(Load average)?
在Linux系统中,uptime、w、top等命令都会有系统平均负载load average的输出,那么什么是系统平均负载呢?
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
例如:
[root@opendigest root]# uptime
7:51pm up 2 days, 5:43, 2 users, load average: 8.13, 5.90, 4.94
命令输出的最后内容表示在过去的1、5、15分钟内运行队列中的平均进程数量。
一般来说只要每个CPU的当前活动进程数不大于3那么系统的性能就是良好的,如果每个CPU的任务数大于5,那么就表示这台机器的性能有严重问题。
对于 上面的例子来说,假设系统有两个CPU,那么其每个CPU的当前任务数为:8.13/2=4.065。这表示该系统的性能是可以接受的。
二、Load average的算法
上面的输出数据是每隔5秒钟检查一次活跃的进程数,然后根据这个数值算出来的。如果这个数除以CPU的数目,结果高于5的时候就表明系统在超负荷运转了。其算法(摘自Linux 2.4的内核代码)如下:
文件: include/linux/sched.h:
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<#define LOAD_FREQ (5*HZ) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point, 2048/pow(exp(1), 5.0/60) */
#define EXP_5 2014 /* 1/exp(5sec/5min), 2048/pow(exp(1), 5.0/300) */
#define EXP_15 2037 /* 1/exp(5sec/15min), 2048/pow(exp(1), 5.0/900) */
#define CALC_LOAD(load,exp,n) \
load *= exp; \
load = n*(FIXED_1-exp); \
load >>= FSHIFT;
/**********************************************************/
文件: kernel/timer.c:
unsigned long avenrun[3];
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count = LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
/**********************************************************/
文件: fs/proc/proc_misc.c:
#define LOAD_INT(x) ((x) >> FSHIFT)
#define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100)
static int loadavg_read_proc(char *page, char **start, off_t off, int count, int *eof, void *data)
{
int a, b, c;
int len;
a = avenrun[0] (FIXED_1/200);
b = avenrun[1] (FIXED_1/200);
c = avenrun[2] (FIXED_1/200);
len = sprintf(page,"%d.d %d.d %d.d %ld/%d %d ",
LOAD_INT(a), LOAD_FRAC(a),
LOAD_INT(b), LOAD_FRAC(b),
LOAD_INT(c), LOAD_FRAC(c),
nr_running(), nr_threads, last_pid);
return proc_calc_metrics(page, start, off, count, eof, len);
}
三、/proc/loadavg 各项数据的含义
/proc文件系统是一个虚拟的文件系统,不占用磁盘空间,它反映了当前操作系统在内存中的运行情况,查看/proc下的文件可以聊寄到系统的运行状态。查看系统平均负载使用“cat /proc/loadavg”命令,输出结果如下:
0.27 0.36 0.37 4/83 4828/
前三个数字大家都知道,是1、5、15分钟内的平均进程数(有人认为是系统负荷的百分比,其实不然,有些时候可以看到200甚至更多)。后面两个呢,一个的分子是正在运行的进程数,分母是进程总数;另一个是最近运行的进程ID号。
四、查看系统平均负载的常用命令
1、cat /proc/loadavg
2、uptime
名称: uptime
使用权限: 所有使用者
使用方式: uptime [-V]
说明: uptime 提供使用者下面的资讯,不需其他参数:
现在的时间 系统开机运转到现在经过的时间 连线的使用者数量 最近一分钟,五分钟和十五分钟的系统负载
参数: -V 显示版本资讯。
范例: uptime
其结果为:
10:41am up 5 days, 10 min, 1 users, load average: 0.00, 0.00, 1.99
3、w
功能说明:显示目前登入系统的用户信息。
语 法:w [-fhlsuV][用户名称]
补充说明:执行这项指令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行w
指令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
参 数:
-f 开启或关闭显示用户从何处登入系统。
-h 不显示各栏位的标题信息列。
-l 使用详细格式列表,此为预设值。
-s 使用简洁格式列表,不显示用户登入时间,终端机阶段作业和程序所耗费的CPU时间。
-u 忽略执行程序的名称,以及该程序耗费CPU时间的信息。
-V 显示版本信息。
4、top
功能说明:显示,管理执行中的程序。
语 法:top [bciqsS][d <间隔秒数>][n <执行次数>]
补充说明:执行top指令可显示目前正在系统中执行的程序,并通过它所提供的互动式界面,用热键加以管理。
参 数:
b 使用批处理模式。
c 列出程序时,显示每个程序的完整指令,包括指令名称,路径和参数等相关信息。
d<间隔秒数> 设置top监控程序执行状况的间隔时间,单位以秒计算。
i 执行top指令时,忽略闲置或是已成为Zombie的程序。
n<执行次数> 设置监控信息的更新次数。
q 持续监控程序执行的状况。
s 使用保密模式,消除互动模式下的潜在危机。
S 使用累计模式,其效果类似ps指令的"-S"参数。
5、tload
功能说明:显示系统负载状况。
语 法:tload [-V][-d <间隔秒数>][-s <刻度大小>][终端机编号]
补充说明:tload指令使用ASCII字符简单地以文字模式显示系统负载状态。假设不给予终端机编号,则会在执行tload指令的终端机显示负载情形。
参 数:
-d<间隔秒数> 设置tload检测系统负载的间隔时间,单位以秒计算。
-s<刻度大小> 设置图表的垂直刻度大小,单位以列计算。
-V 显示版本信息。
上面的知识希望能对你有所收获。
===============
top进入视图
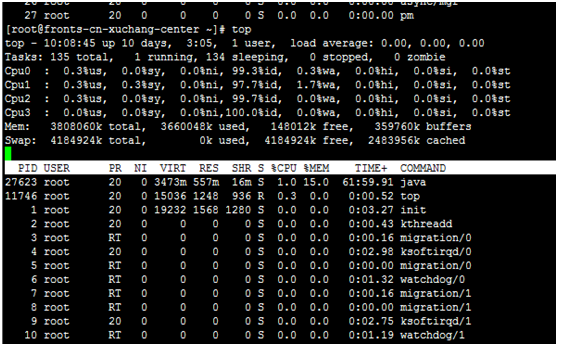
第一行:
10:08:45 — 当前系统时间
10 days, 3:05 — 系统已经运行了10天3小时5分钟(在这期间没有重启过)
1 users — 当前有1个用户登录系统
load average: 0.00, 0.00, 0.00 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
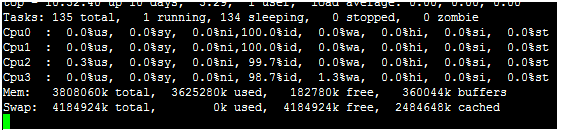
观察上图,服务器有4个逻辑CPU,实际上是1个物理CPU。
如果不按1,则在top视图里面显示的是所有cpu的平均值。
#avg_load
Load=$(cat /proc/loadavg | awk '{print $2}')
Disp_Load=`expr "scale=2; $Load/$CPU_Num" |bc`
echo $Disp_Load
top命令显示的是你的程序占用的cpu的总数,也就是说如果你是4核cpu那么cpu最高占用率可达400%
============
http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
一、查看系统负荷
如果你的电脑很慢,你或许想查看一下,它的工作量是否太大了。
在Linux系统中,我们一般使用uptime命令查看(w命令和top命令也行)。(另外,它们在苹果公司的Mac电脑上也适用。)
你在终端窗口键入uptime,系统会返回一行信息。
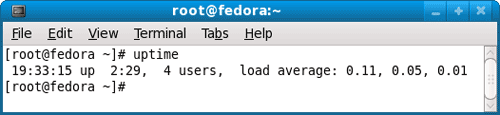
这行信息的后半部分,显示"load average",它的意思是"系统的平均负荷",里面有三个数字,我们可以从中判断系统负荷是大还是小。

为什么会有三个数字呢?你从手册中查到,它们的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。
如果你继续看手册,它还会告诉你,当CPU完全空闲的时候,平均负荷为0;当CPU工作量饱和的时候,平均负荷为1。
那么很显然,"load average"的值越低,比如等于0.2或0.3,就说明电脑的工作量越小,系统负荷比较轻。
但是,什么时候能看出系统负荷比较重呢?等于1的时候,还是等于0.5或等于1.5的时候?如果1分钟、5分钟、15分钟三个值不一样,怎么办?
二、一个类比
判断系统负荷是否过重,必须理解load average的真正含义。下面,我根据"Understanding Linux CPU Load"这篇文章,尝试用最通俗的语言,解释这个问题。
首先,假设最简单的情况,你的电脑只有一个CPU,所有的运算都必须由这个CPU来完成。
那么,我们不妨把这个CPU想象成一座大桥,桥上只有一根车道,所有车辆都必须从这根车道上通过。(很显然,这座桥只能单向通行。)
系统负荷为0,意味着大桥上一辆车也没有。

系统负荷为0.5,意味着大桥一半的路段有车。

系统负荷为1.0,意味着大桥的所有路段都有车,也就是说大桥已经"满"了。但是必须注意的是,直到此时大桥还是能顺畅通行的。

系统负荷为1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%。以此类推,系统负荷2.0,意味着等待上桥的车辆与桥面的车辆一样多;系统负荷3.0,意味着等待上桥的车辆是桥面车辆的2倍。总之,当系统负荷大于1,后面的车辆就必须等待了;系统负荷越大,过桥就必须等得越久。

CPU的系统负荷,基本上等同于上面的类比。大桥的通行能力,就是CPU的最大工作量;桥梁上的车辆,就是一个个等待CPU处理的进程(process)。
如果CPU每分钟最多处理100个进程,那么系统负荷0.2,意味着CPU在这1分钟里只处理20个进程;系统负荷1.0,意味着CPU在这1分钟里正好处理100个进程;系统负荷1.7,意味着除了CPU正在处理的100个进程以外,还有70个进程正排队等着CPU处理。
为了电脑顺畅运行,系统负荷最好不要超过1.0,这样就没有进程需要等待了,所有进程都能第一时间得到处理。很显然,1.0是一个关键值,超过这个值,系统就不在最佳状态了,你要动手干预了。
三、系统负荷的经验法则
1.0是系统负荷的理想值吗?
不一定,系统管理员往往会留一点余地,当这个值达到0.7,就应当引起注意了。经验法则是这样的:
当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
四、多处理器
上面,我们假设你的电脑只有1个CPU。如果你的电脑装了2个CPU,会发生什么情况呢?
2个CPU,意味着电脑的处理能力翻了一倍,能够同时处理的进程数量也翻了一倍。
还是用大桥来类比,两个CPU就意味着大桥有两根车道了,通车能力翻倍了。

所以,2个CPU表明系统负荷可以达到2.0,此时每个CPU都达到100%的工作量。推广开来,n个CPU的电脑,可接受的系统负荷最大为n.0。
五、多核处理器
芯片厂商往往在一个CPU内部,包含多个CPU核心,这被称为多核CPU。
在系统负荷方面,多核CPU与多CPU效果类似,所以考虑系统负荷的时候,必须考虑这台电脑有几个CPU、每个CPU有几个核心。然后,把系统负荷除以总的核心数,只要每个核心的负荷不超过1.0,就表明电脑正常运行。
怎么知道电脑有多少个CPU核心呢?
"cat /proc/cpuinfo"命令,可以查看CPU信息。"grep -c 'model name' /proc/cpuinfo"命令,直接返回CPU的总核心数。
六、最佳观察时长
最后一个问题,"load average"一共返回三个平均值----1分钟系统负荷、5分钟系统负荷,15分钟系统负荷,----应该参考哪个值?
如果只有1分钟的系统负荷大于1.0,其他两个时间段都小于1.0,这表明只是暂时现象,问题不大。
如果15分钟内,平均系统负荷大于1.0(调整CPU核心数之后),表明问题持续存在,不是暂时现象。所以,你应该主要观察"15分钟系统负荷",将它作为电脑正常运行的指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号