
http://blog.csdn.net/solstice/article/details/6527585
TCP是“面向连接的、可靠的、字节流传输协议”,这里的“可靠”究竟是什么意思?《Effective TCP/IP Programming》第9条说:Realize That TCP Is a Reliable Protocol, Not an Infallible Protocol,那么TCP在哪种情况下会出错?这里说的“出错”指的是收到的数据与发送的数据不一致,而不是数据不可达。
我在《一种自动反射消息类型的 Google Protobuf 网络传输方案》中设计了带check sum的消息格式,很多人表示不理解,认为是多余的。IP header里边有check sum,TCP header也有check sum,链路层以太网还有CRC32校验,那么为什么还需要在应用层做校验?什么情况下TCP传送的数据会出错?
IP header和TCP header的check sum是一种非常弱的16-bit check sum算法,把数据当成反码表示的16-bit integers,再加到一起。这种checksum算法能检出一些简单的错误,而对某些错误无能为力,由于是简单的加法,遇到“和”不变的情况就无法检查出错误(比如交换两个16-bit整数,加法满足交换律,结果不变)。以太网的CRC32比较强,但它只能保证同一个网段上的通信不会出错(两台机器的网线插到同一个交换机上,这时候以太网的CRC是有用的)。但是,如果两台机器之间经过了多级路由器呢?
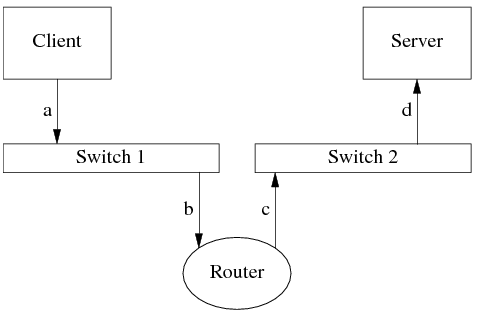
上图中Client向Server发了一个TCP segment,这个segment先被封装成一个IP packet,再被封装成ethernet frame,发送到路由器(图中消息a)。Router收到ethernet frame (b),转发到另一个网段(c),最后Server收到d,通知应用程序。
Ethernet CRC能保证a和b相同,c和d相同;TCP header check sum的强度不足以保证收发payload的内容一样。另外,如果把Router换成NAT,那么NAT自己会构造c(替换掉源地址),这时候a和d的payload不能用tcp header checksum校验。
路由器可能出现硬件故障,比方说它的内存故障(或偶然错误)导致收发IP报文出现多bit的反转或双字节交换,这个反转如果发生在payload区,那么无法用链路层、网络层、传输层的check sum查出来,只能通过应用层的check sum来检测。
这个现象在开发的时候不会遇到,因为开发用的几台机器很可能都连到同一个交换机,ethernet CRC能防止错误。开发和测试的时候数据量不大,错误很难发生。之后大规模部署到生产环境,网络环境复杂,这时候出个错就让人措手不及。
有一篇论文《When the CRC and TCP checksum disagree》分析了这个问题。另外《The Limitations of the Ethernet CRC and TCP/IP checksums for error detection》(http://noahdavids.org/self_published/CRC_and_checksum.html)也值得一读。
这个情况真的会发生吗?会的,Amazon S3 在2008年7月就遇到过,单bit反转导致了一次严重线上事故,所以他们吸取教训加了 check sum。见http://status.aws.amazon.com/s3-20080720.html
另外一个例证:下载大文件的时候一般都会附上MD5,这除了有安全方面的考虑(防止篡改),也说明应用层应该自己设法校验数据的正确性。这是end-to-end principle的一个例证。
TCP作为一个可靠的传输层协议,其核心有三点:
1. Positive acknowledgement with retransmission (重传)
2. Flow control using sliding window(包括Nagle 算法等,批量传)
3. Congestion control(包括slow start、congestion avoidance、fast retransmit等)
第一点已经足以满足“可靠性”要求(为什么?);
第二点是为了提高吞吐量,充分利用链路层带宽;
第三点是防止过载造成丢包。
换言之,第二点是避免发得太慢,第三点是避免发得太快,二者相互制约。从反馈控制的角度看,TCP像是一个自适应的节流阀,根据管道的拥堵情况自动调整阀门的流量。
Java Byte之Adler32算法对数据流的校验
Java Byte之Adler32算法对数据流的校验代码如下:
import java.util.zip.Adler32;import java.util.zip.Checksum;/** * @from www.everycoding.com * @Description:Java Byte之Adler32算法对数据流的校验 */public class ComputeAdler { public static void main(String[] argv) throws Exception { /** * 可用于计算数据流的 Adler-32 校验和的类。Adler-32 校验和几乎与 * CRC-32 一样可靠,但是能够更快地计算出来。 */ byte[] bytes = "www.everycoding.com".getBytes(); Checksum checksumEngine = new Adler32(); checksumEngine.update(bytes, 0, bytes.length); long checksum = checksumEngine.getValue(); System.out.println("生成用于比对数据完整性的校验码:"+checksum); }}执行结果如下:
CRC全称Cyclic Redundancy Check,又叫循环冗余校验。它是一种散列函数(HASH,把任意长度的输入通过散列算法,最终变换成固定长度的摘要输出,其结果就是散列值,按照HASH算法,HASH具有单向性,不可逆性),用来检测或校验传输或保存的数据错误,在通信领域广泛地用于实现差错控制,比如通信系统多使用CRC12和CRC16,XMODEM使用CRC16等等(12、16、32等值均是指多项式的最高阶N次幂),天缘早前在做通信方面工作时也是最常用到这个校验方法,因为其编解码方法都非常简单,运算时间也很短。
但从理论角度,CRC不能完全可靠的验证数据完整性,因为CRC多项式是线性结构,很容易通过改变数据方式达到CRC碰撞,天缘这里给一个更加通俗的解释,假设一串带有CRC校验的代码在传输中,如果连续出现差错,当出错次数达到一定次数时,那么几乎可以肯定会出现一次碰撞(值不对但CRC结果正确),但随着CRC数据位增加,碰撞几率会显著降低,比如CRC32比CRC16具有更可靠的验证性,CRC64又会比CRC32更可靠,当然这都是按照ITU规范标准条件下。
正因为CRC具有以上特点,对于网络上传输的文件类很少只使用CRC作为校验依据,文件传输相比通信底层传输风险更大,很容易受到人为干预影响。
从奇偶校验说起
所谓通讯过程的校验是指在通讯数据后加上一些附加信息,通过这些附加信息来判断接收到的数据是否和发送出的数据相同。比如说RS232串行通讯可以设置奇偶校验位,所谓奇偶校验就是在发送的每一个字节后都加上一位,使得每个字节中1的个数为奇数个或偶数个。比如我们要发送的字节是0x1a,二进制表示为0001 1010。【】
采用奇校验,则在数据后补上个0,数据变为0001 1010 0,数据中1的个数为奇数个(3个)
采用偶校验,则在数据后补上个1,数据变为0001 1010 1,数据中1的个数为偶数个(4个)
接收方通过计算数据中1个数是否满足奇偶性来确定数据是否有错。
奇偶校验的缺点也很明显,首先,它对错误的检测概率大约只有50%。也就是只有一半的错误它能够检测出来。另外,每传输一个字节都要附加一位校验位,对传输效率的影响很大。因此,在高速数据通讯中很少采用奇偶校验。奇偶校验优点也很明显,它很简单,因此可以用硬件来实现,这样可以减少软件的负担。因此,奇偶校验也被广泛的应用着。
奇偶校验就先介绍到这来,之所以从奇偶校验说起,是因为这种校验方式最简单,而且后面将会知道奇偶校验其实就是CRC 校验的一种(CRC-1)。
累加和校验
另一种常见的校验方式是累加和校验。所谓累加和校验实现方式有很多种,最常用的一种是在一次通讯数据包的最后加入一个字节的校验数据。这个字节内容为前面数据包中全部数据的忽略进位的按字节累加和。比如下面的例子:
我们要传输的信息为: 6、23、4
加上校验和后的数据包:6、23、4、33
这里 33 为前三个字节的校验和。接收方收到全部数据后对前三个数据进行同样的累加计算,如果累加和与最后一个字节相同的话就认为传输的数据没有错误。
累加和校验由于实现起来非常简单,也被广泛的采用。但是这种校验方式的检错能力也比较一般,对于单字节的校验和大概有1/256 的概率将原本是错误的通讯数据误判为正确数据。之所以这里介绍这种校验,是因为CRC校验在传输数据的形式上与累加和校验是相同的,都可以表示为:通讯数据 校验字节(也可能是多个字节)
初识 CRC 算法
CRC 算法的基本思想是将传输的数据当做一个位数很长的数。将这个数除以另一个数。得到的余数作为校验数据附加到原数据后面。还以上面例子中的数据为例:
6、23、4 可以看做一个2进制数: 0000011000010111 00000010
假如被除数选9,二进制表示为:1001

 浙公网安备 33010602011771号
浙公网安备 33010602011771号