




Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
mysql -h主机地址 -u用户名 -p用户密码
show create database database_name ; //查询创建该数据库的命令
show create table table_name ; //查询创建该表的命令
- select * from table limit 7,100; //搜索记录行 8-100
- select * from table limit 7,-1; //搜索记录行 8到最后一行
- select * from table limit 7; //搜索前7行记录
- select * from table limit 0,7; //跟上一条命令等价,搜索前7行记录
select t_id,t_name from test order by t_id;
select t_id,t_name from test order by t_id desc;
select count(1) from test1;
select count(column_name) from test1;
select count(*) from test1;
count(1)或括号中是其它数字、字段名,表示只选择该字段(或数字)进行查询,而count(*)表示选择所有的字段进行查询。所以结果是count(*)的查询效率比count(1)低,根据表的结构而定,一张很大的表,效率可能会低很多。所以,我个人的建议是,需要出现count的地方,都不要用count(*),这是跟服务器过不去。
https://www.cnblogs.com/jiechn/p/3979261.html
select 1 from table;
select xxx(表集合中的任意一行) from table;
select * from table
从作用上来说是没有差别的,都是查看是否有记录,一般是作条件查询用的。
select 1 from 中的1是一常量(可以为任意数值),查到的所有行的值都是它,但从效率上来说,1 > xxx > *,因为不用查字典表。
1:select 1 from table 增加一个临时列,没有列名,列的值都是1,每行的列值是写在select后的数,这条sql语句中是1
2:select count(1) from table 管count(a)的a值如何变化,得出的值总是table表的行数
3:select sum(1) from table 计算临时列的和
一般用来当做判断子查询是否成功(即是否有满足条件的时候使用)
比如:select * from ta where exists (select 1 from ta.id = tb.id)
这个判断就是(select 1 from ta.id = tb.id)这个查询如果有返回值的话表示当前查询满足条件,一般来说使用select 1, 当然也可以用select * ,或者select 任何东东,因为这里仅仅是表明子查询有结果就行了,至于什么结果无所谓。
http://www.w3school.com.cn/sql/sql_primarykey.asp
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
创建主键的sql:
MySQL:
CREATE TABLE Persons ( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255),PRIMARY KEY (Id_P))
- 外键:外键用于关联两个表。
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作;
http://www.cppblog.com/wolf/articles/69089.html
提示:删除大哥:不行呀,有约束的,大哥下面还有小弟,可不能扔下我们不管呀!
提示:插入小弟:小子,想造反呀!你还没大哥呢!
管理MySQL的命令
以下列出了使用Mysql数据库过程中常用的命令:
- USE 数据库名 :选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
- SHOW DATABASES: 列出 MySQL 数据库管理系统的数据库列表。
- SHOW TABLES: 显示指定数据库的所有表,使用该命令前需要使用 use 命令来选择要操作的数据库。
- SHOW COLUMNS FROM 数据表: 显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
- SHOW INDEX FROM 数据表: 显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
- SHOW TABLE STATUS LIKE 数据表\G: 该命令将输出Mysql数据库管理系统的性能及统计信息。
- select database(); 查看当前使用的是哪个数据库
- status 查看数据库的状态信息
http://blog.163.com/yang_jianli/blog/static/16199000620129150645784/
在SQL语句或者命令后使用\G而不是分号结尾,可以将每一行的值垂直输出。
如果select出来的结果集超过几个屏幕,那么前面的结果一晃而过无法看到。使用pager可以设置调用os的more或者less等显示查询结果,和在os中使用more或者less查看大文件的效果一样。
mysql> pager more
PAGER set to ‘more’
mysql> pager less
PAGER set to ‘less’
还原
mysql> nopager
PAGER set to stdout
3.使用tee保存运行结果到文件
这个类似于sqlplus的spool功能,可以将命令行中的结果保存到外部文件中。如果指定已经存在的文件,则结果会附加到文件中。
mysql> tee output.txt
Logging to file ‘output.txt’
4.执行OS命令
mysql> system uname
Linux
mysql> ! uname
Linux
5.执行SQL文件
mysql> source test.sql
+—————-+
| current_date() |
+—————-+
| 2008-06-28 |
+—————-+
1 row in set (0.00 sec)
或者
mysql> . test.sql
+—————-+
| current_date() |
+—————-+
| 2008-06-28 |
+—————-+
1 row in set (0.00 sec)
其他还有一些功能,可以通过help或者?获得MySQL命令行支持的一些命令。
继续上面的的话题,介绍mysql命令行的一些小技巧
1.以html格式输出结果
使用mysql客户端的参数–html或者-T,则所有SQL的查询结果会自动生成为html的table代码
$ mysql -uroot –html Welcome to the MySQL monitor. Commands end with ; or g. YourMySQL connection id is 3286 Server version: 5.1.24-rc-log MySQL Community Server (GPL) Type ‘help;’ or ‘h’ for help. Type ‘c’ to clear the buffer. mysql> select * from test.test;
2 rows in set (0.00 sec)
2.以xml格式输出结果
跟上面差不多,使用–xml或者-X选项,可以将结果输出为xml格式
$ mysql -uroot –xml Welcome to the MySQL monitor. Commands end with ; or g. Your MySQLconnection id is 3287 Server version: 5.1.24-rc-log MySQL Community Server (GPL) Type ‘help;’ or ‘h’ for help. Type ‘c’ to clear the buffer. mysql> select * from test.test;
2 rows in set (0.00 sec)
3.修改命令提示符
使用mysql的–prompt=选项,或者进入mysql命令行环境后使用prompt命令,都可以修改提示符
mysql> prompt u@d> PROMPT set to ‘u@d>’ root@(none)>use mysql Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed root@mysql>
其中u表示当前连接的用户,d表示当前连接的数据库,其他更多的可选项可以参考man mysql
这里再介绍下通过配置文件来设置MySQL命令行的这些参数。
通过/etc/my.cnf配置文件的[mysql]部分,可以设置MySQL命令行的一些运行参数。例如:
[mysql] prompt=\u@\d \r:\m:\s> pager=’less -S’ tee=’/tmp/mysql.log’
通过prompt设置显示用户名,当前数据库和当前时间,注意在配置文件里最好使用双斜杠:
root@poster 10:26:35>
通过pager设置使用less来显示查询结果,-S表示截断超过屏幕宽度的行,一行太长MySQL的显示格式就显得很乱,如果要看完整的行,建议使用G将行垂直输出。当然,你也可以添加更多less的参数来控制输出。
tee则将MySQL执行的所有输出保存到一个日志文件中,即使使用less -S截断了超长行,在日志中还是会记录整个的结果,另外,前面通过prompt设置了当前时间显示,这样也便于在日志文件中查看每次操作的时间。由于tee的结果是附加到文件中的,日志文件需要定期清除。
SELECT ... WHERE id IN (1, 3, 4);
\g 的作用是分号和在sql语句中写’;’是等效的
\G 的作用是将查到的结构旋转90度变成纵向
\g的使用例子:查找一个表的创建语句
mysql> create table mytable(id int)\g
Query OK, 0 rows affected (0.21 sec)
mysql> show create table mytable \g
+---------+-------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+-------------------------------------------------------------------------------------------+
| mytable | CREATE TABLE `mytable` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+-------------------------------------------------------------------------------------------+
1 row in set (0.04 sec)
上面的查找的表的创建语句看着很别扭,那么可以使用\G,试一下就知道它的用途了
mysql> show create table mytable \G
*************************** 1. row ***************************
Table: mytable
Create Table: CREATE TABLE `mytable` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
这个时候用着\G感觉使结果很清晰
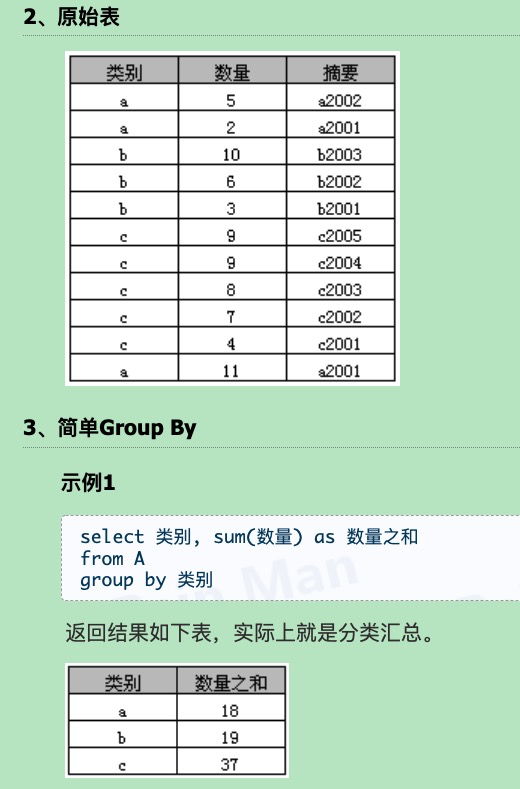
- group by
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
select 类别, sum(数量) as 数量之和 from A group by 类别

\
在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A where 数量 > 8 group by 类别 having SUM(数量) > 10
https://blog.csdn.net/liitdar/article/details/85272035
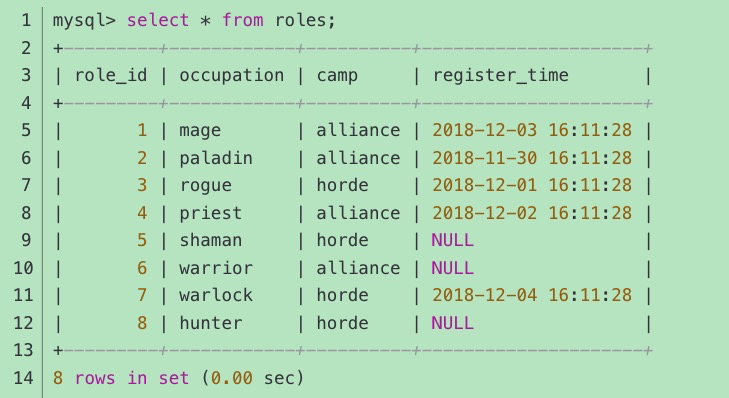
不使用聚合函数,只使用 GROUP BY,查询结果如下:
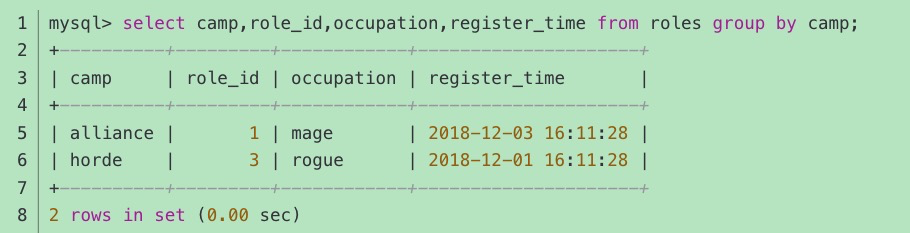
上述查询结果表明,当不使用聚合函数时,GROUP BY 的结果是分组内容中的第一条查询结果。 【重复的记录别丢弃了,所以group by必须配合聚合函数来找最大最小等,只能找最值,不能最同组记录的拼接】
当然,在实际使用中,通常都需要将 GROUP BY 与聚合函数结合起来使用,来实现某种目的。
例如,我们想查找“联盟和部落阵营中所有角色最早的注册时间”,则可以通过如下语句实现:
2.2 HAVING子句
HAVING 子句可以筛选通过 GROUP BY 分组后的各组数据。
承接上文内容,通过 HAVING 子句筛选出所有阵营中最早的注册时间,语句如下:

注意:上述语句中 HAVING 的对象 register_time,实际上是前面聚合函数 MIN(register_time) 的结果集。【having的对象是 select的集合的子集】
而由于 WHERE 子句不能包含聚合函数,所以此处只能使用 HAVING 子句。如果使用 WHERE 子句替换 HAVING 子句,命令会报错,信息如下:
mysql> select camp,MIN(register_time) as register_time from roles group by camp WHERE register_time > '2018-12-01 00:00:00';
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'WHERE register_time > '2018-12-01 00:00:00'' at line 1
mysql>
【HAVING 与 WHERE 的区别】:
WHERE 子句的作用:在对查询结果进行分组前,把不符合 WHERE 条件的行去掉,即在分组之前过滤数据。另外,WHERE 条件中不能包含聚组函数。
HAVING 子句的作用:筛选满足条件的组,即在分组后过滤数据,条件中经常包含聚组函数,使用 HAVING 条件过滤出特定的组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号