
http://ifeve.com/deadlock-prevention/
http://tutorials.jenkov.com/java-concurrency/deadlock-prevention.html
http://blog.sina.com.cn/s/blog_48d4cf2d0100mx5n.html
有时表面上看似发生了死锁,实际上有可能是发生了死循环。。。。。查看CPU执行时间
在有些情况下死锁是可以避免的。本文将展示三种用于避免死锁的技术:
加锁顺序
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。
如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。看下面这个例子:
Thread 1: lock A lock B Thread 2: wait for A lock C (when A locked) Thread 3: wait for A wait for B wait for C
如果一个线程(比如线程3)需要一些锁,那么它必须按照确定的顺序获取锁。它只有获得了从顺序上排在前面的锁之后,才能获取后面的锁。
例如,线程2和线程3只有在获取了锁A之后才能尝试获取锁C(译者注:获取锁A是获取锁C的必要条件)。因为线程1已经拥有了锁A,所以线程2和3需要一直等到锁A被释放。然后在它们尝试对B或C加锁之前,必须成功地对A加了锁。
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁(译者注:并对这些锁做适当的排序),但总有些时候是无法预知的。
加锁时限
另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行(译者注:加锁超时后可以先继续运行干点其它事情,再回头来重复之前加锁的逻辑)。
以下是一个例子,展示了两个线程以不同的顺序尝试获取相同的两个锁,在发生超时后回退并重试的场景:
Thread 1 locks A Thread 2 locks B Thread 1 attempts to lock B but is blocked Thread 2 attempts to lock A but is blocked Thread 1's lock attempt on B times out Thread 1 backs up and releases A as well Thread 1 waits randomly (e.g. 257 millis) before retrying. Thread 2's lock attempt on A times out Thread 2 backs up and releases B as well Thread 2 waits randomly (e.g. 43 millis) before retrying.
在上面的例子中,线程2比线程1早200毫秒进行重试加锁,因此它可以先成功地获取到两个锁。这时,线程1尝试获取锁A并且处于等待状态。当线程2结束时,线程1也可以顺利的获得这两个锁(除非线程2或者其它线程在线程1成功获得两个锁之前又获得其中的一些锁)。
需要注意的是,由于存在锁的超时,所以我们不能认为这种场景就一定是出现了死锁。也可能是因为获得了锁的线程(导致其它线程超时)需要很长的时间去完成它的任务。
此外,如果有非常多的线程同一时间去竞争同一批资源,就算有超时和回退机制,还是可能会导致这些线程重复地尝试但却始终得不到锁。如果只有两个线程,并且重试的超时时间设定为0到500毫秒之间,这种现象可能不会发生,但是如果是10个或20个线程情况就不同了。因为这些线程等待相等的重试时间的概率就高的多(或者非常接近以至于会出现问题)。
(译者注:超时和重试机制是为了避免在同一时间出现的竞争,但是当线程很多时,其中两个或多个线程的超时时间一样或者接近的可能性就会很大,因此就算出现竞争而导致超时后,由于超时时间一样,它们又会同时开始重试,导致新一轮的竞争,带来了新的问题。)
这种机制存在一个问题,在Java中不能对synchronized同步块设置超时时间。你需要创建一个自定义锁,或使用Java5中java.util.concurrent包下的工具。写一个自定义锁类不复杂,但超出了本文的内容。后续的Java并发系列会涵盖自定义锁的内容。
死锁检测
死锁检测是一个更好的死锁预防机制,它主要是针对那些不可能实现按序加锁并且锁超时也不可行的场景。
每当一个线程获得了锁,会在线程和锁相关的数据结构中(map、graph等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。例如,线程A请求锁7,但是锁7这个时候被线程B持有,这时线程A就可以检查一下线程B是否已经请求了线程A当前所持有的锁。如果线程B确实有这样的请求,那么就是发生了死锁(线程A拥有锁1,请求锁7;线程B拥有锁7,请求锁1)。
当然,死锁一般要比两个线程互相持有对方的锁这种情况要复杂的多。线程A等待线程B,线程B等待线程C,线程C等待线程D,线程D又在等待线程A。线程A为了检测死锁,它需要递进地检测所有被B请求的锁。从线程B所请求的锁开始,线程A找到了线程C,然后又找到了线程D,发现线程D请求的锁被线程A自己持有着。这是它就知道发生了死锁。
下面是一幅关于四个线程(A,B,C和D)之间锁占有和请求的关系图。像这样的数据结构就可以被用来检测死锁。
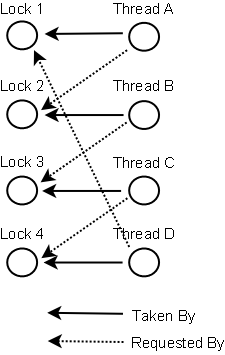
那么当检测出死锁时,这些线程该做些什么呢?
一个可行的做法是释放所有锁,回退,并且等待一段随机的时间后重试。这个和简单的加锁超时类似,不一样的是只有死锁已经发生了才回退,而不会是因为加锁的请求超时了。虽然有回退和等待,但是如果有大量的线程竞争同一批锁,它们还是会重复地死锁(编者注:原因同超时类似,不能从根本上减轻竞争)。
一个更好的方案是给这些线程设置优先级,让一个(或几个)线程回退,剩下的线程就像没发生死锁一样继续保持着它们需要的锁。如果赋予这些线程的优先级是固定不变的,同一批线程总是会拥有更高的优先级。为避免这个问题,可以在死锁发生的时候设置随机的优先级。
扩展阅读:译者注
- 《现代操作系统 第三版》§6.2~§6.7
原创文章,转载请注明: 转载自并发编程网 – ifeve.com
本文链接地址: 避免死锁
===========================================
死锁是指永久阻塞一组争用一组资源的线程。仅因为某个线程可以继续执行,并不表示不会在某个其他位置发生死锁。
====================
通常意义上的死锁是由于不同线程(也可能是进程或者虚拟线程)请求锁的顺序不同造成的。google如何避免死锁,随便一篇文章都会告诉你只要按照同样的顺序请求锁,就可以避免死锁。这可能适用于大部分并发应用。但有些并发程序情况比较复杂,很难应用该条规则。
具体一点,举IM软件为例:假设每个用户(属性有用户名、连接啊、发送的消息列表、接收的消息列表之类)是类Client的实例client。假设每个client有个方法void sendMsg(Client& target, const Msg& msg),这个方法先把消息加入对方的接收列表,再把消息加入自己的发送列表。显然,第一步需要锁住对方对象,第二步需要锁住自己对象。那如果有两个线程:一个执行clienta.sentMsg(clientb, xxx),一个执行clientb.sendMsg(clienta, yyy)就将可能死锁。因为前者请求顺序是(clientb.lock=>clienta.lock),后者是(clienta.lock=>clientb.lock)。注意,将两个步骤顺序颠倒结果也是一样。
应用万能定律?好吧。我们把所有的client的锁排好序,在每个sendMsg的开头按顺序请求所有需要的锁。OK?即使不在乎锁排序的时空开销和编程麻烦,还必须满足一个很严苛的要求:在sendMsg中不能去调用其他可能上锁的函数。否则假设sendMsg请求了锁11,锁40,其调用的函数请求了锁32,锁48。则一样违背了规则,仍有死锁可能。
针对这个情况,可能会有一个想法,何必这么麻烦呢?用一个锁保护发送队列,一个锁保护接收队列。则前者请求顺序(clientb.recvq_lock=>clienta.sendq_lock),后者是(clienta.recvq_lock=>clienta.sendq_lock)。哇,避免死锁的同时提高了效率。但这只是一个看似美好的解决方案。根据我的经验,锁越多越可能死锁!尤其当程序足够复杂的时候。我的建议是如果不是成为性能瓶颈,尽量不要进行锁拆分。(今天我刚阅读出项目中某个类存在死锁可能,正是由于锁拆分引起的。)如果保证并发对象一个对象只用一个锁就可以减少很多死锁了。不怕不优化,就怕乱优化。
如果是我会这么处理:第一步结束后就释放对方的锁。则整个函数执行中最多保有1个锁,自然不会有死锁问题。(估计有人会大喊:骗子,还以为要说啥高深的内容)。嗯,请参考我前几天的blog《一个笑话和其对开发的启示》。其实就是这么简单,避免同时握有多个锁,自然不会有死锁问题哈哈。具体如何应用?很简单,就两条规则。
规则一:类的每个成员函数,在调用其他函数(包括本类的其他成员函数)前先释放本对象的锁(如果持有的话),在返回后再获得本对象的锁(如果需要的话);
规则二:在成员函数内部不去获得其他锁(需要获得其他对象的锁一般是要改目标对象的一些属性,把加锁+修改抽取成类的成员函数即可)。
伪代码如下:
void Client::addToRecvQueue(const Msg& msg)
{
scoped_lock lk(lock); //RAII lock
// TODO: add to recv queue
}
void Client::sendMsg(Client& target, const Msg& msg)
{
target.addToRecvQueue(msg);
{
scoped_lock lk(lock); //RAII lock
// TODO: add to send queue
}
}
如果所有类实现时都满足这两条规则,则不管他们之间调用关系如何错综复杂,都可以保证线程执行时总是只持有一个锁,自然也就没有死锁问题!
哇哈哈哈,问题完美解决?从此一身轻松,远离死锁?没这么容易哈。首先有些时候这么做可能会有效率问题(长调用时加解锁太多次),另外有时候规则一是不可行的(规则二总是可行,而且建议始终采用,因为比较符合面向对象的思想)。比如:有一个类叫Room,是client的容器,有一个方法void sendToAllOtherClients(Client& source, const Msg& msg)。在遍历client的过程中必然要锁住Room对象,不然没法保证遍历的有效性。
当容器对象纷纷粉墨登场后,情况变得更为复杂了。这时候需要把万能规则也用进来。即保证先锁容器锁,再锁其他对象锁。一个操作需要锁多个容器?呵呵。目前我还没遇到这种情况,遇到了再说吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号