




https://git-scm.com/book/zh/v1/Git-%E5%88%86%E6%94%AF-%E5%88%86%E6%94%AF%E7%9A%84%E8%A1%8D%E5%90%88
http://www.html-js.com/article/Week-end-column-Git-crash-course-git-rebase
http://gitbook.liuhui998.com/4_2.html
http://weizhifeng.net/git-rebase.html
git rebase master feature
#把master上有的,feature没有的临时存起来;之后checkout feature,把修改合并到feature上;不会把差集应用到master上。
$ git rebase --onto <newbase> <upstream> <branch>
#执行步骤:1,checkout branch 2,找出branch和upstream之间的差集, 3,把差集应用到newbase上
后面有的说的不对。
git rebase --onto feature master feature
1: checkout 到feature分支
2:找出feature上有的,master上没有的commits,把这些commits临时存起来【注意顺序:feature上有的,master上没有的】
3: 把刚刚生成的临时commits应用到feature上 (--onto)
实际上这一条命令没有任何效果 (因为你把feature上的差异又一次应用到了feature上)
git rebase是个非常强大灵活的命令,它可以让你对commit进行修改、调整顺序、合并等操作、并能以线性的方式进行分支的合并与嫁接等。
简单来说rebase就是把某个分支上的一部分commit嫁接到另一个commit后面,而在这个过程中这些commit的base(基)变了,所以这个操作叫做『变基』。
比如我们有如下的提交历史,当前的分支是topic:
A---B---C topic(HEAD) // HEAD,当前所在的branch
/
D---E---F---G master
我们执行了如下任何一个命令之后:
$ git rebase master #当前的HEAD在top分支
$ git rebase master topic #效果一样;checkout到topic上,把master上有的,topic上没有的,应用到topic上。
提交历史将会变成如下这样:
A'--B'--C' topic(HEAD)
/
D---E---F---G master
可以看出git把A---B---C这段commit嫁接到了G之后,不过虽然这些新commit的内容是一样的,但是hash值是不同的(A'--B'--C'),原因将在后面解释。
命令完整的形式如下:
$ git rebase <upstream> <branch>
其中<upstream>是新的base,如果你提供<branch>,那么首先会checkout到这个<branch>,然后再进行rebase操作。所以以下两种方式
$ git rebase master topic
$ git rebase master
的区别是第一种形式会首先checkout到topic分支,然后再执行rebase的操作。
那么rebase都做了什么事情呢?
-
首先,git会对topic分支和
<upstream>做一个差集,把不同的commit找出来,类似于执行git log <upstream>..HEAD,对于以上例子来说结果就是A---B---C,然后把这些commit存在一个临时的地方。 -
其次,git会把当前分支reset到
<upstream>上,类似于执行git reset --hard <upstream>命令。对于以上例子来说就是reset到master。 -
最后,git把第一步中暂存的commit,按照顺序一个一个地应用到分支上,相当于一个一个重复提交,这就是为什么rebase之后commit的hash值变了。
如果中的一个commit进行了某项修改,而当前分支中也存在一个commit,这两个commit的修改的内容一样,那么当前分支中的commit将会被忽略。比如以下的```A```和```A'```就是这样两个commit。
A---B---C topic
/
D---E---A'---F master
执行完git rebase master之后,结果如下:
B'---C' topic
/
D---E---A'---F master
如果你想更灵活的进行commit嫁接,那么你需要rebase --onto,命令格式如下:
$ git rebase --onto <newbase> <upstream> <branch>
#执行步骤:1,checkout branch 2,找出branch和upstream之间的差集, 3,把差集应用到newbase上假设你有如下的branch tree:
o---o---o---o---o master
\
o---o---o---o---o next
\
o---o---o topic
你想要得到如下的branch tree:
o---o---o---o---o master
| \
| o'--o'--o' topic
\
o---o---o---o---o next
那我们需要如下操作:
$ git rebase --onto master next topic #找出topic上有的,而next上没有的commit,把它们应用到master上
这个操作会把从next开始的commit嫁接到master上。如果你提供<branch>,那么首先会checkout到这个<branch>,然后再进行rebase操作。
我们再看一个例子,比如我们有如下的branch tree:
E---F---G---H---I---J topicA
我们想要删除F---G这两个commit,那么通过rebase --onto就可以实现:
$ git rebase --onto topicA~5 topicA~3 topicA
执行结果是:
E---H'---I'---J' topicA
同样,rebase也会产生冲突,当解决完冲突之后你可以继续rebase的进程:
$ git rebase --continue
或者取消此次rebase:
$ git rebase --abort
关于commit修改、顺序调整、合并等操作可以通过rebase -i来完成
$ git rebase -i <upstream>
chitsaou写的《Git-rebase 小筆記》中有详细的介绍,可以自行查看。
参考
(全文完)
===============================================================================
git rebase upstream 三步:《upstream: 当前分支的上游分支,当前分支是基于哪个上游分支checkout出来的》
1.All changes made by commits in the current branch but that are not in <upstream> are saved to a temporary area. 在当前分支存在,而不在upstream分支的修改被保存
2.The current branch is reset to <upstream>, This has the exact same effect as git reset --hard <upstream>
3.The commits that were previously saved into the temporary area are then reapplied to the current branch, one by one, in order.
使用意图:当天分支"比较乱",不太好打理,不太好跟master主分支进行merge,所以需要对当前分支进行rebase,使得在当前分支上的所有修改能够线性的在主分支的下游,这样就能够比较容易的进行fast forward merge。
Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。
译注:将 HEAD 想象为当前分支的别名。
快进式合并和非快进式合并
http://blog.csdn.net/hutaoer06051/article/details/8673947
何为快进式合并??
如果当前的分支和另一个分支没有内容上的差异,就是说当前分支的每一个提交(commit)都已经存在另一个分支里了,git 就会执行一个“快速向前”(fast forward)操作;
git 不创建任何新的提交(commit),只是将当前分支指向合并进来的分支。
由于当前 master 分支所在的提交对象是要并入的 hotfix 分支的直接上游,Git 只需把 master 分支指针直接右移。换句话说,如果顺着一个分支走下去可以到达另一个分支的话,
那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。
有了 rebase 命令,就可以把在一个分支里提交的改变移到另一个分支里重放一遍。
可以用rebase命令把多个commit压缩成一个。
它的原理是回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支experiment)后续的历次提交对象,生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象为新的出发点,
逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象,从而改写 experiment 的提交历史,使它成为 master 分支的直接下游。rebase之后,回到主干分支进行merge。
git rebase -i HEAD~[number_of_commits] 直接按需增删改修改rebase返回的内容
git rebase -i --abort
git rebase [主分支] [特性分支] 进行重放
$ git checkout master
$ git merge server //fast forward //rebase后还要做这两步
merge 命令,会把两个分支最新的快照以及二者最新的共同祖先进行三方合并,合并的结果是产生一个新的提交对象.
rebase 命令,可以把在一个分支里提交的改变移到另一个分支里重放一遍。
般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁,实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。
$ git rebase --onto master server client
这好比在说:“取出 client 分支,找出 client 分支和 server 分支的共同祖先之后的变化,然后把它们在 master 上重演一遍”。
重放后进行fast forward
一般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁
===============================================
git help rebase
Assume the following history exists and the current branch is "topic": A---B---C topic / D---E---F---G master From this point, the result of either of the following commands: git rebase master //将当前分支topic上的修改合并到master上 git rebase master topic //将topic的修改合并到master上 would be: A´--B´--C´ topic / D---E---F---G master The latter form is just a short-hand of git checkout topic followed by git rebase master.
rebase后,topic的指针前移了,从而改写 topic的提交历史,使它成为 master 分支的直接下游
如果没有冲突,还需要继续进行一步git merge , 把master分支HEAD前移
git checkout master
git merge topic
===
git rebase <upstream> [<branch>]
把当前分支/branch分支的指针rebase移动到upstream的基础之上(方便代码进行fast forward合并),此时各自的指针依然保持不动,需要进行merge
===
视察一个衍合过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
一般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁 — 比如某些项目你不是维护者,但想帮点忙的话,最好用衍合:
先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次衍合操作然后再提交,这样维护者就不需要做任何整合工作(译注:实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。
简介
在Git中,用两种方法将两个不同的branch合并。一种是通过git merge,一种是通过git rebase。然而,大部分人都习惯于使用git merge,而忽略git rebase。本文将介绍git rebase的原理、使用方式及应用范围。
git merge 做些什么
当我们在开发一些新功能的时候,往往需要建立新的branch。(图片来源于git-scm.com)
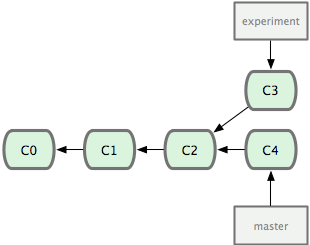
在上图中,每一个绿框均代表一个commit。除了c1,每一个commit都有一条有向边指向它在当前branch当中的上一个commit。
图中的项目,在c2之后就开了另外一个branch,名为experiment。在此之后,master下的修改被放到c4 commit中,experiment下的修改被放到c3 commit中。
如果我们使用merge合并两个分支【把experiment的修改合并到master上】
$ git checkout master
$ git merge experiment
得到的commit log如下图所示
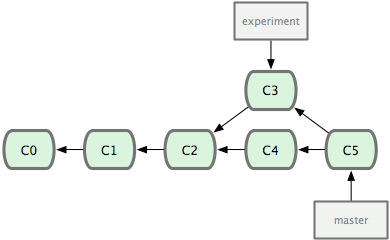
我们看到,merge所做的事情实际上是:
- 首先找到
master和experiment中最新的commit的最近公共祖先,在这里就是c4和c3的最近公共祖先c2。 - 将
experiment分支上在c2以后的所有commit合并成一个commit,并与master合并 - 如有合并冲突(两个分支修改了同一个文件),首先人工去除重复。
- 在master上产生合并后的新commit
git rebase做些什么
rebase所做的事情也是合并两个分支,但是它的方式略有不同。基于上例描述,rebase的工作流程是
- 首先找到
master和experiment中最新的commit的最近公共祖先,在这里就是c4和c3的最近公共祖先c2。 - 将
experiment分支上在c2以后的所有commit*全部移动到*master分支的最新commit之后,在这里就是把c3移动到c4以后。
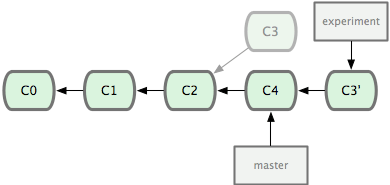
由于git的每一个commit都只存储相对上一个commit的变化(或者说是差值,delta)。我们通过移动c3到master,代表着在master上进行c3相应的修改。为了达成这一点,只需在experiment分支上rebase master
$ git checkout experiment 【分支切换到包含待合并内容的分支上】
$ git rebase master 【把expriment分支上的修改rebase到master上】
需要注意的是,rebase并不是直接将c3移动到master上,而是创建一个副本。我们可以通过实际操作发现这一点。在rebase前后,c3的hash code是不一样的。
rebase前的commit log是
* 1b4c6d6 (master) <- c4
| * 66c417b (experiment) <- c3
|/
* 972628d
rebase后的commit log是
* d9eeb1a - (experiment) <- c3'
* 1b4c6d6 - (master) <- c4
* 972628d
可以发现c3的hash code从66c417b变到了d9eeb1a。
在这之后,我们只需要在master上进行一次前向合并(fast-forward merge)
$ git checkout master
$ git merge experiment
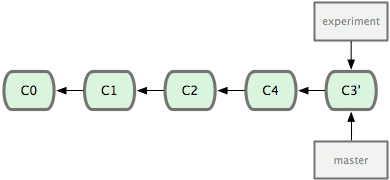
rebase之后的commit log呈线性,更加清晰。此时如果experiment分支不再被需要,我们可以删除它。
$ git branch -d experiment
何时使用
我们一般只在本地开发的时候rebase一个自己写出来的branch。
谨记,千万不要rebase一个已经发布到远程git服务器的分支【因为会修改commit id】。例如,你如果将分支experiment发布到了GitHub,那么你就不应该将它rebase到master上。因为如果你将它rebase到master上,将对其他人造成麻烦。
总结
git rebase帮助我们避免merge带来的复杂commit log,允许以线性commit的形式进行分支开发。
更多有关git rebase的更多用法,见这篇文章。
讨论
欢迎到我们的团队博客进行讨论,我在团队博客里面的讨论时间较多
=====================================================================
http://gitbook.liuhui998.com/4_2.html
假设你现在基于远程分支"origin",创建一个叫"mywork"的分支。
$ git checkout -b mywork origin
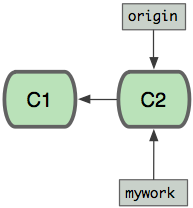
现在我们在这个分支做一些修改,然后生成两个提交(commit).
$ vi file.txt
$ git commit
$ vi otherfile.txt
$ git commit
...
但是与此同时,有些人也在"origin"分支上做了一些修改并且做了提交了. 这就意味着"origin"和"mywork"这两个分支各自"前进"了,它们之间"分叉"了。

在这里,你可以用"pull"命令把"origin"分支上的修改拉下来并且和你的修改合并; 结果看起来就像一个新的"合并的提交"(merge commit):

但是,如果你想让"mywork"分支历史看起来像没有经过任何合并一样,你也许可以用 git rebase:
$ git checkout mywork 【分支切换到包含待合并内容的分支上】$ git rebase origin 【把mywork分支上的修改rebase到origin上】这些命令会把你的"mywork"分支里的每个提交(commit)取消掉,并且把它们临时 保存为补丁(patch)(这些补丁放到".git/rebase"目录中),然后把"mywork"分支更新 到最新的"origin"分支,最后把保存的这些补丁应用到"mywork"分支上。

当'mywork'分支更新之后,它会指向这些新创建的提交(commit),而那些老的提交会被丢弃。 如果运行垃圾收集命令(pruning garbage collection), 这些被丢弃的提交就会删除. (请查看 git gc)

现在我们可以看一下用合并(merge)和用rebase所产生的历史的区别:

在rebase的过程中,也许会出现冲突(conflict).
When you have resolved this problem run "git rebase --continue".
在这种情况,Git会停止rebase并会生成一个临时的分支让你去解决 冲突;在解决完冲突后(git mergetool),用"git-add"命令去更新这些内容的索引(index), 然后,你无需执行 git-commit,只要执行:
$ git rebase --continue
或者如果--continue无效果,使用 $ git rebase --skip --continue之后,如果还有confict,继续git mergetool来合并冲突
这样git会继续应用(apply)余下的补丁。
在任何时候,你可以用--abort参数来终止rebase的行动,并且"mywork" 分支会回到rebase开始前的状态。
$ git rebase --abort
When you have resolved this problem run "git rebase --continue".
If you would prefer to skip this patch, instead run "git rebase --skip".
To restore the original branch and stop rebasing run "git rebase --abort".
===============
git rebase --onto master server client
取出/checkout到 client 分支,找出 client 分支和 server 分支的共同祖先之后的变化,然后把它们在 master 上重演一遍
git rebase [主分支] [特性分支] 命令会先取出特性分支 server,然后在主分支 master 上重演:
$ git rebase master server 衍合的风险
一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行衍合操作。
在进行衍合的时候,实际上抛弃了一些现存的提交对象而创造了一些类似但不同的新的提交对象。如果你把原来分支中的提交对象发布出去,并且其他人更新下载后在其基础上开展工作,而稍后你又用 git rebase 抛弃这些提交对象,把新的重演后的提交对象发布出去的话,你的合作者就不得不重新合并他们的工作,这样当你再次从他们那里获取内容时,提交历史就会变得一团糟。
如果把衍合当成一种在推送之前清理提交历史的手段,而且仅仅衍合那些尚未公开的提交对象,就没问题。如果衍合那些已经公开的提交对象,并且已经有人基于这些提交对象开展了后续开发工作的话,就会出现叫人沮丧的麻烦。
https://stackoverflow.com/questions/2452226/master-branch-and-origin-master-have-diverged-how-to-undiverge-branches
The git pull command provides a shorthand way to fetch from origin and rebase local work on it:
$ git pull --rebase

 浙公网安备 33010602011771号
浙公网安备 33010602011771号