




http://bbs.csdn.net/topics/350022037
http://blog.csdn.net/gaohuanjie/article/details/24666173
http://www.gregreda.com/2013/06/03/join-vs-exists-vs-in/
https://www.zhihu.com/question/20699147
- select * from a where id in (select id from b );
对于这条sql语句它的执行计划其实并不是先查询出b表的所有id,然后再与a表的id进行比较。
mysql会把in子查询转换成exists相关子查询,所以它实际等同于这条sql语句:select * from a where exists(select * from b where b.id=a.id );
而exists相关子查询的执行原理是: 循环取出a表的每一条记录与b表进行比较,比较的条件是a.id=b.id . 看a表的每条记录的id是否在b表存在,如果存在就行返回a表的这条记录。
exists查询有什么弊端?
由exists执行原理可知,a表(外表)使用不了索引,必须全表扫描,因为是拿a表的数据到b表查。而且必须得使用a表的数据到b表中查(外表到里表中),顺序是固定死的。
如何优化?
建索引。但是由上面分析可知,要建索引只能在b表的id字段建,不能在a表的id上,mysql利用不上。
这样优化够了吗?还差一些。
由于exists查询它的执行计划只能拿着a表的数据到b表查(外表到里表中),虽然可以在b表的id字段建索引来提高查询效率。
但是并不能反过来拿着b表的数据到a表查,exists子查询的查询顺序是固定死的。
为什么要反过来?
因为首先可以肯定的是反过来的结果也是一样的。这样就又引出了一个更细致的疑问:在双方两个表的id字段上都建有索引时,到底是a表查b表的效率高,还是b表查a表的效率高?
该如何进一步优化?
把查询修改成inner join连接查询:select * from a inner join b on a.id=b.id; (但是仅此还不够,接着往下看)
为什么不用left join 和 right join?
这时候表之间的连接的顺序就被固定住了,比如左连接就是必须先查左表全表扫描,然后一条一条的到另外表去查询,右连接同理。仍然不是最好的选择。
为什么使用inner join就可以?
inner join中的两张表,如: a inner join b,但实际执行的顺序是跟写法的顺序没有半毛钱关系的,最终执行也可能会是b连接a,顺序不是固定死的。如果on条件字段有索引的情况下,同样可以使用上索引。
那我们又怎么能知道a和b什么样的执行顺序效率更高?
答:你不知道,我也不知道。谁知道?mysql自己知道。让mysql自己去判断(查询优化器)。具体表的连接顺序和使用索引情况,mysql查询优化器会对每种情况做出成本评估,最终选择最优的那个做为执行计划。
在inner join的连接中,mysql会自己评估使用a表查b表的效率高还是b表查a表高,如果两个表都建有索引的情况下,mysql同样会评估使用a表条件字段上的索引效率高还是b表的。
而我们要做的就是:把两个表的连接条件的两个字段都各自建立上索引,然后explain 一下,查看执行计划,看mysql到底利用了哪个索引,最后再把没有使用索引的表的字段索引给去掉就行了。
实测下来,in 改成inner join的explain语句没啥区别
SELECT ref.`id` AS ref_id, ref.`…` AS …, … app.`id` AS app_id, … FROM `reference` AS ref LEFT JOIN `applicants` AS app ON app.`id` = ref.`applicant_id` LEFT JOIN `g_people` AS ape ON ape.`id` = app.`person_id` LEFT JOIN `g_addresses` AS apa ON apa.`id` = app.`address_id` LEFT JOIN `properties` AS pro ON pro.`id` = ref.`property_id` LEFT JOIN `g_addresses` AS pra ON pra.`id` = pro.`address_id` WHERE ref.`id` = 4 and app.xx = xx and ape.xx = xxx
========================
EXISTS、IN与JOIN,都可以用来实现形如“查询A表中在(或不在)B表中的记录”的查询逻辑。
在论坛上看到很多人对此有所误解(如关于in的疑惑、用 外连接 和 Is Null 代替 not in两帖),特做一简单测试。
测试结果: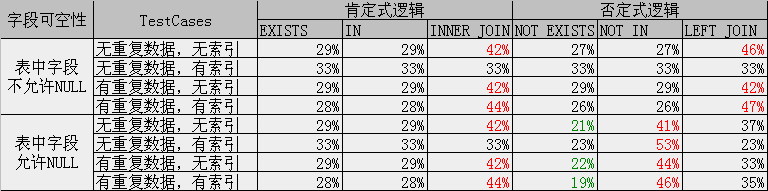
测试代码较长,附于本帖最后。
图表中百分数表示同一组3个查询的执行时间比例。红色表示3个语句中最慢,绿色表示3个语句中最快的,并列则没加颜色。
其中索引只测试了聚集索引,当表中字段较多且查询字段是非聚集索引时,选择执行计划的条件比较复杂,没有测试。并且当表中数量变化后,执行计划可能也有差异。图表反映了3种查询方式的解析机制的不同,基本结论是类似的,但具体情况还要视执行计划而定。
分析结论:
通常情况下,3种查询方式的执行时间:
EXISTS <= IN <= JOIN
NOT EXISTS <= NOT IN <= LEFT JOIN
只有当表中字段允许NULL时,NOT IN的方式最慢:
NOT EXISTS <= LEFT JOIN <= NOT IN
综上:
IN的好处是逻辑直观简单(通常是独立子查询);缺点是只能判断单字段,并且当NOT IN时效率较低,而且NULL会导致不想要的结果。
EXISTS的好处是效率高,可以判断单字段和组合字段,并不受NULL的影响;缺点是逻辑稍微复杂(通常是相关子查询)。
JOIN用在这种场合,往往是吃力不讨好。JOIN的用途是联接两个表,而不是判断一个表的记录是否在另一个表。
编程建议:
(以下三条建议中EXISTS和IN同时代指肯定式逻辑和加NOT后的否定式逻辑)
如果查询条件是单字段主键(有索引且不允许NULL),则EXISTS和IN的性能基本一样,IN的查询通常写法简单、逻辑直观。
如果查询条件涉及多个字段,则最好选择EXISTS,千万不要用字段拼接再IN的方式(索引会失效)。
如果条件不确定,选用EXISTS是最保险的办法,性能最好,不受三值逻辑影响(EXISTS只会返回True/False不会返回Unknown),但代码逻辑稍稍复杂,思路要理清楚,而且相关字段最好采用“表(别)名.字段名”的形式。
附一:IN/NOT IN容易出现的两个问题
参看如下代码:
SELECT
EmployeeID = n,
EmployeeName = 'E' + RIGHT('000' + CAST(n AS varchar(10)),3)
INTO #Employees
FROM dbo.Nums WHERE n <= 10;
SELECT EmployeeID
INTO #Badboys
FROM (SELECT TOP(4) EmployeeID = n FROM dbo.Nums WHERE n <= 10 ORDER BY NEWID()) tmp
UNION
SELECT NULL;
--问题1:
SELECT * FROM #Employees WHERE EmployeeID IN (SELECT EmployeeID FROM #Badboys);
SELECT * FROM #Employees WHERE EmployeeID NOT IN (SELECT EmployeeID FROM #Badboys);
--问题2:
SELECT * FROM #Employees WHERE EmployeeName IN (SELECT EmployeeName FROM #Badboys);
SELECT * FROM #Employees WHERE EmployeeName NOT IN (SELECT EmployeeName FROM #Badboys);
其中:
问题1是三值逻辑的问题,说明了在NOT IN遇到NULL时要特别小心(参看关于 not in的疑问一帖)。这也是为什么建议“如果可能,尽量让所有字段都声明为NOT NULL”的原因之一。
问题2是SQL Server子查询处理时命名空间解析的漏洞,说明了在多表查询中采用“表(别)名.字段名”的形式的好处,否则就要对字段名的拼写非常小心。
附二:EXISTS、IN与JOIN性能分析测试代码:
--表中字段不允许NULL --TestCase1: 无重复数据,无索引 CREATE TABLE T1(n int NOT NULL); CREATE TABLE T2(n int NOT NULL); INSERT INTO T1 SELECT n FROM dbo.Nums WHERE n <= 100; INSERT INTO T2 SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0; --TestCase2: 无重复数据,有索引 CREATE UNIQUE CLUSTERED INDEX IX_T1 ON T1(n); CREATE UNIQUE CLUSTERED INDEX IX_T2 ON T2(n); --TestCase3: 有重复数据,无索引 DROP TABLE T1; DROP TABLE T2; CREATE TABLE T1(n int NOT NULL); CREATE TABLE T2(n int NOT NULL); INSERT INTO T1 SELECT n FROM dbo.Nums WHERE n <= 100; INSERT INTO T2 SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0 UNION ALL SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 3 = 0; --TestCase4: 有重复数据,有索引 CREATE CLUSTERED INDEX IX_T1 ON T1(n); CREATE CLUSTERED INDEX IX_T2 ON T2(n); --表中字段允许NULL --TestCase5: 无重复数据,无索引 DROP TABLE T1; DROP TABLE T2; CREATE TABLE T1(n int NULL); CREATE TABLE T2(n int NULL); INSERT INTO T1 SELECT n FROM dbo.Nums WHERE n <= 100; INSERT INTO T2 SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0; --TestCase6: 无重复数据,有索引 CREATE UNIQUE CLUSTERED INDEX IX_T1 ON T1(n); CREATE UNIQUE CLUSTERED INDEX IX_T2 ON T2(n); --TestCase7: 有重复数据,无索引 DROP TABLE T1; DROP TABLE T2; CREATE TABLE T1(n int NULL); CREATE TABLE T2(n int NULL); INSERT INTO T1 SELECT n FROM dbo.Nums WHERE n <= 100; INSERT INTO T2 SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0 UNION ALL SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 3 = 0; --TestCase8: 有重复数据,有索引 CREATE CLUSTERED INDEX IX_T1 ON T1(n); CREATE CLUSTERED INDEX IX_T2 ON T2(n); --Foreach TestCase above,分别执行以下两组语句并观察执行计划: --肯定式逻辑 SELECT T1.* FROM T1 WHERE EXISTS (SELECT * FROM T2 WHERE T2.n = T1.n); SELECT T1.* FROM T1 WHERE T1.n IN (SELECT T2.n FROM T2); SELECT DISTINCT T1.* --不加DISTINCT可能会引起重复 FROM T1 INNER JOIN T2 ON T1.n = T2.n; --否定式逻辑 SELECT T1.* FROM T1 WHERE NOT EXISTS (SELECT * FROM T2 WHERE T2.n = T1.n); SELECT T1.* FROM T1 WHERE T1.n NOT IN (SELECT T2.n FROM T2); SELECT T1.* FROM T1 LEFT JOIN T2 ON T1.n = T2.n WHERE T2.n IS NULL; --End Foreach --清场 DROP TABLE T1; DROP TABLE T2;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号