
CPU 使用率 = (结束时CPU使用时间 - 开始时CPU使用时间) / (结束时间 - 开始时间)
- cpu usage=1 - (idle2-idle1)/(cpu2-cpu1)*100
- cpu usage=[(user2 +sys2+nice2) - (user1 + sys1+nice1)]/(total2 - total1)*100 #这个好理解一点
这三种方式都行,docker下使用第一种方式,读cpuacct.usage

CPU使用时间就是上一节文中提到的cgroup文件下的cpuacct.usage文件里的时间。
https://zhuanlan.zhihu.com/p/35914450
要明白为何 top,free 显示的是宿主机的情况,以及如何获得容器的资源限制需要先理解 Docker 的两项基础技术:Namespace 和 cgroup。两者在 CoolShell 的博客里都已经讲解得非常清楚,这里只简单说明一下。Namespace 解决了环境隔离的问题,它将进程的PID,Network,IPC等和其它进程隔离开来,结合 chroot,让进程仿佛运行在一个独占的操作系统中。cgroup 则对进程能够使用的资源作限制,如在一台48核256G的机器上只让容器使用2核2G。
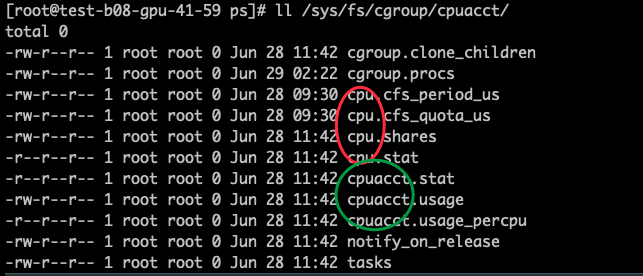
容器中CPU,内存,磁盘资源都是被 cgroup 限制和统计的,所有信息都放在 /sys/fs/cgroup 这个虚拟文件夹里,在容器里运行 mount 命令可以看到这些挂载记录
...
cgroup on /sys/fs/cgroup/cpuset type cgroup (ro,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu type cgroup (ro,nosuid,nodev,noexec,relatime,cpu)
cgroup on /sys/fs/cgroup/cpuacct type cgroup (ro,nosuid,nodev,noexec,relatime,cpuacct)
cgroup on /sys/fs/cgroup/memory type cgroup (ro,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/devices type cgroup (ro,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (ro,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (ro,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (ro,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (ro,nosuid,nodev,noexec,relatime,hugetlb)
...CPU
获取CPU信息需要用到 cpuset, cpu, cpuacct
- cpuset 提供一个机制指定 cgroup 可以使用哪些CPU核哪些内存节点(an on-line node that contains memory)
- cpu 设置CPU的使用配额/份额
- cpuacct 提供 cgroup CPU 使用时长的统计信息
把上面三个文件夹的文件都看了一遍后,会发现 cgroup 里的提供的信息比物理机上的资源使用状况信息少很多,这其实是非常合理的,因为两者本质上就是不同的东西。比如物理机只有10%的时间在运行任务,那剩下90%时间物理机是真正称得上空闲,而 cgroup 限制组内进程最多只能用50%的CPU,而组内进程只用了10%的CPU,但不能说还有40%或者80%是空闲的,在 cgroup 内根本没有空闲这个概念,因此也就没法从中得到常见的 idle 指标。
另外,cgroup 内没有统计 iowait,中断,这些也没法拿到。不过没关系,细化的指标可以在进程里找,系统信息足够反映负载状况即可。这里介绍一下我比较关心的3个指标的获取方式。
LimitedCores: cgroup 限制可以使用的 CPU 核数
cgroup 有三种方式限制 CPU 的使用
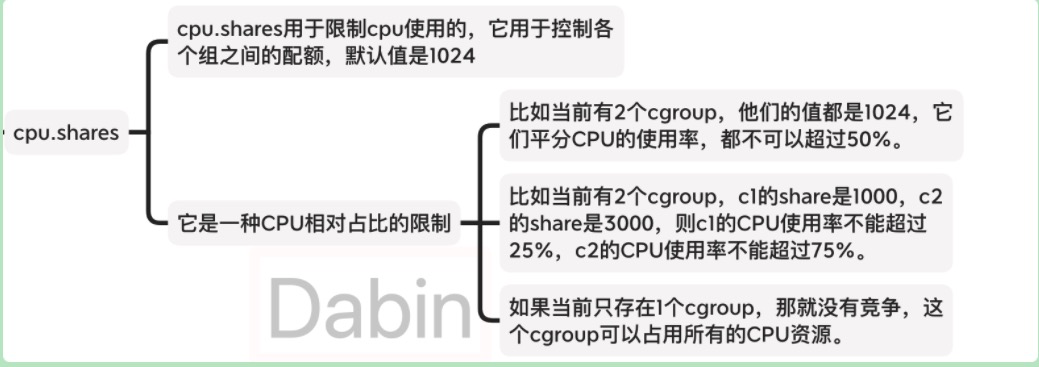
- share,对应文件
cpu/cpu.shares,是系统内多个 cgroup 的进程同时运行时他们的CPU使用上限占比,比如只有两个cgroup: [cgroup1.shares: 1024, cgroup2.shares: 512],那 cgroup1 可以用 2/3 的 CPU。 - quota,对应文件
cpu/cpu.cfs_quota_uscpu,表示在每个 period(时间间隔)内 cgroup 可以使用的 CPU 时间,文件里数字的单位是微秒。
假设 {cpu.cfs_quota_us: 200000, cpu.cfs_period_us: 100000},意思是每 100ms 可以使用 200ms CPU 时间,相当于可以使用两个核。quota 为 -1 的时候表示无限制。
period表示 CPU 的周期数,默认是 100000,单位是微秒,也就是 1s,一般不需要修改;
quota表示容器的在上述 CPU 周期里能使用的 quota,真正能使用的 CPU 核数就是 cpu-quota / cpu-period,因此对于 3 核的容器,对应的 cpu-quota 值为 300000。
- cpuset,对应文件
cpuset/cpuset.cpus, 表示 cgroup 可以用那几个 CPU,比如0,3-7,12可以使用 7 个核。
对于 share,我们没法知道有多少邻居以及邻居的值为多少,所以忽略这个限制。考虑到 cpuset 在生产环境极少使用,同时用 quota 和 cpuset 的就更少了,所以我们的策略是:先看 quota,如果 quota 有限制则返回,否则再看 cpuset。
Usage:cgroup 的 CPU 占用率,占了物理机的多少CPU 【不是docker中自身cpu的使用率:占被分配的cpu的比例】
上面我们拿到了能用多少个核,自然知道 cgroup 的占用上限,只要知道 cgroup 用了物理机的多少 CPU 就可以知道饱和程度了。要获取这个首先需要知道一段时间内物理机用了多少CPU时间,然后获得 cgroup 用了多少CPU时间,最后相除。
- 物理机使用的CPU时间从 /proc/stat 里获取,将里面 cpu 那一行的数字相加并且乘以物理机CPU核数即可得到从开机到现在用的CPU总时间。可以设置一秒的时间间隔,求差即可得到这一秒内用的CPU时间。
- cgroup 使用的CPU时间可以从
cpuacct/cpuacct.usage中获得,也是求一段时间的差即可。
特别需要注意的是 /proc/stat 里单位是纳秒,而 cpuacct.usage 里的是 Clock Tick,一般是 100纳秒/tick,准确数字可以通过 getconf CLK_TCK 命令获得。
getconf CLK_TCK:代表1s内tick的数量,100即代表**1秒内包含有100个tick** ,而cpuacct/cpuacct.usage中得到的数据单位为ns,而/proc/stat中得到的数据以tick为单位,因此转换不是乘100而是乘`10^9/CLK_TCK`
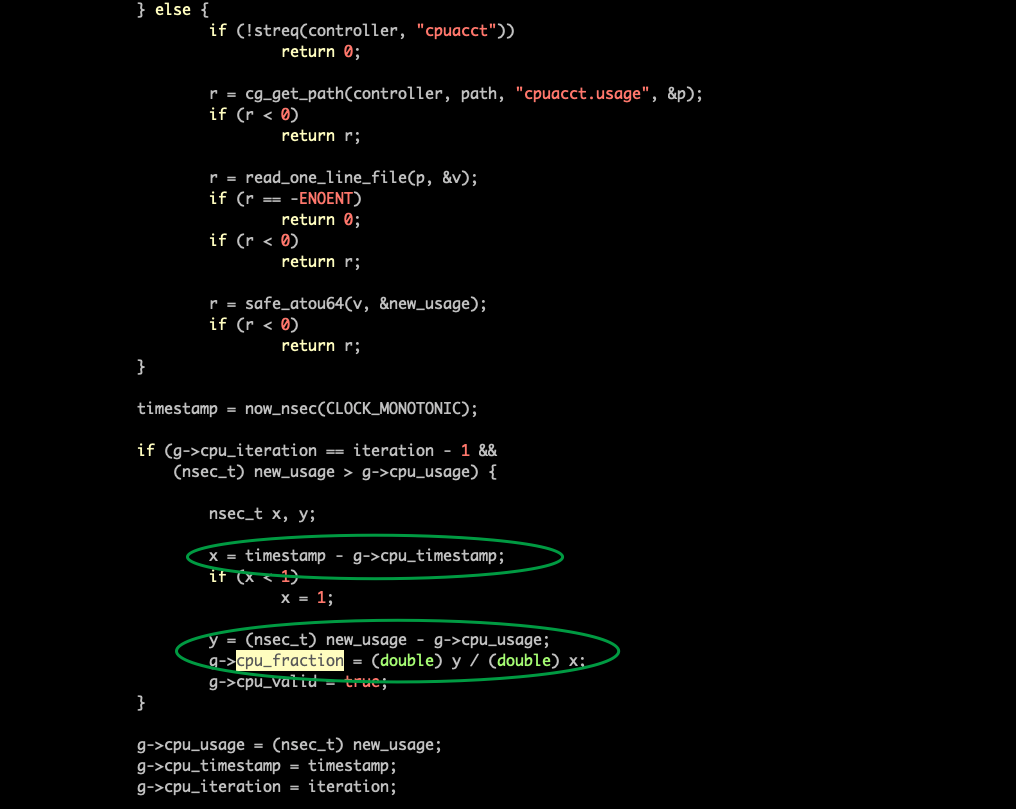
MONOTONIC: 单调的,递增的
cpuacct.usage是MONOTONIC time。
https://www.cnblogs.com/my_life/articles/5340108.html
https://github.com/systemd/systemd/blob/main/src/cgtop/cgtop.c
timestamp = now_nsec(CLOCK_MONOTONIC);
docker自身的cpu使用率的计算:
tstart=$(date +%s%N)#获取到当前的时间(纳秒) cstart=$(cat /sys/fs/cgroup/cpu/mygroup/cpuacct.usage)#当前时刻mygroup这个cgroup已使用的cpu纳秒数 sleep 5 tstop=$(date +%s%N)#获取当前的时间(纳秒) cstop=$(cat /sys/fs/cgroup/cpu/mygroup/cpuacct.usage)#当前时刻mygroup这个cgroup已使用的cpu纳秒数 bc -l <<EOF ($cstop - $cstart) / ($tstop - $tstart) * 100 #cpu占用的毫秒数/总的时间数即为cpu利用率
CPU 使用率 = (结束时CPU使用时间 - 开始时CPU使用时间) / (结束时总CPU间 - 开始时总CPU时间)
Throttled:cgroup 的 CPU 使用被限制的次数
如果被频繁限制的话,说明很可能分配的CPU不够用了。可以从 cpu/cpu.stat 的字段获得。
内存
cgroup 对内存的使用做了比较多的统计,但是内存使用率本身就是一个糊涂账,因为很多内存是为了提高性能从磁盘映射过来的需要时可以清理掉。cgroup 里的内存信息和定义推荐看 Kernal Doc cgroup-v1 memory
需要额外提一下的是 cache 和 mapped_file,cache 是 page cache memory 也成为 disk cache 是磁盘映射到内存的内存,而 mapped_file 也是一样意思,但实际中常常会发现 cache 比 mapped_file 大很多,这其实是 mapped_file 是还被进程引用着的,而 cache 则包括曾经被进程用过但现在已经没有任何进程使用的映射,也就是 unmapped_file。
对于内存,可以重点关注以下几个指标(没有特别注明,所有指标都从 memory/memory.stat 中取:
- Total: cgroup 被限制可以使用多少内存,可以从文件里的 hierarchical_memory_limit 获得,但不是所有 cgroup 都限制内存,没有限制的话会获得 2^64-1 这样的值,我们还需要从
/proc/meminfo中获得MemTotal,取两者最小。 - RSS: Resident Set Size 实际物理内存使用量,在
memory/memory.stat的 rss 只是 anonymous and swap cache memory,文档里也说了如果要获得真正的 RSS 还需要加上 mapped_file。 - Cached:
memory/memory.stat中的 cache - MappedFile:
memory/memory.stat中的 mapped_file - SwapTotal: 限制的 swap 大小,(hierarchical_memsw_limit - hierarchical_memory_limit) 同样会遇到内存没有限制的情况。
- SwapUsed:
memory/memory.stat中的 total_swap
不管docker还是k8s(通过cadvisor)最终都通过cgroup的memory group来得到内存的原始文件,memory相关的主要文件如下:
1
|
cgroup.event_control #用于eventfd的接口
|
cpu的使用率
https://biang.io/blog/development/tools/os/linux/other/based-on-the-linuxprocstat-cpu-usage
https://github.com/influxdata/telegraf/blob/master/plugins/inputs/docker/stats_helpers.go
1、/proc/stat文件的介绍
在Linux下,CPU利用率分为用户态,系统态和空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间,三者之和就是CPU的总时间,当没有用户进程、系统进程等需要执行的时候,CPU就执行系统缺省的空闲进程。从平常的思维方式理解的话,CPU的利用率就是非空闲进程占用时间的比例,即CPU执行非空闲进程的时间 / CPU总的执行时间。
在Linux系统中,CPU时间的分配信息保存在/proc/stat文件中,利用率的计算应该从这个文件中获取数据。文件的头几行记录了每个CPU的用户态,系统态,空闲态等状态下分配的时间片(单位是Jiffies),这些数据是从CPU加电到当前的累计值。常用的监控软件就是利用/proc /stat里面的这些数据来计算CPU的利用率的。
不同版本的linux /proc/stat文件内容不一样,以Linux 2.6来说,/proc/stat文件的内容如下:
cpu 2032004 102648 238344 167130733 758440 15159 17878 0
cpu0 1022597 63462 141826 83528451 366530 9362 15386 0
cpu1 1009407 39185 96518 83602282 391909 5796 2492 0
intr 303194010 212852371 3 0 0 11 0 0 2 1 1 0 0 3 0 11097365 0 72615114
6628960 0 179 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
ctxt 236095529
btime 1195210746
processes 401389
procs_running 1
procs_blocked 0第一行的数值表示的是CPU总的使用情况,所以我们只要用第一行的数字计算就可以了。下表解析第一行各数值的含义:
参数
解析(单位:jiffies)
user (2032004)
从系统启动开始累计到当前时刻,用户态的CPU时间,不包含 nice值为负进程。
nice (102648)
从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间 #负值代表高优先级,即高优先级进程的cpu时间
system (238344)
从系统启动开始累计到当前时刻,核心时间
idle (167130733)
从系统启动开始累计到当前时刻,除IO等待时间以外其它等待时间
iowait (758440)
从系统启动开始累计到当前时刻,IO等待时间
irq (15159)
从系统启动开始累计到当前时刻,硬中断时间
softirq (17878)
从系统启动开始累计到当前时刻,软中断时间
“intr”这行给出中断的信息,第一个为自系统启动以来,发生的所有的中断的次数;然后每个数对应一个特定的中断自系统启动以来所发生的次数。
“ctxt”给出了自系统启动以来CPU发生的上下文交换的次数。
“btime”给出了从系统启动到现在为止的时间,单位为秒。
“processes (total_forks) 自系统启动以来所创建的任务的个数目。
“procs_running”:当前运行队列的任务的数目。
“procs_blocked”:当前被阻塞的任务的数目。
思路一
CPU时间=user+system+nice+idle+iowait+irq+softirq
那么CPU利用率可以使用以下两个方法。先取两个采样点,然后计算其差值:
- cpu usage=1 - (idle2-idle1)/(cpu2-cpu1)*100
因为/proc/stat中的数值都是从系统启动开始累计到当前时刻的积累值,所以需要在不同时间点t1和t2取值进行比较运算,当两个时间点的间隔较短时,就可以把这个计算结果看作是CPU的即时利用率。
CPU的即时利用率的计算公式:
CPU在t1到t2时间段总的使用时间 = ( user2+ nice2+ system2+ idle2+ iowait2+ irq2+ softirq2) - ( user1+ nice1+ system1+ idle1+ iowait1+ irq1+ softirq1)
CPU在t1到t2时间段空闲使用时间 = (idle2 - idle1)
CPU在t1到t2时间段即时利用率 = 1 - CPU空闲使用时间 / CPU总的使用时间
思路二
- cpu usage=[(user2 +sys2+nice2) - (user1 + sys1+nice1)]/(total2 - total1)*100 #这个好理解一点
2、shell代码示例
#!/bin/bash
#cpu使用率
interval=3
cpu_num=`cat /proc/stat | grep cpu[0-9] -c`
start_idle=()
start_total=()
cpu_rate=()
cpu_rate_file=./`hostname`_cpu_rate.csv
if [ -f ${cpu_rate_file} ]; then
mv ${cpu_rate_file} ${cpu_rate_file}.`date +%m_%d-%H_%M_%S`.bak
fi
for((i=0;i<${cpu_num};i++))
{
echo -n "cpu$i," >> ${cpu_rate_file}
}
echo -n "cpu" >> ${cpu_rate_file}
echo "" >> ${cpu_rate_file}
while(true)
do
for((i=0;i<${cpu_num};i++))
{
start=$(cat /proc/stat | grep "cpu$i" | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
start_idle[$i]=$(echo ${start} | awk '{print $4}')
start_total[$i]=$(echo ${start} | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
}
start=$(cat /proc/stat | grep "cpu " | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
start_idle[${cpu_num}]=$(echo ${start} | awk '{print $4}')
start_total[${cpu_num}]=$(echo ${start} | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
sleep ${interval}
for((i=0;i<${cpu_num};i++))
{
end=$(cat /proc/stat | grep "cpu$i" | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
end_idle=$(echo ${end} | awk '{print $4}')
end_total=$(echo ${end} | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
idle=`expr ${end_idle} - ${start_idle[$i]}`
total=`expr ${end_total} - ${start_total[$i]}`
idle_normal=`expr ${idle} \* 100`
cpu_usage=`expr ${idle_normal} / ${total}`
cpu_rate[$i]=`expr 100 - ${cpu_usage}`
echo "The CPU$i Rate : ${cpu_rate[$i]}%"
echo -n "${cpu_rate[$i]}," >> ${cpu_rate_file}
}
end=$(cat /proc/stat | grep "cpu " | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
end_idle=$(echo ${end} | awk '{print $4}')
end_total=$(echo ${end} | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
idle=`expr ${end_idle} - ${start_idle[$i]}`
total=`expr ${end_total} - ${start_total[$i]}`
idle_normal=`expr ${idle} \* 100`
cpu_usage=`expr ${idle_normal} / ${total}`
cpu_rate[${cpu_num}]=`expr 100 - ${cpu_usage}`
echo "The average CPU Rate : ${cpu_rate[${cpu_num}]}%"
echo -n "${cpu_rate[${cpu_num}]}" >> ${cpu_rate_file}
echo "------------------"
echo "" >> ${cpu_rate_file}
done
https://github.com/influxdata/telegraf/blob/master/plugins/inputs/docker/stats_helpers.go
https://lessisbetter.site/2020/09/01/cgroup-3-cpu-md/
测试环境
Ubuntu 18.04,内核版本4.15,机器拥有4核。
1
|
[~]$ cat /proc/version
|
CPU相关子系统简介

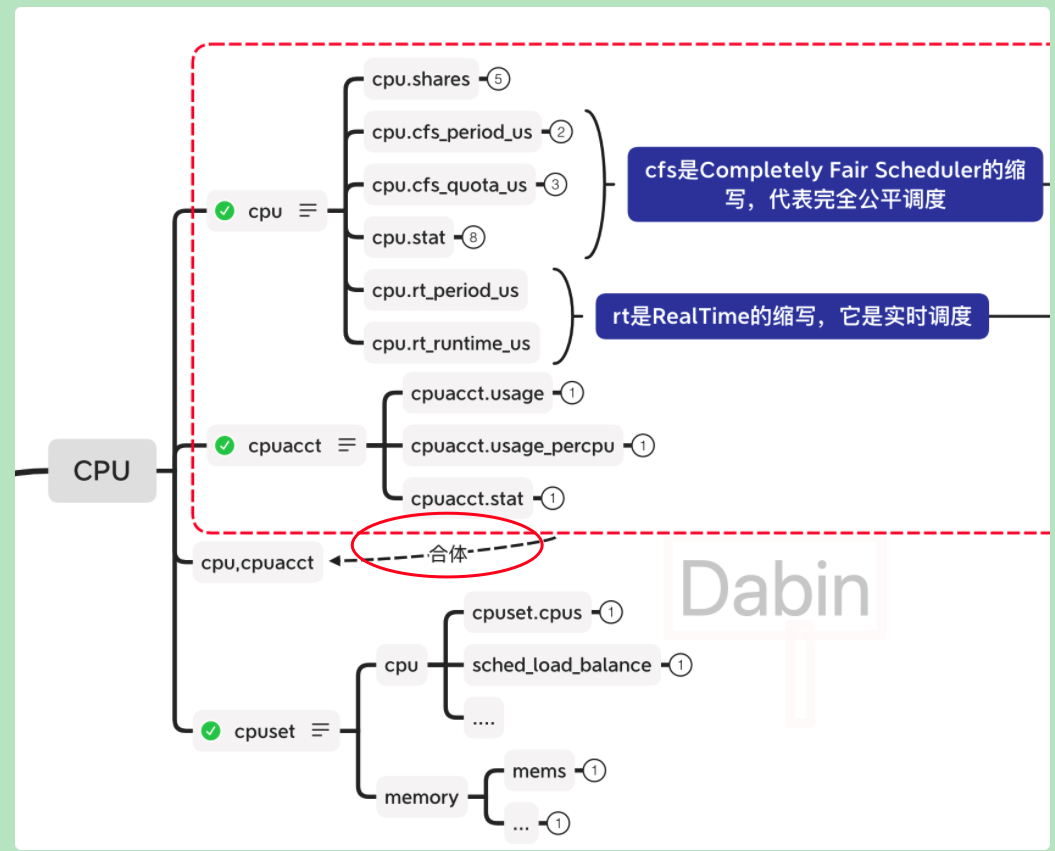
不同的文件前缀属于不同的配置:

有关CPU的cgroup subsystem有3个:
- cpu : 用来限制cgroup的CPU使用率
- cpuacct : 用来统计cgroup的CPU的使用率
- cpuset : 用来绑定cgroup到指定CPU的哪个核上和NUMA节点
每个子系统都有多个配置项和指标文件,主要介绍下图常用的配置项:
cpu
cpu子系统用来限制cgroup如何使用CPU的时间,也就是调度,它提供了3种调度办法,并且这3种调度办法都可以在启动容器时进行配置,分别是:
- share :相对权重的CPU调度
- cfs :完全公平调度
- rt :实时调度
share调度的配置项和原理如下:
cfs 是Completely Fair Scheduler的缩写,代表完全公平调度,它利用 cpu.cfs_quota_us 和 cpu.cfs_period_us 实现公平调度,这两个文件内容组合使用可以限制进程在长度为 cfs_period_us 的时间内,只能被分配到总量为 cfs_quota_us 的 CPU 时间。CFS的指标如下:
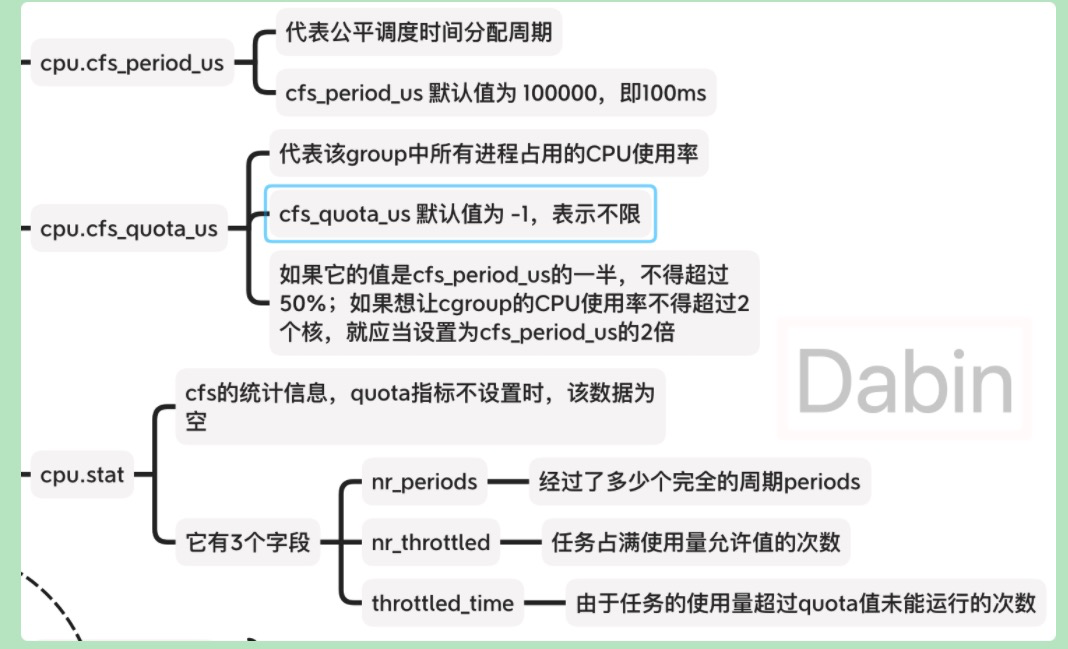
注意:
cfs_period_us取值范围1000~1000000:1ms ~ 1s,cfs_quota_us的最小值为1000,当设置的值不在取值范围时,会报write xxx: invalid argument的错误。- 只有这2个参数都有意义时,才能把任务写入到 tasks 文件。
rt 是RealTime的缩写,它是实时调度,它与cfs调度的区别是cfs不会保证进程的CPU使用率一定要达到设置的比率,而rt会严格保证,让进程的占用率达到这个比率,适合实时性较强的任务,它包含 cpu.rt_period_us 和 cpu.rt_runtime_us 2个配置项。
-
cpuacct
cpuacct包含非常多的统计指标,常用的有以下4个文件:

https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html/resource_management_guide/sec-cpuacct
cpuacct)子系统会自动生成报告来显示 cgroup 任务所使用的 CPU 资源,其中包括子群组任务。报告有三种:- cpuacct.usage
- 报告此 cgroup 中所有任务(包括层级中的低端任务)使用 CPU 的总时间(纳秒)。
- cpuacct.stat
-
user— 用户模式中任务使用的 CPU 时间。 -
system— 系统(kernel)模式中任务使用的 CPU 时间。
USER_HZ 变量定义的单位中。cpuacct.usage_percpu
-
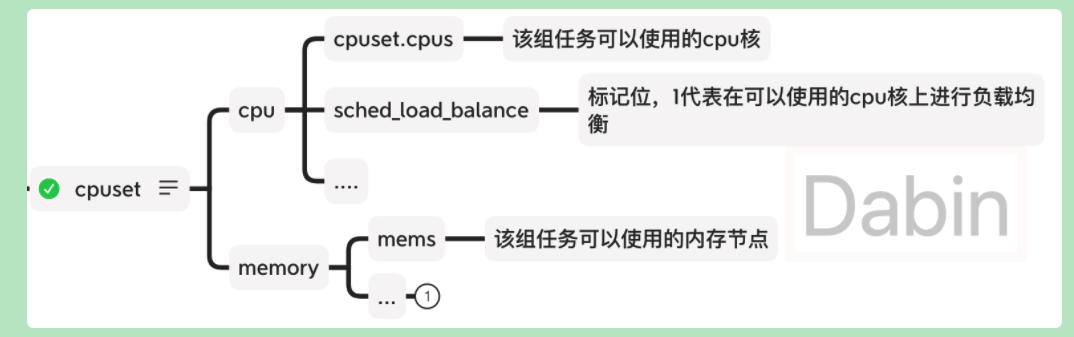
cpuset
为啥需要cpuset?
比如:
- 多核可以提高并发、并行,但是核太多了,会影响进程执行的局部性,降低效率。
- 一个服务器上部署多种应用,不同的应用不同的核。
cpuset也包含居多的配置项,主要是分为cpu和mem 2类,mem与NUMA有关,其常用的配置项如下图:
利用Docker演示Cgroup CPU限制
cpu
不限制cpu的情况
stress为基于ubuntu:16.04安装stress做出来的镜像,利用stress来测试cpu限制。
Dockerfile如下:
1
|
From ubuntu:16.04
|
启动容器不做任何cpu限制,利用 stress -c 2 开启另外2个stress线程,共3个:
1
|
[/sys/fs/cgroup/cpu]$ docker run --rm -it stress:16.04
|
在cgroup/cpu,cpuacct下,找到该容器对应的目录,查看 cfs_period_us 和 cfs_quota_us 的默认值:
1
|
[/sys/fs/cgroup/cpu,cpuacct/system.slice/docker-5fad38726740b90b93c06972fe4a9f11391a38aaeb3e922f10c3269fa32e1873.scope]$ cat cpu.cfs_period_us
|
查看主机CPU利用率,为3个stress进程,每1个都100%,它们属于同一个cgroup:
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
限制cpu的情况
--cpu-quota设置5000,开stress分配到另外2个核。
[/sys/fs/cgroup/cpu]$ docker run –rm -it –cpu-quota=5000 stress:16.04
root@7e79005d7ca1:/#
root@7e79005d7ca1:/# stress -c 2
stress: info: [13] dispatching hogs: 2 cpu, 0 io, 1 vm, 0 hdd
查看 cfs_period_us 和 cfs_quota_us 的设置,5000/100000 = 5% , 即限制该容器的CPU使用率不得超过5%。
1
|
[/sys/fs/cgroup/cpu,cpuacct/system.slice/docker-7e79005d7ca1b338d870d3dc79af3f1cd38ace195ebd685a09575f6acee36a07.scope]$ cat cpu.cfs_quota_us
|
利用top可以看到3个进程总cpu使用率5.1%。
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
cpuacct
查看cpuacct.stat, cpuacct.usage, cpuacct.usage_percpu,一定要同时输出这几个文件,不然可能有时间差,利用python可以计算每个核上的时间之和为usage,即该容器占用的cpu总时间。
1
|
[/sys/fs/cgroup/cpu,cpuacct]$ cat cpuacct.*
|
cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu | awk '{for(i=1;i<=NF;i++){a[NR]+=$i}print a[NR]}'
146324154591
cat /sys/fs/cgroup/cpuacct/cpuacct.usage
146328577253
-
cpuset
启动容器,然后使用stress占用1个核:
1
|
[/sys/fs/cgroup/cpu]$ docker run --rm -it stress:16.04
|
top显示占用100%CPU。
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
cpuset 能看到可使用的核为: 0~3。
1
|
[/sys/fs/cgroup/cpuset/docker/a907df624697a19631929c1e9e971d2893afddbf6befb0dd44be3cf0024a3e0d]$ cat cpuset.cpus
|
使用cpuacct查看CPU情况使用统计,可以看到用了4个核上的使用时间。
1
|
[/sys/fs/cgroup/cpu/docker/a907df624697a19631929c1e9e971d2893afddbf6befb0dd44be3cf0024a3e0d]$ cat cpuacct.usage cpuacct.usage_all
|
现在创建一个新容器,限制只能用1,3这2个核:
1
|
[/sys/fs/cgroup/cpu]$ docker run --rm -it --cpuset-cpus 1,3 stress:16.04
|
查看可以使用的核:
1
|
[/sys/fs/cgroup/cpuset/docker/0ce61a38e7c9621334871ab40d5b7d287d89a1e994148833ddf3ca4941a39c89]$ cat cpuset.cpus
|
cpuacct.usage_all 显示只有1、3两个核的数据在使用:
1
|
[/sys/fs/cgroup/cpu/docker/0ce61a38e7c9621334871ab40d5b7d287d89a1e994148833ddf3ca4941a39c89]$ cat cpuacct.usage_all
|
现在切换到root账号,把 sched_load_balance 标记设置为0,不进行核间的负载均衡,然后利用 cpuacct.usage_all 查看每个核上的时间,隔几秒前后查询2次,可以发现3号核的cpu使用时间停留在21332956940,而核1的cpu使用时间从185084024837 增加到 221479683602, 说明设置之后stress线程一致在核1上运行,不再进行负载均衡。
1
|
[/sys/fs/cgroup/cpuset/docker/0ce61a38e7c9621334871ab40d5b7d287d89a1e994148833ddf3ca4941a39c89]$ echo 0 > cpuset.sched_load_balance
|
利用Go演示Cgroup CPU限制
测试程序:02.2.cgroup_cpu.go 。
该程序接受1个入参,代表测试类型:
- 空或
nolimit: 无限制 cpu: 执行cpu限制,利用cfs把cpu使用率控制在5%cpuset: 限制只使用核1和核3
测试程序的执行动作如下:
- 程序首先在cpu和cpuset中创建2个cgroup,
- 按传入的参数设置限制或不设置限制
- 利用
/proc/self/exe启动进程 - 把进程加入到2个cgroup的tasks,即加入cgroup
- 进程会创建3个goroutine不断的去消耗cpu,它们会占用3个线程
当CPU使用率不限制时,3个线程会分配到3个核上执行,所以进程的CPU使用率应当达到300%。
利用测试程序分3组实验,然后利用 top、cpuacct.usage_all、cpuset.cpu 3个角度查看CPU限制和使用情况。
不限制CPU
- 启动测试程序,进程id为4805,进入Namespace后进程id变为1,可以看到启动了3个worker协程。
1
|
[/home/ubuntu/workspace/notes/docker/codes]$ go run 02.2.cgroup_cpu.go
|
- top查看进程的CPU占用率为300%,符合预期。
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
- 利用cpuacct查看每个核上的使用时间:
1
|
[/sys/fs/cgroup/cpuacct]$ cat test_cpu_limit/cpuacct.usage_all
|
- 利用cpuset.cpus查看使用的cpu核:
1
|
[/sys/fs/cgroup/cpuset]$ cat test_cpuset_limit/cpuset.cpus
|
使用cpu限制CPU使用率
- 启动测试程序:
1
|
[/home/ubuntu/workspace/notes/docker/codes]$ go run 02.2.cgroup_cpu.go cpu
|
- top查看进程的CPU占用率为5.0%,符合预期。
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
- 利用cpuacct查看每个核上的使用时间,由于没有限制使用的cpu核,所以每个核上都还有运行时间
1
|
[/sys/fs/cgroup/cpuacct]$ cat test_cpu_limit/cpuacct.usage_all
|
- 利用cpuset.cpus查看使用的cpu核
1
|
[/sys/fs/cgroup/cpuset]$ cat test_cpuset_limit/cpuset.cpus
|
使用cpuset限制CPU占用的核
- 启动测试程序,这次与前面的不同,看到只起来了2个worker协程在运行,因为机器上的Go版本是go1.10,还不支持抢占,当协程为for循环时,2个协程都持续运行,不让出cpu,只有2个核时,第3个协程无法运行。
1
|
[/home/ubuntu/workspace/notes/docker/codes]$ go run 02.2.cgroup_cpu.go cpuset
|
- top查看进程的CPU占用率为200%,符合只使用2个核的预期。
1
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
- 利用cpuacct查看每个核上的使用时间,只有核1和3上有时间统计,说明只使用了核1和3
1
|
[/sys/fs/cgroup/cpuacct]$ cat test_cpu_limit/cpuacct.usage_all
|
- 利用cpuset.cpus查看使用的cpu核
1
|
[/sys/fs/cgroup/cpuset]$ cat test_cpuset_limit/cpuset.cpus
|
推荐资料
https://unihon.github.io/2019-08/specify-memory-and-cpu-of-the-container/
CPU
CPU 的控制(数量)主要涉及的选项为 cpu-period 和 cpu-quota,如果是 Docker 1.13 及以上,可以用更方便的 cpus 取代。另外还有 cpuset-cpus 用于指定容器进程使用哪个 CPU,有点类似于 taskset。
注意:这里的 CPU,指的是逻辑 CPU。
cpu-period、cpu-quota
cpu-period:The length of a CPU period in microseconds.cpu-quota:Microseconds of CPU time that the container can get in a CPU period.
cpu-period 的默认值为 100 毫秒(cpu-period 给的是 100000,应该是换算为微秒了),没什么特别需求不用更改。
实际 CPU 的使用量为 cpu-quota/cpu-period,cpu-quota 使用默认值 100000。
如果限制为一个 CPU 的 50%(半个 CPU),cpu-quota 则为 50000。
# 更多例子
|
--cpus
cpus:Number of CPUs.
虽然 cpus 可以很方便地达到和 cpu-period、cpu-quota 基本“一样”的效果,但是 --cpus 并不是在内部(Docker Engine API 层)转换为 cpu-period、cpu-quota。
--cpus 选项实际上设置的是 API 里面的 NanoCPUs。
NanoCPUs:CPU quota in units of 1e-9 CPUs.
1 cpus = 1000000000 NanoCPUs
--cpuset-cpus
cpuset-cpus:CPUs in which to allow execution (0-3, 0,1).
cpuset-cpus 的优先级要比 cpu-quota、cpu-period 和 cpus 高。cpuset-cpus 为 0-3 表示容器进程可以运行在 0 到 3 号 CPU 上,0,1 表示容器进程可以运行在 0 和 1 号 CPU 上。
如果 cpuset-cpus 为 0,则表示容器进程只可以运行在 0 号 CPU 上。
cpu-quota/cpu-period 或 cpus 的“有效值”永远是小于或者等于 cpuset-cpus 所涉及到的 CPU 数量。
即是说,当 cpu-quota/cpu-period 或 cpus 的值为 2 时,如果 cpuset-cpus 所涉及到的 CPU 数量只有一个,如 0 号 CPU。那么容器最多只能使用 0 号 CPU 100% 的资源(一个 CPU)。
注意
如果是使用 cpus 限制容器的 CPU 数量,当指定的数量大于宿主机的 CPU 数量时,会返回不能指定大于宿主机的 CPU 数量的提示。
而用 cpu-quota 和 cpu-period 时,当他们的比值大于宿主机的 CPU 数量时,是不会报错的。
因为 cpu-quota 指定的是“上限配额”,如果 cpu-quota/cpu-period 大于宿主机的 CPU 数量时,则是表示可以使用所有的 CPU 资源。
注:关于 cpu-period 和 cpu-quota 更详细的信息,请看参考。
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号