




https://cizixs.com/2017/08/04/docker-resources-limit/
在使用 docker 运行容器时,一台主机上可能会运行几百个容器,这些容器虽然互相隔离,但是底层却使用着相同的 CPU、内存和磁盘资源。
如果不对容器使用的资源进行限制,那么容器之间会互相影响,小的来说会导致容器资源使用不公平;大的来说,可能会导致主机和集群资源耗尽,服务完全不可用。
docker 作为容器的管理者,自然提供了控制容器资源的功能。正如使用内核的 namespace 来做容器之间的隔离,docker 也是通过内核的 cgroups 来做容器的资源限制。
这篇文章就介绍如何使用 docker 来限制 CPU、内存和 IO,以及对应的 cgroups 文件。
NOTE:如果想要了解 cgroups 的更多信息,可以参考 kernel 文档 或者其他资源。
我本地测试的 docker 版本是 17.03.0 社区版:
➜ stress docker version
Client:
Version: 17.03.0-ce
API version: 1.26
Go version: go1.7.5
Git commit: 60ccb22
Built: Thu Feb 23 11:02:43 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.0-ce
API version: 1.26 (minimum version 1.12)
Go version: go1.7.5
Git commit: 60ccb22
Built: Thu Feb 23 11:02:43 2017
OS/Arch: linux/amd64
Experimental: false
使用的是 ubuntu 16.04 系统,内核版本是 4.10.0:
➜ ~ uname -a
Linux cizixs-ThinkPad-T450 4.10.0-28-generic #32~16.04.2-Ubuntu SMP Thu Jul 20 10:19:48 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
NOTE: 不同版本和系统的功能会有差异,具体的使用方法和功能解释请以具体版本的 docker 官方文档为准。
我们使用 stress 容器来产生 CPU、内存和 IO【是磁盘IO, 非网络IO】 的压力,具体的使用请参考它的帮助文档。
$ docker run --rm -it progrium/stress --cpu 2 --io 1 --vm 2 --vm-bytes 128M --timeout 10s
The container always runs in verbose mode.
Options
-?, --help show this help statement
--version show version statement
-v, --verbose be verbose
-q, --quiet be quiet
-n, --dry-run show what would have been done
-t, --timeout N timeout after N seconds
--backoff N wait factor of N microseconds before work starts
-c, --cpu N spawn N workers spinning on sqrt()
-i, --io N spawn N workers spinning on sync()
-m, --vm N spawn N workers spinning on malloc()/free()
--vm-bytes B malloc B bytes per vm worker (default is 256MB)
--vm-stride B touch a byte every B bytes (default is 4096)
--vm-hang N sleep N secs before free (default is none, 0 is inf)
--vm-keep redirty memory instead of freeing and reallocating
-d, --hdd N spawn N workers spinning on write()/unlink()
--hdd-bytes B write B bytes per hdd worker (default is 1GB)
--hdd-noclean do not unlink files created by hdd workers
Example: stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
Note: Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size).
1. CPU 资源
主机上的进程会通过时间分片机制使用 CPU,CPU 的量化单位是频率,也就是每秒钟能执行的运算次数。
为容器限制 CPU 资源并不能改变 CPU 的运行频率,而是改变每个容器能使用的 CPU 时间片。理想状态下,CPU 应该一直处于运算状态(并且进程需要的计算量不会超过 CPU 的处理能力)。
-
docker 限制 CPU Share: -c, --cpu-shares : 总的CPU怎么按比例分配
docker 允许用户为每个容器设置一个数字,代表容器的 CPU share,默认情况下每个容器的 share 是 1024。要注意,这个 share 是相对的,本身并不能代表任何确定的意义。
当主机上有多个容器运行时,每个容器占用的 CPU 时间比例为它的 share 在总额中的比例。
举个例子,如果主机上有两个一直使用 CPU 的容器(为了简化理解,不考虑主机上其他进程),其 CPU share 都是 1024,那么两个容器 CPU 使用率都是 50%;
如果把其中一个容器的 share 设置为 512,那么两者 CPU 的使用率分别为 67% 和 33%;
如果删除 share 为 1024 的容器,剩下来容器的 CPU 使用率将会是 100%。
总结下来,这种情况下,docker 会根据主机上运行的容器和进程动态调整每个容器使用 CPU 的时间比例。
这样的好处是能保证 CPU 尽可能处于运行状态,充分利用 CPU 资源,而且保证所有容器的相对公平;缺点是无法指定容器使用 CPU 的确定值。
docker 为容器设置 CPU share 的参数是 -c --cpu-shares,它的值是一个整数。
我的机器是 4 核 CPU,因此使用 stress 启动 4 个进程来产生计算压力:
➜ stress docker run --rm -it stress --cpu 4 #启动4个进程,不是docker的命令参数,是stress的命令参数
stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 12000us
stress: dbug: [1] --> hogcpu worker 4 [7] forked
stress: dbug: [1] using backoff sleep of 9000us
stress: dbug: [1] --> hogcpu worker 3 [8] forked
stress: dbug: [1] using backoff sleep of 6000us
stress: dbug: [1] --> hogcpu worker 2 [9] forked
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogcpu worker 1 [10] forked
在另外一个 terminal 使用 htop 查看资源的使用情况:
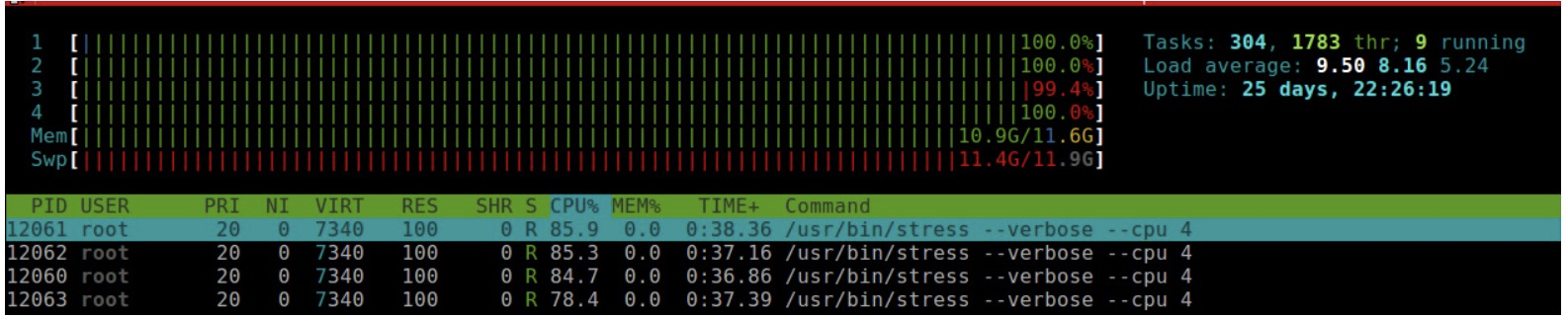
从上图中可以看到,CPU 四个核资源都达到了 100%。四个 stress 进程 CPU 使用率没有达到 100% 是因为系统中还有其他机器在运行。
为了比较,我另外启动一个 share 为 512 的容器:
➜ stress docker run --rm -it -c 512 stress --cpu 4 #没显示指定-c,默认值是1024
stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 12000us
stress: dbug: [1] --> hogcpu worker 4 [6] forked
stress: dbug: [1] using backoff sleep of 9000us
stress: dbug: [1] --> hogcpu worker 3 [7] forked
stress: dbug: [1] using backoff sleep of 6000us
stress: dbug: [1] --> hogcpu worker 2 [8] forked
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogcpu worker 1 [9] forked
因为默认情况下,容器的 CPU share 为 1024,所以这两个容器的 CPU 使用率应该大致为 2:1,下面是启动第二个容器之后的监控截图:

两个容器分别启动了四个 stress 进程,第一个容器 stress 进程 CPU 使用率都在 54% 左右,第二个容器 stress 进程 CPU 使用率在 25% 左右,比例关系大致为 2:1,符合之前的预期。
-
限制容器能使用的 CPU 核数: --cpus, 最多使用的核数、最大的CPU使用率
上面讲述的 -c --cpu-shares 参数只能限制容器使用 CPU 的比例,或者说优先级,无法确定地限制容器使用 CPU 的具体核数;
从 1.13 版本之后,docker 提供了 --cpus 参数可以限定容器能使用的 CPU 核数。这个功能可以让我们更精确地设置容器 CPU 使用量,是一种更容易理解也因此更常用的手段。
--cpus 后面跟着一个浮点数,代表容器最多使用的核数,可以精确到小数点二位,也就是说容器最小可以使用 0.01 核 CPU。
比如,我们可以限制容器只能使用 1.5 核数 CPU【总CPU 150%】:
➜ ~ docker run --rm -it --cpus 1.5 stress --cpu 3
stress: info: [1] dispatching hogs: 3 cpu, 0 io, 0 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 9000us
stress: dbug: [1] --> hogcpu worker 3 [7] forked
stress: dbug: [1] using backoff sleep of 6000us
stress: dbug: [1] --> hogcpu worker 2 [8] forked
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogcpu worker 1 [9] forked
在容器里启动三个 stress 来跑 CPU 压力,如果不加限制,这个容器会导致 CPU 的使用率为 300% 左右(也就是说会占用三个核的计算能力)。实际的监控如下图:

可以看到,每个 stress 进程 CPU 使用率大约在 50%,总共的使用率为 150%,符合 1.5 核的设置。
如果设置的 --cpus 值大于主机的 CPU 核数,docker 会直接报错:
➜ ~ docker run --rm -it --cpus 8 stress --cpu 3
docker: Error response from daemon: Range of CPUs is from 0.01 to 4.00, as there are only 4 CPUs available.
See 'docker run --help'.
如果多个容器都设置了 --cpus ,并且它们之和超过主机的 CPU 核数,并不会导致容器失败或者退出,这些容器之间会竞争使用 CPU,具体分配的 CPU 数量取决于主机运行情况和容器的 CPU share 值。
也就是说 --cpus 只能保证在 CPU 资源充足的情况下容器最多能使用的 CPU 数,docker 并不能保证在任何情况下容器都能使用这么多的 CPU(因为这根本是不可能的)。
-
限制容器运行在某些 CPU 核: --cpuset-cpus=0,1
现在的笔记本和服务器都会有多个 CPU,docker 也允许调度的时候限定容器运行在哪个 CPU 上。比如,我的主机上有 4 个核,可以通过 --cpuset 参数让容器只运行在前两个核上:
➜ ~ docker run --rm -it --cpuset-cpus=0,1 stress --cpu 2
stress: info: [1] dispatching hogs: 2 cpu, 0 io, 0 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 6000us
stress: dbug: [1] --> hogcpu worker 2 [7] forked
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogcpu worker 1 [8] forked
这样,监控中可以看到只有前面两个核 CPU 达到了 100% 使用率。

--cpuset-cpus 参数可以和 -c --cpu-shares 一起使用,限制容器只能运行在某些 CPU 核上,并且配置了使用率。
限制容器运行在哪些核上并不是一个很好的做法,因为它需要实现知道主机上有多少 CPU 核,而且非常不灵活。除非有特别的需求,一般并不推荐在生产中这样使用。
CPU 信息的 cgroup 文件
- 所有和容器 CPU share 有关的配置都在
/sys/fs/cgroup/cpu/docker/<docker_id>/目录下面,其中cpu.shares保存了 CPU share 的值(其他文件的意义可以查看 cgroups 的官方文档):
➜ ~ ls /sys/fs/cgroup/cpu/docker/d93c9a660f4a13789d995d56024f160e2267f2dc26ce676daa66ea6435473f6f/
cgroup.clone_children cpuacct.stat cpuacct.usage_all cpuacct.usage_percpu_sys cpuacct.usage_sys cpu.cfs_period_us cpu.shares notify_on_release
cgroup.procs cpuacct.usage cpuacct.usage_percpu cpuacct.usage_percpu_user cpuacct.usage_user cpu.cfs_quota_us cpu.stat tasks
➜ ~ cat /sys/fs/cgroup/cpu/docker/d93c9a660f4a13789d995d56024f160e2267f2dc26ce676daa66ea6435473f6f/cpu.shares
1024
- 和 cpuset(限制 CPU 核)有关的文件在
/sys/fs/cgroup/cpuset/docker/<docker_id>目录下,其中cpuset.cpus保存了当前容器能使用的 CPU 核:
➜ ~ ls /sys/fs/cgroup/cpuset/docker/d93c9a660f4a13789d995d56024f160e2267f2dc26ce676daa66ea6435473f6f/
cgroup.clone_children cpuset.cpus cpuset.mem_exclusive cpuset.memory_pressure cpuset.mems notify_on_release
cgroup.procs cpuset.effective_cpus cpuset.mem_hardwall cpuset.memory_spread_page cpuset.sched_load_balance tasks
cpuset.cpu_exclusive cpuset.effective_mems cpuset.memory_migrate cpuset.memory_spread_slab cpuset.sched_relax_domain_level
➜ ~ cat /sys/fs/cgroup/cpuset/docker/d93c9a660f4a13789d995d56024f160e2267f2dc26ce676daa66ea6435473f6f/cpuset.cpus
0-1
动态修改容器运行在指定的CPU核心上
[root@doc]# echo "5,7" > /sys/fs/cgroup/cpuset/docker/818e686e5932bbac2dd525c39c655bdd55135bfc3127297ef0ca813f05e7f77a/cpuset.cpus
[root@doc]#
[root@doc]# cat /sys/fs/cgroup/cpuset/docker/818e686e5932bbac2dd525c39c655bdd55135bfc3127297ef0ca813f05e7f77a/cpuset.cpus
5,7
--cpus限制 CPU 核数并不像上面两个参数一样有对应的文件对应,它是由cpu.cfs_period_us和cpu.cfs_quota_us两个文件控制的。
如果容器的 --cpus 设置为 3,其对应的这两个文件值为:
➜ ~ cat /sys/fs/cgroup/cpu/docker/233a38cc641f2e4a1bec3434d88744517a2214aff9d8297e908fa13b9aa12e02/cpu.cfs_period_us
100000
➜ ~ cat /sys/fs/cgroup/cpu/docker/233a38cc641f2e4a1bec3434d88744517a2214aff9d8297e908fa13b9aa12e02/cpu.cfs_quota_us
300000
其实在 1.12 以及之前的版本,都是通过 --cpu-period 和 --cpu-quota 这两个参数控制容器能使用的 CPU 核数的。
前者表示 CPU 的周期数,默认是 100000,单位是微秒,也就是 1s,一般不需要修改;
后者表示容器的在上述 CPU 周期里能使用的 quota,真正能使用的 CPU 核数就是 cpu-quota / cpu-period,因此对于 3 核的容器,对应的 cpu-quota 值为 300000。
https://zhuanlan.zhihu.com/p/35914450
cpu/cpu.cfs_quota_us,表示在每个 period(时间间隔)内 cgroup 可以使用的 CPU 时间,文件里数字的单位是微秒.
假设 {
cpu/cpu.cfs_quota_us: 200000,
cpu/cpu.cfs_period_us : 100000},意思是每 100ms 可以使用 200ms CPU 时间,相当于可以使用两个核。quota 为 -1 的时候表示无限制。
2. 内存资源
默认情况下,docker 并没有对容器内存进行限制,也就是说容器可以使用主机提供的所有内存。这当然是非常危险的事情,如果某个容器运行了恶意的内存消耗软件,或者代码有内存泄露,很可能会导致主机内存耗尽,因此导致服务不可用。对于这种情况,docker 会设置 docker daemon 的 OOM(out of memory) 值,使其在内存不足的时候被杀死的优先级降低。另外,就是你可以为每个容器设置内存使用的上限,一旦超过这个上限,容器会被杀死,而不是耗尽主机的内存。
限制内存上限虽然能保护主机,但是也可能会伤害到容器里的服务。如果为服务设置的内存上限太小,会导致服务还在正常工作的时候就被 OOM 杀死;如果设置的过大,会因为调度器算法浪费内存。因此,合理的做法包括:
- 为应用做内存压力测试,理解正常业务需求下使用的内存情况,然后才能进入生产环境使用
- 一定要限制容器的内存使用上限
- 尽量保证主机的资源充足,一旦通过监控发现资源不足,就进行扩容或者对容器进行迁移
- 如果可以(内存资源充足的情况),尽量不要使用 swap,swap 的使用会导致内存计算复杂,对调度器非常不友好
docker 限制容器内存使用量
在 docker 启动参数中,和内存限制有关的包括(参数的值一般是内存大小,也就是一个正数,后面跟着内存单位 b、k、m、g,分别对应 bytes、KB、MB、和 GB):
-m --memory:容器能使用的最大内存大小,最小值为 4m--memory-swap:容器能够使用的 swap 大小--memory-swappiness:默认情况下,主机可以把容器使用的匿名页(anonymous page)swap 出来,你可以设置一个 0-100 之间的值,代表允许 swap 出来的比例--memory-reservation:设置一个内存使用的 soft limit,如果 docker 发现主机内存不足,会执行 OOM 操作。这个值必须小于--memory设置的值--kernel-memory:容器能够使用的 kernel memory 大小,最小值为 4m。--oom-kill-disable:是否运行 OOM 的时候杀死容器。只有设置了-m,才可以把这个选项设置为 false,否则容器会耗尽主机内存,而且导致主机应用被杀死
关于 --memory-swap 的设置必须解释一下,--memory-swap 必须在 --memory 也配置的情况下才能有用。
- 如果
--memory-swap的值大于--memory,那么容器能使用的总内存(内存 + swap)为--memory-swap的值,能使用的 swap 值为--memory-swap减去--memory的值 - 如果
--memory-swap为 0,或者和--memory的值相同,那么容器能使用两倍于内存的 swap 大小,如果--memory对应的值是200M,那么容器可以使用400Mswap - 如果
--memory-swap的值为 -1,那么不限制 swap 的使用,也就是说主机有多少 swap,容器都可以使用
如果限制容器的内存使用为 64M,在申请 64M 资源的情况下,容器运行正常(如果主机上内存非常紧张,并不一定能保证这一点):
➜ docker run --rm -it -m 64m stress --vm 1 --vm-bytes 64M --vm-hang 0
WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap.
stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogvm worker 1 [7] forked
stress: dbug: [7] allocating 67108864 bytes ...
stress: dbug: [7] touching bytes in strides of 4096 bytes ...
stress: dbug: [7] sleeping forever with allocated memory
.....
而如果申请 100M 内存,会发现容器里的进程被 kill 掉了(worker 7 got signal 9,signal 9 就是 kill 信号)
➜ docker run --rm -it -m 64m stress --vm 1 --vm-bytes 100M --vm-hang 0
WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap.
stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: dbug: [1] using backoff sleep of 3000us
stress: dbug: [1] --> hogvm worker 1 [7] forked
stress: dbug: [7] allocating 104857600 bytes ...
stress: dbug: [7] touching bytes in strides of 4096 bytes ...
stress: FAIL: [1] (415) <-- worker 7 got signal 9
stress: WARN: [1] (417) now reaping child worker processes
stress: FAIL: [1] (421) kill error: No such process
stress: FAIL: [1] (451) failed run completed in 0s
关于 swap 和 kernel memory 的限制就不在这里过多解释了,感兴趣的可以查看官方的文档。
内存信息的 cgroups 文件
对于 docker 来说,它的内存限制也是存放在 cgroups 文件系统的。对于某个容器,你可以在 sys/fs/cgroup/memory/docker/<container_id> 目录下看到容器内存相关的文件:
➜ ls /sys/fs/cgroup/memory/docker/b067fa0c58dcdd4fa856177fac0112655b605fcc9a0fe07e36950f0086f62f46
cgroup.clone_children memory.kmem.failcnt memory.kmem.tcp.limit_in_bytes memory.max_usage_in_bytes memory.soft_limit_in_bytes notify_on_release
cgroup.event_control memory.kmem.limit_in_bytes memory.kmem.tcp.max_usage_in_bytes memory.move_charge_at_immigrate memory.stat tasks
cgroup.procs memory.kmem.max_usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.numa_stat memory.swappiness
memory.failcnt memory.kmem.slabinfo memory.kmem.usage_in_bytes memory.oom_control memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.failcnt memory.limit_in_bytes memory.pressure_level memory.use_hierarchy
而上面的内存限制对应的文件是 memory.limit_in_bytes:
➜ cat /sys/fs/cgroup/memory/docker/b067fa0c58dcdd4fa856177fac0112655b605fcc9a0fe07e36950f0086f62f46/memory.limit_in_bytes
67108864
3. IO 资源(磁盘)
对于磁盘来说,考量的参数是容量和读写速度,因此对容器的磁盘限制也应该从这两个维度出发。目前 docker 支持对磁盘的读写速度进行限制,但是并没有方法能限制容器能使用的磁盘容量(一旦磁盘 mount 到容器里,容器就能够使用磁盘的所有容量)。
➜ ~ docker run -it --rm ubuntu:16.04 bash
root@5229f756523c:/# time $(dd if=/dev/zero of=/tmp/test.data bs=10M count=100 && sync)
100+0 records in
100+0 records out
1048576000 bytes (1.0 GB) copied, 3.82859 s, 274 MB/s
real 0m4.124s
user 0m0.000s
sys 0m1.812s
限制磁盘的权重
通过 --blkio-weight 参数可以设置 block 的权重,这个权重和 --cpu-shares 类似,它是一个相对值,取值范围是 10-1000,当多个 block 去屑磁盘的时候,其读写速度和权重成反比。
不过在我的环境中,--blkio-weight 参数虽然设置了对应的 cgroups 值,但是并没有作用,不同 weight 容器的读写速度还是一样的。github 上有一个对应的 issue,但是没有详细的解答。
--blkio-weight-device 可以设置某个设备的权重值,测试下来虽然两个容器同时读的速度不同,但是并没有按照对应的比例来限制。
限制磁盘的读写速率
除了权重之外,docker 还允许你直接限制磁盘的读写速率,对应的参数有:
--device-read-bps:磁盘每秒最多可以读多少比特(bytes)--device-write-bps:磁盘每秒最多可以写多少比特(bytes)
上面两个参数的值都是磁盘以及对应的速率,格式为 <device-path>:<limit>[unit],device-path 表示磁盘所在的位置,限制 limit 为正整数,单位可以是 kb、mb 和 gb。
比如可以把设备的度速率限制在 1mb:
$ docker run -it --device /dev/sda:/dev/sda --device-read-bps /dev/sda:1mb ubuntu:16.04 bash
root@6c048edef769:/# cat /sys/fs/cgroup/blkio/blkio.throttle.read_bps_device
8:0 1048576
root@6c048edef769:/# dd iflag=direct,nonblock if=/dev/sda of=/dev/null bs=5M count=10
10+0 records in
10+0 records out
52428800 bytes (52 MB) copied, 50.0154 s, 1.0 MB/s
从磁盘中读取 50m 花费了 50s 左右,说明磁盘速率限制起了作用。
另外两个参数可以限制磁盘读写频率(每秒能执行多少次读写操作):
--device-read-iops:磁盘每秒最多可以执行多少 IO 读操作--device-write-iops:磁盘每秒最多可以执行多少 IO 写操作
上面两个参数的值都是磁盘以及对应的 IO 上限,格式为 <device-path>:<limit>,limit 为正整数,表示磁盘 IO 上限数。
比如,我们可以让磁盘每秒最多读 100 次:
➜ ~ docker run -it --device /dev/sda:/dev/sda --device-read-iops /dev/sda:100 ubuntu:16.04 bash
root@2e3026e9ccd2:/# dd iflag=direct,nonblock if=/dev/sda of=/dev/null bs=1k count=1000
1000+0 records in
1000+0 records out
1024000 bytes (1.0 MB) copied, 9.9159 s, 103 kB/s
从测试中可以看出,容器设置了读操作的 iops 为 100,在容器内部从 block 中读取 1m 数据(每次 1k,一共要读 1000 次),共计耗时约 10s,换算起来就是 100 iops/s,符合预期结果。
写操作 bps 和 iops 与读类似,这里就不再重复了,感兴趣的可以自己实验。
磁盘信息的 cgroups 文件
容器中磁盘限制的 cgroups 文件位于 /sys/fs/cgroup/blkio/docker/<docker_id> 目录:
➜ ~ ls /sys/fs/cgroup/blkio/docker/1402c1682cba743b4d80f638da3d4272b2ebdb6dc6c2111acfe9c7f7aeb72917/
blkio.io_merged blkio.io_serviced blkio.leaf_weight blkio.throttle.io_serviced blkio.time_recursive tasks
blkio.io_merged_recursive blkio.io_serviced_recursive blkio.leaf_weight_device blkio.throttle.read_bps_device blkio.weight
blkio.io_queued blkio.io_service_time blkio.reset_stats blkio.throttle.read_iops_device blkio.weight_device
blkio.io_queued_recursive blkio.io_service_time_recursive blkio.sectors blkio.throttle.write_bps_device cgroup.clone_children
blkio.io_service_bytes blkio.io_wait_time blkio.sectors_recursive blkio.throttle.write_iops_device cgroup.procs
blkio.io_service_bytes_recursive blkio.io_wait_time_recursive blkio.throttle.io_service_bytes blkio.time notify_on_release
其中 blkio.throttle.read_iops_device 对应了设备的读 IOPS,前面一列是设备的编号,可以通过 cat /proc/partitions 查看设备和分区的设备号;后面是 IOPS 上限值:
➜ ~ cat /sys/fs/cgroup/blkio/docker/1402c1682cba743b4d80f638da3d4272b2ebdb6dc6c2111acfe9c7f7aeb72917/blkio.throttle.read_iops_device
8:0 100
blkio.throttle.read_bps_device 对应了设备的读速率,格式和 IOPS 类似,只是第二列的值为 bps:
➜ ~ cat /sys/fs/cgroup/blkio/docker/9de94493f1ab4437d9c2c42fab818f12c7e82dddc576f356c555a2db7bc61e21/blkio.throttle.read_bps_device
8:0 1048576
总结
从上面的实验可以看出来,CPU 和内存的资源限制已经是比较成熟和易用,能够满足大部分用户的需求。磁盘限制也是不错的,虽然现在无法动态地限制容量,但是限制磁盘读写速度也能应对很多场景。
至于网络,docker 现在并没有给出网络限制的方案,也不会在可见的未来做这件事情,因为目前网络是通过插件来实现的,和容器本身的功能相对独立,不是很容易实现,扩展性也很差。
docker 社区已经有很多呼声,也有 issue 是关于网络流量限制的: issue 26767、issue 37、issue 4763。
资源限制一方面可以让我们为容器(应用)设置合理的 CPU、内存等资源,方便管理;另外一方面也能有效地预防恶意的攻击和异常,对容器来说是非常重要的功能。如果你需要在生产环境使用容器,请务必要花时间去做这件事情。
参考资料
- docker docs: Limit a container’s resources
- Resource management in Docker
- Docker资源管理探秘:Docker背后的内核Cgroups机制
https://www.cnblogs.com/yinzhengjie/p/12239341.html
CPU密集型的场景:
优先级越低越好,计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力 IO密集型的场景:
优先级值调高点,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度),比如Web应用,高并发,数据量大的动态网站来说,数据库应该为IO密集型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号