




https://zhuanlan.zhihu.com/p/79030485
众所周知,训练深度学习模型非常耗时。PB级别的数据加上大型的模型往往需要几天甚至一周的时间才能训练完成。所以加速训练是一个非常热门的研究话题,其中的核心技术之一就是分布式训练。
分布式训练一般分为同步训练和异步训练,同步训练中所有的worker读取mini-batch的不同部分,同步计算损失函数的gradient,最后将每个worker的gradient整合之后更新模型。异步训练中每个worker独立读取训练数据,异步更新模型参数。通常同步训练利用AllReduce来整合不同worker计算的gradient,异步训练则是基于参数服务器架构(parameter server)。
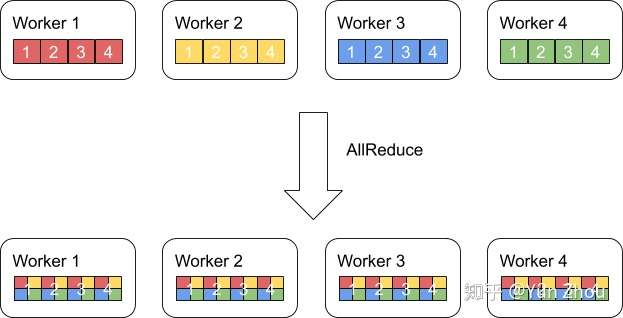
AllReduce其实是一类算法,目标是高效得将不同机器中的数据整合(reduce)之后再把结果分发给各个机器。在深度学习应用中,数据往往是一个向量或者矩阵,通常用的整合则有Sum、Max、Min等。图一展示了AllReduce在有四台机器,每台机器有一个长度为四的向量时的输入和输出。
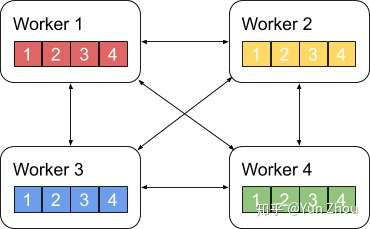
AllReduce具体实现的方法有很多种,最单纯的实现方式就是每个worker将自己的数据发给其他的所有worker,然而这种方式存在大量的浪费。
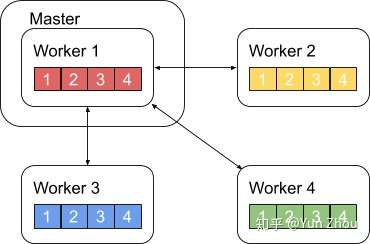
一个略优的实现是利用主从式架构,将一个worker设为master,其余所有worker把数据发送给master之后,由master进行整合元算,完成之后再分发给其余worker。不过这种实现master往往会成为整个网络的瓶颈。
AllReduce还有很多种不同的实现,多数实现都是基于某一些对数据或者运算环境的假设,来优化网络带宽的占用或者延迟。Sparse Allreduce: Efficient Scalable Communication for Power-Law Data是一个很好的例子。另外还有百度在2017年提出的Ring AllReduce,这个实现被应用在很多深度学习平台上,包括Uber的Horovod,在此详细记录一下。
Ring AllReduce算法分为两个阶段。
第一阶段,将N个worker分布在一个环上,并且把每个worker的数据分成N份。
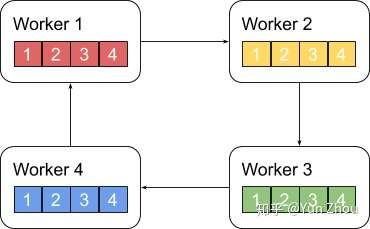
接下来我们具体看第k个worker,这个worker会把第k份数据发给下一个worker,同时从前一个worker收到第k-1份数据。
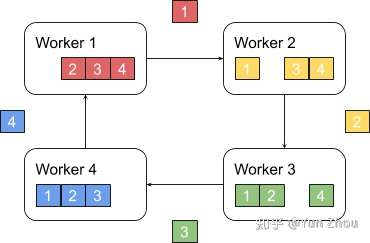
之后worker会把收到的第k-1份数据和自己的第k-1份数据整合,再将整合的数据发送给下一个worker。
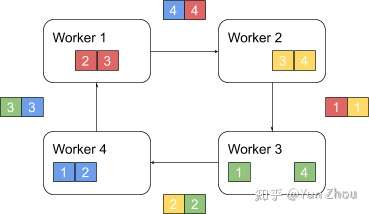
以此循环N次之后,每一个worker都会包含最终整合结果的一份。
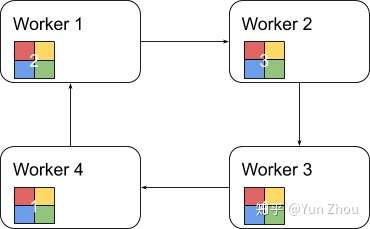
第二阶段,每个worker将整合好的部分发送给下一个worker。worker在收到数据之后更新自身数据对应的部分即可。
假设每个worker的数据是一个长度为S的向量,那么个Ring AllReduce里,每个worker发送的数据量是O(S),和worker的数量N无关。这样就避免了主从架构中master需要处理O(S*N)的数据量而成为网络瓶颈的问题。
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号