░
YOLOX: Exceeding YOLO Series in 2021
1. Inclusion
介于yoloV4和yoloV5在基于anchor的pipeline上的过度优化,因此使用Yolov3作为我们的基础网络
Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3).
yolox的large模型比yoloV5提升了1.8%AP,总而言知,就是比当前最使用的算法还要牛逼
YOLOX-L achieves 50.0% AP on COCO with 640 × 640 resolution, outperforming the counterpart YOLOv5-L by 1.8% AP.
2. YOLOX
2.1. YOLOX-DarkNet53
训练的细节: 在coco数据集上训练了300个epoch, 使用SGD优化器,学习率使用lr x batchSize / 64, 初始学习率是0.1, 使用cosine的学习率变化, 权重的L2正则是0.0005, SGD动量是0.9, batchSize的大小是128, 输出图片的尺度从448到832不等
Implementation details We train the models for a total of 300 epochs with 5 epochs warmup on COCO train2017 [17]. We use stochastic gradient descent (SGD) for training. We use a learning rate of lr×BatchSize/64 (linear scaling [8]), with a initial lr = 0.01 and the cosine lr schedule. The weight decay is 0.0005 and the SGD momentum is 0.9. The batch size is 128 by default to typical 8-GPU devices. Other batch sizes include single GPU training also work well. The input size is evenly drawn from 448 to 832 with 32 strides.
yoloV3 基线: 我们的基线采用了Darknet53做为主题和使用了一个SPPlayer,相比于原先的方法,我们稍微改变了训练的策略。添加了EMA weight梯度更新,余弦学习率变化,IOU loss 和 IOU分支,使用BCEloss作为训练类别和置信度的分支,使用IOU loss训练回归分支。通常的训练技巧对于能力的提高是正交的,我们仅使用水平翻转,颜色抖动,多尺度并且抛弃了随机Resized和crop,因为我们发现随机resize和crop与mosaic 数据增强存在重合,根据这些我们的yoloV3提高到了38.5%AP
YOLOv3 baseline Our baseline adopts the architecture of DarkNet53 backbone and an SPP layer, referred to YOLOv3-SPP in some papers [1, 7]. We slightly change some training strategies compared to the original implementation [25], adding EMA weights updating, cosine lr schedule, IoU loss and IoU-aware branch. We use BCE Loss for training cls and obj branch, and IoU Loss for training reg branch. These general training tricks are orthogonal to the key improvement of YOLOX, we thus put them on the baseline. Moreover, we only conduct RandomHorizontalFlip, ColorJitter and multi-scale for data augmentation and discard the RandomResizedCrop strategy, because we found the RandomResizedCrop is kind of overlapped with the planned mosaic augmentation. With those enhancements, our baseline achieves 38.5% AP on COCO val, as shown in Tab. 2.
概念解答:
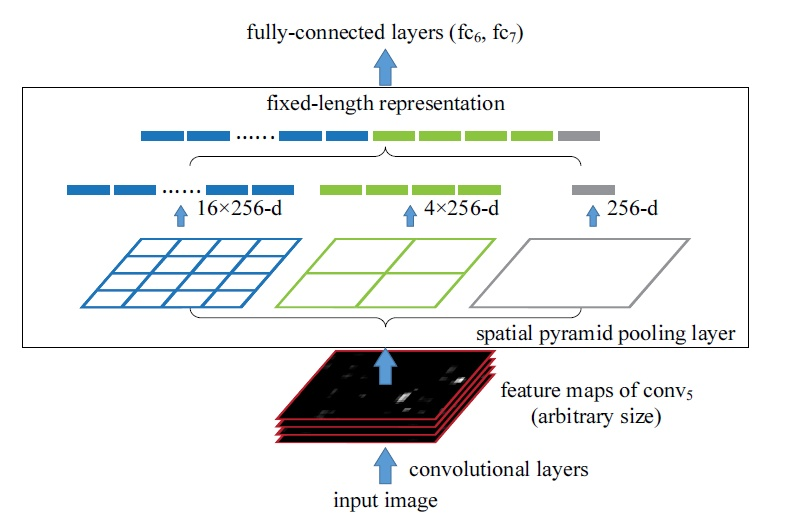
SPP layer: 金字塔池化,主要用于将全卷机以后的数据,使用最大值池化,不管输入尺寸多少,都压缩到一个固定的尺寸的输出层,这样就可以实现不同输入图像
EMA weights updating:权重的指数移动平均 ,, 其中,
表示前
条的平均值 (
),
是加权权重值 (一般设为0.9-0.999)。在深度学习的优化过程中,
是t时刻的模型权重weights,
是t时刻的影子权重(shadow weights), 表示在某一个时刻获得的权重,与前面N-1的时刻做加权相加
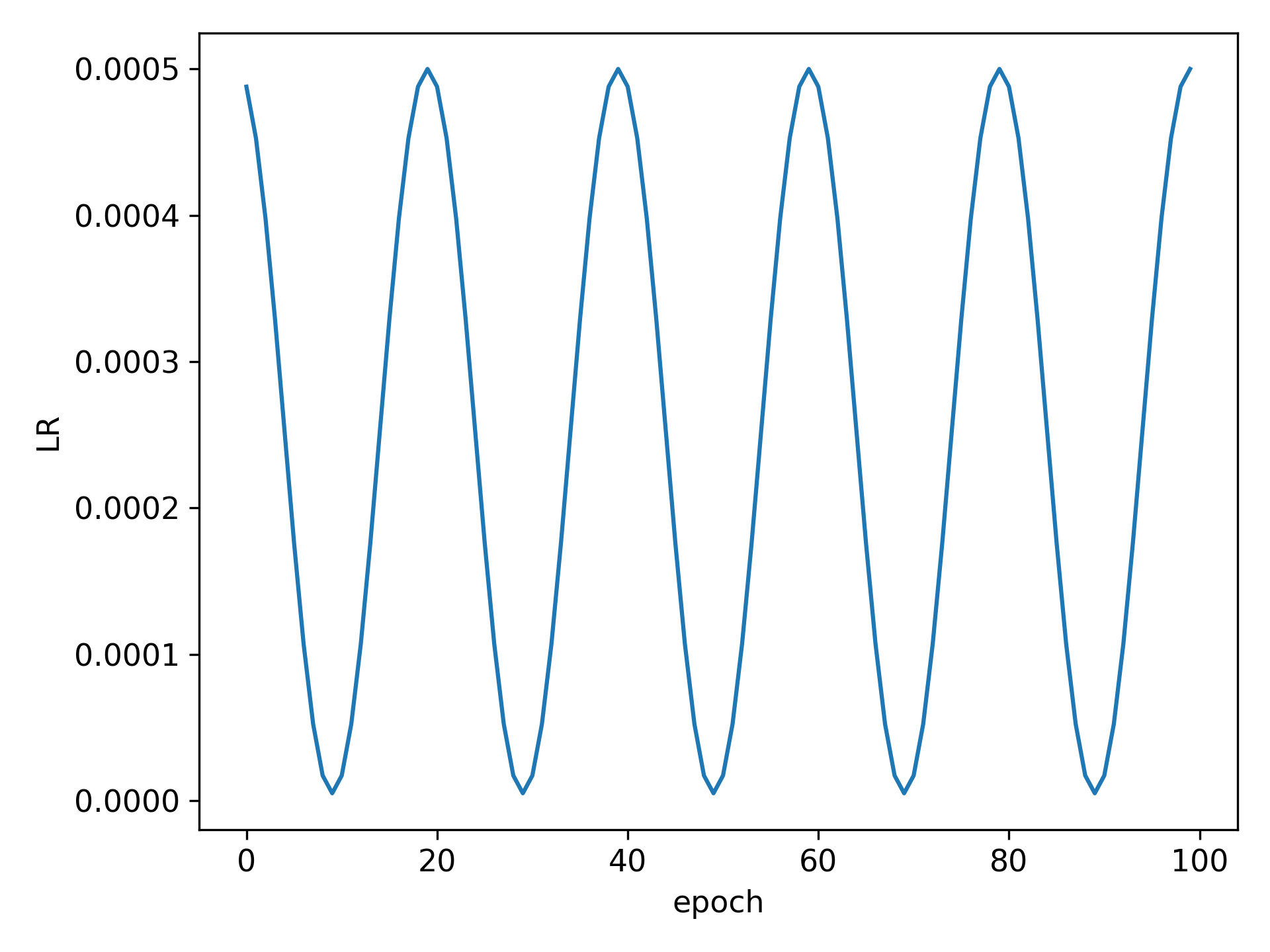
cosine lr schedule: 余弦学习率衰减, Cosine是个周期函数嘛,这里的T_max就是这个周期的一半, 如果你将T_max设置为10,则学习率衰减的周期是20个epoch,其中前10个epoch从学习率的初值(也是最大值)下降到最低值,后10个epoch从学习率的最低值上升到最大值。
IoU loss:交叉熵损失函数

RandomHorizontalFlip: 随机的水平左右翻转, 根据求出的随机数的结果,来对图像和标签进行左右翻转,或者不进行左右翻转。
RandomResizedCrop: 随机裁剪和压缩,首先对物体进行随机的裁剪,将裁剪出来的部分,进行压缩到一定的尺寸
强大的数据增强: 我们使用Mosaic和Mixup来提高YoloX的表现,Mosaic是Yolov3变体提出的一种有效的增强策略,广泛的被使用在yolov4,yoloV5和其他检测器中,MixUp通常被使用在图片分类任务中,但是被BOF算法使用在检测训练中,我们采用MiXUp和Mosaic功能在我们的模型中,并且在最后15个epoch进行关闭,使用了42.0%的AP
Strong data augmentation We add Mosaic and MixUp into our augmentation strategies to boost YOLOX’s performance. Mosaic is an efficient augmentation strategy proposed by ultralytics-YOLOv32 . It is then widely used in YOLOv4 [1], YOLOv5 [7] and other detectors [3]. MixUp [10] is originally designed for image classification task but then modified in BoF [38] for object detection training. We adopt the MixUp and Mosaic implementation in our model and close it for the last 15 epochs, achieving 42.0% AP in Tab.
Mosaic: 马赛克数据增强,首先取出4张照片,然后对四张照片做色彩,翻转,缩放等图像增强操作,然后将四张照片做一定的拼接



图片选择 位置摆放 图片拼接
Mix up: 图片混合将随机的两张样本按比例混合,分类的结果按比例分配, 这里主要是指分类任务,对于检测任务,后续会根据代码做补充

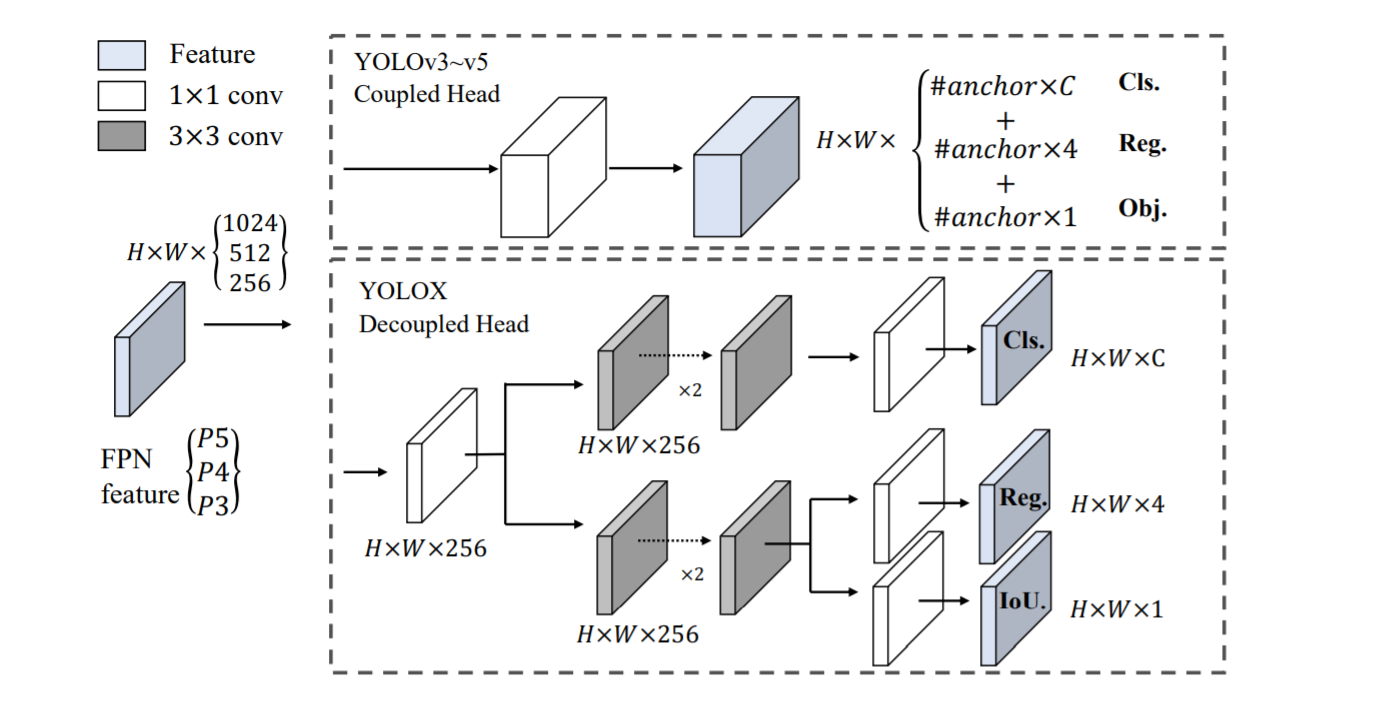
免anchor: yolov4和yolov5都是基于传统的anchor操作,然后anchor技术有许多问题,第一点,为了实际好的检测效果,需要采用聚类的方法来确定一些合适的anchor框,聚类的anchor是特定的且不够通用,第二点,anchor技术增加了检测头的复杂性和每张图的检测数量。在一些边缘的AI项目,需要移动大量的数据,这会导致整个延迟,从而构成潜在的瓶颈, AP提高到了42.9%
对于每一个位置,我们将3个减少为1个,并且使得他们直接预测4个值,分别是2个偏置项,在网格中的左上角的位置,以及预测框的长和宽。
Anchor-free Both YOLOv4 [1] and YOLOv5 [7] follow the original anchor-based pipeline of YOLOv3 [25]. However, the anchor mechanism has many known problems. First, to achieve optimal detection performance, one needs to conduct clustering analysis to determine a set of optimal anchors before training. Those clustered anchors are domain-specific and less generalized. Second, anchor mechanism increases the complexity of detection heads, as well as the number of predictions for each image. On some edge AI systems, moving such large amount of predictions between devices (e.g., from NPU to CPU) may become a potential bottleneck in terms of the overall latency。
We reduce the predictions for each location from 3 to 1 and make them directly predict four values, i.e., two offsets in terms of the left-top corner of the grid, and the height and width of the predicted box.

多个正样本: 为了保持与yolov3的规则一直,上述的anchor-free版本选择的是对于每一个物体只使用一个正样本的结果,而忽视了其他高质量的预测,然而,优化这些高质量的预测可能也会带来有效的梯度,这样可以缓解在训练过程中的正负样本极端不平衡的情况,我们简单的使用中心点3x3的区域作为正样本,也被称为中心样本在FCOS, 这样的操作可以使得检测的准确率提高到45.0%,已经超越了当前最高的yolov3变体
Multi positives To be consistent with the assigning rule of YOLOv3, the above anchor-free version selects only ONE positive sample (the center location) for each object meanwhile ignores other high quality predictions. However, optimizing those high quality predictions may also bring beneficial gradients, which may alleviates the extreme imbalance of positive/negative sampling during training. We simply assigns the center 3×3 area as positives, also named “center sampling” in FCOS [29]. The performance of the detector improves to 45.0% AP as in Tab. 2, already surpassing the current best practice of ultralytics-YOLOv3 (44.3% AP2 ).
简单的OTA 近年来,在检测任务中,高级的标签分配是另外一个重要的过程,基于我们的研究OTA, 对于标签分配,我们总结出4个关键的点,1,损失和质量的考虑 2.中心先验,3.对于每一个真实标签的动态正样本框,4.全局视眼, OTA正好满足这四个规则,因此我们选择他作为候选标签分配策略
SimOTA Advanced label assignment is another important progress of object detection in recent years. Based on our own study OTA [4], we conclude four key insights for an advanced label assignment: 1). loss/quality aware, 2). center prior, 3). dynamic number of positive anchors4 for each ground-truth (abbreviated as dynamic top-k), 4). global view. OTA meets all four rules above, hence we choose it as a candidate label assigning strategy.
最后添加一张关于上述策略与效果的图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号