MobileNetV1
亮点1:mobileNetV1使用的是一种新的网络结构, 这种网络结构的特点是使用3x3的分组卷积层进行单通道的特征提取,然后使用1x1的卷积对通道进行特征融合

图示说明: 左边是改进前的网络结构,右边是改进后的网络结构,由一个3x3的分组卷积和一个1x1的卷积构成

上述网络结构的代码:
def conv_dw(inp, oup, stride): return nn.Sequential( # 3x3分组卷积 nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False), nn.BatchNorm2d(inp), nn.ReLU(inplace=True), # 1x1卷积 nn.Conv2d(inp, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True), )
完整的网络结构
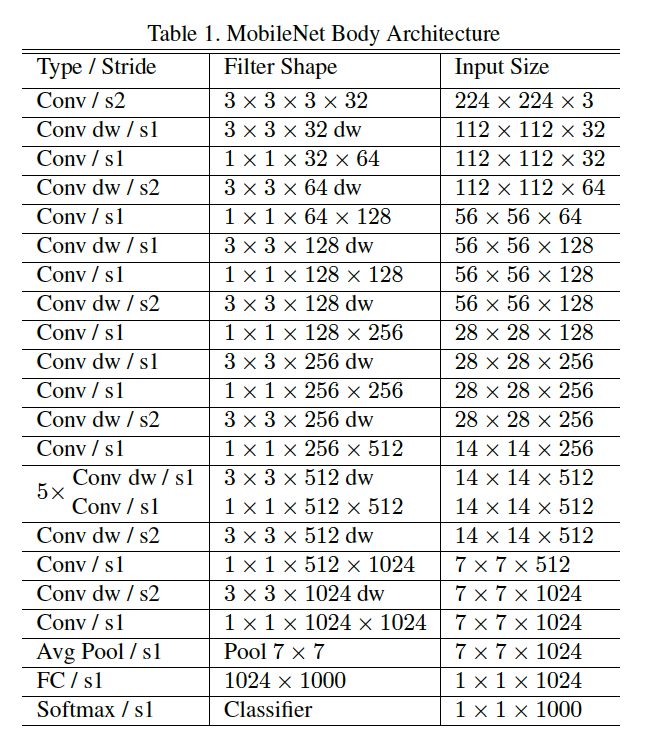
github路径:https://github.com/StevenLOL/pytorch-mobilenet/blob/master
完整代码: main.py
import argparse import os import shutil import time import torch import torch.nn as nn import torch.nn.parallel import torch.backends.cudnn as cudnn import torch.optim import torch.utils.data import torchvision.transforms as transforms import torchvision.datasets as datasets import torchvision.models as models model_names = sorted(name for name in models.__dict__ if name.islower() and not name.startswith("__") and callable(models.__dict__[name])) model_names.append('mobilenet') parser = argparse.ArgumentParser(description='PyTorch ImageNet Training') parser.add_argument('data', metavar='DIR', help='path to dataset') parser.add_argument('--arch', '-a', metavar='ARCH', default='resnet18', choices=model_names, help='model architecture: ' + ' | '.join(model_names) + ' (default: resnet18)') parser.add_argument('-j', '--workers', default=4, type=int, metavar='N', help='number of data loading workers (default: 4)') parser.add_argument('--epochs', default=90, type=int, metavar='N', help='number of total epochs to run') parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='manual epoch number (useful on restarts)') parser.add_argument('-b', '--batch-size', default=256, type=int, metavar='N', help='mini-batch size (default: 256)') parser.add_argument('--lr', '--learning-rate', default=0.1, type=float, metavar='LR', help='initial learning rate') parser.add_argument('--momentum', default=0.9, type=float, metavar='M', help='momentum') parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float, metavar='W', help='weight decay (default: 1e-4)') parser.add_argument('--print-freq', '-p', default=10, type=int, metavar='N', help='print frequency (default: 10)') parser.add_argument('--resume', default='', type=str, metavar='PATH', help='path to latest checkpoint (default: none)') parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true', help='evaluate model on validation set') parser.add_argument('--pretrained', dest='pretrained', action='store_true', help='use pre-trained model') best_prec1 = 0 class Net(nn.Module): def __init__(self): super(Net, self).__init__() def conv_bn(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True) ) def conv_dw(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False), nn.BatchNorm2d(inp), nn.ReLU(inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True), ) self.model = nn.Sequential( conv_bn( 3, 32, 2), conv_dw( 32, 64, 1), conv_dw( 64, 128, 2), conv_dw(128, 128, 1), conv_dw(128, 256, 2), conv_dw(256, 256, 1), conv_dw(256, 512, 2), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 1024, 2), conv_dw(1024, 1024, 1), nn.AvgPool2d(7), ) self.fc = nn.Linear(1024, 1000) def forward(self, x): x = self.model(x) x = x.view(-1, 1024) x = self.fc(x) return x def main(): global args, best_prec1 args = parser.parse_args() # create model if args.pretrained: print("=> using pre-trained model '{}'".format(args.arch)) model = models.__dict__[args.arch](pretrained=True) else: print("=> creating model '{}'".format(args.arch)) if args.arch.startswith('mobilenet'): model = Net() print(model) else: model = models.__dict__[args.arch]() if args.arch.startswith('alexnet') or args.arch.startswith('vgg'): model.features = torch.nn.DataParallel(model.features) model.cuda() else: model = torch.nn.DataParallel(model).cuda() # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda() optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay) # optionally resume from a checkpoint if args.resume: if os.path.isfile(args.resume): print("=> loading checkpoint '{}'".format(args.resume)) checkpoint = torch.load(args.resume) args.start_epoch = checkpoint['epoch'] best_prec1 = checkpoint['best_prec1'] model.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer']) print("=> loaded checkpoint '{}' (epoch {})" .format(args.resume, checkpoint['epoch'])) else: print("=> no checkpoint found at '{}'".format(args.resume)) cudnn.benchmark = True # Data loading code traindir = os.path.join(args.data, 'train') valdir = os.path.join(args.data, 'val') normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) train_loader = torch.utils.data.DataLoader( datasets.ImageFolder(traindir, transforms.Compose([ transforms.RandomSizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), normalize, ])), batch_size=args.batch_size, shuffle=True, num_workers=args.workers, pin_memory=True) val_loader = torch.utils.data.DataLoader( datasets.ImageFolder(valdir, transforms.Compose([ transforms.Scale(256), transforms.CenterCrop(224), transforms.ToTensor(), normalize, ])), batch_size=args.batch_size, shuffle=False, num_workers=args.workers, pin_memory=True) if args.evaluate: validate(val_loader, model, criterion) return for epoch in range(args.start_epoch, args.epochs): adjust_learning_rate(optimizer, epoch) # train for one epoch train(train_loader, model, criterion, optimizer, epoch) # evaluate on validation set prec1 = validate(val_loader, model, criterion) # remember best prec@1 and save checkpoint is_best = prec1 > best_prec1 best_prec1 = max(prec1, best_prec1) save_checkpoint({ 'epoch': epoch + 1, 'arch': args.arch, 'state_dict': model.state_dict(), 'best_prec1': best_prec1, 'optimizer' : optimizer.state_dict(), }, is_best) def train(train_loader, model, criterion, optimizer, epoch): batch_time = AverageMeter() data_time = AverageMeter() losses = AverageMeter() top1 = AverageMeter() top5 = AverageMeter() # switch to train mode model.train() end = time.time() for i, (input, target) in enumerate(train_loader): # measure data loading time data_time.update(time.time() - end) target = target.cuda(async=True) input_var = torch.autograd.Variable(input) target_var = torch.autograd.Variable(target) # compute output output = model(input_var) loss = criterion(output, target_var) # measure accuracy and record loss prec1, prec5 = accuracy(output.data, target, topk=(1, 5)) losses.update(loss.data[0], input.size(0)) top1.update(prec1[0], input.size(0)) top5.update(prec5[0], input.size(0)) # compute gradient and do SGD step optimizer.zero_grad() loss.backward() optimizer.step() # measure elapsed time batch_time.update(time.time() - end) end = time.time() if i % args.print_freq == 0: print('Epoch: [{0}][{1}/{2}]\t' 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' 'Data {data_time.val:.3f} ({data_time.avg:.3f})\t' 'Loss {loss.val:.4f} ({loss.avg:.4f})\t' 'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t' 'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format( epoch, i, len(train_loader), batch_time=batch_time, data_time=data_time, loss=losses, top1=top1, top5=top5)) def validate(val_loader, model, criterion): batch_time = AverageMeter() losses = AverageMeter() top1 = AverageMeter() top5 = AverageMeter() # switch to evaluate mode model.eval() end = time.time() for i, (input, target) in enumerate(val_loader): target = target.cuda(async=True) input_var = torch.autograd.Variable(input, volatile=True) target_var = torch.autograd.Variable(target, volatile=True) # compute output output = model(input_var) loss = criterion(output, target_var) # measure accuracy and record loss prec1, prec5 = accuracy(output.data, target, topk=(1, 5)) losses.update(loss.data[0], input.size(0)) top1.update(prec1[0], input.size(0)) top5.update(prec5[0], input.size(0)) # measure elapsed time batch_time.update(time.time() - end) end = time.time() if i % args.print_freq == 0: print('Test: [{0}/{1}]\t' 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' 'Loss {loss.val:.4f} ({loss.avg:.4f})\t' 'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t' 'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format( i, len(val_loader), batch_time=batch_time, loss=losses, top1=top1, top5=top5)) print(' * Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}' .format(top1=top1, top5=top5)) return top1.avg def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'): torch.save(state, filename) if is_best: shutil.copyfile(filename, 'model_best.pth.tar') class AverageMeter(object): """Computes and stores the average and current value""" def __init__(self): self.reset() def reset(self): self.val = 0 self.avg = 0 self.sum = 0 self.count = 0 def update(self, val, n=1): self.val = val self.sum += val * n self.count += n self.avg = self.sum / self.count def adjust_learning_rate(optimizer, epoch): """Sets the learning rate to the initial LR decayed by 10 every 30 epochs""" lr = args.lr * (0.1 ** (epoch // 30)) for param_group in optimizer.param_groups: param_group['lr'] = lr def accuracy(output, target, topk=(1,)): """Computes the precision@k for the specified values of k""" maxk = max(topk) batch_size = target.size(0) _, pred = output.topk(maxk, 1, True, True) pred = pred.t() correct = pred.eq(target.view(1, -1).expand_as(pred)) res = [] for k in topk: correct_k = correct[:k].view(-1).float().sum(0) res.append(correct_k.mul_(100.0 / batch_size)) return res if __name__ == '__main__': main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号