
docker
创建容器
docker run --name=docker_nginx_v1 -d -p 80:80 nginx:v1
有些是一个减号,有些是两个减号 --name="容器新名字": 为容器指定一个名称;-d: 后台运行容器,并返回容器ID,也即启动守护式容器;-i:以交互模式运行容器,通常与 -t 同时使用;-t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;-P: 随机端口映射;-v:文件映射 -p: 指定端口映射,有以下四种格
docker cp 1.txt containerName:/usr/local
docker exec -it containerName /bin/bash
docker inspect --format=‘{{.NetworkSetting.IpAdress}}’ containerName 获取容器所需要的信息
docker rm containerName
docker stop
docker kill
docker start
docker rmi 镜像
docker logs -f -t --tail 容器ID
docker top 容器ID 查看容器内运行的进程
将镜像保存起来
- docker commit 容器名 镜像名
- docker save 镜像名 -o 路径/文件.tar
- docker load -i 文件.tar
这是一个信息文本
这是一个危险文本。
这是一个危险文本。
dockerfile
| 命令 | 作用 |
|---|---|
| FROM image_name:tag | 定义了使用那个基础镜像构建 |
| MAINTAINER user_name | 声明镜像的创建者 |
| ENV key value | 设置环境变量 |
| RUN command | |
| Add source_dir/file dest_dir/file | 将宿主机的文件复制到容器内,压缩文件会自动解压 |
| COPY | 类似上 但不能解压 |
| WORKDIR path_dir | 设置工作目录 终端登录进来的落脚点 |
| EXPOSE | 当前容器对外暴露的端口 |
| CMD | 指定一个容器启动时要运行的命令, CMD 会被docker run 之后的参数替换 |
| ENTRYPOINT | 指定一个容器启动时要运行的命令 |
docker build -t 新镜象名字:TAG
#基于哪个镜像
FROM frolvlad/alpine-oraclejdk8:slim
#将本地文件夹挂载到当前容器
VOLUME /tmp
#复制文件到容器,
ADD eureka-server-0.0.1-SNAPSHOT.jar app.jar
#RUN bash -c 'touch /app.jar'
#配置容器启动后执行的命令
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
#声明需要暴露的端口
EXPOSE 8761Namespace 的作用是“隔离”,它让应用进程只能看到该 Namespace 内的“世界”;而 Cgroups 的作用是“限制”,它给这个“世界”围上了一圈看不见的墙。这么一折腾,进程就真的被“装”在了一个与世隔绝的房间里,而这些房间就是 PaaS 项目赖以生存的应用“沙盒”。
你应该可以理解,对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”,同一台机器上的所有容器,都共享宿主机操作系统的内核。
创建镜像 都是基于rootfs的文件系统
UnionFS(联合文件系统)
A B C
- a - b => - a
- x - x - b
-x
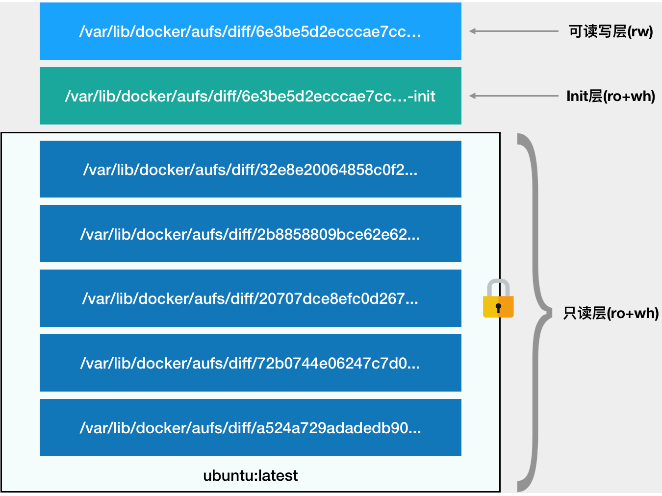
一 只读层
二 可读写层 删除只读层的foo文件。 实际上会在可读写层创建wh.foo 将其白障起来
三 init层 存放/etc/hosts etc/resolv.conf
总结:
-
上面的读写层通常也称为容器层,下面的只读层称为镜像层,所有的增删查改操作都只会作用在容器层,相同的文件上层会覆盖掉下层。知道这一点,就不难理解镜像文件的修改,比如修改一个文件的时候,首先会从上到下查找有没有这个文件,找到,就复制到容器层中,修改,修改的结果就会作用到下层的文件,这种方式也被称为copy-on-write。
-
查了一下,包括但不限于以下这几种:aufs, device mapper, btrfs, overlayfs, vfs, zfs。aufs是ubuntu 常用的,device mapper 是 centos,btrfs 是 SUSE,overlayfs ubuntu 和 centos 都会使用,现在最新的 docker 版本中默认两个系统都是使用的 overlayfs,vfs 和 zfs 常用在 solaris 系统。
docker exec 命令进入到了容器当中。在了解了 Linux Namespace 的隔离机制后,你应该会很自然地想到一个问题:docker exec 是怎么做到进入容器里的呢?
docker inspect --format '{{ .State.Pid }}' 4ddf4638572d(容器id) // 查看此容器的进程id
ls -l /proc/(pid进程号)/ns 列出namespace
#define _GNU_SOURCE
#include <fcntl.h>
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE);} while (0)
int main(int argc, char *argv[]) {
int fd;
fd = open(argv[1], O_RDONLY);
if (setns(fd, 0) == -1) {
errExit("setns");
}
execvp(argv[2], &argv[2]);
errExit("execvp");
}
这段代码功能非常简单:它一共接收两个参数,第一个参数是 argv[1],即当前进程要加入的 Namespace 文件的路径,比如 /proc/25686/ns/net;而第二个参数,则是你要在这个 Namespace 里运行的进程,比如 /bin/bash。
$ gcc -o set_ns set_ns.c
$ ./set_ns /proc/25686/ns/net /bin/bash
查看到bin/bash的进程
# 在宿主机上
ps aux | grep /bin/bash
root 28499 0.0 0.0 19944 3612 pts/0 S 14:15 0:00 /bin/bash
这时,如果按照前面介绍过的方法,查看一下这个 PID=28499 的进程的 Namespace,你就会发现这样一个事实:
$ ls -l /proc/28499/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:18 /proc/28499/ns/net -> net:[4026532281]
$ ls -l /proc/25686/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:05 /proc/25686/ns/net -> net:[4026532281]
在 /proc/[PID]/ns/net 目录下,这个 PID=28499 进程,与我们前面的 Docker 容器进程(PID=25686)指向的 Network Namespace 文件完全一样。这说明这两个进程,共享了这个名叫 net:[4026532281] 的 Network Namespace。
一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
Volume (数据卷)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号