基本分布式爬虫架构:实现分布式豆瓣爬虫
一、控制节点- URL 管理器
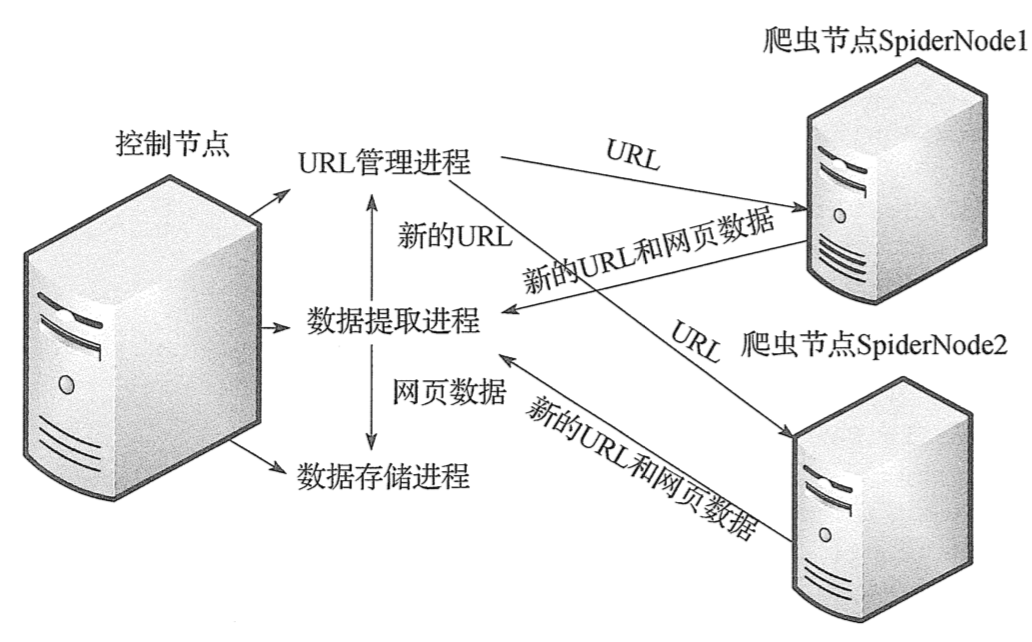
1.1 简单分布式爬虫架构
本次分布式爬虫采用主从模式,主从模式是指一台主机作为控制节点,负责管理所有运行网络爬虫的主机,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单、利于管理。而控制节点则需要与所有爬虫进行通信,因此可以看到主从模式是有缺陷的,控制节点会成为整个系统的瓶颈,容易导致整个分布式网络爬虫系统性能下降。

1.2 控制节点
控制节点主要分为 URL 管理器、数据存储器和被控制调度器。控制调度器通过三个进程来协调 URL 管理器和数据存储器的工作:一个是 URL 管理进程,负责 URL 的管理和将 URL 传递给爬虫节点;一个是数据提取进程,负责读取爬虫节点返回的数据,将返回数据中的 URL 交给 URL 管理进程,将标题和摘要等数据交给数据存储进程;最后一个是数据存储进程,负责将数据提取进程中提交的数据进行本地存储。
1.3 URL 管理器
对之前的 url 管理器进行优化,采用 set 内存去重的方式,如果直接存储大量的 URL 链接,尤其是 URL 链接很长的时候,很容易造成内存溢出,所以我们将爬取过的 URL 进行 MD5 处理。字符串经过 MD5 处理后的信息摘要长度为128位,将生成的 MD5 摘要存储到 set 后,可以减少好几倍的内存消耗,不过 Python 中的 MD5 算法生成的是256位,取中间的128位即可。我们同时添加了 save_progress 和 load_progress 方法进行序列化的操作,将未爬取 URL 集合和已爬取的 URL 集合序列化到本地,保存当前的进度,以便下次恢复状态。
1.4 代码如下
1 import pickle 2 import hashlib 3 4 5 class UrlManager: 6 def __init__(self): 7 self.new_urls = self.load_progress('new_urls.txt') # 未爬取 url 集合 8 self.old_urls = self.load_progress('old_urls.txt') # 已爬取 url 集合 9 10 def has_new_url(self): 11 """ 12 判断是否有未爬取的 url 13 :return: bool 14 """ 15 return self.new_urls_size() != 0 16 17 def get_new_url(self): 18 """ 19 返回一个未爬取的 url 20 :return: str 21 """ 22 new_url = self.new_urls.pop() 23 m = hashlib.md5() 24 m.update(new_url.encode('utf-8')) 25 self.old_urls.add(m.hexdigest()[8:-8]) 26 27 return new_url 28 29 def add_new_url(self, url): 30 """ 31 添加一个新的 url 32 :param url: 单个 url 33 :return: None 34 """ 35 if url is None: 36 return None 37 m = hashlib.md5() 38 m.update(url.encode('utf-8')) 39 url_md5 = m.hexdigest()[8:-8] 40 if (url not in self.new_urls) and (url_md5 not in self.old_urls): 41 self.new_urls.add(url) 42 43 def add_new_urls(self, urls): 44 """ 45 添加多个新的url 46 :param urls: 多个 url 47 :return: None 48 """ 49 if urls is None: 50 return None 51 for url in urls: 52 self.add_new_url(url) 53 54 def new_urls_size(self): 55 """ 56 返回未爬过的 url 集合的大小 57 :return: int 58 """ 59 return len(self.new_urls) 60 61 def old_urls_size(self): 62 """ 63 返回已爬过的 url 集合的大小 64 :return: int 65 """ 66 return len(self.old_urls) 67 68 def save_progress(self, path, data): 69 """ 70 保存进度 71 :param path: 路径 72 :return: None 73 """ 74 with open(path, 'wb') as file: 75 pickle.dump(data, file) 76 77 def load_progress(self, path): 78 """ 79 从本地文件加载进度 80 :param path: 路径 81 :return: set 82 """ 83 print('[+] 从文件加载进度{}'.format(path)) 84 try: 85 with open(path, 'rb') as file: 86 return pickle.load(file) 87 except: 88 print('[!] 无进度文件') 89 90 return set()
二、控制节点-数据存储器
2.1 实现原理
因为存储方式相同所以数据存储器的代码无需修改
2.2 代码如下
1 import csv
2
3 class DataOutput:
4 def __init__(self):
5 self.file = open('数据.csv', 'w')
6 self.csv_file = csv.writer(self.file)
7 self.csv_file.writerow(['电影名', '评分', '评分人数'])
8
9 def output_csv(self, data):
10 """
11 将数据写入 csv 文件
12 :param data: 数据
13 :return: None
14 """
15 self.csv_file.writerow(data)
三、控制节点-控制调度器
3.1 实现原理
控制调度器主要是产生并启动 URL 管理进程、数据提取进程和数据存储进程,同时维护4个队列保持进程间的通信,分别为 url_q、result_q、conn_q、store_q。4个队列说明如下:
- url_q:队列是 URL 管理进程将 URL 传递给爬虫节点的通道。
- result_q:队列是爬虫节点将数据返回给数据提取进程的通道。
- conn_q:队列是数据提取进程将新的 URL 数据提交给 URL 管理进程的通道。
- store_q:队列是数据提取进程将获取到的数据交给数据存储进程的通道。
3.2 代码如下
1 from multiprocessing.managers import BaseManager
2 from multiprocessing import Queue, Process
3 from DataOutput import DataOutput
4 from UrlManager import UrlManager
5 import time
6
7
8 class NodeManager:
9 def start_manager(self, url_q, result_q):
10 """
11 创建一个分布式管理器
12 :param url_q: url 队列
13 :param result_q: 结果队列
14 :return: BaseManager
15 """
16 # 把创建的两个队列注册在网络上,利用 register 方法,callable 参数关联了 Queue 对象
17 # 将 Queue 对象在网络中暴露
18 BaseManager.register('get_task_queue', callable=lambda:url_q)
19 BaseManager.register('get_result_queue', callable=lambda:result_q)
20 # 绑定端口 8001,设置验证口令"douban",相当于对象的初始化并返回
21 return BaseManager(address=('', 8001), authkey='douban'.encode('utf-8'))
22
23 def url_manager_proc(self, url_q, conn_q, root_url):
24 """
25 url 管理进程
26 :param url_q: url 队列
27 :param conn_q: 解析得到的 url 队列
28 :param root_url: 起始 url
29 :return: None
30 """
31 url_manage = UrlManager()
32 url_manage.add_new_url(root_url)
33 while True:
34 while url_manage.has_new_url():
35 print('old_urls={}'.format(url_manage.old_urls_size()))
36 new_url = url_manage.get_new_url()
37 url_q.put(new_url)
38 urls = conn_q.get()
39 url_manage.add_new_urls(urls)
40 else:
41 url_q.put('end')
42 print('控制节点发起结束通知')
43 url_manage.save_progress('old_urls.txt', url_manage.old_urls)
44 url_manage.save_progress('new_urls.txt', url_manage.new_urls)
45 return
46
47 def result_solve_proc(self, result_q, conn_q, store_q):
48 """
49 数据提取进程
50 :param result_q: 未处理数据队列
51 :param conn_q: 解析得到的 url 队列
52 :param store_q: 解析后的数据队列
53 :return:
54 """
55 while True:
56 try:
57 if not result_q.empty():
58 content = result_q.get()
59 if content['new_urls'] == 'end':
60 print('结果分析进程接收通知然后结束')
61 store_q.put('end')
62 return
63
64 conn_q.put(content['new_urls'])
65 store_q.put(content['data'])
66 else:
67 time.sleep(0.1)
68 except:
69 time.sleep(0.1)
70
71 def store_proc(self, store_q):
72 """
73 数据存储进程
74 :param store_q: 解析后的数据队列
75 :return:
76 """
77 output = DataOutput()
78 while True:
79 if not store_q.empty():
80 data = store_q.get()
81
82 if data == 'end':
83 print('存储进程接收结束通知然后结束')
84 return
85
86 for item in data:
87 output.output_csv(item)
88 else:
89 time.sleep(0.1)
90
91
92 if __name__ == '__main__':
93 # 初始化 4 个队列
94 url_q = Queue()
95 result_q = Queue()
96 conn_q = Queue()
97 store_q = Queue()
98 # 创建分布式管理器
99 node = NodeManager()
100 manager = node.start_manager(url_q, result_q)
101 # 创建 url 管理进程、数据提取进程和数据存储进程
102 url = 'https://movie.douban.com/top250?start=0'
103 url_manager_proc = Process(target=node.url_manager_proc, args=(url_q, conn_q, url,))
104 result_solve_proc = Process(target=node.result_solve_proc, args=(result_q, conn_q, store_q,))
105 store_proc = Process(target=node.store_proc, args=(store_q,))
106 # 启动 3 个进程和分布式管理器
107 url_manager_proc.start()
108 result_solve_proc.start()
109 store_proc.start()
110 manager.get_server().serve_forever()
四、爬虫节点- HTML 下载器
4.1 爬虫节点
爬虫节点相对简单,主要包含 HTML 下载器、HTML 解析器和爬虫调度器。执行流程如下:
- 爬虫调度器从控制节点中的 url_q 队列读取 URL。
- 爬虫调度器调用 HTML 下载器、HTML 解析器获取网页中心的 URL 和标题摘要。
- 爬虫调度器将新的 URL 和标题摘要传入 result_q 队列交给控制节点。
4.2 代码如下
1 import requests
2
3
4 class HtmlDownloader:
5 def download(self, url):
6 """
7 下载 html 页面源码
8 :param url: url
9 :return: str / None
10 """
11 if not url:
12 return None
13
14 headers = {
15 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:63.0) Gecko/20100101 Firefox/63.0',
16 }
17 r = requests.get(url, headers=headers)
18 if r.status_code == 200:
19 r.encoding = 'utf-8'
20 return r.text
21 else:
22 return None
五、爬虫节点- HTML 解析器
5.1 实现原理
解析规则不变,代码不变
5.2 代码如下
1 from lxml.html import etree
2 import re
3
4 class HtmlParser:
5 def parser(self, page_url, html_text):
6 """
7 解析页面新的 url 链接和数据
8 :param page_url: url
9 :param html_text: 页面内容
10 :return: tuple / None
11 """
12 if not page_url and not html_text:
13 return None
14 new_urls = self._get_new_urls(page_url, html_text)
15 new_data = self._get_new_data(html_text)
16
17 return new_urls, new_data
18
19 def _get_new_urls(self, page_url, html_text):
20 """
21 返回解析后的 url 集合
22 :param page_url: url
23 :param html_text: 页面内容
24 :return: set
25 """
26 new_urls = set()
27 links = re.compile(r'\?start=\d+').findall(html_text)
28 for link in links:
29 new_urls.add(page_url.split('?')[0] + link)
30 return new_urls
31
32 def _get_new_data(self, html_text):
33 """
34 返回解析后的数据列表
35 :param html_text: 页面内容
36 :return: list
37 """
38 datas = []
39 for html in etree.HTML(html_text).xpath('//ol[@class="grid_view"]/li'):
40 name = html.xpath('./div/div[@class="info"]/div[@class="hd"]/a/span[1]/text()')[0]
41 score = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]
42 person_num = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip('人评价')
43 datas.append([name, score, person_num])
44 return datas
六、爬虫节点- 爬虫调度器
6.1 实现原理
爬虫调度器需要先连接上控制节点,然后从 url_q 队列中获取 URL,下载并解析网页,接着将获取的数据交给 result_q 队列并返回给控制节点
6.2 代码如下
1 from multiprocessing.managers import BaseManager
2 from HtmlParser import HtmlParser
3 from HtmlDownloader import HtmlDownloader
4
5
6 class SpiderWork:
7 def __init__(self):
8 BaseManager.register('get_task_queue')
9 BaseManager.register('get_result_queue')
10
11 server_adrr = '192.168.31.101'
12 print('连接到服务器 {}'.format(server_adrr))
13 self.m = BaseManager(address=(server_adrr, 8001), authkey='douban'.encode('utf-8'))
14 self.m.connect()
15 self.task = self.m.get_task_queue()
16 self.result = self.m.get_result_queue()
17
18 self.downloader = HtmlDownloader()
19 self.parser = HtmlParser()
20 print('初始化完成')
21
22 def crawl(self):
23 while True:
24 try:
25 if not self.task.empty():
26 url = self.task.get()
27 if url == 'end':
28 print('控制节点通知爬虫节点停止工作')
29 self.result.put({'new_urls': 'end', 'data': 'end'})
30 return
31
32 print('爬虫节点正在解析: {}'.format(url.encode('utf-8')))
33 content = self.downloader.download(url)
34 new_urls, data = self.parser.parser(url, content)
35 self.result.put({'new_urls': new_urls, 'data': data})
36 except EOFError:
37 print('连接失败!')
38 except Exception as e:
39 print(e)
40 print('爬取失败!')
41
42
43 if __name__ == '__main__':
44 spider = SpiderWork()
45 spider.crawl()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号