Pytorch基础-自动求导和优化器的设置
手动设计神经网络以及手写传播极其麻烦,所以一般采用直接反向传播autograd或者直接使用optim模块进行求解;
一般使用自动反向传播使用backward函数进行;
loss = loss_fn(model(t_u, *params), t_c) loss.backward() params.grad
关于backward函数需要注意的有以下几点:
1.图积累的问题:
backward的本质原理是通过跟踪param变量的函数调用链,在各个节点计算相应的导数值,进行反向传播计算;
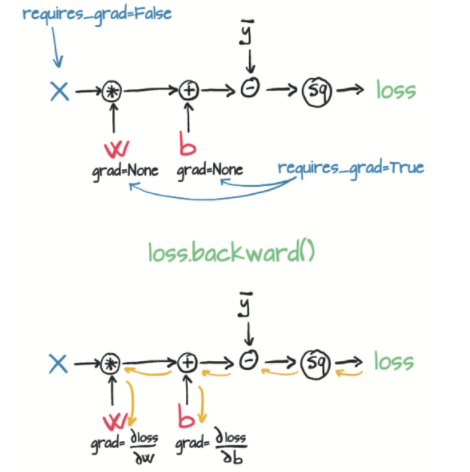
2.关于autograd值清理的问题:
在pytorch中,每次autogard下的backward并不能在每次计算之后将梯度值清0;
所以需要手动进行清零,如果在使用优化器的情况下,会变得比较简单;
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None:
params.grad.zero_() # 这可以在调用backward之前在循环中的任何时候完成
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
params = (params - learning_rate * params.grad).detach().requires_grad_()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
如上所示,每次判断都会清楚params中的grad中得值是否为空,如果不为零,直接使用zero_()进行清零,直接进行计算;
对于优化器,则是进行封装后的优化策略封装,可以避免繁琐更新模型中的每一个参数;
对于优化器来说,可以使用zero_grad和step来将grad属性归零,并且进行优化;
例如,创建一个SGD优化器:
params = torch.tensor([1.0, 0.0], requires_grad=True) learning_rate = 1e-5 optimizer = optim.SGD([params], lr=learning_rate)
使用优化器的详细代码如下所示:
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
training_loop(
n_epochs = 5000,
optimizer = optimizer,
params = params,
t_u = t_un,
t_c = t_c)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号