Virtualization学习笔记
基础知识
虚拟化
虚拟化在我看来就是“虚拟层->翻译层->真实层”,假设我的真实物理主机是windows系统:
- VMware
- Worksation:Linux操作系统->虚拟硬件->操作系统抽象接口(windows提供文件/网络/内存)
- ESXi(裸金属虚拟化):Linux操作系统->直接控制硬件
- Docker
- Docker on Linux:Linux虚拟机->通过linux自带的namespace、cgroup 等机制进行隔离->直接使用宿主机的Linux内核
- Docker on Windows/wsl2:Docker->WSL2轻量虚拟机->Hyper-V提供虚拟化支持->直接使用物理硬件
- jvm:java->jvm->机器码
VMM(又名Hypervisor),有点像是上面的翻译层,只不过控制权更大,直接掌管所有读写和虚拟机创建销毁:
- 等价性(essentially identical):一个运行于 VMM 下的程序,其行为应与直接运行于等价物理机上的同程序的行为完全一致
- 资源控制(resource control):VMM 对虚拟资源具有完全的控制能力,包括资源的分配、监控、回收
- 效率性(efficiency):机器指令中经常使用的那一部分应在没有 VMM 干预下直接在硬件上执行
现在有两种Hypervisor 方案:
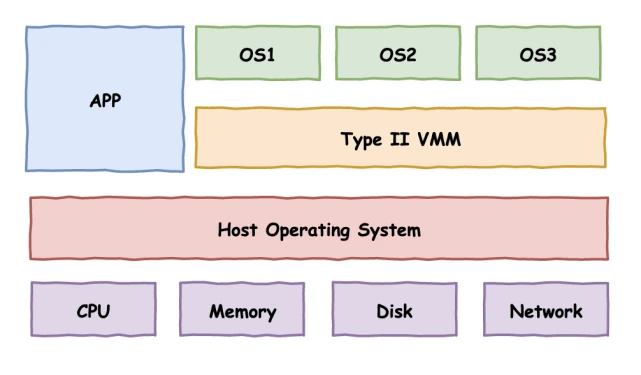
- Type-I:Hypervisor 直接运行在硬件上,即以 Hypervisor 作为 Host OS 直接管控硬件资源。例如 VMware ESXI 便是采用此种架构的 Hypervisor

- Type-II:Hypervisor 运行在传统的操作系统上,与其他应用程序并行运行。例如 Qemu 与 VMware Player 便是采用此种架构的 Hypervisor
CPU虚拟化
特权级压缩(Ring Compression):这不就是门吗,VMM 运行在最高特权级上,Guest VM 运行在低特权级上,当 Guest VM 执行到敏感指令时,其便会陷入位于最高特权级的 VMM,此时便能由 VMM 模拟敏感指令的行为。
X86系统早期并不很好支持虚拟化,原因在于它有17 条非特权敏感指令,意味着这些操作在真实物理机上它也是允许你执行的,只是你权限不够的话硬件就不会理你,但是不会触发异常。
但是不会触发异常意味着VMM就不能捕捉到,而guest OS以为自己做了(比如修改IF位),但是VMM根本不知道有这会儿事。对比mov CR3这种已知会触发异常的敏感指令,VMM就会帮你执行后返回给你。
因此在硬件还未提供对虚拟化的足够支持之前,Hypervisor 只能从软件层面下功夫,于是出现了两种纯软件虚拟化技术:「模拟执行」(VMWare)与「直接源代码改写」(Xen)。在软件虚拟化技术已经发展成熟多年之后,x86 架构对虚拟化的支持才姗姗来迟:「硬件辅助虚拟化」(Intel VT)开始出现在人们的视野当中。
纯软件实现CPU虚拟化
模拟解释执行:就是一条条翻译,比如QEMU,Linux指令->QEMU->宿主机指令。
但是这样子太慢了,毕竟非特权敏感指令并不多,我们其实只要为“敏感指令”单独开特殊通道就行了,简称HOOK:

不过这种扫描修补方法破坏了局部性(因为跳来跳去的),损失了性能。
类似于「扫描 & 修补」技术,二进制代码翻译同样会在运行时动态地修改代码,不过不同的是 BT 技术以基本块(只有一个入口和一个出口的代码块)作为翻译的单位:
- Emulator 对读入的二进制代码翻译输出为对应 ISA 的一个不包含特权指令与敏感指令的子集所构成的代码,使其可以在用户态下安全运行
- Emulator 动态地为当前要运行的基本块开辟一块空间,称之为翻译缓存(translation cache),在其中存放着翻译后的代码,每一块 TC 与原代码以某种映射关系(例如哈希表)进行关联
也就是比如:
cli ; 关闭中断(敏感指令)
mov eax, 1
sti ; 开启中断(敏感指令)
那么就会整个被翻译成:
call vmm_disable_interrupt ; 模拟 cli 的效果
mov eax, 1
call vmm_enable_interrupt ; 模拟 sti 的效果
自然指令是膨胀了。
这看起来和翻译修补差不多,但是这个效率高一点,毕竟是二进制,下次再跑相同代码就直接运行等价安全代码就行了。
翻译方法大致分为以下两种:
- 简单翻译:可以直接理解为等效代码模拟,这种方法实现较为简单,但是会让指令数量大幅膨胀,就是上面那个示例。
- 等值翻译:翻译的原代码与结果代码相同。理论上大多数指令都可以使用等值翻译直接在硬件上执行,但这需要更复杂的动态分析技术,运行之前就算出等价结果,直接写结果。
在相同 ISA 架构上大部分指令都是可以直接进行等值翻译的,除了以下几种:
- PC 相对寻址指令。这类指令的寻址与 PC 相关,但在进行二进制翻译后更改了代码基本块的结构,因此这类指令需要额外插入一些补偿代码来确保寻址的准确,这造成了一定的性能损失。
- 直接控制转换。这类指令包括函数调用与跳转指令,其目标地址需要被替换为生成代码的地址。
- 间接控制转换。这类指令包括间接调用、返回、间接跳转,其目标地址是在运行时动态得到的,因此我们无法在翻译时确定跳转目标。
- 特权指令。对于简单的特权指令可以直接翻译为类似的等值代码(例如 cli 指令可以直接翻译为置 vcpu 的 flags 寄存器的 IF 位为 0),但对于稍微复杂一点的指令,则需要进行深度模拟,利用跳转指令陷入 VMM 中,这通常会造成一定的性能开销。
由于二进制代码翻译技术使用了更为复杂的过程,由此也会引入更多的问题,对于以下情形则需要额外的处理:
- 自修改代码(Self Modifying Code)。这类程序会在运行时修改自身所执行的代码,这需要我们的 Emulator 对新生成的代码进行重翻译。
- 自参考代码(Self Referential Code)。这类程序会在运行中读取自己的代码段中内容,这需要我们额外进行处理,使其读取原代码段中内容而非翻译后的代码。
- 精确异常(Precise Exceptions)。即在翻译代码执行的过程中发生了中断或异常,这需要将运行状态恢复到原代码执行到异常点时的状态,之后再交给 Guest OS 处理。BT 技术暂很难很好地处理这种情况,因为翻译后的代码与原代码已经失去了逐条对应的关系。一个可行的解决方案就是在发生异常时进行回滚,之后重新使用解释执行的方式。
- 实时代码。这类代码对于实时性要求较高,在模拟环境下运行会损失时间精确性,目前暂时无法解决。
硬件辅助虚拟化
Intel就是VMX,AMD就是SVM。
VMX操作模式
以 Intel VT-x 为例介绍硬件辅助虚拟化(hardware-assisted virtualization)技术。
VT-x 技术为 Intel CPU 额外引入了两种运行模式,统称为 VMX 操作模式(Virtual Machine eXtensions),通过 vmxon 指令开启,这两种运行模式都独立有着自己的分级保护环:VMX Root Operation和VMX Non-Root Operation
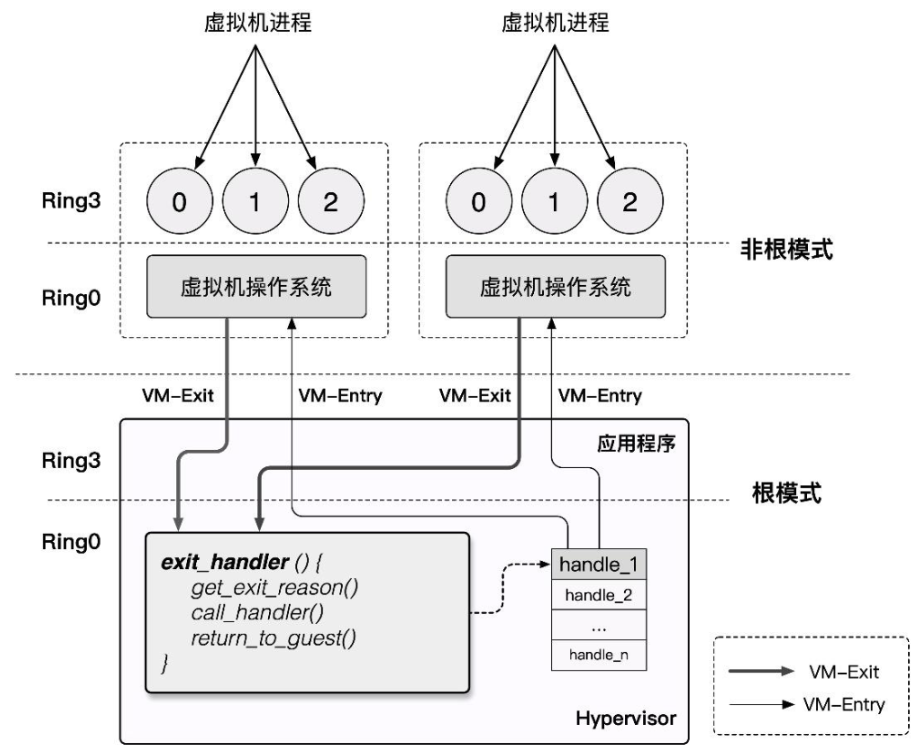
作为传统的 IA32 架构的扩展,VMX 操作模式在默认下是关闭的,只有当 VMM(Virtual Machine Monitor)需要使用硬件辅助虚拟化功能时才会使用 Intel 提供的两条新指令来开关 VMX 操作模式:
- VMXON:开启 VMX 操作模式。
- VMXOFF:关闭 VMX 操作模式。
在 Intel SDM 中描述的 VMX 生命周期如下: - 软件通过 VMXON 指令进入 VMX 操作模式。
- VMM 可以通过 VM entries 进入 Guest VM(单次只能执行一个 VM),VMM 通过 VMLAUNCH (第一次进入 VM)与 VMRESUME (从 VMM 中恢复到 VM)指令来使能 VM entry,通过 VM exits 重获控制权。
- VM exits 通过 VMM 指定的入口点移交控制权,VMM 对 VM 的退出原因进行响应后通过 VM entry 返回到 VM 中。
- 当 VMM 想要停止自身运行并退出 VMX 操作模式时,其通过 VMXOFF 指令来完成。
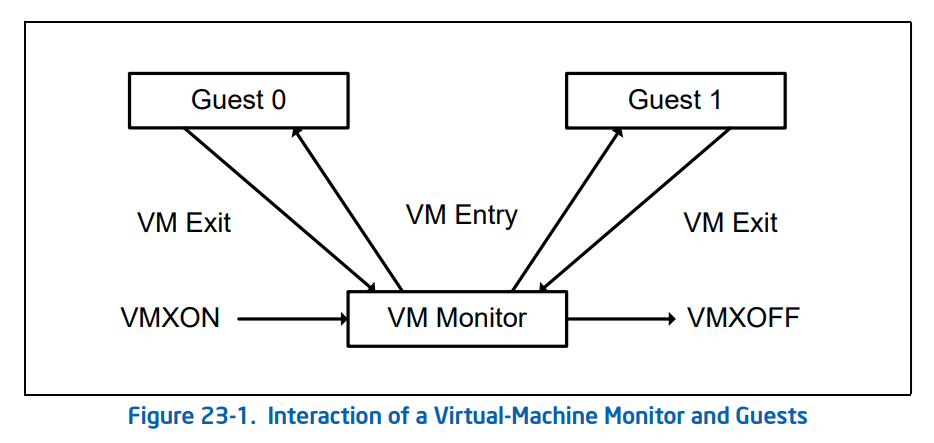
现在我们来深入 VM entry 与 VM exit 这两个行为的实现细节中,在其流程中他们分别进行了如下动作:
VM entry:从 Hypervisor 切换到 VM - 检查 VMCS 合法性(各字段值是否合法)。
- 加载 VMCS 的 Guest-state area 中的各字段到对应的寄存器。
- 加载指定的 MSR(Model-Specific Register,一个特殊的cpu寄存器,里面存的东西都很核心,比如是否启用虚拟化/关闭缓存/调节电源/VMX开启/CPU频率这些。例如 syscall 指令便是通过 MSR 寄存器来获取到内核系统调用的入口点)
- 设置 VMCS 的状态为 launched。
- 根据需要通过写 VMCS 的 VM-entry Interrucption-Information 向 VM 进行事件注入(如异常、异步中断等)。
VM exit:从 VM 切换到 Hypervisor - 将 VM 退出的原因与详细信息写入 VMCS 的 VM-exit information fields。
- 将 VM 的寄存器保存至 VMCS 的 Guest-state area 。
- 从 VMCS 的 Host-state area 中恢复 Host 寄存器。
- 加载指定 MSR。
VMCS
VMCS(Virtual-Machine Control Structure)是用以保存 CPU 虚拟化所需要的相关状态的一块内存,每个 virtual CPU 对应有一个 VMCS,同一时刻一个物理 CPU 只能与一个 VMCS 绑定,反之亦然,但在不同的时刻我们可以将 VMCS 绑定到不同的物理 CPU 上,称之为 VMCS 的迁移(Migration)。
与 VMCS 的绑定与解绑相关的是以下两条指令:
- VMPTRLD 将指定的 VMCS 与执行该指令的 CPU 进行绑定
- VMCLEAR 将执行该指令的 CPU 与其 VMCS 进行解绑
VT-x 中将 VMCS 定义为一个最大不超过 4KB 的内存块,且应与 4KB 对齐,其内容格式如下:
struct VMCS {
/* 版本号,4字节 */
uint32_t vmcs_revision_identifier:31, shadow_vmcs_indicator:1;
/* 中止标识,4字节
* 当 VM-Exit 失败时便会产生 VMX 中止,并在此处存放原因
*/
uint32_t vmx_abort_indicator;
/* 数据域 */
struct VMCSData vmcs_data;
};
- Guest-state area:保存 VM 寄存器状态,在 VM-entry 时加载,在 VM-exit 时保存
- Host-state area:保存 Hypervisor 寄存器状态,在 VM-exit 时加载
- VM-execution control fileds:控制 Non-Root 模式下的处理器行为
- VM-entry control fileds:控制 VM-Entry 过程中的某些行为
- VM-exit control fileds:控制 VM-Exit 过程中的某些行为
- VM-exit information fields:保存 VM-Exit 的基本原因及其他详细信息,在一些处理器上该域为只读域
我们可以通过以下两条指令读写 VMCS(这里的索引不是偏移值,而是每个字段都有个独特的索引值,类似字典要查表,所以为啥这样设计?):
- VMREAD <索引>: 读 VMCS 中 “索引” 指定的域
- VMWRITE <索引>: < 数据 > 向 VMCS 中 “索引” 指定的域写入数据
KVM
windows中对应的是Hyper-V,理解为将VMX/SVM打包为一个库函数,提供api给上层调用
Kernel-based Virtual Machine 是一个自 Linux 2.6.20 后集成在 kernel 中的一个开源系统虚拟化内核模块,本质上是一个依赖于硬件辅助虚拟化的位于 kernel 中的 Hypervisor,或者说 KVM 将 Linux kernel 变成了 Hypervisor,并提供了相应的用户态操作 VM 的接口: /dev/kvm ,我们可以通过 ioctl(io-control) 指令来操作 KVM。
但 KVM 本身仅提供了 CPU 与内存的虚拟化,不能构成一个完整的虚拟化环境,那么我们不难想到的是我们可以复用现有的全虚拟化方案,将模拟 CPU 与内存的工作交由 KVM 完成,这样便能直接通过 KVM 来借助硬件辅助虚拟化以提高虚拟机性能。
QEMU 便支持通过 KVM 来创建与运行虚拟机,利用 QEMU + KVM 进行虚拟化的方案如下:
- QEMU 通过 ioctl 进入内核态将控制权移交 KVM,KVM 进行 VM 的运行。
- 产生 VM-Exit,KVM 接管,判断原因并决定继续运行还是交由 QEMU 处理。
- 若是后者,恢复到用户态 QEMU 中的处理代码进行相应的处理,之后退出或回到第一步。
内存虚拟化
纯软件实现
为了实现内存空间的隔离,Hypervisor 需要为 Guest VM 准备一层新的地址空间:Guest Physical Address Space,从 Guest 侧其只能看到这一层地址空间,Hypervisor 需要记录从 GPA 到 HVA 之间的转换关系。
说白了就是虚拟机找到的“物理地址”还需要再翻译过来,结果翻译过来的是真实物理机的虚拟地址,然后再转换一遍,这可真慢啊:GVA->GPA->HVA->HPA。
为了快一点,就诞生了一个叫做“影子页表”的,说白了就是本来正常的流程是GVA->GPA,结果现在页框里面直接填的就是HPA,即GVA->HPA。
为了实现影子页表,我们本质上需要实现 MMU 虚拟化:
- Guest VM 所能看到与操作的实际都上是虚拟的 MMU,真正载入 MMU 的页表是由 Hypevisor 完成翻译后所产生的影子页表。
- 影子页表中的访问权限为只读的,当 Guest 想要读写页表时便能被 Hypervisor 捕获到这个操作并代为处理。
不过这种方法的缺点就是我们需要为 Guest VM 中的每套页表都独立维护一份影子页表,且需要多次在 VMM 与 VM 间进行切换,这有着不小的开销。
硬件辅助实现
扩展页表(Extend Page Table, EPT),硬件层面的对内存虚拟化的支持,现在硬件维护一张EPT表,流程直接变成:GVA->GPA->HPA,太快了。
Hypervisor 仅需要截获 EPT Violation 异常(EPT 表项为空),效率提高了不少。
VPID:TLB 资源优化:
- Translation Lookaside Buffer 为用以加快虚拟地址到物理地址转换的页表项缓存,当进行地址转换时 CPU 首先会先查询 TLB,TLB 根据虚拟地址查找是否存在对应的 cache,若 cache miss 了才会查询页表。
由于 TLB 是与对应的页表进行工作的,因此在切换页表时 TLB 原有的内容就失效了,此时我们应当使用 INVLPG 使 TLB 失效,类似地,在 VM-Entry 与 VM-Exit 时 CPU 都会强制让 TLB 失效,但这么做仍存在一定的性能损耗。 - 也就是虚拟机中的TLB维护的是GVA->GPA,每次切换页表时(比如切换进程)就会导致TLB刷新(除非是打了全局页G=1的页)。而在上文我们说了每次VM-entry和exit实际上就是切换了进程,真实物理机总是刷新TLB太浪费了,所以我们需要一个标志来表示“这些事虚拟机的页表,别给我刷新了!”。
- Virtual Processor Identifier(VPID)则是一种硬件级的对 TLB 资源管理的优化,其在硬件上为每个 TLB 表项打上一个 VPID 标识(VMM 为每个 vCPU 分配一个唯一的 VPID,存放在 VMCS 中,逻辑 CPU 的 VPID 为 0),在 CPU 查找 TLB cache 时会先比对 VPID,这样我们就无需在每次进行 VM entry/exit 时刷掉所有的 cache,而可以继续复用之前保留的 cache。
IO虚拟化
从处理器的角度而言,我们与外设之间的交互主要是通过 MMIO 与 Port IO 来完成的,因而针对外设的虚拟化称之为 I/O 虚拟化。
I/O 虚拟化需要实现以下三个任务:
- 提供设备接口:Hypervisor 需要为 VM 提供虚拟 / 直通设备的接口。
- 访问截获:Hypervisor 需要截获 VM 对外设的访问操作。
- 实现设备功能:Hypervisor 需要实现虚拟设备的功能。
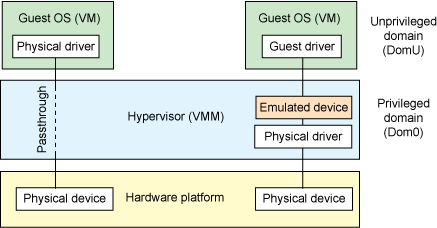
平台设备模拟
平台设备模拟即由 Hypervisor 负责模拟虚拟设备的功能,不同的虚拟化软件对于模拟设备的实现方式不同。
有两种设备模拟方式,说白了就是“你愿意用VMM提供的api进行设备模拟”还是“你自己把模拟设备当做一个app,然后进行调用”:
- 基于 hypervisor 的设备模拟(Hypervisor-based device emulation)是 VMware workstation 系列产品较为常用的一种方式:在 hypervisor 中有着对一般设备的仿真供 guest OS 进行共享,包括虚拟磁盘、虚拟网络适配器与其他的必要元素,这种模型如下图所示:
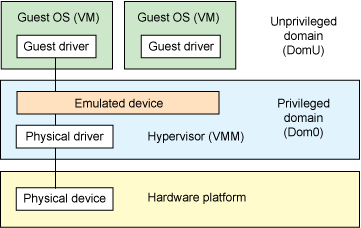
- 第二种架构称为用户空间设备模拟(User space device emulation),其虚拟设备的模拟在用户空间进行。QEMU 在用户空间中独立进行设备模拟,虚拟设备被其他的 VM 通过 hypervisor 提供的接口进行调用。由于设备的模拟是独立于 hypervisor 的,因此我们可以模拟任何设备,且该模拟设备可以在其他 hypervisor 间进行共享。

想都想得到这肯定是最慢的,因为所有虚拟机的IO操作都要被VMM从“虚拟设备”翻译成“真实设备”。
上面我们是通过“真实物理设备”去通过“VMM”创造一个给“虚拟机用的虚拟设备”,如果我们不需要共享,为什么不直接把我们的真实物理设备给虚拟机用呢?
设备直通(Device passthrough)
上面的这两种模型或多或少都存在着一定的性能开销,如果该设备需要被多个 VM 共享,那这种开销或许是值得的,但如果该设备并不需要共享,那么我们其实可以使用一种更为高效的方法——设备直通(Device passthrough)。
设备直通可以理解为设备独占的设备模拟:直接将设备隔离给到指定的 VM 上,以便该设备可以由该 VM 独占使用。这提供了接近于原生设备的性能,例如对于一些需要大量 IO 的设备(例如网络设备等),使用设备直通能提供相当完美的性能。
Virtio半虚拟化
又到了折中时间,全虚拟化太慢,设备直通独占又不太好。那就折中一下,虚拟机OS自己实现一套virtio驱动,然后直接和VMM联系,中间传输的数据规定一些标准,加快速度:
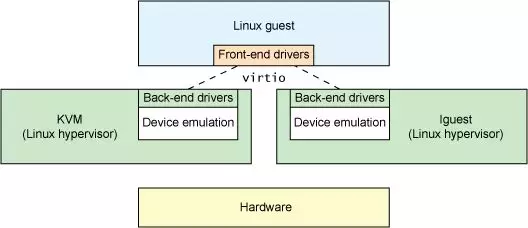
VirtQueue便是virtio中规定的专门用来传输数据的结构,本身表示一个数据队列,由一方向队列中添加 buffer,另一方从队列中取出 buffer——通过这样的方式实现了 Guest 与 Host 之间基本的数据传输模型。
为了减少模型的复杂性,通常我们使用 virtqueue 的传输都是单向的,因此一个最简单的模型就是我们就可以使用两个 virtqueue 来实现 Guest 与 Host 之间的双向通信:tx queue(发送队列) & rx queue(接收队列):

Vring就是VirtQueue所采用的数据结构,是一个环形缓冲区队列,其由三部分组成:
- 描述符表(Desc):长度,属性,下一个的idx,GPA
- 可用描述符数组(Avail):标志,idx,ring
- 已用描述符数组(Used):标志,idx,ring
那么一个虚拟PCI设备的操作就是:
- 获取 feature bits
- 设备通过一组位(feature bits)声明它支持哪些功能,比如 checksum offloading、多队列、event idx 等。
- 驱动读取设备提供的 feature bits,选择自己也支持的一部分,然后写入确认值。
- 这个过程叫 feature negotiation(特性协商)。
- 读写配置空间
- 每个 virtio PCI 设备都有一段叫做 配置空间(Config Space) 的区域。
- 里面包含了设备的配置信息,比如网络卡的 MAC 地址、磁盘的容量、块大小等。
- 驱动在初始化和运行过程中可以随时访问它,用来 获取设备信息或进行配置。
- 读写 status bits
- status 是一个非常重要的寄存器(通常是设备寄存器空间中的一部分)。
- 驱动通过设置不同的 状态位(status bits) 来告诉设备当前的初始化进度或发生了错误。
- 设备重置
- 驱动可以将 status 位清零以重置设备,表示要清空当前所有状态并重新开始初始化流程。
- 通常在异常、关闭或热插拔设备时使用。
- 创建 / 销毁 virtqueue
- 驱动会通过 创建 virtqueue 的过程告诉设备:我创建了一个队列,用来收发数据。
- 每个 virtqueue 都是用 vring 实现的共享内存结构
- 驱动会向设备登记:
- 队列编号
- vring 的物理地址
- 队列大小
- 销毁时释放这些资源并通知设备。
IOMMU
IOMMU 解决了系统虚拟化技术的一个难点:对于非纯模拟的设备而言,其并不知道 GPA->HPA 之间的映射关系,当其按 Guest OS 提供的地址进行 DMA(直接内存访问,只要是大数据吞吐的 高速 I/O 设备,几乎都使用 DMA) 时会直接访问到 Host 的内存(硬盘:我数据发过来到内存了,我看到的地址怎么是HPA,你没收到吗?虚拟机:没收到,你应该发到VPA啊?)。
当引入了 IOMMU 之后,IOMMU 可以根据 Host 侧提供的 GPA 到 HPA 之间的地址转换表,进行 DMA remapping,这样外设就能正常地访问到 Guest 的物理内存,而不会错误地访问到 Host 对应的物理内存区域。
IOMMU 通常被集成于北桥中,其提供面向设备端的两个功能:
- DMA 重映射( DMA remapping):有着 DMA 功能的设备可以使用虚拟地址,通过 IOMMU 转换为物理地址进行直接内存访问。
- 中断重映射(Interrupt remapping):IOMMU 会拦截设备产生的中断,根据中断重映射表产生新的中断请求发送给 LAPIC(Local Advanced Programmable Interrupt Controller,本地高级可编程中断控制器)。
QEMU
QEMU安装与创建
(可选)先把KVM安装了,在虚拟机中就要打开(我的ubuntu22.04就不行,因为这玩意儿不能和hyper-v共存,我还是想用wsl的,也懒得搞了,慢一点就慢一点):
然后使用命令 grep “vmx”或者“svm” /proc/cpuinfo确定一下是否可以使用kvm
最后用:sudo apt-get install qemu-kvm
下载与安装
去QEMU下载官网找到tar安装包下载。
然后解压tar –jxvf qemu-2.8.0.tar.bz2。
先确定依赖库:
sudo apt-get install -y zlib1g-dev libglib2.0-dev autoconf2.13 libtool libgtk2.0-dev
然后就可以编译安装了:
$ cd qemu-2.8.0
$ ./configure --enable-kvm --enable-debug --target-list=x86_64-softmmu --python=/usr/bin/python2.7 // 这里填入自己的python路径
$ make -j 4 // 根据自己实际CPU核数加快速度
$ sudo make install
成功!:
muyigin@ysyx:~/Downloads/qemu-2.2.0$ qemu-system-x86_64 --version
(process:8669): GLib-WARNING **: 14:04:08.993: ../../../glib/gmem.c:534: custom memory allocation vtable not supported
QEMU emulator version 2.2.0, Copyright (c) 2003-2008 Fabrice Bellard
创建新虚拟机
然后就创建一个空白qemu(其实就和你创建一个新虚拟机一样,后面还要挂上一个iso):
先创建一个空白盘:qemu-img create -f qcow2 test.img 10G // 这里的test只是第一块硬盘的名称
再挂上现成的iso文件:qemu-system-x86_64 -m 256 -hda test.img -cdrom winxpsp2.iso -enable-kvm // 这里的win.iso才是真正挂载的安装系统的盘
然后使用vncviewer来连接:
sudo apt-get install vncviewer
vncviewer localhost:5900
QEMU内存模拟
GPA视角
Qemu中的内存管理是树状的。
在 Qemu 当中使用 MemoryRegion 结构体类型来表示一块具体的 Guest 物理内存区域,该结构体定义于 include/exec/memory.h 当中:
/** MemoryRegion:
*
* 表示一块内存区域的一个结构体.
*/
struct MemoryRegion {
Object parent_obj; // MemoryRegion 是一个 Object 的子类,用于实现 QEMU 的对象系统继承机制
/* private: */
/* The following fields should fit in a cache line */
bool romd_mode; // 如果为 true,表示 ROM 允许通过普通的 load/store 访问
bool ram; // 如果为 true,表示该内存区域是 RAM(而不是 I/O 或 ROM)
bool subpage; // 如果为 true,表示这是一个“子页”区域,可能被拆分成更小的块
bool readonly; // 对于 RAM 区域,是否为只读
bool nonvolatile; // 是否为非易失性内存(如 NVDIMM)
bool rom_device; // 是否是一个 ROM 类型的设备区域
bool flush_coalesced_mmio; // 是否需要刷新合并的 MMIO 区域
bool global_locking; // 是否启用全局锁控制对该区域的访问
uint8_t dirty_log_mask; // 用于标记脏页日志的掩码,跟踪内存修改
bool is_iommu; // 是否为 IOMMU(输入输出内存管理单元)区域
RAMBlock *ram_block; // 指向实际的 RAM 块结构体【这个才是真正的地址,其他都是杂七杂八的参数......】🌟
Object *owner; // 指向拥有该内存区域的对象(例如一个设备)
const MemoryRegionOps *ops; // 指向内存区域操作函数表(读/写/映射等操作,C来实现虚函数表.......)🌟
void *opaque; // 提供给 ops 使用的用户自定义数据,类似上下文参数
MemoryRegion *container; // 指向包含此区域的“父” MemoryRegion
Int128 size; // 内存区域的大小,使用 128 位整数表示以支持大内存
hwaddr addr; // 本区域在父 MemoryRegion 中的偏移地址
void (*destructor)(MemoryRegion *mr); // 内存区域被销毁时调用的回调函数
uint64_t align; // 要求的对齐方式(通常用于映射或分配时对齐)
bool terminates; // 如果为 true,表示该区域是一个终点(如 RAM、MMIO 终结点)
bool ram_device; // 是否为一个 RAM 类型的“设备区域”
bool enabled; // 当前内存区域是否处于启用状态
bool warning_printed; /* For reservations */ // 是否已经打印了相关的警告(用于保留冲突)
uint8_t vga_logging_count; // VGA 显存日志记录计数器(用于日志记录控制)
MemoryRegion *alias; // 如果该区域是别名(alias),指向实际的 MemoryRegion
hwaddr alias_offset; // 与 alias 对应的偏移地址
int32_t priority; // 区域的优先级(用于决定区域冲突或匹配时谁覆盖谁)
QTAILQ_HEAD(, MemoryRegion) subregions; // 子 MemoryRegion 的链表头(本区域的子区域) 🌟这里就是树状节点构成
QTAILQ_ENTRY(MemoryRegion) subregions_link; // 用于将本区域插入到父区域的 subregions 链表中
QTAILQ_HEAD(, CoalescedMemoryRange) coalesced; // 合并访问范围链表(用于优化 MMIO)
const char *name; // 内存区域的名称(便于调试和日志)
unsigned ioeventfd_nb; // 注册的 ioeventfd 数量(用于事件通知)
MemoryRegionIoeventfd *ioeventfds; // 指向 ioeventfd 数组的指针
};
QEMU 模拟一块设备内存时,需要告诉 QEMU:「如果 Guest 访问我这块内存,你应该调用哪段代码来模拟读写行为?」
read / write 函数不是直接调用的函数,而是通过回调机制绑定到具体的设备模拟代码中。
相关的初始化函数是定义在别的模块中的,而下面的三种区域在你初始化的时候需要你自己提供实现代码(回调代码):
MMIO memory_region_init_io() // 需要提供 read/write 回调
ROM device memory_region_init_rom_device() // 读可直接访问,写走回调
IOMMU memory_region_init_iommu() // 实现地址翻译逻辑
初始化完成以后真正需要使用调用这块内存的时候,就是通过 MemoryRegionOps 中的函数指针来描述的(如 read、write、read_with_attrs 等),也就是上面的那个ops函数表。
里面是这样的,其实就是类似C++的虚函数表,但是土鳖C语言连对象都没有,所以就这样子实现:
/*
* Memory region callbacks
*/
struct MemoryRegionOps {
/* 从内存区域上读. @addr 与 @mr 有关; @size 单位为字节. */ 🌟这里就是实际read和write函数的地址
uint64_t (*read)(void *opaque,
hwaddr addr,
unsigned size);
/* 往内存区域上写. @addr 与 @mr 有关; @size 单位为字节. */
void (*write)(void *opaque,
hwaddr addr,
uint64_t data,
unsigned size);
🌟这里是read/write with attributes的函数地址
MemTxResult (*read_with_attrs)(void *opaque,
hwaddr addr,
uint64_t *data,
unsigned size,
MemTxAttrs attrs);
MemTxResult (*write_with_attrs)(void *opaque,
hwaddr addr,
uint64_t data,
unsigned size,
MemTxAttrs attrs);
enum device_endian endianness;
/* Guest可见约束: */
struct {
/* 若非 0,则指定了超出机器检查范围的访问大小界限
*/
unsigned min_access_size;
unsigned max_access_size;
/* If true, unaligned accesses are supported. Otherwise unaligned
* accesses throw machine checks.
*/
bool unaligned;
/*
* 若存在且 #false, 则该事务不会被设备所接受
* (并导致机器的相关行为,例如机器检查异常).
*/
bool (*accepts)(void *opaque, hwaddr addr,
unsigned size, bool is_write,
MemTxAttrs attrs); //🌟QEMU 会在发起访存请求时先调用 .accepts() 检查是否合法
} valid;
/* 内部应用约束: */
struct {
/* 若非 0,则决定了最小的实现的 size .
* 更小的 size 将被向上回绕,且将返回部分结果.
*/
unsigned min_access_size;
/* 若非 0,则决定了最大的实现的 size .
* 更大的 size 将被作为一系列的更小的 size 的访问而完成.
*/
unsigned max_access_size;
/* 若为 true, 支持非对齐的访问.
* 否则所有的访问都将被转换为(可能多种)对齐的访问.
*/
bool unaligned;
} impl;
};
Flatview:翻译MR
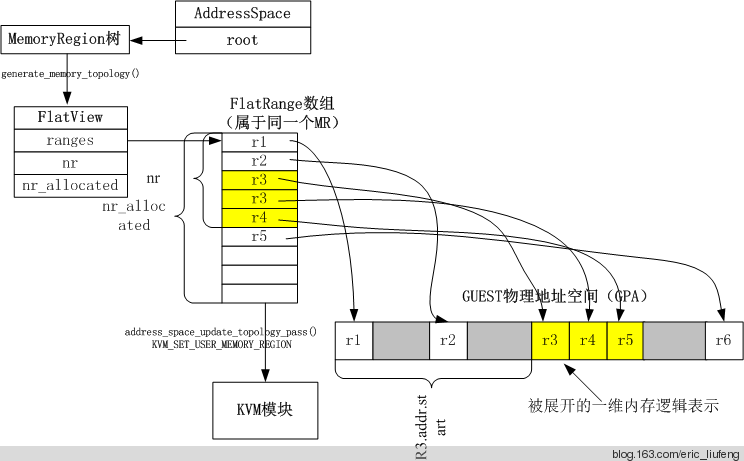
QEMU 通过树状结构的 MemoryRegion 管理 Guest 的物理地址空间,支持动态调整(如热插拔设备)。但这种嵌套、重叠的复杂结构不适合直接与 KVM 等内核模块交互。因此 QEMU 使用 FlatView 用来表示一棵 MemoryRegion 树所表示的线性的 Guest 地址空间,其将树状结构 “展平” 为列表,每个条目记录连续内存区域的起始地址(GPA)、大小、属性(如 RAM/MMIO),消除嵌套关系,简化内核处理。例如,KVM 需要明确的物理内存布局来配置 EPT(Extended Page Table),FlatView 提供可直接映射的平坦内存描述,避免内核解析复杂树结构。FlatView使用一个 FlatRange 结构体指针数组来存储不同 MemoryRegion 对应的地址信息,每个 FlatRange 表示单个 MemoryRegion 的 Guest 视角的一块线性的物理地址空间以及是否只读等特性信息, FlatRange 之间所表示的地址范围不会重叠。
说白了就是告诉VMM,我的树形节点你别管,我就告诉你,每一个节点的地址是从哪里到哪里,权限是些啥。
AddressSpace:区分每个不同类型的空间
就是个更大的集合,在根节点的地方:
/**
* struct AddressSpace: describes a mapping of addresses to #MemoryRegion objects
*/
struct AddressSpace {
/* private: */
struct rcu_head rcu;
char *name;
MemoryRegion *root; // 🌟 这里指向我们的memoryRegion
/* Accessed via RCU. */
struct FlatView *current_map; // 🌟 这里指向Flatview
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
QTAILQ_HEAD(, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
HVA视角
实际上GPA就是HVA,因为RAMBlock 结构体用来表示单个实体 MemoryRegion 所占用的 Host 虚拟内存信息,多个 RAMBlock 结构体之间构成单向链表。
也就是说上面MR中指向的ramblock,里面的实际地址就是HVA(封装了一下,加了一些其他信息),所以这步转换非常快。
struct RAMBlock {
struct rcu_head rcu;
struct MemoryRegion *mr; // 🌟该 RAMBlock 对应的 MemoryRegion(即 HVA → GPA)
uint8_t *host; // 🌟 GVA->HVA,通常由 QEMU 通过 mmap() 获得(如果未使用 KVM)
uint8_t *colo_cache; /* For colo, VM's ram cache */
ram_addr_t offset;
ram_addr_t used_length;
ram_addr_t max_length;
void (*resized)(const char*, uint64_t length, void *host);
uint32_t flags;
/* Protected by iothread lock. */
char idstr[256];
/* RCU-enabled, writes protected by the ramlist lock */
QLIST_ENTRY(RAMBlock) next;
QLIST_HEAD(, RAMBlockNotifier) ramblock_notifiers;
int fd;
size_t page_size;
/* dirty bitmap used during migration */
unsigned long *bmap;
/* bitmap of already received pages in postcopy */
unsigned long *receivedmap;
unsigned long *clear_bmap;
uint8_t clear_bmap_shift;
ram_addr_t postcopy_length;
};
注意下图,你可以认为虚拟机实际使用的真实物理机的地址就是那一串RAMlist:
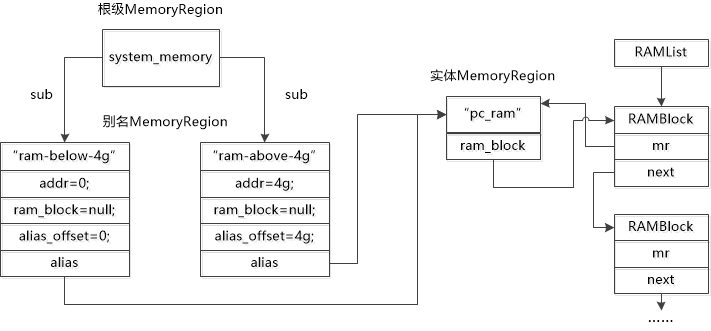
QEMU设备模拟
QEMU 在用户空间中独立进行设备模拟,虚拟设备被其他的 VM 通过 hypervisor 提供的接口进行调用。由于设备的模拟是独立于 hypervisor 的,因此我们可以模拟任何设备,且该模拟设备可以在其他 hypervisor 间进行共享。
我再来重复一下过程:
虚拟机(Guest)执行访问某个 MMIO 地址的指令
- KVM 捕捉到这次访问
- KVM 把控制权交还给 QEMU
- QEMU 检查 exit_reason == KVM_EXIT_MMIO,于是调用读写设备对应的 MemoryRegion 的回调函数
- QEMU把控制权还给KVM
MMIO
当 VM 在访问某一虚拟设备对应的物理内存 / 端口时,控制权由 VM 转交到 Hypervisor,此时 QEMU 会根据触发 VM-exit 的事件类型进行不同的处理。
int kvm_cpu_exec(CPUState *cpu)
{
//...
do {
//...
// 进入 KVM 模式运行虚拟 CPU(Guest 执行)
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
// Guest 退出(VM-exit),QEMU 取回控制权
trace_kvm_run_exit(cpu->cpu_index, run->exit_reason); // 🌟比如此时发生了请求访问MMIO的请求
switch (run->exit_reason) {
case KVM_EXIT_IO: // Guest 执行了 IN/OUT 指令(I/O 端口访问)
DPRINTF("handle_io\n");
// 处理端口 I/O。比如访问串口、键盘等传统 I/O 设备
kvm_handle_io(
run->io.port, // I/O 端口号
attrs, // 存储类型属性
(uint8_t *)run + run->io.data_offset, // 数据地址
run->io.direction, // 是读还是写
run->io.size, // 单次传输的字节数
run->io.count // 连续传输次数
);
ret = 0;
break;
case KVM_EXIT_MMIO: // 🌟拿这里举个例子,qemu得知原因以后,就调用下面的函数来执行
DPRINTF("handle_mmio\n");
// QEMU 使用 address_space_rw 处理 MMIO(例如 PCI BAR 区域、显存)
address_space_rw( // 🌟事实上,现在先获取flatview映射表的位置,然后再根据地址找出是哪个MemoryRegion,最后调用属于这个region的ops里定义的函数
// 🌟 大白话就是,qemu可不希望你IO操作读写真的就去真实物理机读写了,你自己的事情你自己解决!当初你初始化的时候不是说好了怎么处理吗?但是那个定义在“MR结构体”里的,你说你现在手里拿着的是虚拟机操作系统翻译过后的GPA不知道MR在哪里?那我先address_space_rw() 通过 address_space_to_flatview() 找到当前的 FlatView 映射表,然后再给你找出MR。🌟
&address_space_memory, // 使用主地址空间
run->mmio.phys_addr, // 访存物理地址
attrs, // 存储属性
run->mmio.data, // 读写数据的指针
run->mmio.len, // 访问长度
run->mmio.is_write // 是否写入
);
ret = 0;
break;
}
}
}
PMIO
对于 PMIO 而言会调用到 kvm_handle_io() 函数,该函数实际上也是对 address_space_rw() 的封装,只不过使用的是端口地址空间 address_space_io(就是你当初初始化的不同的地址),最后也会调用到对应 MemoryRegion 的函数表中的读写函数。
PCI 设备
PCI 即 Peripheral Component Interconnect,是一种连接电脑主板和外部设备的总线标准,其通过多根 PCI bus 完成 CPU 与 多个 PCI 设备间的连接,,在 X86 硬件体系结构中几乎所有的设备都以各种形式连接到 PCI 设备树上。
基础知识
PCI桥
- 北桥:CPU总线和PCI总线之间通讯,intel从2008开始就把北桥的内存控制器集成进cpu了,所以没有单独的北桥芯片了(以前北桥芯片负责控制内存/与cpu通讯/与南桥通讯/连接显卡)
- 南桥:ISA总线和PCI总线之间通讯,ISA总线是先前的总线标准(所以大量旧设备都是依赖它的,键盘鼠标/并口串口/USB等)。重要的是里面有中断控制器/DMA控制器/时钟电源管理
在 Linux 下我们可以使用 lspci 指令查看插在当前机器的 PCI bus 上的 PCI 设备,使用 -t 参数查看树形结构,-v 参数可以查看详细信息。
每个PCI 设备都有着三个编号:总线编号(Bus Number)、设备编号(Device Number)与功能编号(Function Number),作为设备的唯一标识;在此之上还有 PCI 域的概念,一个 PCI 域上最多可以连接 256 根 PCI 总线
当我们使用 lspci 命令查看 PCI 设备信息时,在每个设备开头都可以看到形如 xx:yy.z 的十六进制编号,这个格式其实是 总线编号:设备编号.功能编号,当我们使用 lspci -v 查看 PCI 设备信息时,在总线编号前面的 4 位数字便是 PCI 域的编号。
lspci -vv -s 00:02.0 -nn查看具体设备的详细信息。
PCI设备配置
每个 PCI 逻辑设备中都有着其自己的配置空间(configuration space),通常是设备地址空间的前 64 字节(新版的设备还扩展了 0x40~0xFF 这段配置空间),其中存放了一些设备的基本信息,如生厂商信息、IRQ中断号、mem 空间与 io 空间的起始地址与大小等
Intel 芯片组中我们可以使用 IO 空间的 CF8/CFC 地址(端口)来访问 PCI 设备的配置寄存器:
- CF8:CONFIG_ADDRESS,即 PCI 配置空间地址端口。
- CFH:CONFIG_DATA,即 PCI 配置空间数据端口。
当我们往 CONFIG_ADDRESS 端口填入对应的设备标识后,就可以从 CONFIG_DATA 端口上读写 PCI 配置空间的内存, CONFIG_ADDRESS 端口的格式如下:
- 31 位:Enable 位
- 23:16 位:总线编号
- 15:11 位:设备编号
- 10:8 位:功能编号
- 7:2 位:配置空间寄存器编号
- 1:0 位:恒为 00
现在我们来看 PCI 配置空间的结构,PCI 设备分为 Bridge 与 Agent 两类,故配置空间也分为相应的两类。
Agent 类型配置空间又被称为 Type 00h,格式如下图所示:

相应地,Bridge 类型配置空间被称为 Type 01h,与 Agent 类型配置空间大同小异:

PCI BAR
Base Address register(BAR)是 PCI 设备配置空间中非常重要的一部分,该组寄存器(也称之为 BAR空间)用以定义 PCI 需要的配置空间大小以及配置 PCI 设备占用的地址空间,我们都知道与设备通信有两种方式:MMIO 与 Port IO,相应地 BAR 的格式也有如下两种:


当 PCI 设备复位后,其会在 BAR 中存放该设备所需使用的资源类型与大小,当操作系统对 PCI 总线进行配置时,首先会获取到 PCI 设备的 BAR 中的初始信息,之后根据该初始信息分配合理的 PCI 总线域地址,将其写回到 BAR 当中
通过 BAR 进行资源分配的具体过程如下:
- 当 PCI 复位时,其会向 BAR 中写入资源信息,通过将低位的 bit 设置为 read only 的 0 来标识最小地址空间大小
- 系统软件(例如 BIOS)通过向 BAR 写一个所有 bit 都为 1 的值来确定从哪个 bit 开始是可写的,从而获取到该 BAR 对应所需的最小地址空间,同时通过最低位来获取到 BAR 的类型,并对应为这些 BAR 空间分配地址,并将分配的地址写回 BAR 空间中
- 比如说低 20 bit 都不可写,那就是说这个 bar 所需要的地址空间最小为 1MB,最后从地址总线上分配一个1MB 对齐的地址写回 bar 里
需要注意的一点是,处理器使用存储器域的地址,而 BAR 寄存器存放 PCI 总线域的地址,因此处理器不能直接通过 BAR + offset 的方式访问 PCI 设备的 BAR 空间,而应当要将 PCI 总线域的地址转换为存储器域的地址
由此,PCI BAR 中地址在存储器域中皆有着相应的映像,当处理器访问 PCI 设备的地址空间时,首先访问该设备在存储器域中的地址空间,之后通过 HOST 主桥将存储器域上地址空间转换为 PCI 总线域的地址空间,最后通过 PCI 总线将数据发送到指定的设备中
反之亦然,当 PCI 设备需要访问存储器域的地址空间时(DMA 操作),首先需要访问该存储器地址空间所对应的 PCI 总线空间,之后通过 HOST 主桥将其转换为存储器地址空间,再由 DDR 控制器完成对存储器的读写
说白了就是,cpu只能访问内存地址a,北桥就主动把a上面的写操作都映射到PCI设备的PCI总线地址b中;而PCI设备(比如此时想DMA了),它的BAR寄存器里面存着的是PCI bus地址c,然后它就往c里面写东西,北桥就会自动把c的东西写到内存a中去。
映射模式
所有 IO 设备的内存与端口空间需要被映射到对应的地址空间/端口空间中才能访问,这需要占用部分的内存地址空间与端口地址空间,即我们有两种映射外设资源的方式:
- MMIO(Memory-mapped I/O):即内存映射 IO。这种方式将 IO 设备的内存与寄存器映射到指定的内存地址空间上,此时我们便可以通过常规的访问内存的方式来直接访问到设备的寄存器与内存
- PMIO(Port-mapped I/O):即端口映射 IO。这种方式将 IO 设备的寄存器编码到指定的端口上,我们需要通过访问端口的方式来访问设备的寄存器与内存(例如在 x86 下通过 in 与 out 这一类的指令可以读写端口)。IO 设备通过专用的针脚或者专用的总线与 CPU 连接,这与内存地址空间相独立,因此又称作 isolated I/O
完成映射之后通过相应的内存/端口访问到的便是 PCI 设备的内存/端口地址空间
例如实模式下的 0xA0000 ~ 0xBFFFF 这 128KB 地址空间通常被用作显存的映射,当我们在实模式下读写这块区域时通常便是直接读写显卡上的显存,而并非普通的内存
通过 procfs 的 /proc/命令sudo cat /proc/iomem/ioports 我们可以查看物理地址空间的情况,其中我们便能看到各种设备所占用的地址空间/端口。
中断机制
PCI 设备有两种打中断的方法:传统的 INTx 中断与 MSI 中断,出于兼容的需要 PCIe 完全继承了这个特性
INTx 中断
INTx 类型的中断即传统的通过中断引脚来产生的中断,PCI 总线使用 INTA# 、INTB# 、INTC# 、INTD# 信号(低电平有效)向处理器发出中断请求,不过多数设备仅使用 INTA# 信号,产生 INTA# 中断信号的流程:
- 设备向南桥上的中断控制器打一个 INTA# ,中断控制器转为 INTR 信号后通过 APIC bus (Advanced Programmable Interrupt Controller,高级可编程中断控制器)打向处理器
- 接受中断信号的处理器(未设置则默认都打到 CPU0)通过中断向量表执行对应的处理程序
PCI 配置空间中的 Interrupt Pin 与 Interrupt Line 域:
- Interrupt Pin:记录设备应该使用哪一个 INTx 中断信号(一般是INTA#)
- Interrupt Line:记录设备连接的引脚IRQ
所以具体过程就是:PCI设备通过MMIO或PMIO往BAR的地址/端口里面直接写,同时往IRQ发出信号传递给南桥专门的中断控制器,中断控制器按照中断信号发出中断门请求。
MSI 中断
Message Signaled Interrupt 是一种更为现代化与普遍的 PCI 中断机制,MSI-eXtend 则为其升级版,该机制的引入是为了消除 INTx 的边带信号,目前绝大多数 PCIe 设备已不再使用传统的 INTx 中断,而是使用 MSI/MSI-X 提交中断请求
在 PCIe 设备中有着两个 Capability 结构,分别对应 MSI 与 MSI-X,通常一个 PCIe 设备仅会包含其中一个。对于 MSI 而言其 Capability ID 为 5,一共有四种结构,分别对应 32 位与 64 位的 Message 结构,以及对应的带上中断 Masking 的结构:
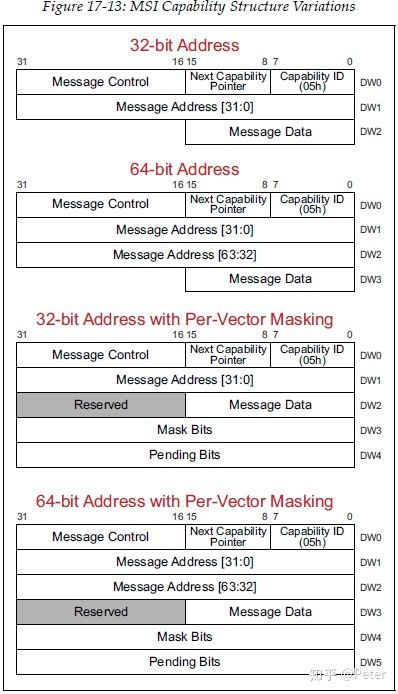
MSI/MSI-X 本质上是通过向特定的内存区域进行写入来达到中断触发的效果,当 PCI 设备提交请求时,其向 MSI/MSI-x Capability 结构中的 Message Address 地址(PCI总线域)写入 Message Data 数据,从而产生一个存储器写 TLP,由此向处理器提交存储器写请求
MSI 仅支持 32 个连续的中断向量,而 MSI-X 支持 2048 个非连续的中断向量,但 MSI-X 的中断向量信息并不像 MSI 那样直接存放在配置空间,而是存放在 MMIO 空间中,通过BIR(Base address Indicator Register)与 BAR 来确定其在 MMIO 中的具体位置
简单来说,就是现在不用引脚去触发中断控制器了,直接往特定内存地址写入数据的方式来触发中断。内存访问总线(例如 PCIe 总线)通过硬件机制通知中断控制器。处理器的中断控制器在接收到这个信息后,会立即触发中断门。
TLP
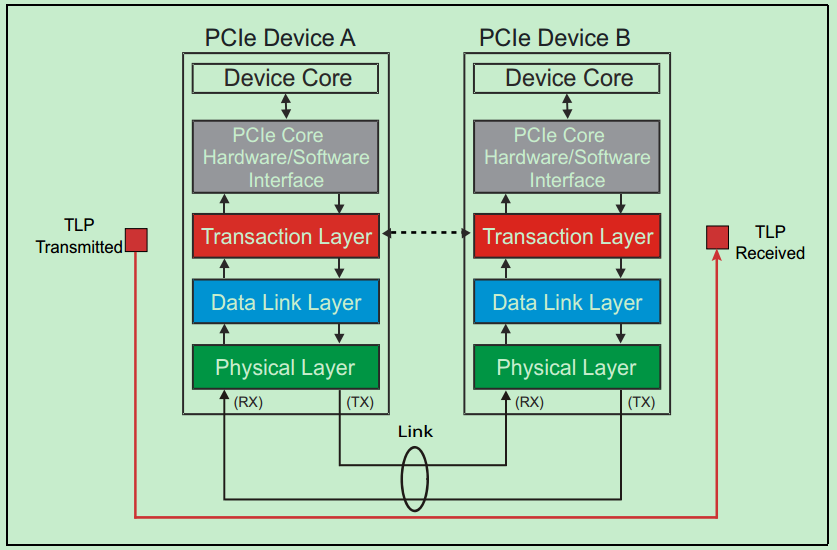
我们首先需要介绍 PCI 设备底层的通信结构,类似于计网的 OSI 七层模型,PCI 总线也可以由下到上划分为 物理层(Physical Layer)、数据链路层(Data Link Layer)、事务层(Transaction Layer),TLP 即 Transaction Layer Package:在事务层进行传输的数据包:
参考资料
本文来自博客园,作者:muyiGin,转载请注明原文链接:https://www.cnblogs.com/muyiGin/p/18896771

 浙公网安备 33010602011771号
浙公网安备 33010602011771号