




Json-Tutorial02 数值解析
前言
本节主要记录json-tutorial02的设计部分,主要完成两个内容:
- 完成字面量true/false/null解析函数的重构
- 借用c标准库函数strtod完成数字的解析
代码设计
字面量解析函数重构
在上一节的代码中,true/false/null分别由三个函数解析,并且结构十分相似:
static int lept_parse_value(lept_context* c, lept_value* v) {
switch (*c->json) {
case 'n': return lept_parse_null(c, v);
case '\0': return LEPT_PARSE_EXPECT_VALUE;
case 'f': return lept_parse_false(c, v);
case 't': return lept_parse_true(c, v);
default: return LEPT_PARSE_INVALID_VALUE;
}
}
可以发现,这三个函数实际上都是将第每个字母与要解析的json字符数组比较后,都匹配就算解析完成了,同时,需要比较的字符数也是由字面量本身确定的。所以可以统一使用lept_parse_literal来解析,其中literal参数就是null/false/true三个字面量的字符串,type是我们预期解析出来的类型:
static int lept_parse_literal(lept_context* c, lept_value* v, const char* literal, lept_type type) {
size_t i;
EXPECT(c, literal[0]);
for (i = 0; literal[i + 1] != '\0'; i++) {
// 依次将c->json的每个字符与literal做比较
if (c->json[i] != literal[i + 1]) {
return LEPT_PARSE_INVALID_VALUE;
}
}
// 解析了i个字符,c->json指针也得往后移i
c->json += i;
v->type = type;
return LEPT_PARSE_OK;
}
数字解析
按照教程的原话,数字解析是json中最麻烦的部分,按照指引,可以找到JSON标准ECMA-404 采用图的形式表示语法,也可以更直观地看到解析时可能经过的路径:
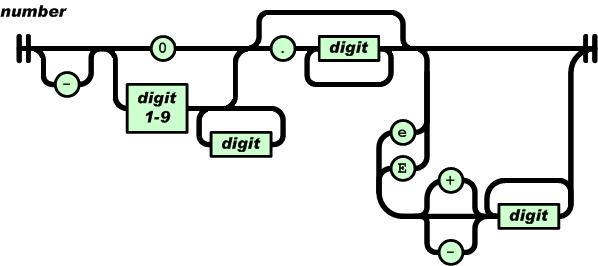
如果让我自己写解析函数,一时半会儿是写不出来的,写出来也不对,不如按照这张图来
'.'之前的部分
我们将数字解析分为三部分来看,以.和'E'/'e'字符分别作为分割线。先来看'.'之前的部分。
这张图从左往右第一个就是负号,这说明正号在json数字解析中是不合法的,只有负号以及无符号才符合要求。那么,我们首先判断第一个字符,如果是负号就合法,指针往后挪:
static int lept_parse_number(lept_context* c, lept_value* v) {
const char* p = c->json;
if (*p == '-') p++;
if (*p == '0') {
p++;
} else {
/*如果是0和负号以外的开头会走到这*/
if (!ISDIGIT1TO9(*p)) {
/* the first char is not 0~9, invalid */
return LEPT_PARSE_INVALID_VALUE;
}
/*如果是数字则指针一直往右移*/
for (p++; ISDIGIT(*p); p++) {
/* move p until *p is not digit */
}
}
...
}
如果是0和负号以外的字符打头,则判断是否是1~9之间的数字,如果不是那就不合法了,返回LEPT_PARSE_INVALID_VALUE。除此之外,所有的数字都认为是合法的,所以指针p一直往右移到第一个不是数字的字符为止,再做后续判断。
'.'和'E'/'e'之间的部分
将正负号、数字全部排除之后,这时候除了'E'/'e'之外,能出现的唯一合法字符就是'.'(并且会出现在'E'/'e'的前面)和结束符'\0'。结束符我们先不管,先判断是否是'.'。
static int lept_parse_number(lept_context* c, lept_value* v) {
/* '.'符之前的判断 */
if (*p == '.') {
p++;
if (!ISDIGIT(*p)) {
return LEPT_PARSE_INVALID_VALUE;
}
for (p++; ISDIGIT(*p); p++) {}
}
...
}
'E'/'e'后面的部分
如果是'.'的话,那么合法的情况就是:一路往后都是数字,直到遇到'E'/'e'或者\0'。所以,顺理成章的,依然先不管'\0',假设遇到了'E'/'e',那么紧跟其后的是'+'、'-'、或者0~9数字都是合法的。
static int lept_parse_number(lept_context* c, lept_value* v) {
/* '.'符之前的判断 */
/* 'e'/'E'之前的判断*/
/* 'e'/'E'之后的判断*/
if (*p == 'e' || *p == 'E') {
p++;
if (*p != '+' && *p != '-' && !ISDIGIT1TO9(*p)) {
return LEPT_PARSE_INVALID_VALUE;
}
for (p++; ISDIGIT(*p); p++) {}
}
...
}
在'E'/'e'后面的部分都解析完之后,如果最后一个字符不为'\0',则说明是有问题的,比如'123.4E103x',这种情况在教程里面视为LEPT_PARSE_ROOT_NOT_SINGULAR错误,个人认为欠妥。
数值过大、过小的处理
当我们对合法性校验完之后,调用strtod库函数来将数值字符串转化为double。当然,由于double可表示的数值有范围,所以这个转换是有数值限制的,如果过大或者过小,那么strtod会返回一个HUGE_VAL或者-HUGE_VAL。同时还要兼顾转换出错的错误处理。完整的解析代码如下:
static int lept_parse_number(lept_context* c, lept_value* v) {
/* \TODO validate number */
const char* p = c->json;
if (*p == '-') p++;
if (*p == '0') {
p++;
} else {
if (!ISDIGIT1TO9(*p)) {
/* the first char is not 0~9, invalid */
return LEPT_PARSE_INVALID_VALUE;
}
for (p++; ISDIGIT(*p); p++) {
/* move p until *p is not digit */
}
}
if (*p == '.') {
p++;
if (!ISDIGIT(*p)) {
return LEPT_PARSE_INVALID_VALUE;
}
for (p++; ISDIGIT(*p); p++) {}
}
if (*p == 'e' || *p == 'E') {
p++;
if (*p != '+' && *p != '-' && !ISDIGIT1TO9(*p)) {
return LEPT_PARSE_INVALID_VALUE;
}
for (p++; ISDIGIT(*p); p++) {}
}
if (*p != '\0') {
return LEPT_PARSE_ROOT_NOT_SINGULAR;
}
/* 错误码全局变量 */
errno = 0;
/* 由于已经做过合法性校验,这里传入NULL即可 */
v->n = strtod(c->json, NULL);
if (errno == ERANGE && (v->n == HUGE_VAL || v->n == -HUGE_VAL)) {
/* 转换出错或数值过大、过小 */
return LEPT_PARSE_NUMBER_TOO_BIG;
}
v->type = LEPT_NUMBER;
// 移动指针
c->json = p;
return LEPT_PARSE_OK;
}
总结
个人认为这个教程如果根据上面的图来写,还是思路清晰而且比较简单的,另外,需要注意合法性校验之后,对于转换错误的情况的处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号