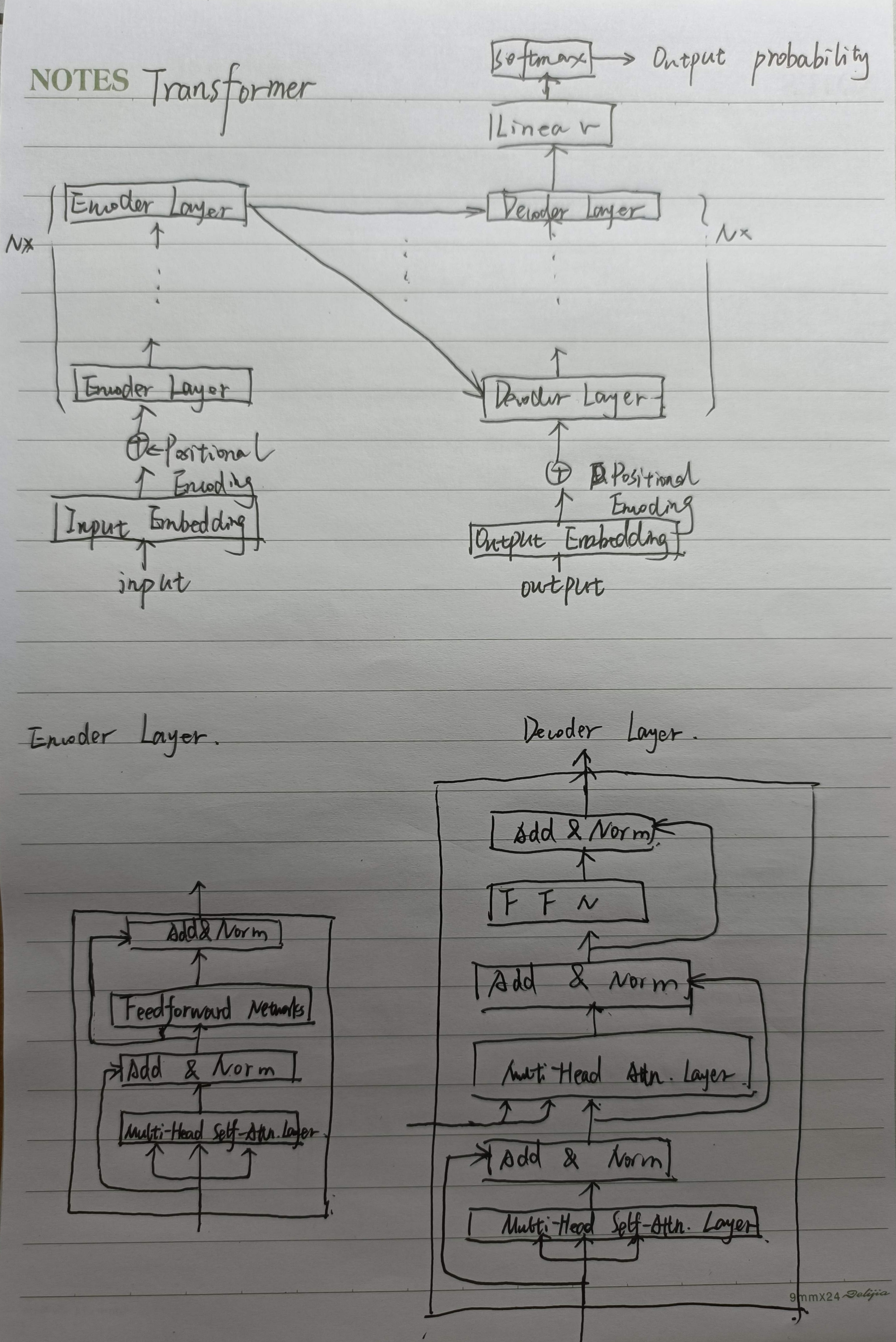
Transformer
Transformer在那里做了权重共享,为什么可以做权重共享?好处是什么?
- Input Embedding 和 Output Embedding 共享
- Decoder中Embedding层和FC层权重共享
Transformer的点积模型做缩放(Scaled)的原因是什么?
论文中的解释:向量的点积结果会很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。
假设Query和Key向量中的元素都是相互独立的,均值为0方差为1的随机变量,那么两个向量的内积\(q^Tk=\Sigma_{i=1}^{d_k}q_ik_i\)的均值为0,而方差为\(d_k\)。所以scale除以\(\sqrt{d_k}\)使得其方差变为1,这样就可以使其他得分小的不至于为0,为0的话参数就无法更新了。
当\(d_k\)(k的维度)较大时,很有可能存在\(Q\)与\(KT\)计算出的注意力分数远远大于Q与其他\(K^T\)计算出来的注意力分数,这就导致了softmax函数对大部分\(QK^T\)的偏导数为0,模型误差反向传播经过softmax函数后无法继续传播到模型前面部分的参数上,造成这些参数无法得到更新,最终影响模型的训练效率。
为什么用乘法计算注意力,而不用传统的加法?
作者说是为了使计算更快。因为虽然矩阵加法的计算更简单,但Add公式里套着\(tanh\)和\(v\),相当于一个完整的隐层。在整体计算复杂度上加法和乘法接近,但矩阵乘法已经有了非常成熟的加速实现。
为什么加法不需要用scaled?
因为当\(d_k\)较大时,很可能存在一组\(QK\)计算出的注意力权重远大于其他组,导致softmax对其他组的偏导数为0,使得这些参数无法得到更新,最终影响模型的训练效率。
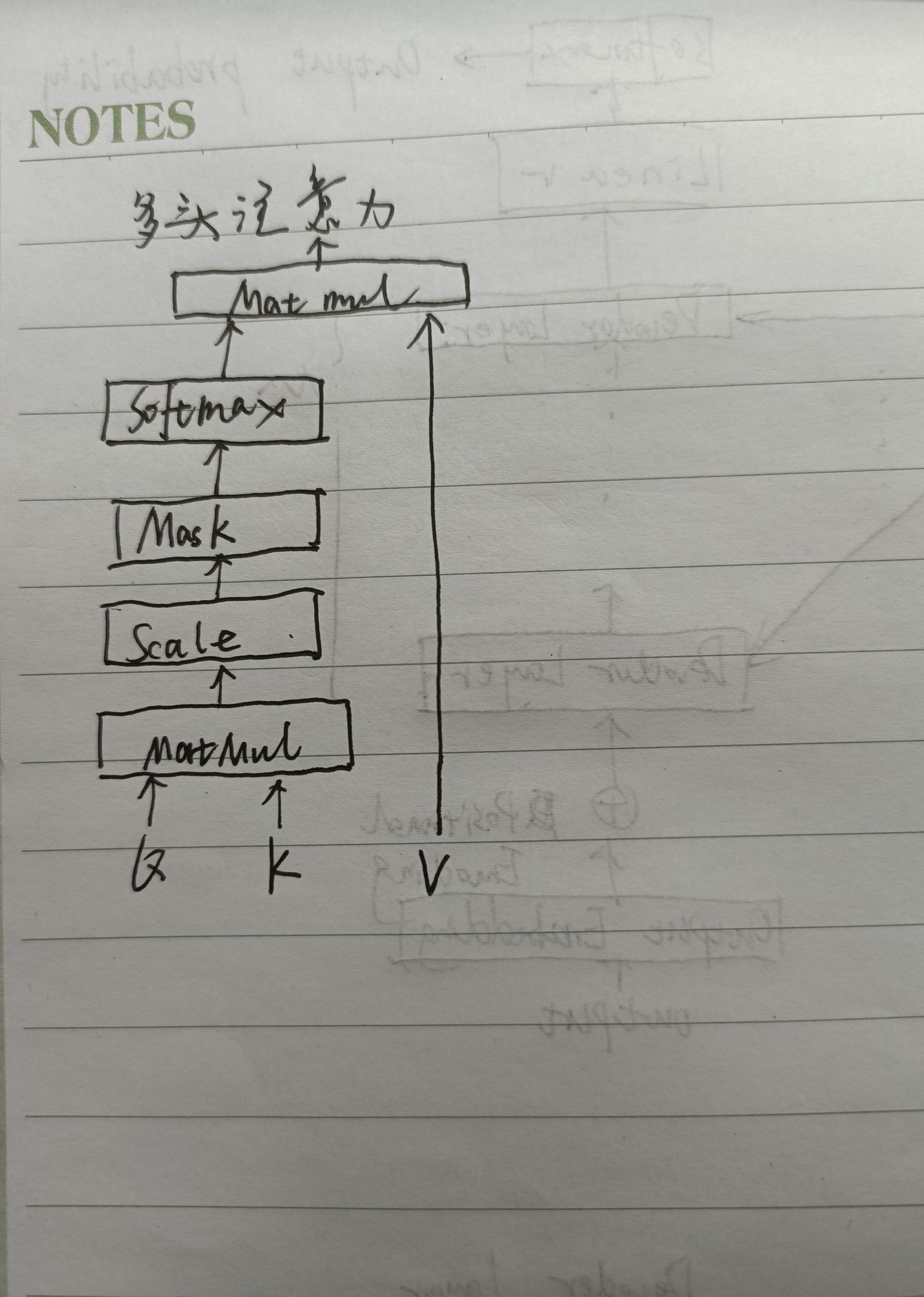
Transformer中是怎么做multi head attention 的,这样做multi head attention,会增加它的时间复杂度嘛?
Q1:怎么做的?
A: 把输入映射为多组QKV矩阵,每组分别计算注意力,再将每组的结果concat起来。
Q2:会增加时间复杂度吗?
A: 不会。Self—Attn的时间复杂度为: \(O(n^2 \cdot d)\), 这里,\(n\)是序列长度,\(d\)是Embedding的维度。
Sef-Attn包括三个步骤:相似度计算,Softmax和加权平均。它们的时间复杂度是:
相似度计算可以看作大小为(n,d)和(d,n)的两个矩阵相乘:\((n,d)\times (d,n)=O(n^2\cdot d)\),得到一个(n,n)的矩阵。
softmax的时间复杂度为\(O(n^2\cdot d)\)。
加权平均的每一项可以看作大小为(n,n)和(n,d)的两个矩阵相乘: \((n,n)\times(n,d)=O(n^2\cdot d)\)
所以,自注意力总的时间复杂度为\(O(n^2 \cdot d)\)。
而多头并不是循环计算每个头,而是通过transpose and reshapes(即经过矩阵矩阵的变换),再用矩阵乘法来完成的。
原本(n,d)的输入,经过矩阵变换,拆解成维度为(n,h,a)的的矩阵,\(h\)为头的数量,\(a\)为每个头输入的维度,再调整n和h的顺序得到(h,n,a)的矩阵作为每个头的输入。
这样,两个矩阵相乘\((h,n,a)\times(h,a,n)\)可以看做是两个小矩阵相乘\((n,a)\times(a,n)\)做\(h\)词,所以时间复杂度为\(O(n^2\cdot h)=O(n^2\cdot d)\)。
所以多头注意力不会增加时间复杂度。
不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
Self-Attn的核心是用文本中的其他词来增强目标词的语义表示,从而更好地利用上下文的信息。
Self-Attention中,Sequence中的每个词都会和Sequence的每个词做点乘积去计算相似度,也包括这个词本身。
对于self-attention,q=k=v, 这里的相等实际上指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了QKV参数矩阵的。如果不乘,则每个此对应的qkv完全一样。
在相同量级的情况下,\(q_i\)与\(k_i\)点积的值回事最大的,在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法利用上下文信息来增强当前词的语义表示。
而乘QKV参数矩阵,会使得每个词的qkv不一样,这能很大程度上减轻上述影响。
当然,qkv参数矩阵也使得多头可以捕捉更丰富的特征。
为什么Transformer 要做 Multi-head Attention? 它的好处在哪?
Transformer使用多头注意力,将模型分为多个头,形成多个子空间,每个头关注不同方面的信息。
但最近一些研究表明注意力头不是越多越好,去掉一些头效果依然有不错的效果,这表明原论文中的Transformer模型在特定任务上使用8个头是有冗余的。在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息等的能力了,再多一些头,无非是一种enhance或者冗余而已。
Transformer的Encoder端和Decoder端是如何进行交互的?和一般的seq2seq有什么差别?
Encoder编码生成中间向量,该中间向量将会作为K和V,与每一层Decoder层计算注意力。
Transformer中multi-head attention中每个head为什么要进行降维?
在不增加时间复杂度的情况下,同时,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。