
MiniOB Lab4: join tables & group by
MiniOB Lab4: join tables & aggregation with group by
本次实验感觉挺难的,主要是需要了解的部分很多,理论又非常抽象,高度凝练的抽象与工程上的细节形成特别强烈的对比,很容易在工程的细节中迷失。这份记录希望能够帮助我理清楚相关的思路,虽然我到现在也还没有完全理解在执行过程中,miniob究竟做了什么。
Part I: Nested Loop Join
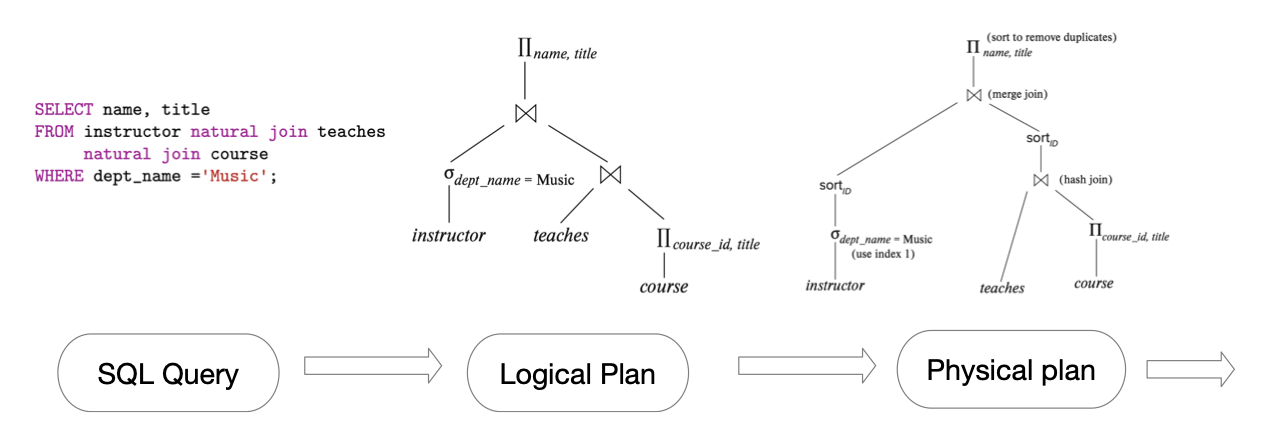
在这一部分我们首先需要完成的是最为简单的一种join的方式。我们先介绍一下查询的流程。我们将通过以下的SQL进行演示。
select * from join_table_1 inner join join_table_2 on join_table_1.id=join_table_2.id;
Query Processing
首先,对于SQL语句,经过Parse部分后,我们需要对算子和表达式进行Logical Plan,在将我们的算子进行逻辑计划后,优化形成控制流,最后转换成实际的物理执行计划。在写入结果时,数据从树的底部开始向上流动,根据物理算子进行操作,最后在树的根部获得结果。
这里,MiniOB采用的是火山模型。并不会实际地存储中间运算的结果,而是将中间运算结果层层往上传递直到树根。
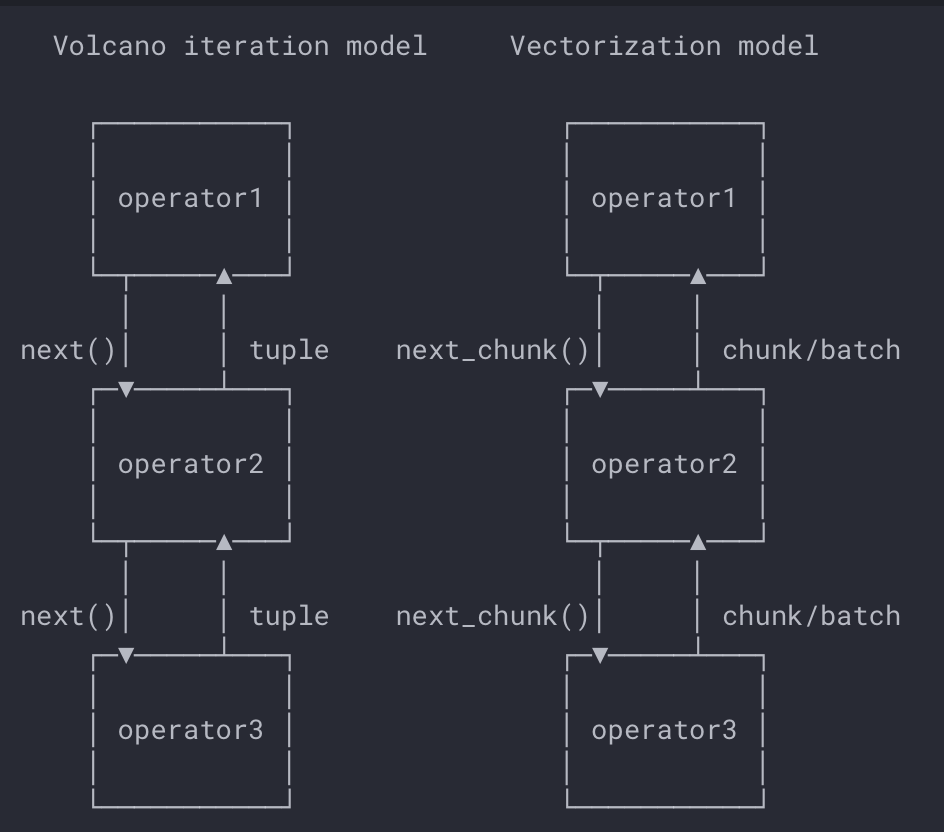
接下来首先关注Logical plan。
Logical Plan
执行完语法分析后,sql将形成一个个sql_node,为后面的logical plan做好准备工作。在src/observer/net/sql_task_handler.cpp中,我们将在rc = optimize_stage_.handle_request(sql_event);中进入到逻辑树生成部分。
生成部分仍然是自上而下递归进行的。首先生成的逻辑操作,位于树根的就是我们的SELECT操作。因此我们将进入到select中继续向下生成逻辑树。
在进入到了select重载的Logical Plan中,我们将会检查有多少个Table节点。如果发现了多个Table节点,则意味着我们需要进行JOIN操作,因此生成join逻辑运算节点,将两个图节点加载到join的左右子节点下方。
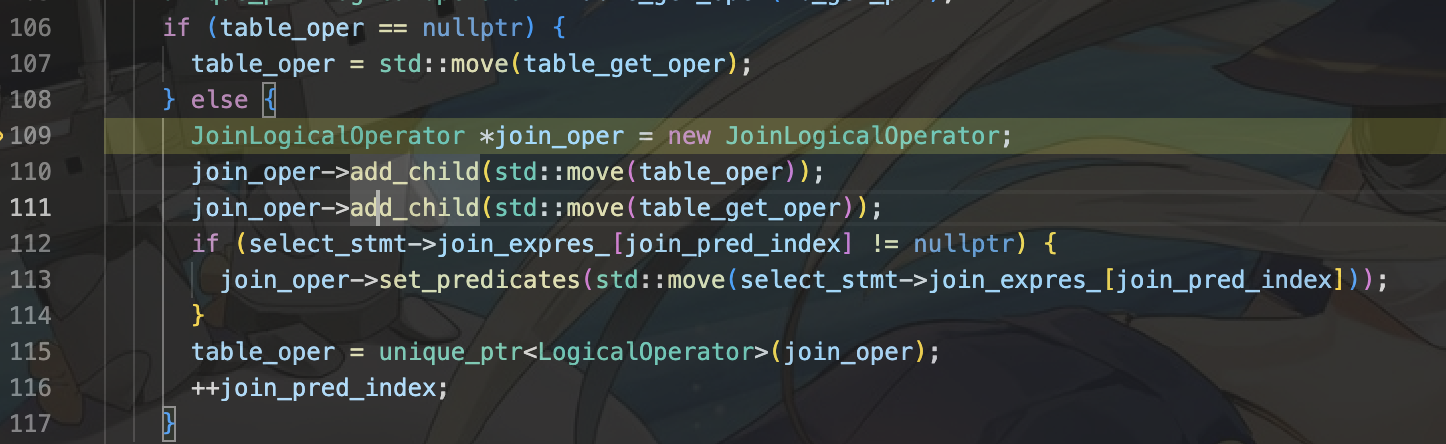
随后判断是否具有谓词条件ON。如果有则设置。这在上图中的if中也可以看见。
随后select将判断是否还有剩余谓词和子查询。这里我们均没有出现,我们也将跳过。这样我们就生成了一个简单的逻辑谓词树。
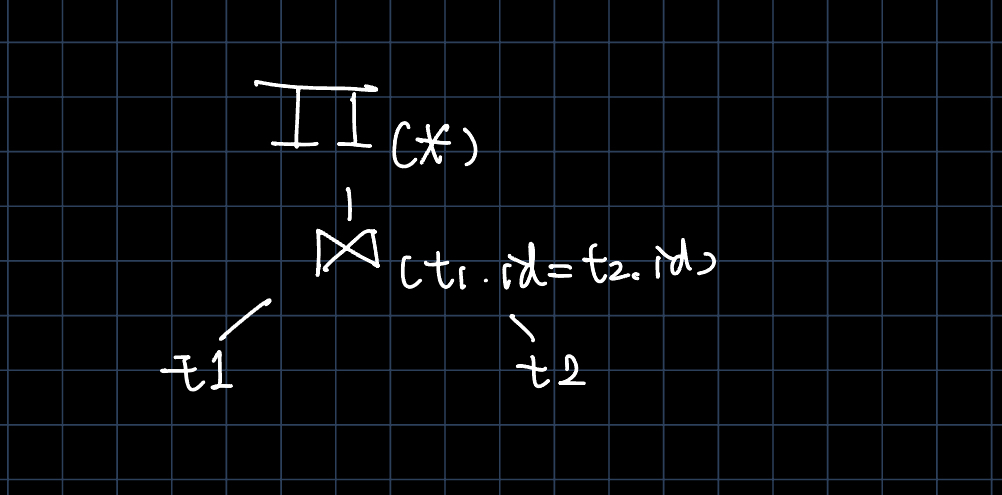
Physical Plan
在经过优化后,我们将进入到物理计划生成部分。在这一部分中,如果我们已经部署了PAX存储结构和向量化处理方式,就可以采用向量化执行。但是这对于作业来说过于复杂,因此我们还是通过row存模式,一个一个tuple进行解决。这里我们将生成实际执行的算子。我们将依次进入 PROJECTION -> JOIN -> TABLE_GET 创建计划。



在每个计划中,我们将获得子节点。并递归式地创建计划,直到树的叶子节点。需要特别注意的是JOIN中的谓词和SQL语句中的谓词有着区别。一个是连接条件,一个是最终的筛选条件。因此我们文件中的predicate_*_.cpp/h不对JOIN语句产生作用,而是对SELECT产生作用。
这样我们形成的物理算子树:

自下而上数据的流动
我们在写入结果时才真正开始执行操作,如下图所示。

首先,我们需要自上而下打开算子。忽略掉网络通信算子,第一个打开的是projection算子,其次是nestedLoopJoin算子。
回想一下我们的物理算子,我们的物理算子有RESULT -> PROJECT -> NLJoin -> TABLE_GET。
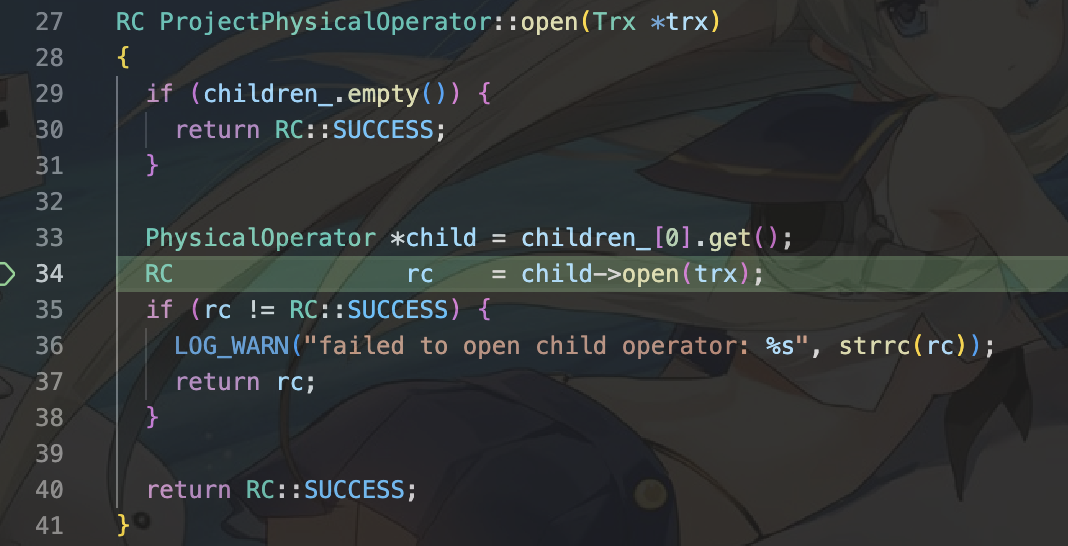
这样,我们在NLJ算子中就需要:
- 获得子节点的两个算子。
- 打开左表节点算子。
为什么不在NLJ算子中就打开右表节点?因为右表需要反复进行遍历。每一个left_tuple需要在遍历整个右表后才进入到下一个tuple。而从头遍历需要调用close,这样我们最好让右表遍历函数拥有对于右表的打开和关闭权限。否则很容易造成未定义行为(例如反复打开右表等)。
这样我们有:
RC NestedLoopJoinPhysicalOperator::open(Trx *trx) {
if (children_.size() != 2) {
return RC::INTERNAL;
}
RC rc = RC::SUCCESS;
left_ = children_[0].get();
right_ = children_[1].get();
right_closed_ = true;
round_done_ = true;
rc = left_->open(trx);
trx_ = trx;
return rc;
}
接下来我们进入到write_tuple_result。在这里,一个个tuple将自下而上传递,逐步完成物理算子操作。在next函数中递归进行控制,结果自下而上返回。
对于我们的NLJ操作,我们具有predicate谓词,也就是我们的ON子句。在这里,我们需要增加一个filter函数来过滤掉不符合我们的要求的tuple。
首先我们在头文件里增加:
private:
RC left_next(); //! 左表遍历下一条数据
RC right_next(); //! 右表遍历下一条数据,如果上一轮结束了就重新开始新的一轮
bool find_position(TupleSchema* schemas, TupleCellSpec& spec, int& index);
bool filter(); //! 过滤掉不符合条件的Descartes结果。
接下来我们需要完成双循环遍历的情况。我们可以注意到在头文件中的注释,告诉我们非常重要的部分:round_done_和right_closed_,以及finished。
首先我们需要思考双循环。我们有基础算法的伪代码如下:

- 整理我们的思路。
- 首先判断有没有获得left_tuple,也就是开始进入循环。进入到左节点的next获取一个tuple。
- 接着进入到右节点获得一个tuple,直到右节点返回EOF。
- 右节点返回EOF后,需要通过round_done_来表明右表一次遍历已经完成。同时通过关闭算子和打开算子的方式,将右节点设置到表的起点重新遍历。
- 每次获得左边tuple和右边tuple后,需要判断是否保留该tuple。最简单的方式是不让next函数返回,这样中间值将会被下次迭代的结果替换。所以通过loop的方式来控制循环是否停止。停止则代表保留结果,写入sql_result。否则将不会停止,由新的结果来替换旧的结果。
RC NestedLoopJoinPhysicalOperator::next() {
if (finished) {
return RC::RECORD_EOF;
}
RC rc;
bool loop = true;
while (loop) {
// 第一次开始,首先需要获得一个左表的tuple。
if (left_tuple_ == nullptr) {
rc = left_next();
if (rc != RC::SUCCESS) {
// 左表为空的时候结束。
finished = true;
return rc;
}
rc = right_next();
if (rc != RC::SUCCESS) {
// 右表为空的时候结束。(说明右表为空表)。
finished = true;
return RC::RECORD_EOF;
}
} else {
// 左表不变,获取新的右表tuple。
rc = right_next();
if (rc != RC::SUCCESS) {
// 右表一遍遍历完成,换一个新的左表tuple。
rc = left_next();
if (rc != RC::SUCCESS) {
finished = true;
return RC::RECORD_EOF;
}
// 右表从头开始遍历。
if (RC::SUCCESS != right_next()) {
finished = true;
return RC::RECORD_EOF;
}
}
}
// 过滤我们的tuple。
loop = filter();
}
return RC::SUCCESS;
}
RC NestedLoopJoinPhysicalOperator::left_next() {
// 正常地获取一个tuple。
RC rc = RC::SUCCESS;
rc = left_->next();
if (rc != RC::SUCCESS) {
return rc;
}
left_tuple_ = left_->current_tuple();
joined_tuple_.set_left(left_tuple_);
return rc;
}
RC NestedLoopJoinPhysicalOperator::right_next() {
RC rc = RC::SUCCESS;
// 一轮是否已经结束?
if (round_done_) {
// 一轮结束,关闭右表。
if (!right_closed_) {
rc = right_->close();
right_closed_ = true;
if (rc != RC::SUCCESS) {
return rc;
}
}
// 重新打开右表,相当于回到起点。
rc = right_->open(trx_);
if (rc != RC::SUCCESS) {
return rc;
}
right_closed_ = false;
round_done_ = false;
}
// 获得右表的一个tuple。
rc = right_->next();
if (rc != RC::SUCCESS) {
// 当到达右表结尾时,返回EOF给上层next算子。
if (rc == RC::RECORD_EOF) {
round_done_ = true;
}
return rc;
}
// 拼接右表。
right_tuple_ = right_->current_tuple();
joined_tuple_.set_right(right_tuple_);
return rc;
}
接下来就是filter部分。这一部分比较复杂,我们一步步地来了解。
predicates_
我们的predicates_是联结表达式,在expression.h中有这样的定义:
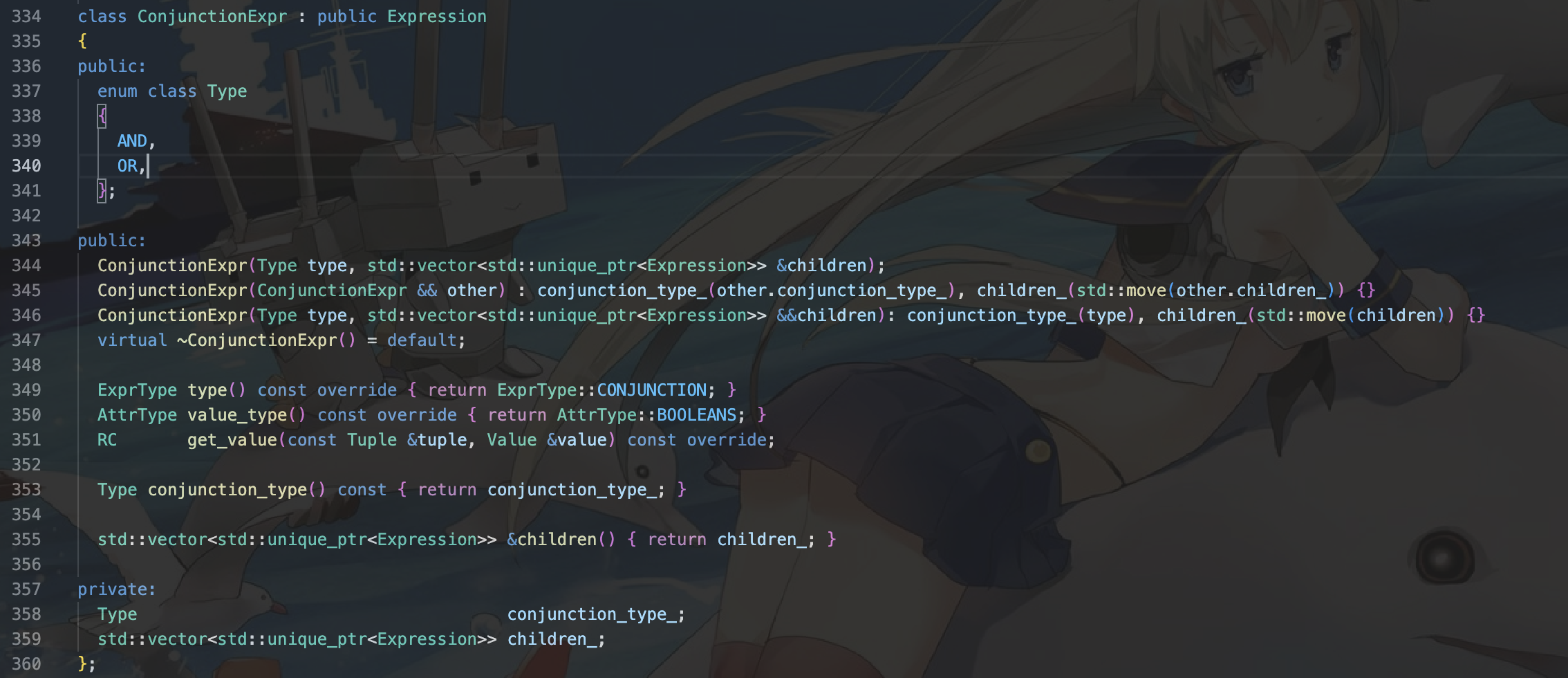
MINIOB里的表达式有哪些类型?
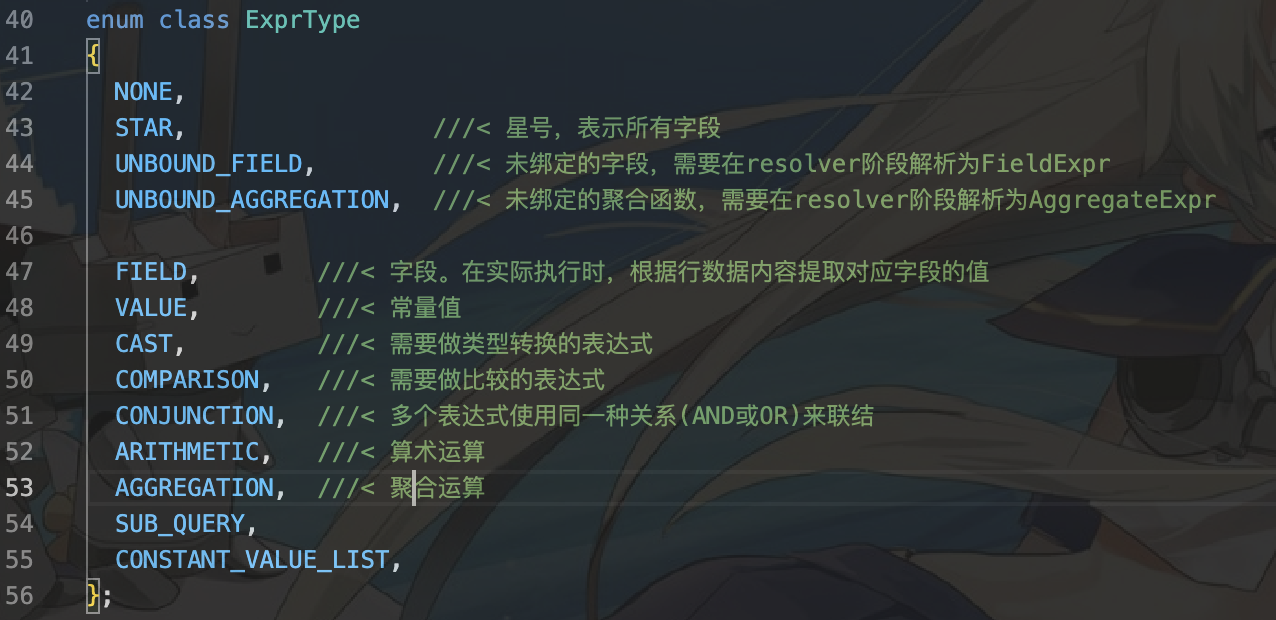
这样子表达式就应该是比较表达式。我们需要从连结表达式中获得子表达式,子表达式为比较表达式。比较表达式比较长,这里就通过代码块的形式展示。
/**
* @brief 比较表达式
* @ingroup Expression
*/
class ComparisonExpr : public Expression
{
public:
ComparisonExpr(CompOp comp, std::unique_ptr<Expression> left, std::unique_ptr<Expression> right);
virtual ~ComparisonExpr();
ExprType type() const override { return ExprType::COMPARISON; }
RC get_value(const Tuple &tuple, Value &value) const override;
AttrType value_type() const override { return AttrType::BOOLEANS; }
CompOp comp() const { return comp_; }
/**
* @brief 根据 ComparisonExpr 获得 `select` 结果。
* select 的长度与chunk 的行数相同,表示每一行在ComparisonExpr 计算后是否会被输出。
*/
RC eval(Chunk &chunk, std::vector<uint8_t> &select) override;
std::unique_ptr<Expression> &left() { return left_; }
std::unique_ptr<Expression> &right() { return right_; }
/**
* 尝试在没有tuple的情况下获取当前表达式的值
* 在优化的时候,可能会使用到
*/
RC try_get_value(Value &value) const override;
/**
* compare the two tuple cells
* @param value the result of comparison
*/
RC compare_value(const Value &left, const Value &right, bool &value) const;
template <typename T>
RC compare_column(const Column &left, const Column &right, std::vector<uint8_t> &result) const;
private:
CompOp comp_;
std::unique_ptr<Expression> left_;
std::unique_ptr<Expression> right_;
};
我们需要通过获取比较表达式,对left和right部分进行比较后,判断当前的join_tuples_是否符合条件,然后得到我们的结果。
- Q1: 会出现什么情况呢?
我们举出的例子有:
select * from join_table_1 inner join join_table_2 on join_table_1.id=join_table_2.id;
select * from join_table_1 inner join join_table_2 on join_table_1.id=1;
select * from join_table_1 inner join join_table_2 on 1=join_table_2.id;
select * from join_table_1 inner join join_table_2 on 1=1;
我们发现,比较表达式的左右子表达式有以上四种情况:
- 左右表达式为field表达式。这两边需要从tuple中获取对应域的值进行比较。
- 左右表达式一个为field表达式,一个为Value表达式。从Value表达式中获取值,与对应的tuple中的域值进行比较。
- 左右表达式均为Value表达式。
接下来我们需要了解怎么获取对应的索引,以及从tuple中获取对应的域值。这里我们通过find_position找到在tuple中对应的index。在函数签名中我们看到,我们也需要寻找到schema(格式信息),以及tupleCellSpec的相关信息。这里虽然不太知道这是干什么的,但是通过结构体中我们可以发现,这是记录 表名,域名和别名的结构体。因此我们需要从field表达式中获取域名和表名。field表达式,就是我们的table.field部分,他们与=共同构成了比较表达式,并绑定在join算子上。
bool NestedLoopJoinPhysicalOperator::find_position(TupleSchema *schemas,
TupleCellSpec &spec,
int &index)

同样,我们也有可能会出现一个不正常脑回路意外的查询,交换了左右表。例如:
select * from join_table_1 inner join join_table_2 on join_table_2.id=join_table_1.id;
这样就会导致find_position在只查询左表格式和左表对应tuple时失败。因此我们需要判断find_position是否恒真。否则反过来查询就可以了。
最后,通过比较表达式的compare_value来判断是否需要写入该结果 (也就是让next跳出循环返回)。在我们的循环条件中,loop为假时写入结果。因此当我们的比较值为真时,返回false。否则返回true,不写入结果。这样我们就有:
bool NestedLoopJoinPhysicalOperator::filter() {
bool ans = false;
// 要判断有没有on,否则会出现错误。
if (predicates_ == nullptr) {
return ans;
}
for (auto &pred : predicates_->children()) {
// 获得联结表达式下的比较表达式。
ComparisonExpr *cmp_pred = static_cast<ComparisonExpr *>(pred.get());
std::unique_ptr<Expression> &left = cmp_pred->left();
std::unique_ptr<Expression> &right = cmp_pred->right();
bool result = false;
Value left_val, right_val;
// 判断:是域表达式还是值表达式?随后根据情况比较。
if (left->type() == ExprType::FIELD && right->type() == ExprType::FIELD) {
FieldExpr *left_field = static_cast<FieldExpr *>(left.get());
FieldExpr *right_field = static_cast<FieldExpr *>(right.get());
const char *left_table_name, *left_field_name, *right_table_name,
*right_field_name;
left_table_name = left_field->field().table_name();
left_field_name = left_field->field().field_name();
right_table_name = right_field->field().table_name();
right_field_name = right_field->field().field_name();
TupleCellSpec left_tup(left_table_name, left_field_name);
TupleCellSpec right_tup(right_table_name, right_field_name);
int left_index = 0, right_index = 0;
TupleSchema *left_schema = left_->schema();
TupleSchema *right_schema = right_->schema();
// 根据元数据信息取出对应Value进行比较。
if (!find_position(left_schema, left_tup, left_index)) {
find_position(right_schema, left_tup, left_index);
find_position(left_schema, right_tup, right_index);
joined_tuple_.left_tuple()->cell_at(right_index, right_val);
joined_tuple_.right_tuple()->cell_at(left_index, left_val);
} else {
joined_tuple_.left_tuple()->cell_at(left_index, left_val);
joined_tuple_.right_tuple()->find_cell(right_tup, right_val);
}
} else if (left->type() == ExprType::FIELD &&
right->type() == ExprType::VALUE) {
int index = 0;
FieldExpr *left_field = static_cast<FieldExpr *>(left.get());
const char *table_name, *field_name;
table_name = left_field->field().table_name();
field_name = left_field->field().field_name();
TupleCellSpec tuple(table_name, field_name);
TupleSchema *schema = left_->schema();
if (!find_position(schema, tuple, index)) {
schema = right_->schema();
find_position(schema, tuple, index);
joined_tuple_.right_tuple()->cell_at(index, left_val);
} else {
joined_tuple_.left_tuple()->cell_at(index, left_val);
}
static_cast<ValueExpr *>(right.get())->get_value(right_val);
} else if (left->type() == ExprType::VALUE &&
right->type() == ExprType::FIELD) {
int index = 0;
FieldExpr *right_field = static_cast<FieldExpr *>(right.get());
const char *table_name, *field_name;
table_name = right_field->field().table_name();
field_name = right_field->field().field_name();
TupleCellSpec tuple(table_name, field_name);
TupleSchema *schema = left_->schema();
if (!find_position(schema, tuple, index)) {
schema = right_->schema();
find_position(schema, tuple, index);
joined_tuple_.right_tuple()->cell_at(index, left_val);
} else {
joined_tuple_.left_tuple()->cell_at(index, left_val);
}
static_cast<ValueExpr *>(left.get())->get_value(right_val);
} else {
auto left_val_expr = static_cast<ValueExpr *>(left.get());
auto right_val_expr = static_cast<ValueExpr *>(right.get());
left_val_expr->get_value(left_val);
right_val_expr->get_value(right_val);
}
cmp_pred->compare_value(left_val, right_val, result);
// 注意!结果不相等时返回true,不让该tuple写入。
if (!result) {
ans = true;
break;
}
}
return ans;
}
这样Lab1的部分就完成了。
Part II: Aggrregate & group by
我们首先看一下我们的explain,了解一下过程。

同样地,首先我们需要进入到logical plan中。在这里,我们的relation只有一个,因此不会出现join算子。接下来,我们需要进入到group by逻辑算子中生成logical plan。
在group by的逻辑生成过程中,我们将会解析group by对象,having 子句,聚合表达式,以及子查询。随后将他们检查并进行绑定。

在hash_group_by中,我们的执行步骤如同手册上所说:

这样我们需要补充的部分就是:1. 获取group by后得到的复合tuple。2. 根据having子句进行筛选。(我们可以启用被注释掉的filter函数)。这样我们就有:
RC HashGroupByPhysicalOperator::open(Trx *trx)
{
if (always_false) {
return RC::SUCCESS;
}
ASSERT(children_.size() == 1, "group by operator only support one child, but got %d", children_.size());
PhysicalOperator &child = *children_[0];
RC rc = child.open(trx);
if (OB_FAIL(rc)) {
LOG_INFO("failed to open child operator. rc=%s", strrc(rc));
return rc;
}
ExpressionTuple<Expression *> group_value_expression_tuple(value_expressions_);
ValueListTuple group_by_evaluated_tuple;
while (OB_SUCC(rc = child.next())) {
Tuple *child_tuple = child.current_tuple();
if (nullptr == child_tuple) {
LOG_WARN("failed to get tuple from child operator. rc=%s", strrc(rc));
return RC::INTERNAL;
}
// 找到对应的group
GroupType *found_group = nullptr;
rc = find_group(*child_tuple, found_group);
if (OB_FAIL(rc)) {
LOG_WARN("failed to find group. rc=%s", strrc(rc));
return rc;
}
// 计算需要做聚合的值
group_value_expression_tuple.set_tuple(child_tuple);
// 计算聚合值
GroupValueType &group_value = get<1>(*found_group);
rc = aggregate(get<0>(group_value), group_value_expression_tuple);
if (OB_FAIL(rc)) {
LOG_WARN("failed to aggregate values. rc=%s", strrc(rc));
return rc;
}
}
if (RC::RECORD_EOF == rc) {
rc = RC::SUCCESS;
}
if (OB_FAIL(rc)) {
LOG_WARN("failed to get next tuple. rc=%s", strrc(rc));
return rc;
}
// 得到最终聚合后的值
for (GroupType &group : groups_) {
GroupValueType &group_value = get<1>(group);
rc = evaluate(group_value);
if (OB_FAIL(rc)) {
LOG_WARN("failed to evaluate group value. rc=%s", strrc(rc));
return rc;
}
// 这里开始!首先我们需要获得聚合(evaluate)后的值。这里可以阅读group by内的实现。
CompositeTuple& tuple = get<1>(group_value);
bool result = false;
rc = filter(tuple, result);
if (rc != RC::SUCCESS) {
LOG_TRACE("record filtered failed=%s", strrc(rc));
return rc;
}
if (result)
results_.emplace_back(std::move(group));
}
groups_.swap(results_);
current_group_ = groups_.begin();
first_emited_ = false;
return rc;
}
这里我们需要补充std::get函数。这是一个从tuple中获取对应类型/对应index的元素的函数。在这里,我们的GroupValueType是一个元组。我们有:
using GroupValueType = std::tuple<AggregatorList, CompositeTuple>;
这样我们可以通过std::get<1>来获取CompositeTuple。自C++14起,我们也可以通过std::get<CompositeTuple>来获取我们的复合tuple。接下来不要忘记通过having子句进行过滤。这里的having子句和predicate子句的next操作几乎完全相同,都是对其他算子得到的结果进行筛选。直接对着抄就好。
RC HashGroupByPhysicalOperator::filter(CompositeTuple &tuple, bool &result)
{
RC rc = RC::SUCCESS;
Value value;
// 根据having子句中的值进行筛选。
for (unique_ptr<Expression> &expr : havings_) {
rc = expr->get_value(tuple, value);
if (rc != RC::SUCCESS) {
return rc;
}
bool tmp_result = value.get_boolean();
if (!tmp_result) {
result = false;
return rc;
}
}
result = true;
return rc;
}
这样就完成了我们的having子句。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号