
MiniOB Lab3
Lab3 PAX Storage and Aggregation function
这是一份对Lab3的实验总结报告。(基于OceanBase库)
Part-1 PAX Storage model
工欲善其事,必先利其器
为了方便我们进行debug,首先我们先对vscode中的launch.json进行修改。
在.vscode中将会有task.json,该文件的作用是在debug线程开始前执行build工作。我们需要记住其label。
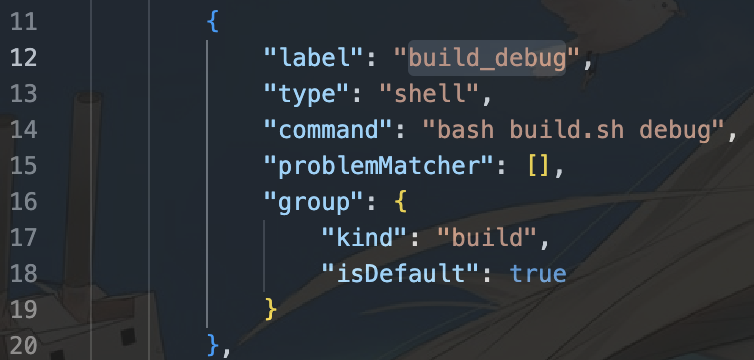
接着,针对我们需要进行的单元测试文件build_debug/bin/pax_storage_test,编写针对它的launch.json。编写的部分如下:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
// ... 前面不改变。
{
"type": "cppdbg",
"request": "launch",
"name": "test PAX",
"program": "${workspaceFolder}/${defaultBuildTask}/bin/pax_storage_test",
"args": [],
"cwd": "${workspaceFolder}/${defaultBuildTask}/",
"internalConsoleOptions": "openOnSessionStart",
"osx": {
"MIMode": "lldb",
"externalConsole":true
},
// 这一部分让我们可以更好地查看STL容器中的东西。
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"preLaunchTask": "build_debug" // 每次修改前都进行build。
},
]
}
这样我们就可以进行debug操作了。debug的断点可以设置在unittest/observer/pax_storage_test.cpp中。
PAX storage model
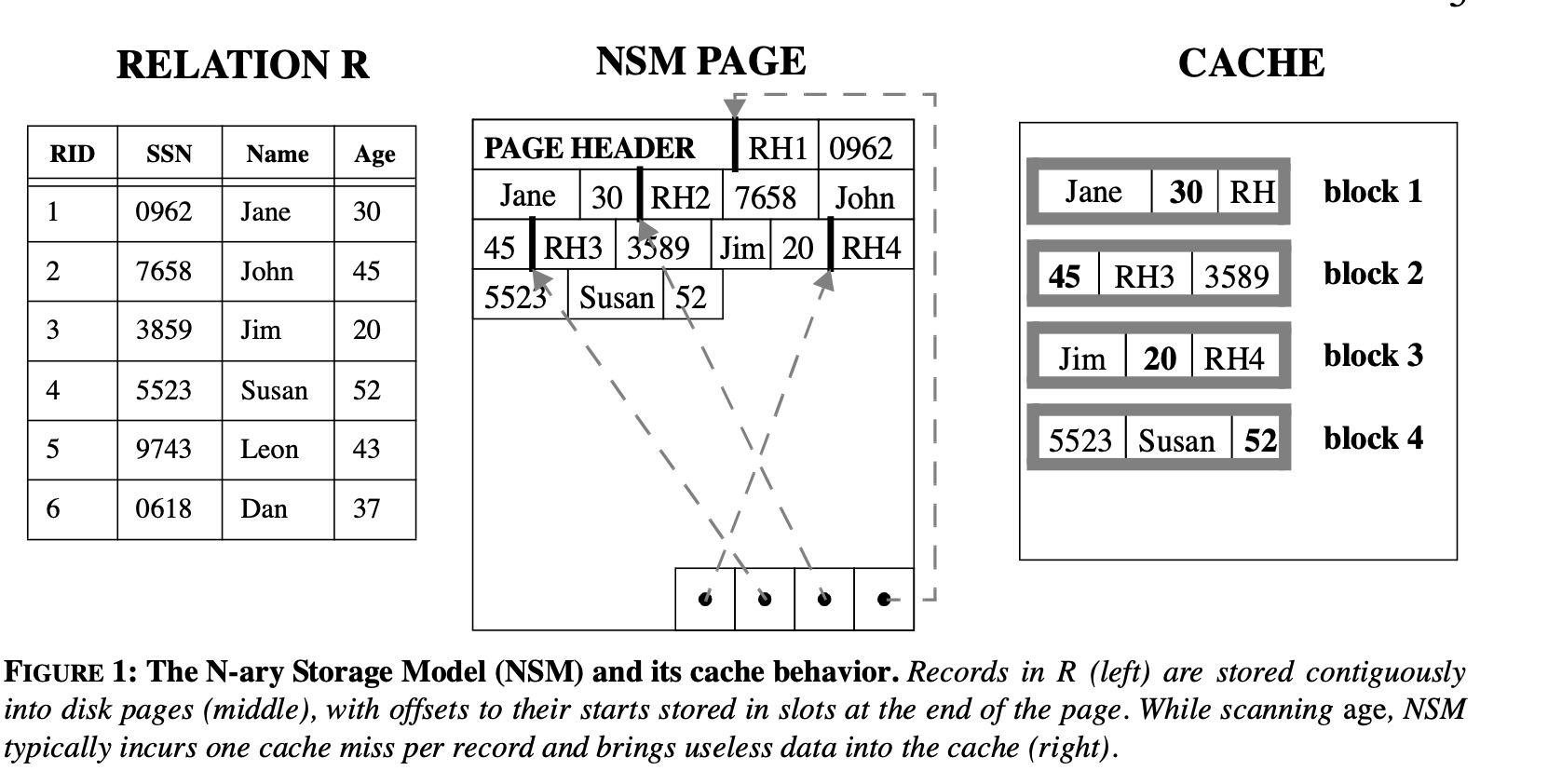
常用的数据库存储结构主要有以下三种:N-ary 存储模型,分解存储模型和PAX存储模型。
N-ary 存储模型
我们直接将Cache中的记录一个一个直接存入实际的物理页中。
Decomposition(分解模型) 存储模型
将表按列拆分,形成主码+一列数据,将子关系模型分别存储到实际的物理页中。

PAX 存储模型
将一个record拆分成多个部分分别放入不同的小页中。
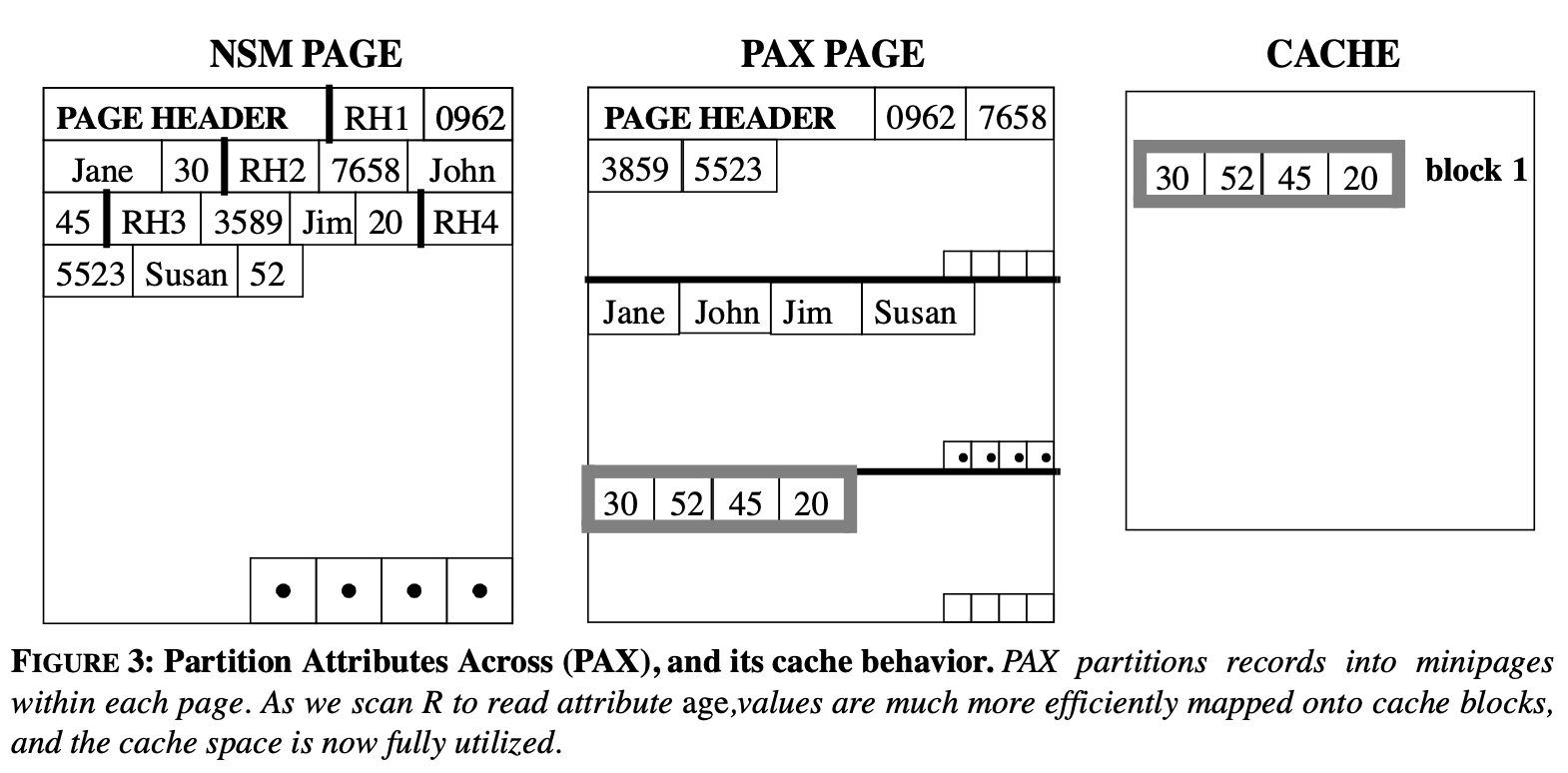
实验过程
根据PAX的储存架构,结合阅读我们发现以下几个重要的点:
-
在PAX数据页的储存结构中,将会由帧元数据(记录了有关页的信息与页和文件相关关联信息),页头信息(记录了当前页面的格式信息),位图(记录了记录是否存在于页面当中,以及提供记录的索引信息),列索引(每一列的结尾的偏移或地址)。
-
在定长的PAX存储结构中,每一列都具有自己的定长。这里我们可以从
field中来获取它们。我们可以观察到两个函数(非常有用!!!):
// get the field data by `slot_num` and `column id`
char *get_field_data(SlotNum slot_num, int col_id);
// get the field length by `column id`, all columns are fixed length.
int get_field_len(int col_id);
Insert_record
结合上述的观察我们可以得知,进行数据的插入工作时,我们需要进行如下的处理:
- 获取PAX存储结构中的每一列规定的定长(field length)。
- 根据不同列的不同定长,将record进行拆分。
- 通过bitmap获取我们的记录索引。
- 根据当前record的索引,判断应该插入数据的偏移。并将数据copy到该区域内。
Answer:
RC PaxRecordPageHandler::insert_record(const char *data, RID *rid)
{
// your code here
// 权限管理!不能插入只读页面。
ASSERT(rw_mode_ != ReadWriteMode::READ_ONLY,
"cannot insert record into page while the page is readonly");
// 判断页面是否已满。
if (page_header_->record_num == page_header_->record_capacity) {
LOG_WARN("Page is full, page_num %d:%d.", disk_buffer_pool_->file_desc(), frame_->page_num());
return RC::RECORD_NOMEM;
}
// Find empty location.
// 从 bitmap 中获取页面索引。
Bitmap bitmap(bitmap_, page_header_->record_capacity);
int bitmapIndex = bitmap.next_unsetted_bit(0);
ASSERT(bitmapIndex >= 0, "The bit_map index smaller than 0!\n");
bitmap.set_bit(bitmapIndex);
page_header_->record_num++;
// The RC dealing with problems.
// 更新log。log是缓存系统的重要部份。
RC rc = log_handler_.insert_record(frame_, RID(get_page_num(), bitmapIndex), data);
if (OB_FAIL(rc)) {
LOG_ERROR("Failed to insert record. page_num %d:%d. rc=%s", disk_buffer_pool_->file_desc(), frame_->page_num(), strrc(rc));
// return rc; // ignore errors
}
int data_offset = 0;
for(int col_id = 0; col_id < page_header_ -> column_num; col_id++) {
const int field_len = get_field_len(col_id);
const char *current_data = data + data_offset;
data_offset += field_len;
char *target = get_field_data(bitmapIndex, col_id);
memcpy(target, current_data, field_len);
}
frame_->mark_dirty();
if (rid) {
rid->page_num = get_page_num();
rid->slot_num = bitmapIndex;
}
// LOG_TRACE("Insert record. rid page_num=%d, slot num=%d", get_page_num(), index);
return RC::SUCCESS;
// exit(-1);
}
一些总结的废话(可以直接跳过不看)
- 我们通过判断该页中预先规定具有多少列,并依次利用
get_field_len来获取该页中的定长。我们获取页长的方式也很简单。虽然题目已经写好了,但其实我们也可以自己写出来。 - 首先观察结构
PageHeader.
struct PageHeader
{
int32_t record_num; ///< 当前页面记录的个数
int32_t column_num; ///< 当前页面记录所包含的列数
int32_t record_real_size; ///< 每条记录的实际大小
int32_t record_size; ///< 每条记录占用实际空间大小(可能对齐)
int32_t record_capacity; ///< 最大记录个数
int32_t col_idx_offset; ///< 列索引偏移量
int32_t data_offset; ///< 第一条记录的偏移量
string to_string() const;
};
- 在页头结构中,我们发现了record的最大容量,每条record的大小,列索引的偏移以及存储的开始位置。存储的开始位置也就是column1的开头。所以我们每个
col_id=0时都应该进行特判。 - 接下来注意阅读
init_empty_page部分。这部分十分重要,是我们完整了解整个数据页结构的最重要部份。在record_manager.cpp中,我们有两个重载的init_empty_page函数。后者直接使用列相关数据初始化,信息会有所隐藏,因此我们阅读前者。
int column_num = 0;
// only pax format need column index
if (table_meta != nullptr && storage_format_ == StorageFormat::PAX_FORMAT) {
column_num = table_meta->field_num();
}
- 上面这一部分很明显暗示我们,与table相关的元数据将储存或通过
field-*相关函数/结构体展示。
page_header_->record_num = 0;
page_header_->column_num = column_num;
page_header_->record_real_size = record_size;
page_header_->record_size = align8(record_size);
page_header_->record_capacity = page_record_capacity(
BP_PAGE_DATA_SIZE, page_header_->record_size, column_num * sizeof(int) /* other fixed size*/);
page_header_->col_idx_offset = align8(PAGE_HEADER_SIZE + page_bitmap_size(page_header_->record_capacity));
page_header_->data_offset = align8(PAGE_HEADER_SIZE + page_bitmap_size(page_header_->record_capacity)) +
column_num * sizeof(int) /* column index*/;
this->fix_record_capacity();
- 这一部分就是完善我们的页头数据。我们注意到,记录的实际大小和定长大小有所不同。进行内存对齐是很常见的操作,这样更有利于我们直接读取完整的数据,增加缓存读取的效率和解析数据的速度。在这里采用align8进行对齐。采用函数 \(\lfloor\dfrac{a+b-1}{b}\rfloor\) 计算。这里用位运算就非常有意思。
int align8(int size) {
return (size + 7) & ~7;
}
- 同样,我们可以发现,其将每一列的索引放置在frame元数据,page_header数据之后。并通过最后的修正来计算出真实的能够容纳record的数目。
// column_index[i] store the end offset of column `i` or the start offset of column `i+1`
int *column_index = reinterpret_cast<int *>(frame_->data() + page_header_->col_idx_offset);
for (int i = 0; i < column_num; ++i) {
ASSERT(i == table_meta->field(i)->field_id(), "i should be the col_id of fields[i]");
if (i == 0) {
column_index[i] = table_meta->field(i)->len() * page_header_->record_capacity;
} else {
column_index[i] = table_meta->field(i)->len() * page_header_->record_capacity + column_index[i - 1];
}
}
- 这里其实才是最重要的部分。也就是告诉我们:
- 在frame数据+头文件列索引偏移后,有一块内存存储了每一列的相关数据。
cols[i]存储了第i+1列数据的开头。- 因此,我们不难想到,对于第一列数据,我们只需要采用
column_index[0]/page_header_ -> record_capacity, 就可以计算出第1列的定长。而其他的列,则使用column_index[i] - column_index[i-1]/record_capacity就可以计算出第i列的定长。我们的get_field_len帮我们完成了这一dirty work.
int PaxRecordPageHandler::get_field_len(int col_id)
{
int *col_idx = reinterpret_cast<int *>(frame_->data() + page_header_->col_idx_offset);
if (col_id == 0) {
return col_idx[col_id] / page_header_->record_capacity;
} else {
return (col_idx[col_id] - col_idx[col_id - 1]) / page_header_->record_capacity;
}
}
- 如何获取我们的记录呢?只需要知道我们的记录索引,配合上对应列的定长,就可以获得该记录在该列中的数据了。也就是数据的起始地址在
frame->data()+page_header_->dataoffset+((col_id == 0) ? 0 : column_index[i-1]+slot_num * get_field_len(col_id);- 我们的dirty work被
get_field_data给做完了。
char *PaxRecordPageHandler::get_field_data(SlotNum slot_num, int col_id)
{
int *col_idx = reinterpret_cast<int *>(frame_->data() + page_header_->col_idx_offset);
if (col_id == 0) {
return frame_->data() + page_header_->data_offset + (get_field_len(col_id) * slot_num);
} else {
return frame_->data() + page_header_->data_offset + col_idx[col_id - 1] + (get_field_len(col_id) * slot_num);
}
}
这样我们第一部分的第一个函数就解析得差不多了。注意不要忘记设置脏页,这与缓存系统有关。
get_record
这一部分其实在上面的讲解中已经讲述过了。我们将记录按照不同列的定长进行拆分,并将其存入到不同列中。那么这样,我们反过来进行即可。
需要注意的是,我们的record**没有预先分配空间。因此我们很容易出现段错误。于是我们需要采用new_record来分配空间。
于是我们有:
- 为record分配空间,并将记录原信息填入其中。
- 遍历每一个列,将列中的信息拷贝到记录当中。
Answer:
RC PaxRecordPageHandler::get_record(const RID &rid, Record &record)
{
// your code here
if (rid.slot_num >= page_header_->record_capacity) {
LOG_ERROR("Invalid slot_num %d, exceed page's record capacity, frame=%s, page_header=%s",
rid.slot_num, frame_->to_string().c_str(), page_header_->to_string().c_str());
return RC::RECORD_INVALID_RID;
}
Bitmap bitmap(bitmap_, page_header_->record_capacity);
if (!bitmap.get_bit(rid.slot_num)) {
LOG_ERROR("Invalid slot_num:%d, slot is empty, page_num %d.", rid.slot_num, frame_->page_num());
return RC::RECORD_NOT_EXIST;
}
record.set_rid(rid);
record.new_record(page_header_ -> record_real_size);
int field_len_offset = 0;
for(int col_id = 0; col_id < page_header_ -> column_num; col_id++) {
const int field_len = get_field_len(col_id);
char *target = get_field_data(rid.slot_num, col_id);
record.set_field(field_len_offset, field_len, target);
field_len_offset += field_len;
}
return RC::SUCCESS;
// exit(-1);
}
一些总结的废话(可以直接跳过不看)2
- 我们来仔细了解record。
- 从RID的结构体中,我们发现这记录了该条记录位于的页号和记录索引。后者将会在bitmap上同步记录(以0-1方式)。
struct RID
{
PageNum page_num; // record's page number
SlotNum slot_num; // record's slot number
// 函数实现。。。
}
- 在record中,我们需要关注以下几个函数:
new_record,set_field. new_record为我们分配了新的record的储存空间,并且确定了归属者。也就是,这个record所能够管理的内存长度范围,从而规定了这条记录的长度。我们需要注意到,这里需要规定的是记录的实际长度而非在数据页内的对齐长度。这对后面还原数据至关重要。
RC new_record(int len)
{
ASSERT(len!= 0, "the len of data should not be 0");
char *tmp = (char *)malloc(len);
if (nullptr == tmp) {
LOG_WARN("failed to allocate memory. size=%d", len);
return RC::NOMEM;
}
set_data_owner(tmp, len);
return RC::SUCCESS;
}
接下来就是set_field.我们注意到,我们的数据按照这样的方式进行拆分和回收,如下图所示。
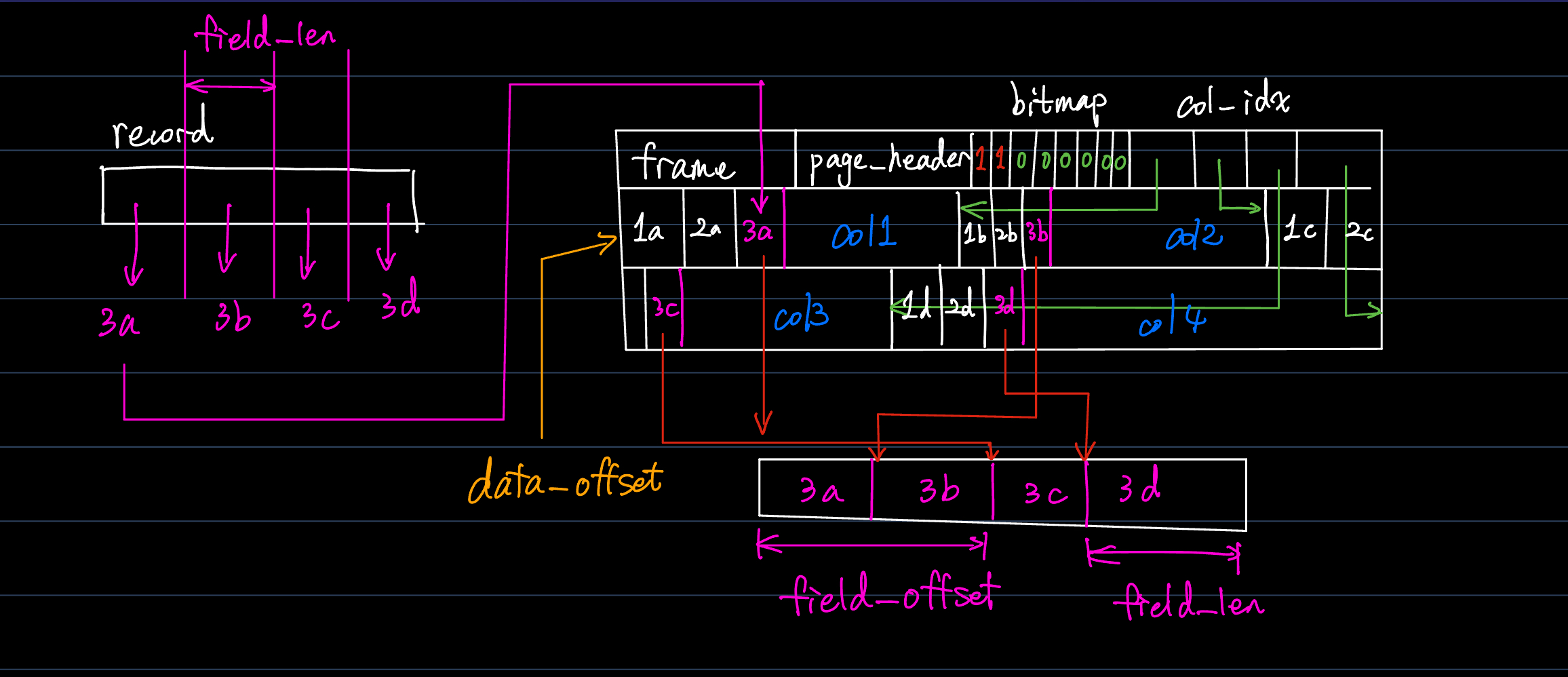
这样我们就明白了为什么需要采用set_field_data.我们需要根据前面的column的定长来计算我们恢复记录时数据保存的起始位置点。然后将记录拷贝到定长的内存空间中。
get_chunk
这里的chunk稍显复杂。因此我们需要先了解一下chunk的相关结构。我们的chunk定义在src/observer/storage/common/chunk.h中。
我们首先来看组成它的成员:
private:
vector<unique_ptr<Column>> columns_;
// TODO: remove it and support multi-tables,
// `columnd_ids` store the ids of child operator that need to be output
vector<int> column_ids_;
- 两个vector分别存储的是该块中含有的column索引和索引对应的Column。
- 注意到我们的
columns_存储的是指向对应索引的column的unique_ptr。 - 我们又注意到,我们的拷贝构造函数和移动构造函数都被ban了
(为什么呢?),这样我们就无法用一个chunk对象来构造另一个chunk对象,也不允许将chunk对象移动到另一个chunk上。
接下来我们再来观察column。column也是相同的,ban掉了拷贝构造函数和移动构造函数。这样我们就只能通过指针来进行操作了。
接下来弄清楚我们的操作过程。
- 从bitmap中获取并没有被删除的记录。
- 针对每列进行查询。
- 从chunk中获取我们需要的列索引号。(注意chunk内不一定是按照[1,2,3,4]储存的列号!)
- 根据获得的列索引号再获取我们对应的指向对应column的unique_ptr。
- 逐个获取可用的记录,直到不再具有可用的记录为止,将其逐个加入到column中。
RC PaxRecordPageHandler::get_chunk(Chunk &chunk)
{
// your code here
const int n = chunk.column_num();
Bitmap bitmap(bitmap_, page_header_->record_capacity);
// Get the column's refrences.
for(int i = 0; i < n; i++) {
int col_idx = chunk.column_ids(i);
Column *column = chunk.column_ptr(i);
for(int j = bitmap.next_setted_bit(0); j < page_header_ -> record_capacity; j = bitmap.next_setted_bit(j + 1)) {
if(j == -1) {
break;
}
char * data = get_field_data(j, col_idx);
column -> append_one(data);
}
}
return RC::SUCCESS;
// exit(-1);
}
Aggregate function
这里我们主要实现的是miniob内的聚集函数min, max, count, avg.
首先可以参考已经有了解析的max部分
接下来我们继续完成剩余的部分。
Expression处理
首先需要处理expression。再parse提取词表后将会形成stmt,进入到表达式部分。我们的表达式将会在这里匹配关键词,分别执行各种操作。src/observer/sql/expr/expression.cpp中的函数unique_ptr<Aggregator> AggregateExpr::create_aggregator()将会用于匹配聚集函数并且用于执行聚集操作。这里我们需要补上MAX, COUNT, AVG三个case。
unique_ptr<Aggregator> AggregateExpr::create_aggregator() const
{
unique_ptr<Aggregator> aggregator;
switch (aggregate_type_) {
case Type::SUM: {
aggregator = make_unique<SumAggregator>();
break;
}
case Type::MAX: {
aggregator = make_unique<MaxAggregator>();
break;
}
case Type::MIN: {
aggregator = make_unique<MinAggregator>();
break;
}
case Type::COUNT: {
aggregator = make_unique<CountAggregator>();
break;
}
case Type::AVG: {
aggregator = make_unique<AvgAggregator>();
break;
}
default: {
ASSERT(false, "unsupported aggregate type");
break;
}
}
return aggregator;
}
接着,我们需要补全相对应的聚集算子。我们将目光聚焦到src/observer/sql/expr/aggregator.h上。我们发现,具体的聚集算子均由基类聚集算子继承而来。我们首先来分析已经存在的SumAggregator。
class Aggregator
{
public:
virtual ~Aggregator() = default;
virtual RC accumulate(const Value &value) = 0;
virtual RC evaluate(Value &result) = 0;
protected:
Value value_;
};
class SumAggregator : public Aggregator
{
public:
RC accumulate(const Value &value) override;
RC evaluate(Value &result) override;
};
这样,SumAggregator将会具有自己的accumulate和evaluate函数作为虚函数覆盖基类虚函数。并且具有一个保护成员value_,该保护成员从基类公有继承而来。
接下来我们再关注accumulate和evaluate函数。
我们发现:
- 在首次遇到第一个元素时,根据第一个元素设立保护成员的类型。
- 每次遇到新的变量时不断累加。
- 在evaluate函数中,将保护变量的结果传递给result。
于是我们的最小值就可以按照:每次遇到新的元素进行比较,当返回的结果为-1时,就更新保护变量即可。
RC MinAggregator::accumulate(const Value &value) {
if (value_.attr_type() == AttrType::UNDEFINED) {
value_ = value;
return RC::SUCCESS;
}
ASSERT(value.attr_type() == value_.attr_type(), "type mismatch. value type: %s, value_.type: %s",
attr_type_to_string(value.attr_type()), attr_type_to_string(value_.attr_type()));
int cmp = value_.compare(value);
if (cmp > 0) {
value_ = value;
}
return RC::SUCCESS;
}
RC MinAggregator::evaluate(Value &result) {
result = value_;
return RC::SUCCESS;
}
自己增加一个变量
当出现count和average变量该怎么办?我们既然采用了继承,就可以自行定义自己内部可以访问的计数变量。我们就有:
class CountAggregator : public Aggregator
{
public:
CountAggregator(): count_(0) {}
RC accumulate(const Value &value) override;
RC evaluate(Value &result) override;
protected:
int count_; // For counting usage.
};
class AvgAggregator : public Aggregator
{
public:
RC accumulate(const Value &value) override;
RC evaluate(Value &result) override;
protected:
float count_; // For counting usage.
};
接下来,在计算Avgerage的时候,不要忘记设置结果的类型为float。否则因为其他变量类型并没有函数divide的定义,将会导致返回结果为0.
RC CountAggregator::accumulate(const Value &value) {
if (value_.attr_type() == AttrType::UNDEFINED) {
value_ = value;
count_++;
return RC::SUCCESS;
}
ASSERT(value.attr_type() == value_.attr_type(), "type mismatch. value type: %s, value_.type: %s",
attr_type_to_string(value.attr_type()), attr_type_to_string(value_.attr_type()));
count_++;
return RC::SUCCESS;
}
RC CountAggregator::evaluate(Value &result) {
result.set_type(AttrType::INTS);
result.set_data(reinterpret_cast<const char *>(&count_), sizeof(count_));
ASSERT(result.get_int() == count_, "Error! The results are not set correctly, with value: %d", result.get_int());
return RC::SUCCESS;
}
RC AvgAggregator::accumulate(const Value &value) {
if (value_.attr_type() == AttrType::UNDEFINED) {
value_ = value;
count_++;
return RC::SUCCESS;
}
ASSERT(value.attr_type() == value_.attr_type(), "type mismatch. value type: %s, value_.type: %s",
attr_type_to_string(value.attr_type()), attr_type_to_string(value_.attr_type()));
count_++;
value_.add(value, value_, value_);
return RC::SUCCESS;
}
RC AvgAggregator::evaluate(Value &result) {
if(count_ == 0) {
return RC::VARIABLE_NOT_VALID; // Divide by 0!
}
Value tmp = value_;
Value value_count;
value_count.set_type(AttrType::FLOATS);
result.set_type(AttrType::FLOATS);
value_count.set_data(reinterpret_cast<const char *>(&count_), sizeof(count_));
result.divide(tmp, value_count, result);
return RC::SUCCESS;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号