
第三章 SQL入门
Chapter 3 SQL介绍
参考书目:《数据库系统概念》第7版,机械工程出版社
Reference: Database System Concepts, 7th Edition
- 广泛的数据库查询语言。
- 定义数据结构,修改数据库中的数据,安全性约束。
3.1 查询语言概览
- 数据定义语言(DDL)。SQL DDL提供定义,删除和修改关系模式的命令。
- 数据操纵语言(DML)。SQL DML提供查询信息,和插入,删除,修改元组的能力。
- 完整性(integrity)。DDL包括了定义完整性约束的命令,保存在数据库中的数据必须满足所定义的完整性约束。
- 视图定义。
- 事务控制。
- 嵌入式和动态式。
- 授权。
3.2 SQL数据定义
- 定义关系的集合和信息。

3.2.1 基本类型

- 每一种类型都具有一个null(空)的特殊值,代表一个缺失的值。可能不存在或不知道。
- 字符串char长度小于定义长度时,一般会追加空格。但是varchar则不会,因为这是可变的。在比较char时,会自动利用空格补齐长度后比较。
3.2.2 基本模式定义
- 采用create table来定义SQL关系。例如下面创建了department关系:
create table department
(dept_name varchar(20),
building varchar(20),
budget numeric(12,2),
primary key(dept_name));
- create table来创建一个表。我们有:
create table r
(
A1 D1,
A2 D2,
...,
An Dn,
<完整性约束1>,
...,
<完整性约束n>
);
-
分号可有可无。鉴于C/C++习惯,我将持续沿用
;。 -
SQL支持许多完整性约束。
- primary key \((A_{j1},A_{j2},\cdots,A_{jm})\) : 主码声明表示属性 \((A_{j1},A_{j2},\cdots,A_{jm})\) 作为构成关系的主码。主码属性必须非空且唯一。
- foreign key \((A_{k1},A_{k2},\cdots,A_{km})\) reference \(s\): 外码声明表示关系中任意的元组在属性 \((A_{k1},A_{k2},\cdots,A_{km})\) 上取值必须对应于关系 \(s\) 在某主码属性上的取值。
- not null: 要求非空属性。
-
SQL禁止任何破坏完整性约束的更新。进行这样的操作将会返回一个错误并且阻止。
-
更新:insert,update,删除delete。去除关系drop table。
-
delete from用于删除关系内的所有元组但是保留关系,而drop table将关系也进行删除处理。
-
alter table为已有关系增加属性。新属性的取值被赋为null。
Mysql 实验
Setup
我们采用mysql进行上述实验。鉴于其他原因,我们将不会进行非常精细化的权限管理。
首先我们安装数据库:sudo apt install mysql-server -y
执行mysql --version检查我们的版本。

登陆sql: sudo mysql -u root -p,没有设置密码前直接回车就可以登陆。
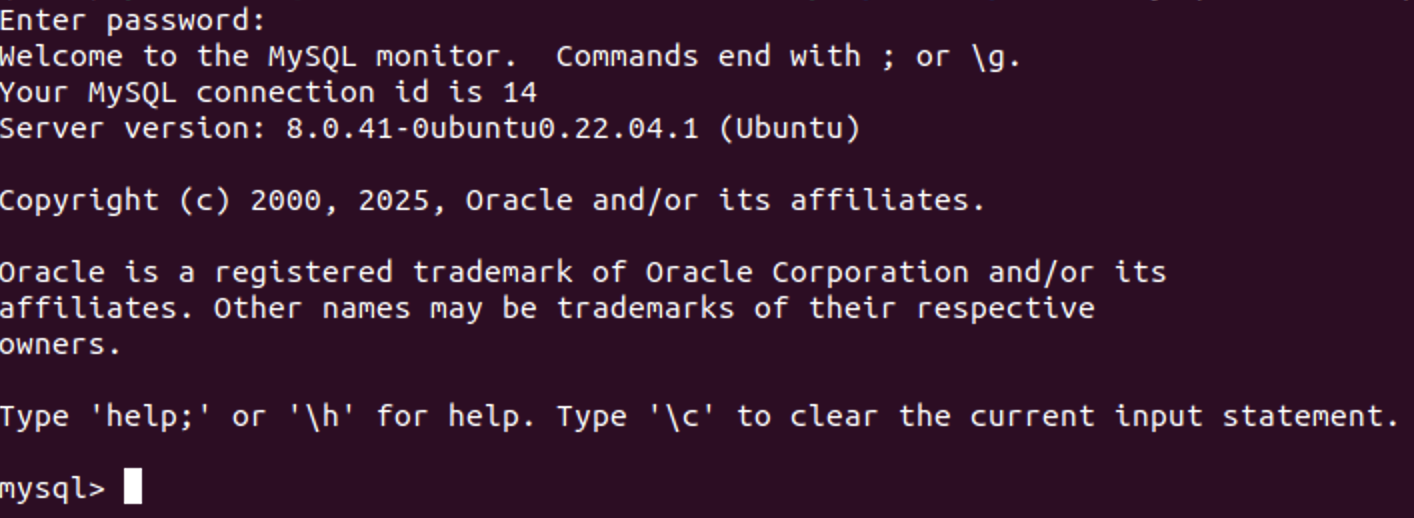
查看我们已经存在的数据库(不是关系!)
show databases;注意分号。
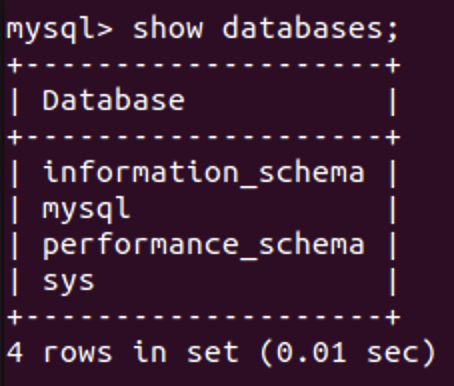
创建我们的实验性数据库create database experiment;
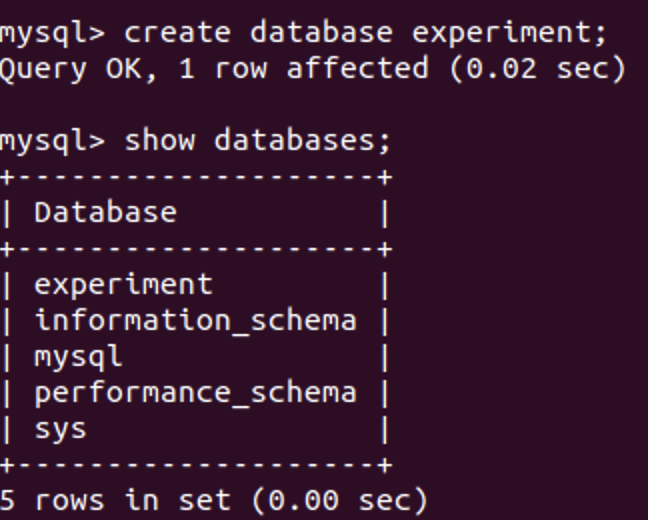
可以发现多了一个数据库。我们通过use experiment来使用它。
创建数据表和删除数据表
根据上文我们的department表格,我们可以进行如下操作:
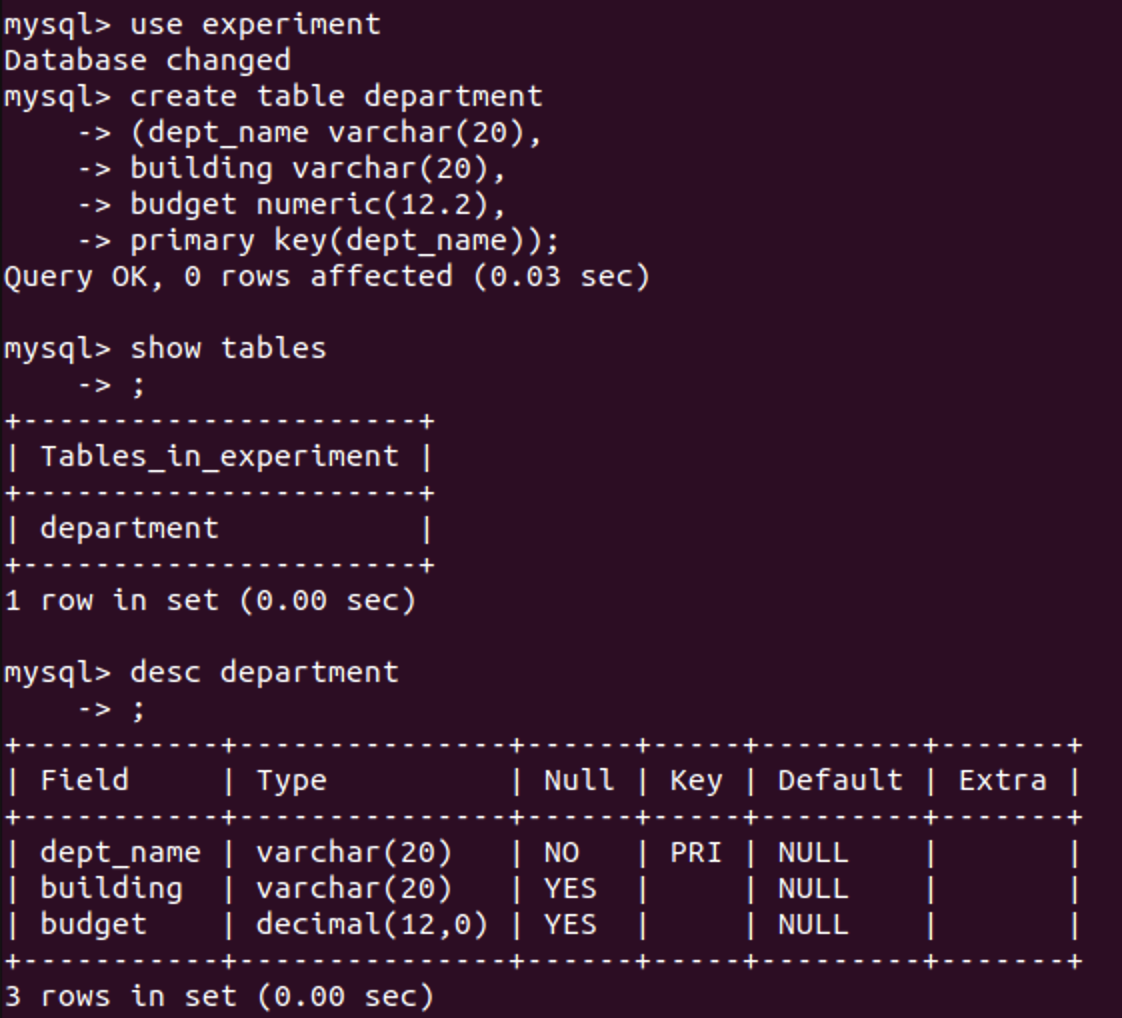
3.3 SQL查询的基本结构
- select, from, where.
- from: 输入的关系。
- where, select:关系在其子句中进行运算,产生关系作为结果。
3.3.1 单关系查询
- 我们采用select的方式来寻找到某一个属性。我们采用这样的命令,来从关系help_topic中列出属性name:
select name
from help_topic;
- 进行去重处理则需要使用distinct:
select distinct name
from help_topic;
- 阻止(显式)声明不去重则使用all。
select all name
from help_topic;
- select字句允许使用+,-,*,/运算符的算数表达式,运算对象可以是常数/元组的属性。
select ID,salary*1.1
from instructor
这样显示出来的关系就是instructor中的ID属性和salary属性中的元组。不同的是所有的salary的值将是原来的1.1倍。
- where字句允许筛选出选定属性中满足特定条件的词组。
- 例如:从instructor中找出CS系工作的,工资超过70000的教师姓名:
select name
from instructor
where dept_name='CS' and salary > 70000;
- 允许在where子句中使用逻辑连词and, or, not。
3.3.2 多关系查询
- 寻找所有教师的姓名,他们所在系的名称以及建筑物名称。
select name,instructor.dept_name, building
from instructor,department
where instructor.dept_name=department.dept_name
- from选取了多个关系,而在where子句中选择想用的属性来讲他们关联在一起。
小结
- SQL查询语句包括三种类型的子句:select,from,where.
- select子句用于列出查询结果中需要的属性。
- from子句用于查询求值中需要访问的关系列表。
- where子句是作用在from子句中的关系属性上的谓词。
select A1,A2,...,A_n
from r1,r2,...,rn
where P;
- 子句写出的顺序是select,from,where,但是进行的运算应该是from,where,select。

- 形成笛卡尔积,相当于(不严格地)将各个表中没有相互关联的属性拼在一起,形成新的表,并从该表中筛选出符合条件的元组。
多重集关系代数Pt.I
对SQL的行为进行建模,我们定义了一个叫做 多重集关系代数(multiset relational algebra) 来进行处理。
- 对于关系 \(r_1\),其中的元组 \(t_1\) 有 \(c_1\) 份的拷贝并且 \(t_1\) 满足条件 \(\sigma_\theta\), 则在 \(\sigma_\theta(r_1)\) 中有 \(c_1\) 份其拷贝。
- 对于关系 \(r_1\),其中的元组 \(t_1\) 有 \(c_1\) 份的拷贝, 对于其中每一份拷贝, \(\prod_A(t_1)\) 都有 \(t_1\) 的拷贝。\(\prod_A(t_1)\) 称为 \(t_1\) 的投影。
- \(r_1\times r_2\) 有元组 \((t1,t2)\) 的 \(c_1c_2\) 份拷贝。
太复杂了我们举例说明一下。注意 \(\sigma\) 即按照条件选择, \(\prod\) 即根据模式筛选出元素中的那一个对应成份。\(\times\) 即经典笛卡尔积。我们有:
\(r_1=\{(1,a),(2,a)\}\),模式为 \((A,B)\)
\(r_2=\{2,3,3\}\),模式为 \(C\).
- \(\sigma_{A > 1}(r_1)=\{(2,a)\}\)
- \(\prod_B(r_1) = \{a,a\}\)
- \(\prod_B(r_1) \times r_2 = \{(a,2),(a,2),(a,3),(a,3),(a,3),(a,3)\}\)
因此,对于我们的SQL查询,可以写成:
\(\prod_{A_1,\ldots,A_n}(\sigma_p(r_1\times r_2\times \cdots r_m))\)
3.4 附加的基本运算
3.4.1 更名运算
-
as为更名运算。
-
old-name as new-name
-
我们可以在select中使用as进行属性名的更换,例如:
select a as b
from relation1, relation2
where relation1.ID = relation2.ID
- 上述展示了从关系1,关系2中选出ID相同的元组,并列出这些元组中a属性的值,并将a属性更名成了b。
- 注意只是结果改变了名字,原关系中没有发生修改。
- 我们可以通过这样的方式缩小关系名的长度,这样展示出来的结果相对方便查看。
- 重命名(也就是as后的部分)称为相关名称/变量。
3.4.2 字符串运算
- 字符串通过单标号
'表示。 - sql标准中大小写敏感,但是mySQL等一些数据库系统不一定区分大小写。
- 字符串上作用多种函数 upper,lower(分别为大写化和小写化),trim表示去除掉字符串后面的空格。
- like用于实现模式匹配。模式匹配大小写敏感。
- %:匹配任意子字符串。
- _:匹配任意一个字符。
- escape定义转义字符。比如我们有:
like 'ab\%cd%' escape '\'匹配以"ab%cd"开头的所有字符串。
3.4.3 通配符
- * 可以用于表示select中的所有属性。
3.4.4 排列显示次序
- order by可以使得元组按照某个顺序排列显示。缺省/asc表示升序排序,desc表示降序。
3.4.5 where子句谓词
- between A and B:表示在where中,筛选出某个范围内的元组。
- 允许使用 \((v_1,\ldots,v_n)\) 来包含一个n元元组,称为行构造器。元组上可以使用比较运算符,按照字典序进行运算。
3.5 集合运算
- union,intersect,except分别对应了 \(\cup\), \(\cap\) 和 \(-\) 运算。
- 可以用于合并从两个select...from...where中筛选出来的相同属性的元组。
3.5.1 union
- 例如:找出2017年秋季开课,或2018年春季开课,或两个学期都开课的所有课程的集合:
select course_id
from section
where semester='fall' and year=2017
union
select course_id
from section
where semester='spring' and year=2018;
- union语句会自动去重。如果我们不想去重而保留所有重复项,就可以使用union all。
3.5.2 intersect
- 和上述union的举例相同,只需要将union替换成intersect,就变成了“既在2017年秋季开设,又在2018年春季开设的课程”。
- intersect all表示不去重。
- MySQL没有实现该运算。
3.5.3 except
- 和上述的例子类似,将union替换成except,我们有“在2017年秋季开课,但是不在2018年春季开课的课程”。
- 保留重复项使用except all。
- MySQL没有实现该运算。
3.6 空值
- 空值(null value) 给基础运算带来了困难。
- 我们在SQL中出现了第三个布尔运算结果,称为unknown。任何涉及到比较运算的结果视为unknown,因为我们不知道空值到底代表了什么。
- 对于where语句来说,当期比较出来的结果为false或unknownn的时候,该元组不能加入结果中。
- SQL采用特殊的关键字null来测试空值,采用is known或is not unknown子句来测试一个比较运算结果是否为unknown,而不是true或false。
select name
from instructor
where salary > 10000 is unknown;
3.7 聚集函数
- 聚集函数:多个值作为输入,单个值作为输出。
- 平均:avg
- 最小/最大值:min/max
- 总和:sum
- 计数:count
3.7.1 基本聚集
- 考虑:找出CS系教师平均工资,我们有:
select avg(salary)
from instructor
where dept_name='CS';
- 返回值是具有单属性的关系,其中只有一个元组。这个元组对应的就是CS的教师的平均工资。我们可以用as给属性取个有意义的名字。
select avg(salary) as avg_salary
from instructor
where dept_name='CS';
- 如果使用聚集函数前需要去重,可以使用distinct。强制不去重使用all。比如我们需要通过ID计算不同的教师数量,我们就需要去重,我们有count函数进行计数。这样我们有:
select count(distinct ID)
from teachers
where semester='spring' and year=2018
这样即使有教师任课数量大于1,也只会被计数一次。
- 采用通配符
*来计算一个关系中元组的数量。
select count(*)
from instructors
3.7.2 分组聚集
- group by可以使得聚集函数作用在一组元组集上。这样,在分组子句中所有属性取值相同的元组将分在同一个组内。
- 考虑下面的查询实例。
select dept_name, avg(salary) as avg_salary
from instructors
group by dept_name
- 选择了关系(表)instructors内的属性(列)dept_name, salary。
- salary将通过dept_name进行分组并计算每一分组下的平均值。
- 结果将属性名改成avg_salary进行显示。
- 在没有group by子句的情况下,我们将整个关系当作是一个组。
- 出现在select语句中但是没有被聚集的属性只能是那些出现在group by子句中的那些属性。否则将会错误。(你让他怎么展示呢?)
- 采用
/* */或者--的方式来撰写注释。
3.7.3 having子句
- 对分组限定条件。我们在形成分组后,才可以使用having子句中的聚集函数。请看下面的例子。
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name
having avg(salary)>42000;
-
找出平均工资超过42000的教师和他们所处的系。
- 从instructor中选出属性dept_name, salary属 性。
- 根据dept_name进行分组后计算salary的均值。
- 通过having筛选出salary均值大于42000的。
-
同样的,包含在having子句中,但是没有被聚集的属性必须出现在group by子句中。否则查询错误。
-
对于有having,group by和聚集的查询含义一般定义如下:
- from确定一个关系。
- where作用到上面的结果,计算出新的关系。
- 出现了group by,将符合的元组通过其进行分组。否则整个关系为一个组。
- having作用到每个分组上,不满足的分组将会被去除。
- select在剩下的分组中产生查询结果,对每个元组应用聚集函数。
3.7.4 对空值和布尔值的聚集
- 除了count(*) 之外的聚集函数将全部忽略控制。因此有可能对于聚集函数,输入集合为空集。
- 空集的count运算结果为0。
- 布尔值的结果有三个,上文已经提及。聚集函数some与any用于布尔值集合,计算or(析取)和and(合取)。
多重集关系代数Pt.II
- 同样的,关系代数也有并,交和差。
- 我们可以用关系代数聚集运算 \(\gamma\) 来允许在关系属性上使用聚集函数。(或者使用 \(\mathcal{G}\))。
- 对于复杂的sql可以进行改写。
select A1,A2,sum(A3)
from r1,r2,...,rm
where P
group by A1, A2, having count(A4)>2
可以写成:
\(t_1\leftarrow \sigma_p(r_1\times r_2\cdots r_m)\)
\(\prod_{A_1,A_2,\text{sum}(A_3)}(\sigma_{count(A_4)>2}(_{A_1,A_2}\gamma_{sum(A_3)~ as ~sum(A_3),~count(A_4)}(t_1)))\)
3.8 嵌套子查询
- 子查询嵌套在另一个查询中的select-from-where表达式中。
3.8.1 集合成员资格
- 查询“2017年秋季和2018年春季都开设的所有课程”。
- 确定子查询:2018年春季开设的课程。
(select course_id
from section
where semester = 'spring' and year = 2018
);
- 确定从子查询中得到的课程,再次进行查询。
select distinct course_id
from selection
where semester = 'autumn'
and year=2017
and course_id in
(select course_id
from selection
where semester = 'spring'
and year=2018
);
- 采用in可以实现类似intersection的功能。采用notin可以实现difference的功能。
- 他们也可以用于枚举集合。
3.8.2 集合比较
- 查询“找出工资至少比生物系某位教师的工资要高的所有教师的姓名。”
- 采用 >some 子句来查询。
select distinct T.name
from instructor as T
where salary > some(
select salary
from instructor
where dept_name = 'Biology'
);
- <some,<=some,>=some,=some,<>some(不等于).
- =some等价于in, 但是 <>some不等价于not in。
- 不等于一些元素不正确,应该是不等于任何。
- <all,<=all,>=all,=all,<>all(不等于).
- =all不等价于in, <>all等价于notin。
- 和一些元素相等就代表存在了,没必要与所有的都相等(也不太可能)
3.8.3 空关系测试
- exists子句,可以测试子查询的结果中是否存在元组。在子查询非空时返回True。
- 外层查询的相关名称可以用在where子句的查询中。这样的子查询称为相关子查询。
- 符合作用域规则。
- not exists代表测试子查询是否不存在元组,子查询空时返回True。采用not exists(B except A) 可以用来说明 关系A包含关系B。
3.8.4 重复元组存在性测试
- unique子句返回子查询结果中没有重复的元组,此时返回true的值。
- 查询“找出在2017年最多开设一次的所有课程”。
select T.course_id
from course as T
where unique(select R.course_id
from section as R
where T.course_id = R.course_id and R.year = 2017)
- not unique子句返回子查询结果中有重复的元组,此时返回true
3.8.5 from子句中的子查询
任何select-from-where表达式返回的结果都是关系。因此可以被插入到其他关系可以出现的位置。
- 例如:“找出平均工资大于42000的教师平均工资”:
select dept_bame,avg_salary
from(
select dept_name,
avg(salary) as avg_salary
from instructor
group by dept_name
) as dept_avg(dept_name, avg_salary)
where avg_salary > 42000
- 这里子查询中的属性和关系进行了重命名。但是注意,MySQL和PostgreSQL都要求from子句中的每个子查询的结果关系必须被命名。
- SQL2003标准后允许子句查询中访问外部的属性。采用lateral关键字。
3.8.6 with子句
- 定义了临时的关系,只对with子句的查询有效。
3.8.7 标量子查询
- 子查询只返回一个包含单个属性的元组。称为标量子查询。例如:
select a, (
select count(*)
from b
where c.a = b.a
)as d
from R
- 标量可以直接运算,不需要from子句。
select(select count(*) from teachers) / (select count(*) from instructor) from dual
3.9 数据库的修改
删除
delete from Relation
where P;
- 删除关系中满足条件P的所有元组。
- 也可以嵌套子查询于where子句中。
插入
insert into R (A1, A2, A3)
values ('AAA', 12,4),
('111',12,3);
- 将对个元组插入元素。
- 我们也可以从查询结果中插入元组。例如下述的语句:
insert into student
select ID, name
from R
where P;
- 需要注意我们必须在插入之前完成执行select语句。否则在没有主码约束的情况下,会插入无数元组。
更新
- update子句可以用于更新元素。
update relation
set A = A1
where P;
- 也可以通过case来进行更新。
update instructor
set salary = case
when P1 then res1
when P2 then res2
else res3
end


 浙公网安备 33010602011771号
浙公网安备 33010602011771号