
ChCore-lab2
lab 2: Memory Manage
前言
新的环境好像不支持arm架构了,总是会在make build触发错误(提示镜像仅适配(linux/amd)平台QAQ)......运行make build会出现exec chbuild not found. 我们于是只能使用utm平台+qemu模拟amd64架构的ubuntu系统来进行运行。
我采用的是utm+ubuntu 22.04 amd64架构平台,因为依赖指令集的翻译,所以性能上非常不好。
可能遇到的问题:超时
在完成实验的过程中,鉴于性能的低下,有可能你完成了所有的实验但是仅得到50分的情况。在检查了你的make qemu后确实能够输出如下结果的:
Map & unmap huge range: OK ...
...
Welcome to ChCore shell!
证明你遇到了超时问题。你可以将./OS-Course-Lab/Scripts/lab.mk中的第47行TMEOUT ?=后的数字进行修改,稍微增大运行时间容忍度。笔者采用了60s。(性能太差了www)
想要完成挑战?
在完成实验的过程中,你可能想要完成挑战部分。但是指导手册中并不会告诉你完成挑战时正确的修改grade的方法。 正确的修改方式是:修改./OS-Course-Lab/Lab2/kernel/config.cmake, 将最后一行修改为:
chcore_config(CHCORE_KERNEL_PM_USAGE_TEST BOOL ON "Whether to enable the challenge test?")
这样将会打开挑战部分,也意味着如果没有完成挑战部分你将拿不到最后的30分。(谨慎使用!)
接下来进入我们的正题吧。
物理内存管理
伙伴系统
内核初始化过程中,需要对内存管理模块进行初始化(mm_init 函数),首先需要把物理内存管起来,从而使内核代码可以动态地分配内存。
ChCore 使用伙伴系统(buddy system)[^buddy]对物理页进行管理,在 mm_init 中对伙伴系统进行了初始化。为了使物理内存的管理可扩展,ChCore 在 mm_init 的开头首先调用平台特定的 parse_mem_map 函数,该函数解析并返回了可用物理内存区域,然后再对各可用物理内存区域初始化伙伴系统。
伙伴系统中的每个内存块都有一个阶(order)表示大小,阶是从 0 到指定上限 BUDDY_MAX_ORDER 的整数。一个 $ n $ 阶的块的大小为 $ 2^n \times PAGE_SIZE $,因此这些内存块的大小正好是比它小一个阶的内存块的大小的两倍。内存块的大小是 2 次幂对齐,使地址计算变得简单。当一个较大的内存块被分割时,它被分成两个较小的内存块,这两个小内存块相互成为唯一的伙伴。一个分割的内存块也只能与它唯一的伙伴块进行合并(合并成他们分割前的块)。
ChCore 中每个由伙伴系统管理的内存区域称为一个 struct phys_mem_pool,该结构体中包含物理页元信息的起始地址(page_metadata)、伙伴系统各阶内存块的空闲链表(free_lists)等。
练习题1
完成kernel/mm/buddy.c中的split_chunk、merge_chunk、buddy_get_pages、 和buddy_free_pages函数中的LAB 2 TODO 1部分,其中buddy_get_pages用于分配指定阶大小的连续物理页,buddy_free_pages用于释放已分配的连续物理页。
- 可以使用
kernel/include/common/list.h中提供的链表相关函数和宏如init_list_head、list_add、list_del、list_entry来对伙伴系统中的空闲链表进行操作- 可使用
get_buddy_chunk函数获得某个物理内存块的伙伴块- 更多提示见代码注释
在这四个部分中,我们要先大致理清楚伙伴系统是怎么工作的。
- 进行物理内存分配
- 收到需要进行物理内存的分配请求。根据需要的物理内存大小确定伙伴系统需要分配的阶次(order)。
- 在地址池中寻找找到各个阶次的自由链表,判断其是否具有该阶次的物理内存页。
- 如果该阶次的物理内存块具有我们需要的页,则将该页从自由链表中取出。
- 如果没有,则搜索比其阶次更大的物理内存页。找到对应的物理内存页后,进行分裂得到我们需要的阶次大小的物理页。将分裂出来的其余阶次的物理页块加入到对应阶次的自由链表当中。
- 释放物理内存
- 收到释放物理内存的请求。
- 释放该阶次的内存,并寻找伙伴(相同阶次的阶次内存进行合并)。
- 将该阶次内存放入自由链表或者将合并后的内存放入其对应阶次的自由链表中。
接下来我们需要了解一下ChCore中的buddy系统的相关结构体。需要参考的文件在kernel/include/common/list.h和kernel/include/mm/buddy.h中。
我们的伙伴系统需要关注的是物理页和自由链表。这样需要关注的结构体如下:
struct page {
/* Free list */
struct list_head node; // 该页在自由链表中的节点。
/* Whether the correspond physical page is free now. */
int allocated; // 是否被分配的标记。 1为被分配,0为没有被分配。
/* The order of the memory chunck that this page belongs to. */
int order; // 该物理页的阶次。
/* Used for ChCore slab allocator. */
void *slab; // 这个用于Chcore的slab分布。我们不需要关注这个。
/* The physical memory pool this page belongs to */
struct phys_mem_pool *pool; // 其属于的内存池。
};
struct free_list {
struct list_head free_list; // 自由链表的链表头,其next指向一个没有被分配的物理页。
unsigned long nr_free; // 该自由链表具有的自由页的个数。
};
自由链表的相关结构和相关的api操作如下:
struct list_head {
struct list_head *prev;
struct list_head *next;
};
static inline void init_list_head(struct list_head *list);
static inline void list_add(struct list_head *new, struct list_head *head);
static inline void list_append(struct list_head *new, struct list_head *head);
static inline void list_del(struct list_head *node);
static inline bool list_empty(struct list_head *head);
#define list_entry(ptr, type, field) \
container_of(ptr, type, field)
我们可以发现这是一个双链表结构。其中大部分的函数都很容易明白其含义。但是其中我们会用到的一个宏定义list_entry(ptr, type, field)是比较难以理解的, 其对应的container_of(ptr, type, field)的定义如下:
#define container_of(ptr, type, field) \
((type *)((void *)(ptr) - (void *)(&(((type *)(0))->field))))
我们知道,一个结构体在定义后分配的(虚拟)内存是连续的。 我们以C prime plus上的一个例子解释如下:
struct stuff
{
int number;
char code[4];
float cost;
};
其内存分布如下:

那么当两个结构体共享相同地址处的一个变量时,我们就可以:
- 从一个结构体中取出这个成员,获得其地址。(地址可以通过
void *的强制类型转换获得。) - 计算这个成员在另一个结构体中相对于结构体头的偏移。也就是利用一个NULL的结构体,计算其对应的成员与他的偏移量。
(void *)(&(struct another_type *)(NULL)->member) - 将该成员减去这个偏移量,我们就可以获得这个新的struct所在的地址。
这样我们就可以在自由链表中仅存取node成员,不需要存储整个页。然后从这个node中,寻找到这个node所对应的物理页,也就是含有这个节点的物理页。
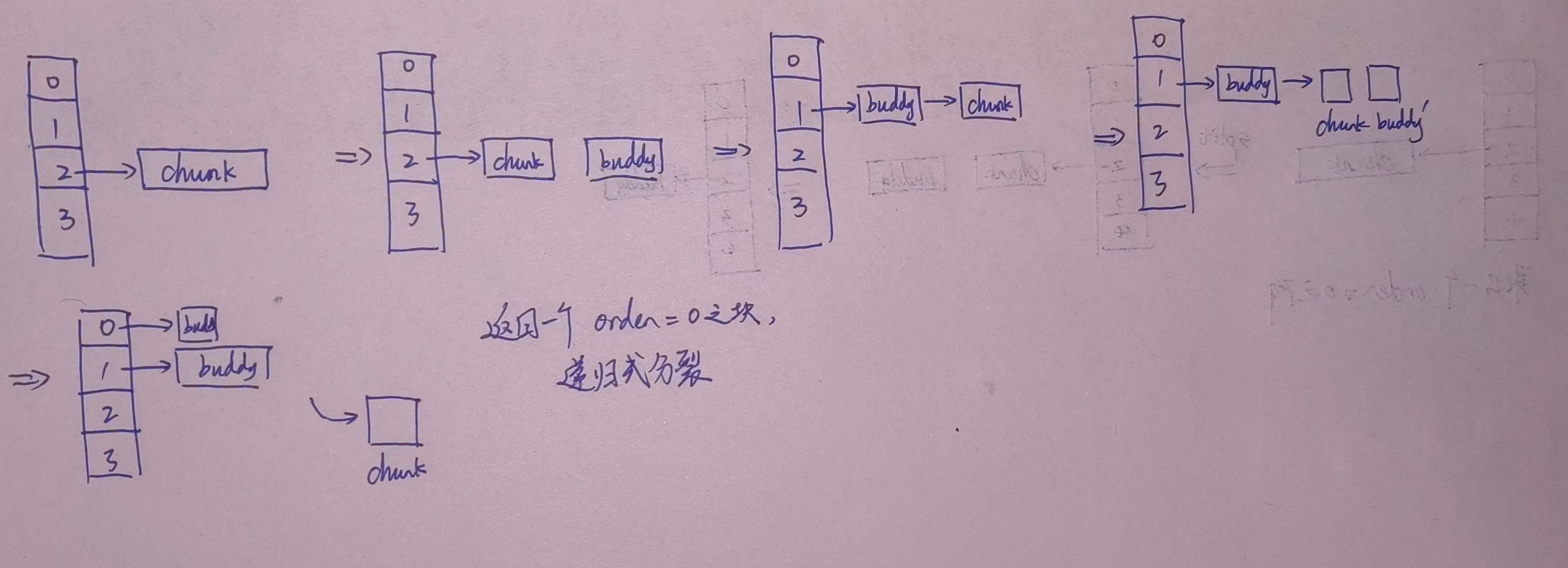
根据提示,我们首先编写split_node()函数。递归的终点自然是当当前物理页满足需要的阶次时,则进行合并。
/* The most recursion level of split_chunk is decided by the macro of
* BUDDY_MAX_ORDER. */
__maybe_unused static struct page *split_chunk(struct phys_mem_pool *__maybe_unused pool,
int __maybe_unused order,
struct page *__maybe_unused chunk)
{
/* LAB 2 TODO 1 BEGIN */
/*
* Hint: Recursively put the buddy of current chunk into
* a suitable free list.
*/
/* BLANK BEGIN */
// return NULL
if (chunk -> order == order)
{
return chunk;
}
else
{
// 将要进行分裂,将对应阶次的自由链表所含有的自由页数减去1。
pool->free_lists[chunk->order].nr_free--;
list_del(&(chunk ->node));
// 减少阶次后获得伙伴物理页块。获得的伙伴页块是将本物理页块均分后的后半部分。
chunk -> order--;
struct page * buddy = get_buddy_chunk(pool,chunk);
// 将多余的伙伴放入到新的阶次的自由链表中,并且该阶次的自由链表增加2.
struct list_head * cur_list_head = &(pool->free_lists[chunk->order].free_list);
list_add(&(buddy->node), cur_list_head);
pool->free_lists[chunk->order].nr_free+=2;
// 继续分裂直到获得自己需要的阶次的内存块后返回。
return split_chunk(pool, order, chunk);
}
/* BLANK END */
/* LAB 2 TODO 1 END */
}
为什么说我们进入递归的是chunk而不是我们的伙伴块呢?这是由于get_buddy_chunk()函数决定的。在该函数中有:
buddy_chunk_addr = chunk_addr
^ (1UL << (order + BUDDY_PAGE_SIZE_ORDER));
这是通过异或的方式来实现非进位的加。在物理内存中伙伴块是相邻的,我们先将传入的order阶次减去1,再进行如上的异或操作,就获得了后半物理内存块的起始地址,最后通过virt_to_page()函数来获得后半部分的物理页,也就是伙伴页。这样后半部分需要放入自由链表中,我们的前半部分将会继续进入递归。
接下来我们先完成物理分配部分的编写。我们首先从当前阶次开始不断向上寻找自由页块,进行分配后注意标注该页的分配状况,从对应阶次的自由链表中移除该物理页。
struct page *buddy_get_pages(struct phys_mem_pool *pool, int order)
{
int cur_order;
struct list_head *free_list;
struct page *page = NULL;
if (unlikely(order >= BUDDY_MAX_ORDER)) {
kwarn("ChCore does not support allocating such too large "
"contious physical memory\n");
return NULL;
}
lock(&pool->buddy_lock);
/* LAB 2 TODO 1 BEGIN */
/*
* Hint: Find a chunk that satisfies the order requirement
* in the free lists, then split it if necessary.
*/
/* BLANK BEGIN */
// UNUSED(cur_order);
// UNUSED(free_list);
// 寻找该阶次及其以上阶次的自由页。
for (cur_order = order; cur_order < BUDDY_MAX_ORDER; cur_order++)
{
// Check current nr_free. Then get the page out.
if (pool -> free_lists[cur_order].nr_free > 0)
{
free_list = &(pool -> free_lists[cur_order].free_list);
page = list_entry(free_list -> next, struct page, node);
break;
}
}
// 注意!如果实在没有页表分配时需要直接进入out部分。这是为了防止二次free。
if (page == NULL)
{
goto out;
}
// 确认阶次或分裂页表。
page = split_chunk(pool, order, page);
list_del(&(page->node));
page -> allocated = 1;
pool -> free_lists[page->order].nr_free--;
/* BLANK END */
/* LAB 2 TODO 1 END */
out: __maybe_unused
unlock(&pool->buddy_lock);
return page;
}
接下来进行合并。合并的想法也是递归形式地合并,我们有:
- 递归的终点是:当达到最大的阶次(13)时,终止返回。
- 还有就是当我已经无法获得新的伙伴页表,或者获得的伙伴页表处于分配状态,或者伙伴页表的阶次不够使其合并成更高阶次时,说明合并结束,返回chunk。
- 否则,将伙伴页表从其阶次的自由链表中删除后,选择伙伴页表和当前chunk地址较低的部分作为新的物理页块的地址,然后将order增加。递归直到情况1和2的终点。
/* The most recursion level of merge_chunk is decided by the macro of
* BUDDY_MAX_ORDER. */
__maybe_unused static struct page * merge_chunk(struct phys_mem_pool *__maybe_unused pool,
struct page *__maybe_unused chunk)
{
/* LAB 2 TODO 1 BEGIN */
/*
* Hint: Recursively merge current chunk with its buddy
* if possible.
*/
/* BLANK BEGIN */
// return NULL;
// 情况1,达到最大阶次。
if(chunk -> order == BUDDY_MAX_ORDER - 1)
return chunk;
// 情况2.
struct page * merging_buddy = get_buddy_chunk(pool, chunk);
if(merging_buddy == NULL || merging_buddy -> allocated || merging_buddy->order != chunk -> order)
{
return chunk;
}
// 存在可以合并的伙伴块,进行合并。注意选取较低地址的块作为新的合并块的地址。
else
{
// Delete the chunk from list.
list_del(&(merging_buddy -> node));
pool -> free_lists[merging_buddy->order].nr_free--;
// merge from tail.
if (merging_buddy < chunk)
chunk = merging_buddy;
chunk -> order++; // 将order增加1即可。这样这两个块都会包括在chunk中。
return merge_chunk(pool, chunk);
}
/* BLANK END */
/* LAB 2 TODO 1 END */
}
释放伙伴内存就很简单了,只需要将当前页标注成未分配,然后进行合并链表,最后将合并后的块加入到对应阶次的自由链表中即可。
void buddy_free_pages(struct phys_mem_pool *pool, struct page *page)
{
int order;
struct list_head *free_list;
lock(&pool->buddy_lock);
/* LAB 2 TODO 1 BEGIN */
/*
* Hint: Merge the chunk with its buddy and put it into
* a suitable free list.
*/
/* BLANK BEGIN */
// UNUSED(free_list);
// UNUSED(order);
// Mark as unused page.
page -> allocated = 0;
page = merge_chunk(pool, page); // merge until cannot merge.
pool -> free_lists[page -> order].nr_free++;
order = page -> order;
free_list = &(pool -> free_lists[order].free_list);
list_append(&(page->node), free_list);
/* BLANK END */
/* LAB 2 TODO 1 END */
unlock(&pool->buddy_lock);
}
slab
我们希望通过基于伙伴系统的物理内存管理,在内核中进行动态内存分配,也就是可以使用 kmalloc 函数(对应用户态的 malloc)。ChCore 的 kmalloc 对于较小的内存分配需求采用 SLAB 分配器[^slab],对于较大的分配需求则直接从伙伴系统中分配物理页。动态分配出的物理页被转换为内核虚拟地址(Kernel Virtual Address,KVA),也就是在 LAB 1 中我们映射的 0xffff_ff00_0000_0000 之后的地址。我们在练习题 1 中已经实现了伙伴系统,接下来让我们实现 SLAB 分配器吧。
练习题2
完成kernel/mm/slab.c中的choose_new_current_slab、alloc_in_slab_impl和free_in_slab函数中的LAB 2 TODO 2部分,其中alloc_in_slab_impl用于在 slab 分配器中分配指定阶大小的内存,而free_in_slab则用于释放上述已分配的内存。
- 你仍然可以使用上个练习中提到的链表相关函数和宏来对 SLAB 分配器中的链表进行操作
- 更多提示见代码注释
首先还是先看一下我们需要使用的结构体和api。
/* slab_header resides in the beginning of each slab (i.e., occupies the first slot). */
// 在每个slab中占有第一个slot,记录了这个slab的相关信息。
struct slab_header {
/* The list of free slots, which can be converted to struct slab_slot_list. */
void *free_list_head; // 可以转换成slab_slot_list类型,也是自由的slot的头指针。
/* Partial slab list. */
struct list_head node; // 指向其他自由链表的partial_slab_list指针。
int order; // 当前slab的阶次。
unsigned short total_free_cnt; /* MAX: 65536 */
unsigned short current_free_cnt; // 当前自由slot的数目。
};
/* Each free slot in one slab is regarded as slab_slot_list. */
struct slab_slot_list {
void *next_free; // 指向下一个自由的slot。
};
struct slab_pointer {
struct slab_header *current_slab; // 当前选定的slab。
struct list_head partial_slab_list; // 自由slab的partial_list。
};
/* All interfaces are kernel/mm module internal interfaces. */
void init_slab(void);
void *alloc_in_slab(unsigned long, size_t *);
void free_in_slab(void *addr);
unsigned long get_free_mem_size_from_slab(void);
接下来就是编写alloc_in_slab()。选择好了slab后,检查当前slab是否全满。如果全满则选择一个新的slab,否则直接选择当前的slab即可。
注意选择了slab后要从partial中删除。
static void *alloc_in_slab_impl(int order)
{
struct slab_header *current_slab;
struct slab_slot_list *free_list;
void *next_slot;
UNUSED(next_slot);
lock(&slabs_locks[order]);
current_slab = slab_pool[order].current_slab;
/* When serving the first allocation request. */
if (unlikely(current_slab == NULL)) {
current_slab = init_slab_cache(order, SIZE_OF_ONE_SLAB);
if (current_slab == NULL) {
unlock(&slabs_locks[order]);
return NULL;
}
slab_pool[order].current_slab = current_slab;
}
/* LAB 2 TODO 2 BEGIN */
/*
* Hint: Find a free slot from the free list of current slab.
* If current slab is full, choose a new slab as the current one.
*/
/* BLANK BEGIN */
// 判断是否该slab为满。如果满了分配一个新的slab。
if (current_slab -> current_free_cnt == 0)
{
choose_new_current_slab(&slab_pool[order]);
}
// 确认是否分配到了slab。否则返回空。
current_slab = slab_pool[order].current_slab;
if (current_slab == NULL)
{
unlock(&slabs_locks[order]);
return NULL;
}
// 修改当前的自由slot的头指针指向。从current_slab中获得自由list的头,将头指针指向第一个自由的slot,随后将自由数减去一。
// 因为第一个slot用于存储当前slot的信息。
free_list = (struct slab_slot_list *) current_slab -> free_list_head;
current_slab -> free_list_head = free_list -> next_free;
current_slab -> current_free_cnt--;
/* BLANK END */
/* LAB 2 TODO 2 END */
unlock(&slabs_locks[order]);
return (void *)free_list;
}
选择一个新的slab,只需要注意查看partial_list中是否还有空的slab,否则从地址池中初始化。然后将当前的slab从当前的partial_list中删除即可。
static void choose_new_current_slab(struct slab_pointer * __maybe_unused pool)
{
/* LAB 2 TODO 2 BEGIN */
/* Hint: Choose a partial slab to be a new current slab. */
/* BLANK BEGIN */
/**
* @param pool: slab_pointer. has 2 members.
* @param current_slab: (struct slab_header *)
* @param partial_slab_list: (list_head)
*
* @brief check partial_list. if none, init one. if has, choose one as new current_slab.
* @brief Then delete it from partial_slab_list.
*/
// 检查当前的partial_list是否是
if(list_empty(&(pool -> partial_slab_list)))
{
int order = pool -> current_slab -> order;
pool -> current_slab = init_slab_cache(order, SIZE_OF_ONE_SLAB);
return;
}
// 获得新的slab。这里还是使用了前面list的contanier宏来从一个节点获得其属于的slab。
struct list_head * partial_slab_list = &(pool -> partial_slab_list);
pool -> current_slab = list_entry(partial_slab_list -> next, struct slab_header, node);
list_del(&(pool -> current_slab -> node));
/* BLANK END */
/* LAB 2 TODO 2 END */
}
最后就是free_in_slab了。需要的是释放一个slab中的slot。我们的想法就是将新的slot作为新的free_list_head,指向原先的free_list_head即可。
/* LAB 2 TODO 2 BEGIN */
/*
* Hint: Free an allocated slot and put it back to the free list.
*/
/* BLANK BEGIN */
// 将当前等待释放的slot的下一个节点指向自由链表的头。
slot -> next_free = slab -> free_list_head;
slab -> free_list_head = slot; // 成为新的头!
slab -> current_free_cnt++;
// UNUSED(slot);
/* BLANK END */
/* LAB 2 TODO 2 END */
try_return_slab_to_buddy(slab, order);
unlock(&slabs_locks[order]);
这样slab就完成了。
Kmalloc
有了伙伴系统和 SLAB 分配器,就可以实现 kmalloc 了。
练习题 3
完成kernel/mm/kmalloc.c中的_kmalloc函数中的LAB 2 TODO 3部分,在适当位置调用对应的函数,实现kmalloc功能
- 你可以使用
get_pages函数从伙伴系统中分配内存,使用alloc_in_slab从 SLAB 分配器中分配内存- 更多提示见代码注释
很简单了。对于小型分配,则直接在slab中进行。大型的分配则将尺寸转换成size,然后分配物理页即可。
/* Currently, BUG_ON no available memory. */
void *_kmalloc(size_t size, bool is_record, size_t *real_size)
{
void *addr = NULL;
int order;
if (unlikely(size == 0))
return ZERO_SIZE_PTR;
if (size <= SLAB_MAX_SIZE) {
/* LAB 2 TODO 3 BEGIN */
/* Step 1: Allocate in slab for small requests. */
/* BLANK BEGIN */
// UNUSED(addr);
// UNUSED(order);
addr = alloc_in_slab(size, real_size); // 小块直接在slab中分配。
/* BLANK END */
#if ENABLE_MEMORY_USAGE_COLLECTING == ON
if(is_record && collecting_switch) {
record_mem_usage(*real_size, addr);
}
#endif
} else {
/* Step 2: Allocate in buddy for large requests. */
/* BLANK BEGIN */
order = size_to_page_order(size); //转换成order后再分配。
addr = get_pages(order);
/* BLANK END */
/* LAB 2 TODO 3 END */
}
BUG_ON(!addr);
return addr;
}
这样我们第一部分就完成了。
页表管理
在LAB 1 中我们已经详细介绍了 AArch64 的地址翻译过程,并介绍了各级页表和不同类型的页表描述符,最后在内核启动阶段配置了一个粗粒度的启动页表。现在,我们需要为用户态应用程序准备一个更细粒度的页表实现,提供映射、取消映射、查询等功能。
练习题4
完成kernel/arch/aarch64/mm/page_table.c中的query_in_pgtbl、map_range_in_pgtbl_common、unmap_range_in_pgtbl和mprotect_in_pgtbl函数中的LAB 2 TODO 4部分,分别实现页表查询、映射、取消映射和修改页表权限的操作,以 4KB 页为粒度。
- 需要实现的函数内部无需刷新 TLB,TLB 刷新会在这些函数的外部进行
- 实现中可以使用
get_next_ptp、set_pte_flags、virt_to_phys、GET_LX_INDEX等已经给定的函数和宏- 更多提示见代码注释
这一部分可以说是最为困难的一部分。首先,很多函数我们甚至无法寻找到它的定义(例如上面提供的virt_to_phys)。我们还是一步步地来完成。
首先第一部分是进行页表的查询。我们可以清楚的是,我们Chcore具有如下的架构形式来实现多级页表:

从虚拟地址中,首先我们从63-48位中获取我们的TTBR0_EL1(低地址映射)或者是TTBR1_EL1(高地址映射)来获得我们的L0页表。随后,从虚拟地址中分别取出不同位置的虚拟页号,用于从上一级页表指向的页表中找到对应的条目,判断其是表条目还是块条目。最后将获得的该条目内的物理页号与对应的页内偏移组合在一起,形成真正的物理地址。
首先阅读get_next_ptp的函数。
/*
* Find next page table page for the "va".
*
* cur_ptp: current page table page
* level: current ptp level
*
* next_ptp: returns "next_ptp"
* pte : returns "pte" (points to next_ptp) in "cur_ptp"
*
* alloc: if true, allocate a ptp when missing
*
* @returns
* @param -ENOMAPPING: No Mapping.
* @param -EINVAL: The level of page table error.
* @param NORMAL_PTP: the normal page table page.
* @param BLOCK_PTP: point to the block.
*/
static int get_next_ptp(ptp_t *cur_ptp, u32 level, vaddr_t va, ptp_t **next_ptp,
pte_t **pte, bool alloc, __maybe_unused long *rss)
{
u32 index = 0;
pte_t *entry;
// 从L0页表开始判断是否为空。
if (cur_ptp == NULL)
return -ENOMAPPING;
// 判断当前需要寻找的页表级别,输出虚拟页号。
switch (level) {
case L0:
index = GET_L0_INDEX(va);
break;
case L1:
index = GET_L1_INDEX(va);
break;
case L2:
index = GET_L2_INDEX(va);
break;
case L3:
index = GET_L3_INDEX(va);
break;
default:
BUG("unexpected level\n");
return -EINVAL;
}
// 获得当前索引内的虚拟页号。
entry = &(cur_ptp->ent[index]);
if (IS_PTE_INVALID(entry->pte)) {
if (alloc == false) {
return -ENOMAPPING; // 判断当前的索引是否有效。
} else {
// 在映射过程中,对没有形成索引的进行重新分配。
/* alloc a new page table page */
ptp_t *new_ptp;
paddr_t new_ptp_paddr;
pte_t new_pte_val;
/* alloc a single physical page as a new page table page
*/
new_ptp = get_pages(0);
if(rss)
*rss += PAGE_SIZE; // 分配了一个新的物理页,可能是真实物理页,也有可能是页号页。这是完成挑战所补充的。
if (new_ptp == NULL)
return -ENOMEM;
memset((void *)new_ptp, 0, PAGE_SIZE);
new_ptp_paddr = virt_to_phys((vaddr_t)new_ptp);
new_pte_val.pte = 0;
new_pte_val.table.is_valid = 1;
new_pte_val.table.is_table = 1;
new_pte_val.table.next_table_addr = new_ptp_paddr
>> PAGE_SHIFT;
/* same effect as: cur_ptp->ent[index] = new_pte_val; */
entry->pte = new_pte_val.pte;
}
}
*next_ptp = (ptp_t *)GET_NEXT_PTP(entry);
*pte = entry;
if (IS_PTE_TABLE(entry->pte))
return NORMAL_PTP;
else
return BLOCK_PTP;
}
从上我们可以看到,返回的是该条目是指向一个页表页(NORMAL_PTP)还是一个页块页(BLOCK_PTP)。在这其中,如果进行查询时没有找到对应的下一级页表或者物理块,就会返回-ENOMAPPING。因此,我们只需要逐层寻找页表来填写我们的物理地址和索引项即可。
接下来我们还需要了解一下我们的页表结构。这一部分位于kernel/include/arch/aarch64/arch/mm/page_table.h中。
首先是页表的结构体。我们只需要了解到:
- ChCore中不存在L0页块。可以看到不存在l0_block.
- 在Union中,我们有is_valid,is_table。这是判断该块是否合法,是否是一个页表的方式。
- pfn是指向下一级页表或者是物理页块的部分。每一个页块所拥有的物理页号长度不同,这也很容易理解。这是因为在物理地址长度固定的情况下,页内偏移所需要的偏移量越多,其物理页号长度越短。
- pte:当前页表项在当前页表内的索引。
- 后面定义的就是这个结构体的一个数组。也就是整个页表。而前面的union结构体是用于抽象页表项的。
// clang-format off
/* table format, which cannot be recognized by clang-format 1.10 */
typedef union {
struct {
u64 is_valid : 1,
is_table : 1,
...
next_table_addr : 36,
...
} table;
struct {
u64 is_valid : 1,
is_table : 1,
...
pfn : 18,
...
} l1_block;
struct {
u64 is_valid : 1,
is_table : 1,
...
pfn : 27,
...
} l2_block;
struct {
u64 is_valid : 1,
is_page : 1,
...
pfn : 36,
...
} l3_page;
u64 pte;
} pte_t;
// clang-format on
/* page_table_page type */
typedef struct {
pte_t ent[PTP_ENTRIES];
} ptp_t;
除了上述的页表结构体外,还有一些很有用的宏定义(函数,掩码)等,非常适合我们使用。
// 判断当前是否是合法的页表项,或者是否指向了下一级页表。
#define IS_PTE_INVALID(pte) (!((pte) & AARCH64_MMU_PTE_INVALID_MASK))
#define IS_PTE_TABLE(pte) (!!((pte) & AARCH64_MMU_PTE_TABLE_MASK))
/* PAGE_SIZE (4k) == (1 << (PAGE_SHIFT)) */
// 页内偏移 12位。
#define PAGE_SHIFT (12)
#define PAGE_MASK (PAGE_SIZE - 1) // 掩码,用于和虚拟地址取&得到低12位的值。
#define PAGE_ORDER (9) // 一个页号含有的页表项的阶次。
// 定义了不同的物理页块的页内偏移。
#define PTP_INDEX_MASK ((1 << (PAGE_ORDER)) - 1)
#define L0_INDEX_SHIFT ((3 * PAGE_ORDER) + PAGE_SHIFT)
#define L1_INDEX_SHIFT ((2 * PAGE_ORDER) + PAGE_SHIFT)
#define L2_INDEX_SHIFT ((1 * PAGE_ORDER) + PAGE_SHIFT)
#define L3_INDEX_SHIFT ((0 * PAGE_ORDER) + PAGE_SHIFT)
// 这里可以获得在不同级别页表下的索引项!因为每个页表的虚拟页号为9位,因此进行相对应的移位掩码操作即可。
#define GET_L0_INDEX(addr) (((addr) >> L0_INDEX_SHIFT) & PTP_INDEX_MASK)
#define GET_L1_INDEX(addr) (((addr) >> L1_INDEX_SHIFT) & PTP_INDEX_MASK)
#define GET_L2_INDEX(addr) (((addr) >> L2_INDEX_SHIFT) & PTP_INDEX_MASK)
#define GET_L3_INDEX(addr) (((addr) >> L3_INDEX_SHIFT) & PTP_INDEX_MASK)
#define PTP_ENTRIES (1UL << PAGE_ORDER)
/* Number of 4KB-pages that an Lx-block describes */
// 一个对应索引指向了多少个对应的4kb物理页块。
#define L0_PER_ENTRY_PAGES ((PTP_ENTRIES) * (L1_PER_ENTRY_PAGES))
#define L1_PER_ENTRY_PAGES ((PTP_ENTRIES) * (L2_PER_ENTRY_PAGES))
#define L2_PER_ENTRY_PAGES ((PTP_ENTRIES) * (L3_PER_ENTRY_PAGES))
#define L3_PER_ENTRY_PAGES (1)
/* Bitmask used by GET_VA_OFFSET_Lx */
// 后面用于计算物理页块偏移。
#define L1_BLOCK_MASK ((L1_PER_ENTRY_PAGES << PAGE_SHIFT) - 1)
#define L2_BLOCK_MASK ((L2_PER_ENTRY_PAGES << PAGE_SHIFT) - 1)
#define L3_PAGE_MASK ((L3_PER_ENTRY_PAGES << PAGE_SHIFT) - 1)
#define GET_VA_OFFSET_L1(va) ((va) & L1_BLOCK_MASK)
#define GET_VA_OFFSET_L2(va) ((va) & L2_BLOCK_MASK)
#define GET_VA_OFFSET_L3(va) ((va) & L3_PAGE_MASK)
这样我们进行逐级搜索,判断是否为页表页描述项还是物理块描述项,返回需要的entry和物理地址。
!注意索引项是否为空。如果为空仍然填写会导致低地址部分的映射错误。
/*
* Translate a va to pa, and get its pte for the flags
*/
int query_in_pgtbl(void *pgtbl, vaddr_t va, paddr_t *pa, pte_t **entry)
{
/* LAB 2 TODO 4 BEGIN */
/*
* Hint: Walk through each level of page table using `get_next_ptp`,
* return the pa and pte until a L2/L3 block or page, return
* `-ENOMAPPING` if the va is not mapped.
*/
/* BLANK BEGIN */
ptp_t *cur_ptp, *next_ptp; // 当前页表页和下一个页表页。
pte_t *pte; // 页表项。
int ret; // 当前页表项的状态。
// 获得L0页表。注意不需要分配新的页表页。
cur_ptp = (ptp_t *) pgtbl;
ret = get_next_ptp(cur_ptp, L0, va, &next_ptp, &pte, false, NULL);
if (ret < 0)
return ret; // -ENOMAPPING,直接返回即可。
else if (ret == BLOCK_PTP)
{
// No L0_block.
kdebug("L0 BLOCK!\n");
return -1;
}
// 获得L1页表。
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L1, va, &next_ptp, &pte, false, NULL);
if (ret < 0)
return ret;
else if (ret == BLOCK_PTP)
{
/**
* 47-30 位是l1的页表项中存储的物理块号。
* 29-0 位是物理块内偏移。
*/
*pa = (pte -> l1_block.pfn << L1_INDEX_SHIFT) + (GET_VA_OFFSET_L1(va));
if (entry) // 注意entry不能为空!如果为空仍然修改会导致指向错误的物理页。
*entry = pte;
return ret;
}
// Get L2 page table.
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L2, va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
else if (ret == BLOCK_PTP)
{
/**
* 47-21 位是l2的页表项中存储的物理块号。
* 20-0 位是物理块内偏移。
*/
*pa = (pte -> l2_block.pfn << L2_INDEX_SHIFT) + (GET_VA_OFFSET_L2(va));
if (entry)
*entry = pte;
return ret;
}
// Get L3 page table.
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L3, va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
else if(ret == BLOCK_PTP)
{
kdebug("why L3 block???\n");
return -1;
}
*pa = (pte -> l3_page.pfn << L3_INDEX_SHIFT) + (GET_VA_OFFSET_L3(va));
if (entry)
*entry = pte;
/* BLANK END */
/* LAB 2 TODO 4 END */
return 0;
}
在进行映射的过程中也是一样的。我们循环地给对每一个4kb范围内的虚拟页号和物理页号进行映射,也就是将虚拟页号指向的L3索引内填入对应的物理页表首地址。注意我们在get_next_ptp中每分配一个物理页块就需要给rss加上一。
// 在get_next_ptp中需要计算rss。
/*
* Find next page table page for the "va".
*
* cur_ptp: current page table page
* level: current ptp level
*
* next_ptp: returns "next_ptp"
* pte : returns "pte" (points to next_ptp) in "cur_ptp"
*
* alloc: if true, allocate a ptp when missing
*
* @returns
* @param -ENOMAPPING: No Mapping.
* @param -EINVAL: The level of page table error.
* @param NORMAL_PTP: the normal page table page.
* @param BLOCK_PTP: point to the block.
*/
static int get_next_ptp(ptp_t *cur_ptp, u32 level, vaddr_t va, ptp_t **next_ptp,
pte_t **pte, bool alloc, __maybe_unused long *rss)
{
u32 index = 0;
pte_t *entry;
if (cur_ptp == NULL)
return -ENOMAPPING;
switch (level) {
case L0:
index = GET_L0_INDEX(va);
break;
case L1:
index = GET_L1_INDEX(va);
break;
case L2:
index = GET_L2_INDEX(va);
break;
case L3:
index = GET_L3_INDEX(va);
break;
default:
BUG("unexpected level\n");
return -EINVAL;
}
entry = &(cur_ptp->ent[index]);
if (IS_PTE_INVALID(entry->pte)) {
if (alloc == false) {
return -ENOMAPPING;
} else {
/* alloc a new page table page */
ptp_t *new_ptp;
paddr_t new_ptp_paddr;
pte_t new_pte_val;
/* alloc a single physical page as a new page table page
*/
new_ptp = get_pages(0);
if(rss)
*rss += PAGE_SIZE;
if (new_ptp == NULL)
return -ENOMEM;
memset((void *)new_ptp, 0, PAGE_SIZE);
new_ptp_paddr = virt_to_phys((vaddr_t)new_ptp);
new_pte_val.pte = 0;
new_pte_val.table.is_valid = 1;
new_pte_val.table.is_table = 1;
new_pte_val.table.next_table_addr = new_ptp_paddr
>> PAGE_SHIFT;
/* same effect as: cur_ptp->ent[index] = new_pte_val; */
entry->pte = new_pte_val.pte;
}
}
*next_ptp = (ptp_t *)GET_NEXT_PTP(entry);
*pte = entry;
if (IS_PTE_TABLE(entry->pte))
return NORMAL_PTP;
else
return BLOCK_PTP;
}
static int map_range_in_pgtbl_common(void *pgtbl, vaddr_t va, paddr_t pa,
size_t len, vmr_prop_t flags, int kind,
__maybe_unused long *rss)
{
/* LAB 2 TODO 4 BEGIN */
/*
* Hint: Walk through each level of page table using `get_next_ptp`,
* create new page table page if necessary, fill in the final level
* pte with the help of `set_pte_flags`. Iterate until all pages are
* mapped.
* Since we are adding new mappings, there is no need to flush TLBs.
* Return 0 on success.
*/
/* BLANK BEGIN */
ptp_t *cur_ptp, *next_ptp; // The current page table and next page table.
pte_t *pte; // page table entry.
int ret; // The return result.
vaddr_t cur_va = va;
paddr_t cur_pa = pa;
u64 i = 0;
while(i < len)
{
cur_ptp = (ptp_t *) pgtbl; // get the L0 page.
cur_va = va + i;
cur_pa = pa + i;
ret = get_next_ptp(cur_ptp, L0, cur_va, &next_ptp, &pte, true, rss);
if(ret < 0)
return ret; // should be avoid only when no memory!
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L1, cur_va, &next_ptp, &pte, true, rss);
if(ret < 0)
return ret; // should be avoid only when no memory!
else if (ret == BLOCK_PTP)
{
i += (1 << L1_INDEX_SHIFT);
if(rss)
*rss += PAGE_SIZE; // 分配了物理页块,注意增加物理页块的数目。
continue;
}
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L2, cur_va, &next_ptp, &pte, true, rss);
if(ret < 0)
return ret;
else if (ret == BLOCK_PTP)
{
i += (1 << L2_INDEX_SHIFT);
if(rss)
*rss += PAGE_SIZE;
continue;
}
// get the virtual page number from va, and find it through next_ptp.
cur_ptp = next_ptp;
vaddr_t virtual_page_number = GET_L3_INDEX(cur_va);
if(rss)
*rss += PAGE_SIZE; // 分配了物理页块,注意增加物理页块的数目。
pte = &(cur_ptp -> ent[virtual_page_number]);
// get the physics number from pa to fill in page table L3.
pte -> l3_page.pfn = cur_pa >> L3_INDEX_SHIFT;
pte -> l3_page.is_valid = 1;
pte -> l3_page.is_page = 1;
set_pte_flags(pte, flags, kind);
i +=(1 << L3_INDEX_SHIFT); // 每次都需要将i增加对应的4kb(或其他物理地址长度)。
}
/* BLANK END */
/* LAB 2 TODO 4 END */
dsb(ishst);
isb();
return 0;
}
unmap和mprotect也是一样的,只不过最后要注意将当前entry的pte置为invalid,并且要调用set_pte_flags来更新对应的页表项指向的物理页的状态。需要注意的是,这里的rss变化我们会在稍后介绍。
int unmap_range_in_pgtbl(void *pgtbl, vaddr_t va, size_t len,
__maybe_unused long *rss)
{
/* LAB 2 TODO 4 BEGIN */
/*
* Hint: Walk through each level of page table using `get_next_ptp`,
* mark the final level pte as invalid. Iterate until all pages are
* unmapped.
* You don't need to flush tlb here since tlb is now flushed after
* this function is called.
* Return 0 on success.
*/
/* BLANK BEGIN */
ptp_t *cur_ptp, *next_ptp; // The current page table and next page table.
ptp_t *l0_ptp, *l1_ptp, *l2_ptp, *l3_ptp;
pte_t *pte; // page table entry.
int ret; // The return result.
u64 i = 0;
vaddr_t cur_va;
while(i < len)
{
cur_ptp = (ptp_t *) pgtbl;
l0_ptp = cur_ptp;
cur_va = va + i;
ret = get_next_ptp(cur_ptp, L0, cur_va, &next_ptp, &pte, false, rss);
if(ret < 0)
return ret;
cur_ptp = next_ptp;
l1_ptp = cur_ptp;
ret = get_next_ptp(cur_ptp, L1, cur_va, &next_ptp, &pte, false, rss);
if(ret < 0)
return ret;
else if(ret == BLOCK_PTP)
{
i += (1 << L1_INDEX_SHIFT);
pte -> pte = 0; // PTE_DESCRIPTOR_INVALID;
continue;
}
cur_ptp = next_ptp;
l2_ptp = cur_ptp;
ret = get_next_ptp(cur_ptp, L2, cur_va, &next_ptp, &pte, false, rss);
if(ret < 0)
return ret;
else if(ret == BLOCK_PTP)
{
i += (1 << L2_INDEX_SHIFT);
pte -> pte = 0; // PTE_DESCRIPTOR_INVALID;
continue;
}
cur_ptp = next_ptp;
l3_ptp = cur_ptp;
ret = get_next_ptp(cur_ptp, L3, cur_va, &next_ptp, &pte, false, rss);
if(ret < 0)
return ret;
else
{
i += (1 << L3_INDEX_SHIFT);
pte -> pte = 0;
// Delete physical pages.
if (rss)
*rss -= PAGE_SIZE;
recycle_pgtable_entry(l0_ptp,l1_ptp,l2_ptp,l3_ptp,cur_va,rss);
}
}
/* BLANK END */
/* LAB 2 TODO 4 END */
dsb(ishst);
isb();
return 0;
}
int mprotect_in_pgtbl(void *pgtbl, vaddr_t va, size_t len, vmr_prop_t flags)
{
/* LAB 2 TODO 4 BEGIN */
/*
* Hint: Walk through each level of page table using `get_next_ptp`,
* modify the permission in the final level pte using `set_pte_flags`.
* The `kind` argument of `set_pte_flags` should always be `USER_PTE`.
* Return 0 on success.
*/
/* BLANK BEGIN */
ptp_t *cur_ptp, *next_ptp; // The current page table and next page table.
pte_t *pte; // page table entry.
int ret; // The return result.
u64 i = 0;
vaddr_t cur_va;
while(i < len)
{
cur_ptp = (ptp_t *) pgtbl;
cur_va = va + i;
ret = get_next_ptp(cur_ptp, L0, cur_va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L1, cur_va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
else if(ret == BLOCK_PTP)
{
i += (1 << L1_INDEX_SHIFT);
continue;
}
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L2, cur_va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
else if(ret == BLOCK_PTP)
{
i += (1 << L2_INDEX_SHIFT);
continue;
}
cur_ptp = next_ptp;
ret = get_next_ptp(cur_ptp, L3, cur_va, &next_ptp, &pte, false, NULL);
if(ret < 0)
return ret;
else
{
i += (1 << L3_INDEX_SHIFT);
set_pte_flags(pte, flags, USER_PTE);
}
}
/* BLANK END */
/* LAB 2 TODO 4 END */
return 0;
}
计算页表释放时,我们需要减少rss。首先,我们先了解这是怎么进行物理页的释放的。首先,我们先搜索到最后一级页表。随后,调用recycle_pagetable_entry()函数。这个函数会检测当前页表内是否有没有被释放的页表项(也就是观察页表项是否pte被置0),随后如果整个页表均已经被释放,则释放整个页表。所以我们在try_release_ptp中free掉整个页表页后,rss将减去1。随后,在unmap函数中,每释放一个L3页表项就相当于释放了一个4kb物理页,减去1即可。
static int try_release_ptp(ptp_t *high_ptp, ptp_t *low_ptp, int index,
__maybe_unused long *rss)
{
int i;
for (i = 0; i < PTP_ENTRIES; i++) {
if (low_ptp->ent[i].pte != PTE_DESCRIPTOR_INVALID) {
return 0; // 检测是否还有没有释放的页表项。
}
}
BUG_ON(index < 0 || index >= PTP_ENTRIES);
high_ptp->ent[index].pte = PTE_DESCRIPTOR_INVALID;
kfree(low_ptp); // 释放当前页表。
if (rss)
*rss -= PAGE_SIZE;
return 1;
}
__maybe_unused static void recycle_pgtable_entry(ptp_t *l0_ptp, ptp_t *l1_ptp,
ptp_t *l2_ptp, ptp_t *l3_ptp,
vaddr_t va,
__maybe_unused long *rss)
{
// 逐级检测,释放页表。
if (!try_release_ptp(l2_ptp, l3_ptp, GET_L2_INDEX(va), rss))
return;
if (!try_release_ptp(l1_ptp, l2_ptp, GET_L1_INDEX(va), rss))
return;
try_release_ptp(l0_ptp, l1_ptp, GET_L0_INDEX(va), rss);
}
这样我们就完成了第二部分。
思考题5
阅读 Arm Architecture Reference Manual,思考要在操作系统中支持写时拷贝(Copy-on-Write,CoW)[^cow]需要配置页表描述符的哪个/哪些字段,并在发生页错误时如何处理。(在完成第三部分后,你也可以阅读页错误处理的相关代码,观察 ChCore 是如何支持 Cow 的)
(吐槽:这个文件超级大,每次打开都很卡。。。)
为了支持写时拷贝,需要在页表项中将 AP(Access Permissions)字段配置为只读。
只读页内发生写操作时,会触发缺页异常,操作系统检测到异常后,会重新分配一个物理页,将共享页的内容拷贝至新的物理页中,并将访问权限配置为可读可写,然后更新页表映射。
在aarch64架构中,AP字段一般为2bits。

00: 没有影响。
01: 对于EL0(用户态)的访问受限,无论后面那个层次的查看权限是否允许。
10: 不允许写操作。无论哪个异常级别,无论接下来的层次查看权限时什么。
11: 在任意异常级别不允许写操作。在用户态不允许读操作。
在完成第三部分后,我们将会去看看Chcore是怎么进行CoW的。这里暂且按下不表。
思考题6
为了简单起见,在 ChCore 实验 Lab1 中没有为内核页表使用细粒度的映射,而是直接沿用了启动时的粗粒度页表,请思考这样做有什么问题。
一方面,为内核分配的大页通常不会被完全使用,从而产生大量内部碎片,造成内存浪费。因此需要通过细粒度的映射,结合伙伴系统和slab分配器等来控制内存碎片。
另一方面,粗粒度的页表缺少详细的权限控制,降低了内存访问的安全性。同时也不适合为后面的各种换页和写时拷贝,共享内存服务。
挑战题7
使用前面实现的page_table.c中的函数,在内核启动后的main函数中重新配置内核页表,进行细粒度的映射。
我们回去参考实验一中的页表映射。
在内核启动时,首先需要对内核自身、其余可用物理内存和外设内存进行虚拟地址映射,最简单的映射方式是一对一的映射,即将虚拟地址
0xffff_0000_0000_0000 + addr映射到addr。需要注意的是,在 ChCore 实验中我们使用了0xffff_ff00_0000_0000作为内核虚拟地址的开始(注意开头f数量的区别),不过这不影响我们对知识点的理解。
| 物理地址范围 | 对应设备 |
|---|---|
0x00000000~0x3f000000 |
物理内存(SDRAM) |
0x3f000000~0x40000000 |
共享外设内存 |
0x40000000~0xffffffff |
本地(每个 CPU 核独立)外设内存 |
再次观察我们的ChCore启动过程。

观察我们的main函数。
...
/* Init mm */
mm_init(info);
kinfo("[ChCore] mm init finished\n");
...
/* Mapping KSTACK into kernel page table. */
map_range_in_pgtbl_kernel((void*)((unsigned long)boot_ttbr1_l0 + KBASE),
KSTACKx_ADDR(0),
(unsigned long)(cpu_stacks[0]) - KBASE,
CPU_STACK_SIZE, VMR_READ | VMR_WRITE);
// 在这里进行细粒度的高地址映射。
arch_interrupt_init();
timer_init();
...
我们可以发现我们先进行mm_init初始化mmu和开启mmu,随后将TTBR0_EL1的虚拟地址映射到对应的物理地址。因此我们只需要配置上面的各个虚拟地址,将他们映射到高地址空间即可。注意内核空间部分地址也需要重新进行映射。最后刷新TLB页表。
这样我们有:
#define PHYSICAL_START (0x0UL)
#define DEVICE_START (0x3F000000UL)
#define DEVICE_END (0x40000000UL)
#define PHYSICAL_END (0x80000000UL)
#define KERNEL_OFFSET (0xffffff0000000000)
// 获得物理页。
volatile void * ttbr1_el1 = get_pages(0);
// 将内核空间进行细粒度映射。
map_range_in_pgtbl_kernel((void *)ttbr1_el1,
KSTACKx_ADDR(0),
virt_to_phys(cpu_stacks[0]), CPU_STACK_SIZE,
VMR_READ | VMR_WRITE);
// 映射物理内存SDRAM。注意修改虚拟空间的映射类型。
// VMR相关类型定义位于:kernel/user-include/uapi/memory.h。
map_range_in_pgtbl_kernel((void *)ttbr1_el1,
KERNEL_OFFSET + PHYSICAL_START,
PHYSICAL_START,
DEVICE_START - PHYSICAL_START,
VMR_EXEC);
// 映射设备(共享外设内存地址)。
map_range_in_pgtbl_kernel((void *)ttbr1_el1,
KERNEL_OFFSET + DEVICE_START,
DEVICE_START,
DEVICE_END - DEVICE_START,
VMR_DEVICE);
// 映射本地CPU外设内存。
map_range_in_pgtbl_kernel((void *)ttbr1_el1,
KERNEL_OFFSET + DEVICE_END,
DEVICE_END,
PHYSICAL_END - DEVICE_END,
VMR_DEVICE);
flush_tlb_all(); // 刷新TLB。
kinfo("[ChCore] kernel remap finished\n");
#undef PHYSICAL_START
#undef DEVICE_START
#undef DEVICE_END
#undef PHYSICAL_END
这样我们完成了细粒度的映射。
缺页处理
接下来就是本次实验的最后一部分,缺页处理异常。
缺页异常(page fault)是操作系统实现延迟内存分配的重要技术手段。当处理器发生缺页异常时,它会将发生错误的虚拟地址存储于 FAR_ELx 寄存器中,并触发相应的异常处理流程。ChCore 对该异常的处理最终实现在 kernel/arch/aarch64/irq/pgfault.c 中的 do_page_fault 函数。本次实验暂时不涉及前面的异常初步处理及转发相关内容,我们仅需要关注操作系统是如何处缺页异常的。
练习题8
完成kernel/arch/aarch64/irq/pgfault.c中的do_page_fault函数中的LAB 2 TODO 5部分,将缺页异常转发给handle_trans_fault函数。
只需要将异常转发出去就好了。获得当前的线程所处于的虚拟地址环境,以及出现缺页异常地址。我们只需直接调用函数即可。
/* LAB 2 TODO 5 BEGIN */
/* BLANK BEGIN */
ret = handle_trans_fault(current_thread->vmspace, fault_addr);
/* BLANK END */
/* LAB 2 TODO 5 END */
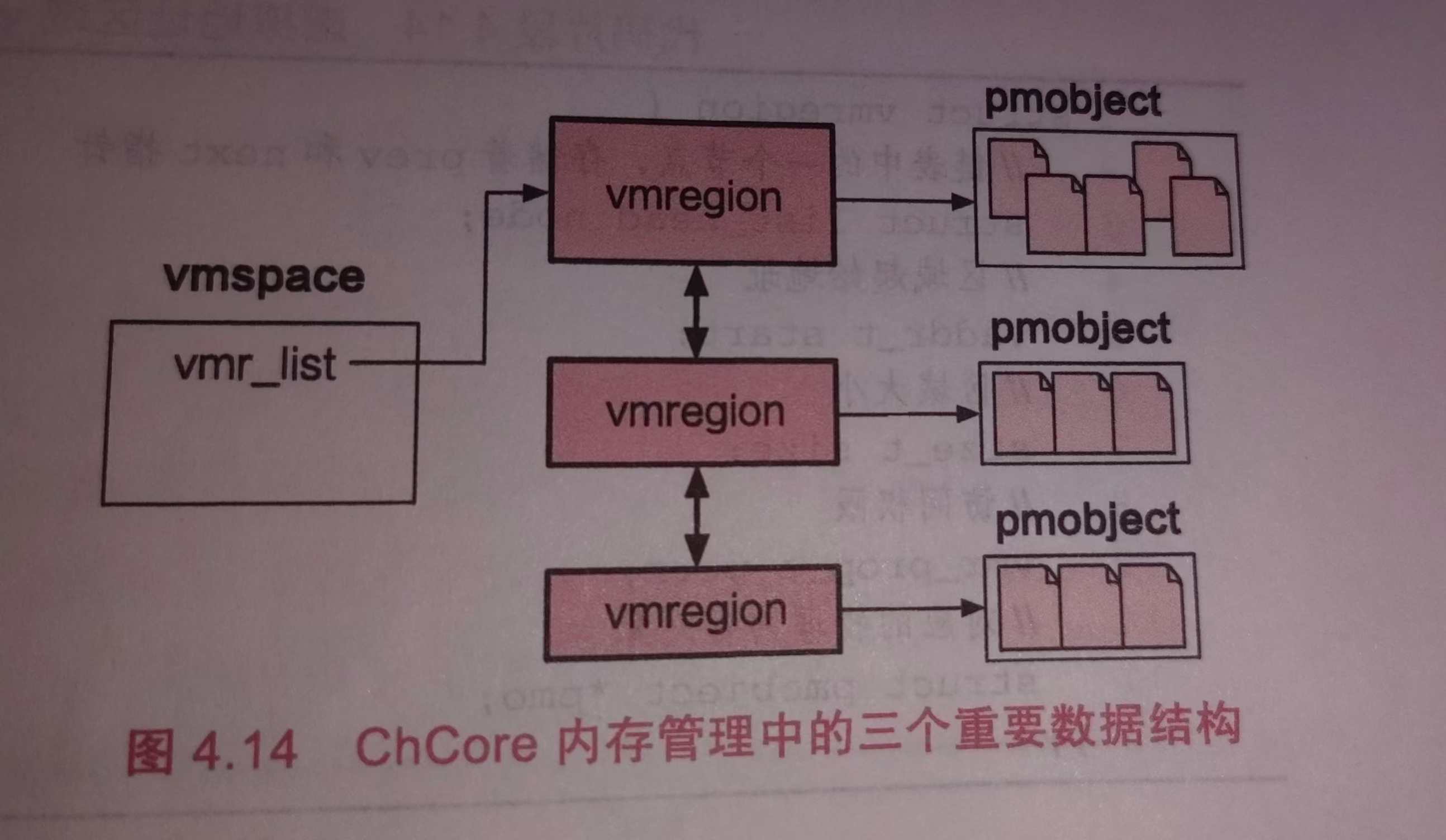
在 ChCore 中,一个进程的虚拟地址空间由多段“虚拟地址区域”(VMR,又称 VMA)组成,一段 VMR 记录了这段虚拟地址对应的“物理内存对象”(PMO),而 PMO 中则记录了物理地址相关信息。因此,想要处理缺页异常,首先需要找到当前进程发生页错误的虚拟地址所处的 VMR,进而才能得知其对应的物理地址,从而在页表中完成映射。
练习题9
完成kernel/mm/vmspace.c中的find_vmr_for_va函数中的LAB 2 TODO 6部分,找到一个虚拟地址找在其虚拟地址空间中的 VMR。
- 一个虚拟地址空间所包含的 VMR 通过 rb_tree 的数据结构保存在
vmspace结构体的vmr_tree字段- 可以使用
kernel/include/common/rbtree.h中定义的rb_search、rb_entry等函数或宏来对 rb_tree 进行搜索或操作
我们首先还是先关注一下我们的虚拟地址是怎样的一个结构体来进行维护的。这位于kernel/include/mm/vmspace.h中。
/* This struct represents one virtual memory region inside on address space */
// 虚拟内存区域。
struct vmregion {
// 维护vmr_list的node部分。其中采用红黑树进行管理,可以减少查询和修改时间。
struct list_head list_node; /* As one node of the vmr_list */
struct rb_node tree_node; /* As one node of the vmr_tree */
// 用这上面的节点追溯到所属于的虚拟空间。
/* As one node of the pmo's mapping_list */
struct list_head mapping_list_node; // 映射到pmobject的节点。
struct vmspace *vmspace;
vaddr_t start;
size_t size;
/* Offset of underlying pmo */
size_t offset;
vmr_prop_t perm; // 权限,对应的物理内存对象,以及写时拷贝操作等。
struct pmobject *pmo;
struct list_head cow_private_pages;
};
/* This struct represents one virtual address space */
// 虚拟地址空间。
struct vmspace {
// 虚拟空间的头节点,以及在红黑树内的跟节点。
/* List head of vmregion (vmr_list) */
struct list_head vmr_list;
/* rbtree root node of vmregion (vmr_tree) */
struct rb_root vmr_tree; // 这个是我们需要传入红黑树搜索的根节点。
// 具有的跟页表,以及相对应的防止TLB冲突的表示。
/* Root page table */
void *pgtbl;
/* Address space ID for avoiding TLB conflicts */
unsigned long pcid;
/* The lock for manipulating vmregions */
struct lock vmspace_lock;
/* The lock for manipulating the page table */
struct lock pgtbl_lock;
/*
* For TLB flushing:
* Record the all the CPU that a vmspace ran on.
*/
unsigned char history_cpus[PLAT_CPU_NUM];
struct vmregion *heap_boundary_vmr;
/* Records size of memory mapped. Protected by pgtbl_lock. */
long rss; // 这里就是需要记录的分配了多少物理页。
};
红黑树的实现是很漂亮的,我们应该掌握这样的数据结构。(我一定会去认真看的!kernel/lib/rbtree.c doge)篇幅有限,这里仅展示我们要使用的api。
struct rb_node {
unsigned long __parent_color; // 颜色
struct rb_node *right_child; // 不用说也知道的二叉孩子
struct rb_node *left_child;
} __attribute__((aligned(sizeof(long))));
struct rb_root {
struct rb_node *root_node;
};
#define rb_entry(node, type, field) container_of(node, type, field)
// 定义的比较函数,可以参考C++。
typedef int (*comp_node_func)(const struct rb_node *lhs,
const struct rb_node *rhs);
typedef int (*comp_key_func)(const void *key, const struct rb_node *node);
typedef bool (*less_func)(const struct rb_node *lhs, const struct rb_node *rhs);
// 搜索对应的节点。
struct rb_node *rb_search(struct rb_root *this, const void *key,
comp_key_func cmp);
这样,我们就明确我们需要进行的操作:
- 利用传进来的虚拟地址空间结构内的根节点,搜索当前虚拟地址属于的虚拟地址区域。这就是采用红黑树进行搜索的。
- 判断是否返回的是一个空的NULL。为后面缺页异常重新映射做准备。
- 如果非空,利用我们的container函数,从当前的节点追溯到虚拟空间,返回即可。
/* This function should be surrounded with the vmspace_lock. */
__maybe_unused struct vmregion *find_vmr_for_va(struct vmspace *vmspace,
vaddr_t addr)
{
/* LAB 2 TODO 6 BEGIN */
/* Hint: Find the corresponding vmr for @addr in @vmspace */
/* BLANK BEGIN */
struct rb_node *result_node = rb_search(&vmspace->vmr_tree, (const void *)addr, cmp_vmr_and_va);
if (result_node)
{
kdebug("FOUND %p \n", addr);
}
else
{
kdebug("Not FOUND %p \n", addr);
}
return result_node ? rb_entry(result_node, struct vmregion, tree_node) : NULL;
/* BLANK END */
/* LAB 2 TODO 6 END */
}
缺页处理主要针对 PMO_SHM 和 PMO_ANONYM 类型的 PMO,这两种 PMO 的物理页是在访问时按需分配的。缺页处理逻辑为首先尝试检查 PMO 中当前 fault 地址对应的物理页是否存在(通过 get_page_from_pmo 函数尝试获取 PMO 中 offset 对应的物理页)。若对应物理页未分配,则需要分配一个新的物理页,再将页记录到 PMO 中,并增加页表映射。若对应物理页已分配,则只需要修改页表映射即可。
练习题10
完成kernel/mm/pgfault_handler.c中的handle_trans_fault函数中的LAB 2 TODO 7部分(函数内共有 3 处填空,不要遗漏),实现PMO_SHM和PMO_ANONYM的按需物理页分配。你可以阅读代码注释,调用你之前见到过的相关函数来实现功能。
最后一部分我们需要完成的是缺页异常的处理。对于没有分配的物理页,也就是在get_page_from_pmo失败后,我们需要重新分配物理页,对应的是pa==0的情况。分配物理页时请注意初始化为0。
void * va = get_pages(0);
pa = virt_to_phys(va);
memset(va, 0, PAGE_SIZE);
分配完物理页后,我们需要将其添加映射到当前虚拟空间基地址指向的页表结构中。
/* Add mapping in the page table */
lock(&vmspace->pgtbl_lock);
/* BLANK BEGIN */
map_range_in_pgtbl(vmspace->pgtbl, fault_addr, pa, PAGE_SIZE, perm, NULL);
/* BLANK END */
如果已经存在了物理页但是是因为换页导致的缺失,只需要重新换入/重新映射即可。
/* BLANK BEGIN */
map_range_in_pgtbl(vmspace->pgtbl, fault_addr, pa, PAGE_SIZE, perm, NULL);
/* BLANK END */
[!CHALLENGE] 挑战题 11
我们在map_range_in_pgtbl_common、unmap_range_in_pgtbl函数中预留了没有被使用过的参数rss用来来统计map映射中实际的物理内存使用量[^rss],
你需要修改相关的代码来通过Compute physical memory测试,不实现该挑战题并不影响其他部分功能的实现及测试。如果你想检测是否通过此部分测试,需要修改.config中CHCORE_KERNEL_PM_USAGE_TEST为ON
参考开头和中间的map,unmap部分即可。
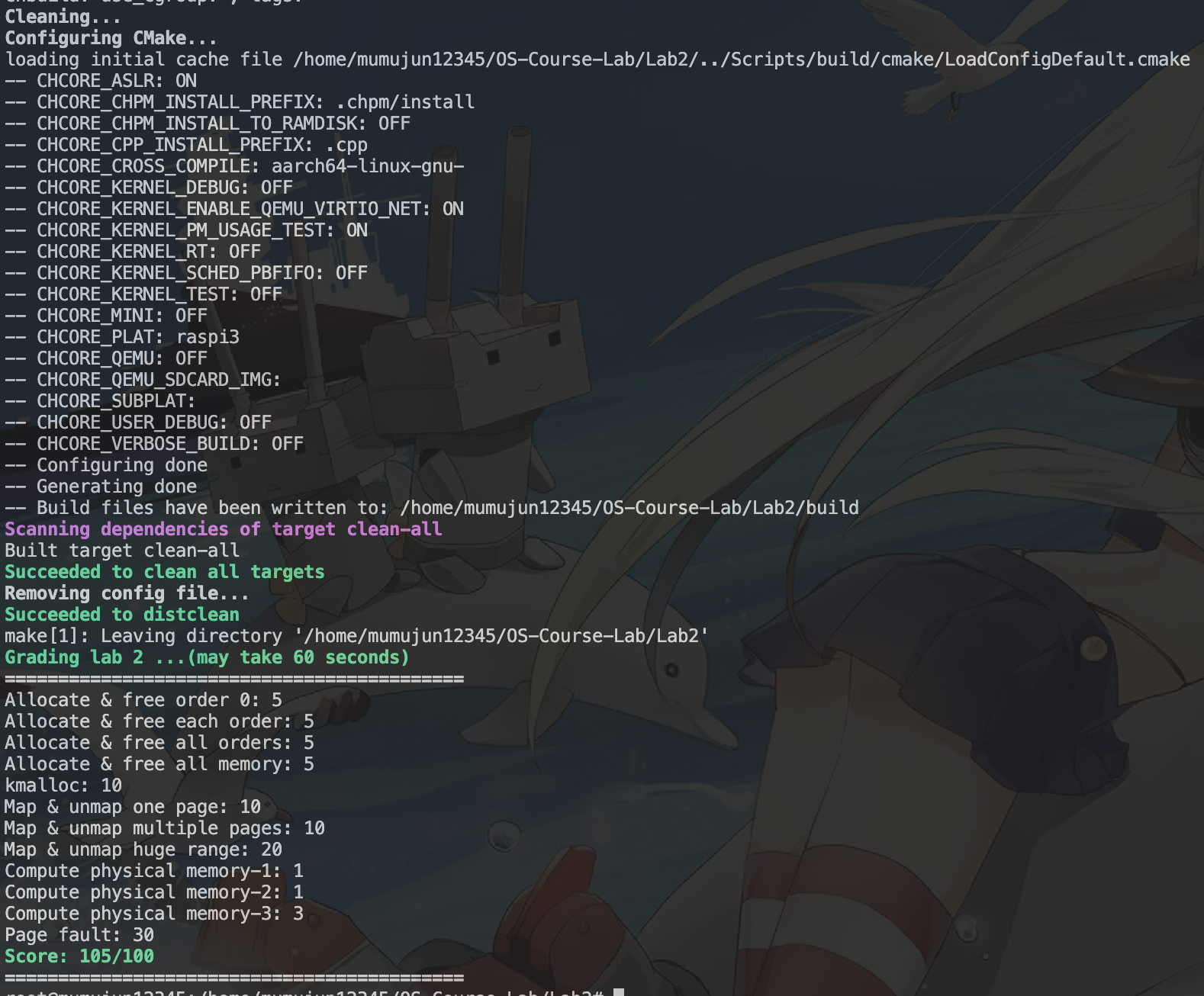
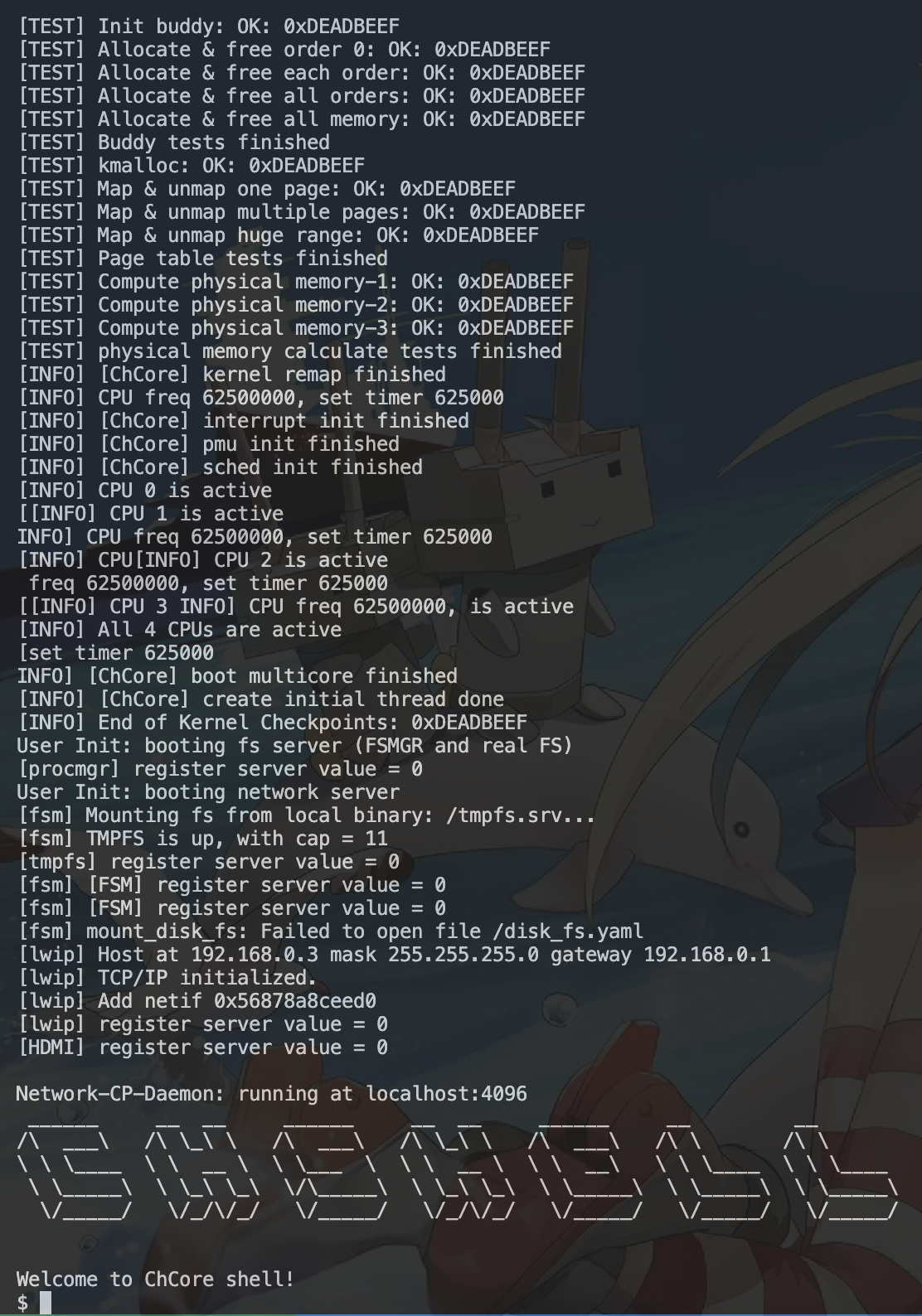
最终展示结果:
实验2结束。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号