MapReduce入门(品读WordCount)
解读WordCount
WordCount程序就是MapReduce的HelloWord程序。通过对WordCount程序分析,我们可以了解MapReduce程序的基本结构和执行过程。
WordCount设计思路
WordCount程序很好的体现了MapReduce编程思想。
一般来说,文本作为MapReduce的输入,MapReduce会将文本进行切分处理并将行号作为输入键值对的键,文本内容作为键值对的值,经map方法处理后,输出中间结果为<word,1>形式。MapReduce会默认按键值分发给reduce方法,在完成计数并输出最后结果<word,count>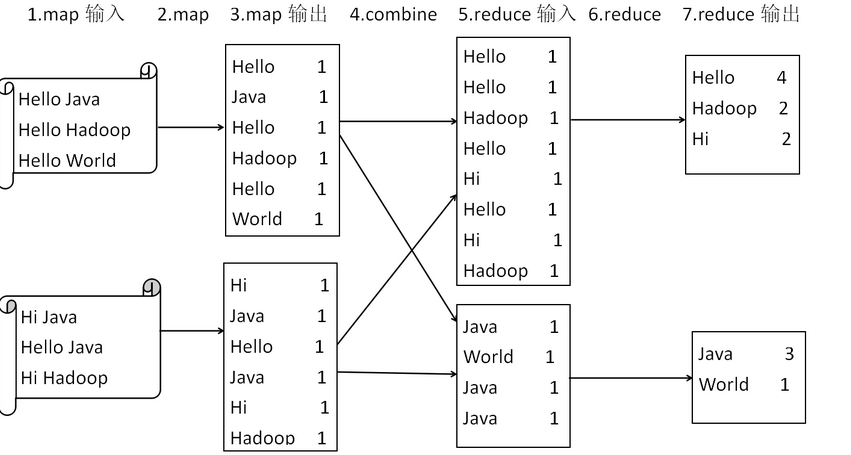
MapReduce运行方式
MapReduce运行方式分为本地运行和服务端运行两种。
本地运行多指本地Windows环境,方便开发调试。
而服务端运行,多用于实际生产环境。
hadoop本地安装
下载hadoop-2.7.3.tar.gz,解压缩。比如解压缩到D盘
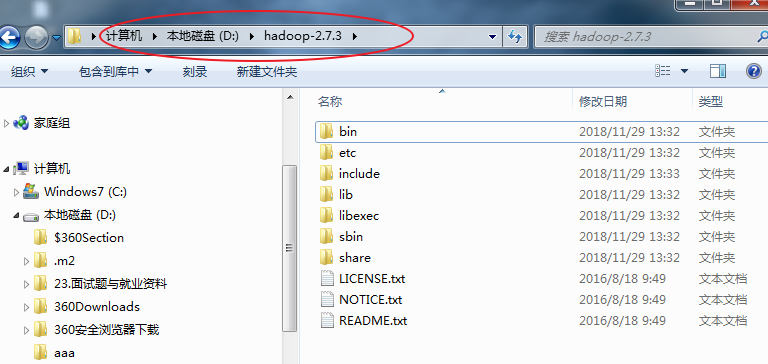
hadoop根目录就是D:\hadoop-2.7.3
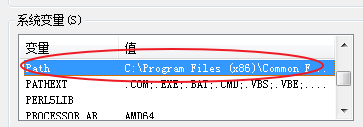
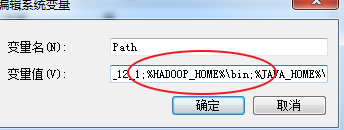
配置环境变量
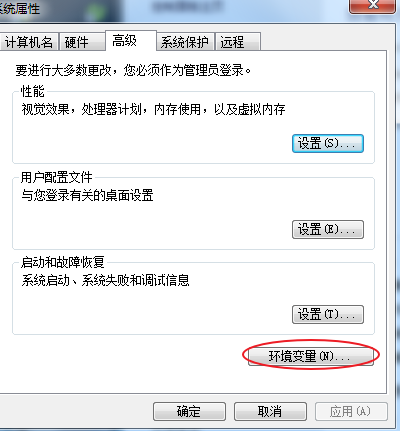
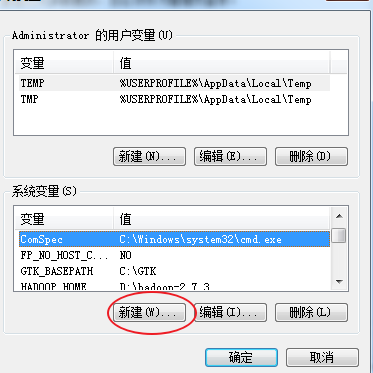

path环境配置
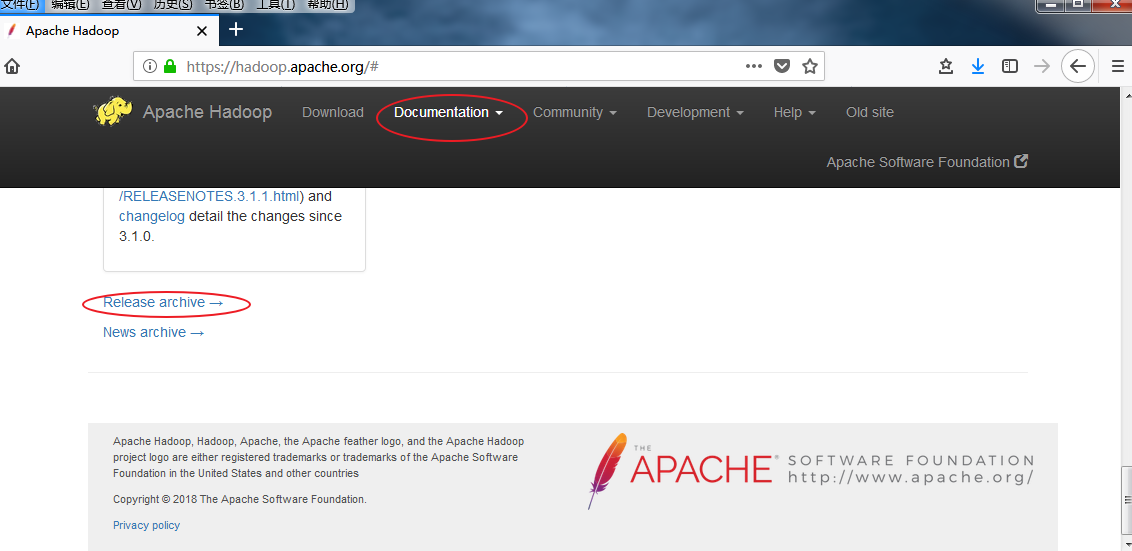
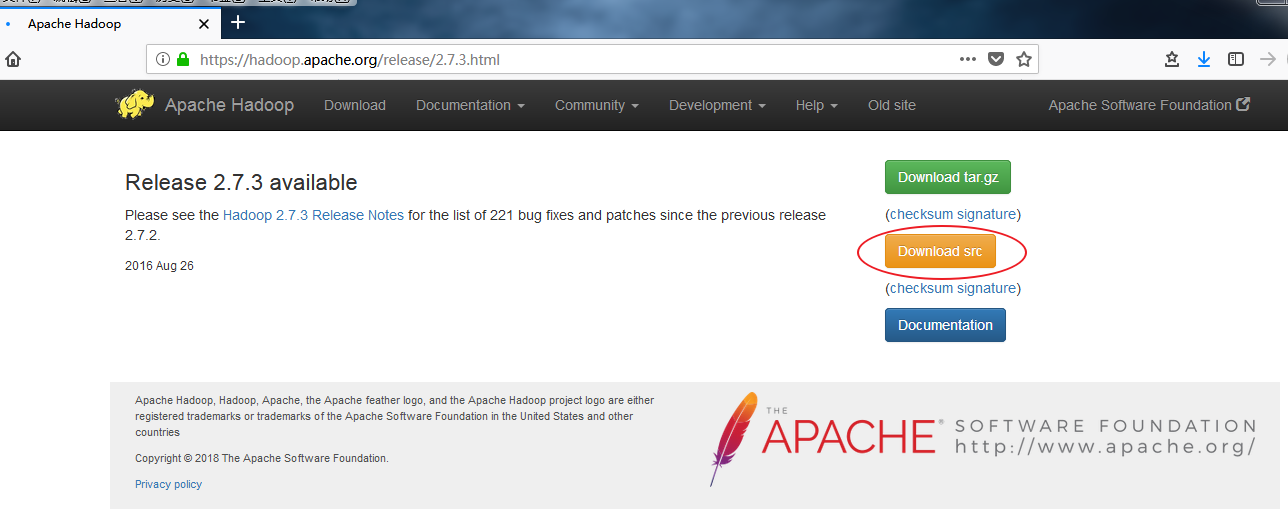
下载对应hadoop源代码
hadoop-2.7.3-src.tar.gz

修改Hadoop源码
注意,在Windows本地运行MapReduce程序时,需要修改Hadoop源码。如果在Linux服务器运行,则不需要修改Hadoop源码。
修改Hadoop源码,其实就是简单修改一下Hadoop的NativeIO类的源码
下载对应hadoop源代码,hadoop-2.7.3-src.tar.gz解压,hadoop-2.7.3-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的IDEA的project.
修改代码


修改代码
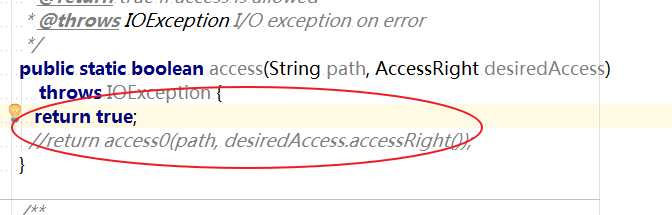
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
//return access0(path, desiredAccess.accessRight());
}
如果不修改NativeIO类的源码,在Windows本地运行MapReduce程序会产生异常:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609) at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977) at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187) at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174) at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115) at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:125) at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163) at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:240) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308) at cn.hadron.mr.RunJob.main(RunJob.java:33)
定义Mapper类
package com.hadron.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
//4个泛型参数:前两个表示map的输入键值对的key和value的类型,后两个表示输出键值对的key和value的类型
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
//该方法循环调用,从文件的split中读取每行调用一次,把该行所在的下标为key,该行的内容为value
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String [] words = StringUtils.split(value.toString(),' ');
for ( String w : words
) {
context.write(new Text(w), new IntWritable(1));
}
}
}
代码说明:
Mapper类用于读取数据输入并执行map方法,编写Mapper类需要继承org.apache.hadoop.mapreduce.Mapper类,并且根据相应问题实现map方法。
Mapper类的4个泛型参数:前两个表示map的输入键值对的key和value的类型,后两个表示输出键值对的key和value的类型
MapReduce计算框架会将键值对作为参数传递给map方法。该方法有3个参数,第1个是Object类型(一般使用LongWritable类型)参数,代表行号,第2个是Object类型参数(一般使用Text类型),代表该行内容,第3个Context参数,代表上下文。
Context类全名是org.apache.hadoop.mapreduce.Mapper.Context,也就是说Context类是Mapper类的静态内容类,在Mapper类中可以直接使用Context类。
在map方法中使用StringUtils的split方法,按空格将输入行内容分割成单词,然后通过Context类的write方法将其作为中间结果输出。
定义Reducer类
package com.hadron.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
* Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,
* 每组调用一次,这一组数据特点:key相同,value可能有多个。
* /所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
*/
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum=0;
for ( IntWritable i: values
) {
sum=sum+i.get();
}
context.write(key,new IntWritable(sum));
}
}
代码说明:
Reducer类用于接收Mapper输出的中间结果作为Reducer类的输入,并执行reduce方法。
Reducer类的4个泛型参数:前2个代表reduce方法输入的键值对类型(对应map输出类型),后2个代表reduce方法输出键值对的类型
reduce方法参数:key是单个单词,values是对应单词的计数值所组成的列表,Context类型是org.apache.hadoop.mapreduce.Reducer.Context,是Reducer的上下文。
定义主方法(主类)
package com.hadron.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
//设置环境变量HADOOP_USER_NAME,其值是root
System.setProperty("HADOOP_USER_NAME", "root");
//Configuration类包含了Hadoop的配置
Configuration conf =new Configuration();
//设置fs.defaultFS
conf.set("fs.defaultFS", "hdfs://192.168.55.128:9000");
//设置yarn.resourcemanager节点
conf.set("yarn.resourcemanager.hostname", "node1");
try {
FileSystem fs =FileSystem.get(conf);
Job job =Job.getInstance(conf);
job.setJarByClass(RunJob.class);
job.setJobName("wc");
//设置Mapper类
job.setMapperClass(WordCountMapper.class);
//设置Reduce类
job.setReducerClass(WordCountReducer.class);
//设置reduce方法输出key的类型
job.setOutputKeyClass(Text.class);
//设置reduce方法输出value的类型
job.setOutputValueClass(IntWritable.class);
//指定输入路径
FileInputFormat.addInputPath(job, new Path("/user/root/input/"));
//指定输出路径(会自动创建)
Path outpath=new Path("/user/root/output");
//输出路径是MapReduce自动创建的,如果存在则需要先删除
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f=job.waitForCompletion(true);
if (f) {
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
hdfs 上 新建input目录
[root@node1 ~]# hdfs dfs -mkdir /user/root/input


本地运行
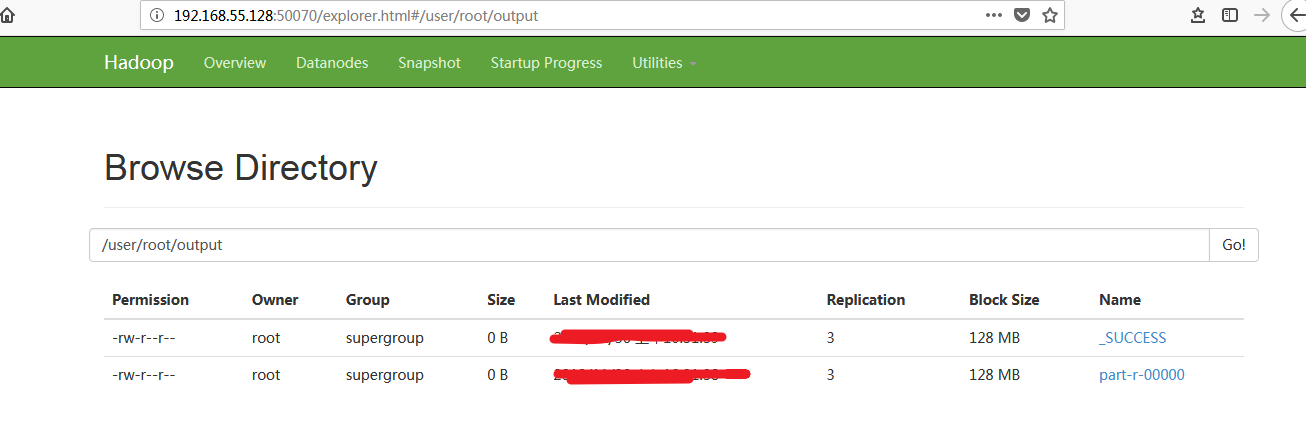
执行结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号