

1、多行文本的处理(如日志中多行异常数据归为一行)
Codec Plugin —— Multiline
设置参数:
- pattern: 设置行匹配的正则表达式
- what : 如果匹配成功,那么匹配行属于上一个事件还是下一个事件
- previous / next
- negate : 是否对pattern结果取反
- true / false
# 多行数据,异常
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
#新建配置文件
vim multiline-exception.conf
#配置文件详情,将异常日志换行归为一行
input {
stdin {
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}
filter {}
output {
stdout { codec => rubydebug }
}
#执行管道
bin/logstash -f multiline-exception.conf
复制上述异常日志,进行测试执行结果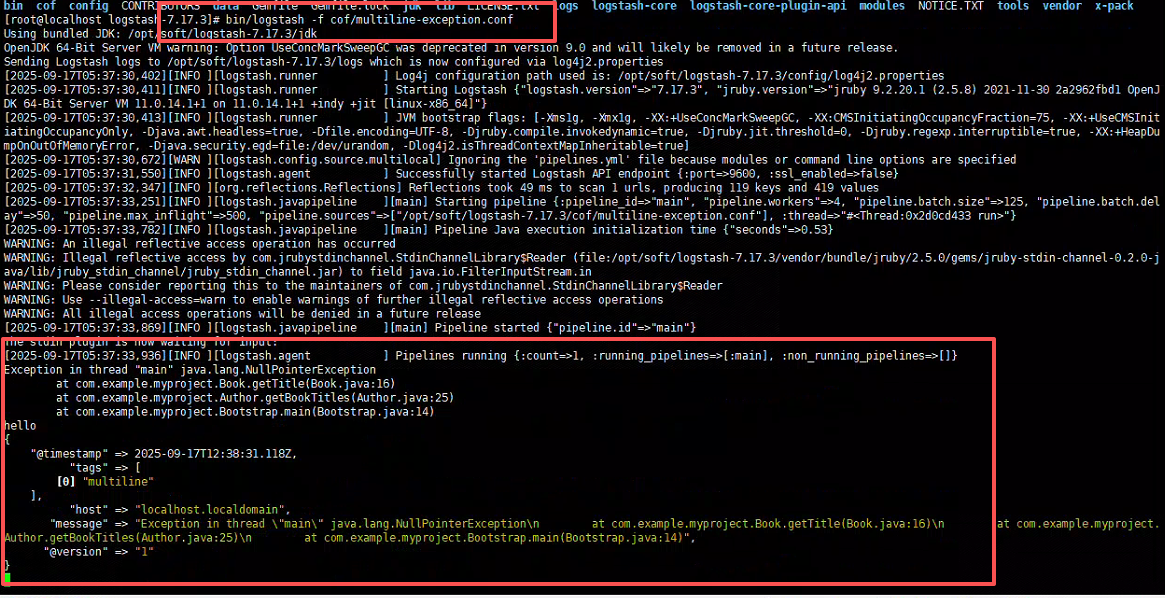
2、Logstash导入csv数据到ES
2.1前置知识
1)Filter Plugins
https://www.elastic.co/guide/en/logstash/7.17/filter-plugins.html
Filter Plugin可以对Logstash Event进行各种处理,例如解析,删除字段,类型转换
- Date: 日期解析
- Dissect: 分割符解析
- Grok: 正则匹配解析
- Mutate: 对字段做各种操作
- Convert : 类型转换
- Gsub : 字符串替换
- Split / Join /Merge: 字符串切割,数组合并字符串,数组合并数组
- Rename: 字段重命名
- Update / Replace: 字段内容更新替换
- Remove_field: 字段删除
- Ruby: 利用Ruby 代码来动态修改Event
2)Logstash Queue
- In Memory Queue
进程Crash,机器宕机,都会引起数据的丢失 - Persistent Queue
机器宕机,数据也不会丢失; 数据保证会被消费; 可以替代 Kafka等消息队列缓冲区的作用
1、持久化队列
数据存储在磁盘中,确保进程崩溃或重启后仍可恢复队列内容
2、空间限制
通过 max_bytes 参数控制队列总大小,避免磁盘空间耗尽
# pipelines.yml
queue.type: persisted (默认是memory)
queue.max_bytes: 4gb

2.1导入csv数据到ES
1)测试数据集下载:https://grouplens.org/datasets/movielens/
(如不想自己下载、篇幅二中夸克网盘可下载)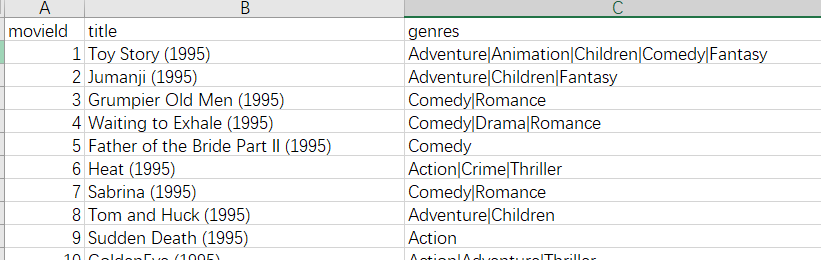
2)准备logstash-movie.conf配置文件
vim logstash-movie.confelasticsearch 记得换成自己的服务地址
file.path 表示文件地址
input {
file {
path => "/home/es/logstash-7.17.3/dataset/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
user => "elastic"
password => "123456"
}
stdout {}
}3)运行logstash
# linux
bin/logstash -f logstash-movie.conf4)运行结果
配置文件截取年份(的方式可以进行优化,不优化可能导致year取不到正确的值。自行拓展方案。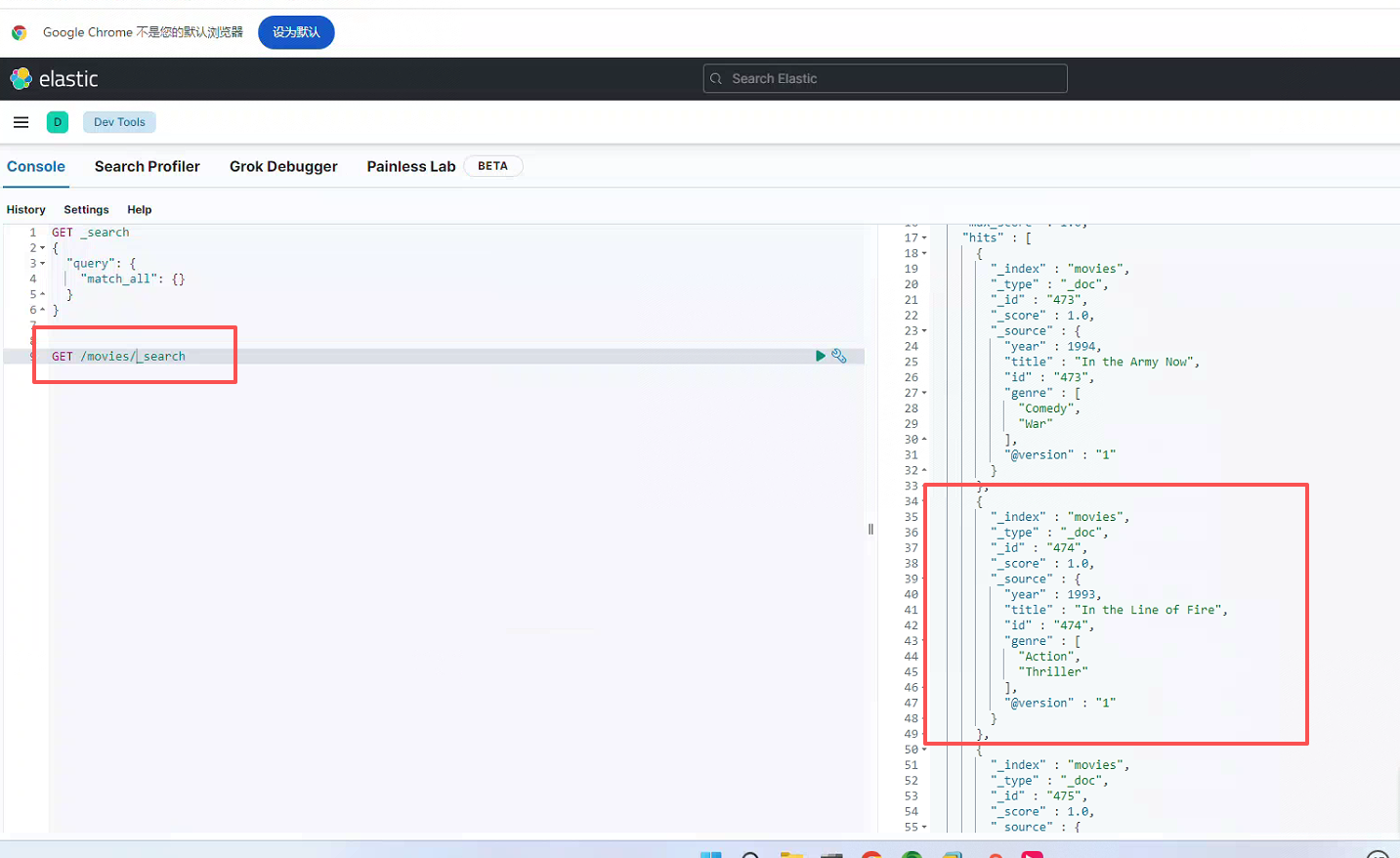
- –config.test_and_exit : 解析配置文件并报告任何错误
- –config.reload.automatic: 启用自动配置加载
3、同步mysql数据库数据到Elasticsearch
3.1需求: 将数据库中的数据同步到ES,借助ES的全文搜索,提高搜索速度
- 需要把新增用户信息同步到Elasticsearch中
- 用户信息Update 后,需要能被更新到Elasticsearch
- 支持增量更新
- 用户注销后,不能被ES所搜索到
3.2实现思路
- 基于canal同步数据(后续讲解)
- 借助JDBC Input Plugin将数据从数据库读到Logstash
- 需要自己提供所需的 JDBC Driver;(此篇以mysql驱动为主)
- 驱动自行下载、或者关注公众号"开源创富指南",回复ELK获取本系列课程所有软件。
- JDBC Input Plugin 支持定时任务 Scheduling,其语法来自 Rufus-scheduler,其扩展了 Cron,使用 Cron 的语法可以完成任务的触发;
- JDBC Input Plugin 支持通过 Tracking_column / sql_last_value 的方式记录 State,最终实现增量的更新;
- https://www.elastic.co/cn/blog/logstash-jdbc-input-plugin
3.3JDBC Input Plugin实现步骤
1)拷贝jdbc依赖到logstash-7.17.3/drivers目录下(drivers目录需要自己建,原本没有)
2)准备mysql-demo.conf配置文件
3) 需要安装mysql数据库,可参考我的博客(https://blog.csdn.net/qq_38132995/article/details/107122088?fromshare=blogdetail&sharetype=blogdetail&sharerId=107122088&sharerefer=PC&sharesource=qq_38132995&sharefrom=from_link)
4)配置文件需要配置好你自己的mysql和elasticsearch
vim mysql-demo.confinput {
jdbc {
jdbc_driver_library => "/opt/soft/logstash-7.17.3/drivers/mysql-connector-java-5.1.49.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useSSL=false"
jdbc_user => "root"
jdbc_password => "123456"
#启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
#指定追踪的字段,
tracking_column => "last_updated"
#追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是数字类型
tracking_column_type => "numeric"
#记录最后一次运行的结果
record_last_run => true
#上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
schedule => " * * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "users"
hosts => ["http://localhost:9200"]
user => "elastic"
password => "123456"
}
stdout{
codec => rubydebug
}
}运行logstash
bin/logstash -f mysql-demo.conf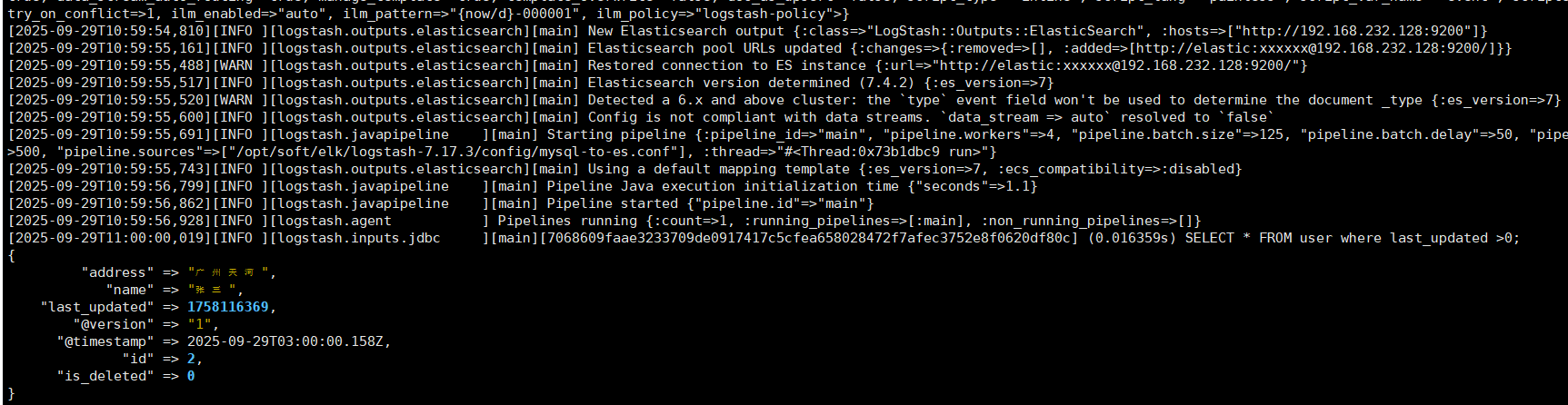
#user表
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`address` varchar(50) DEFAULT NULL,
`last_updated` bigint DEFAULT NULL,
`is_deleted` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 ;
#插入数据
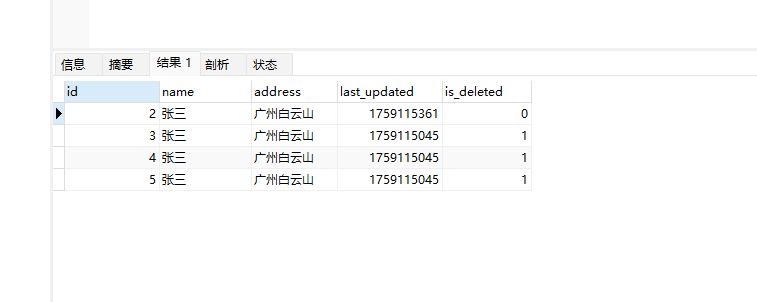
INSERT INTO user(name,address,last_updated,is_deleted) VALUES("张三","广州天河",unix_timestamp(NOW()),0);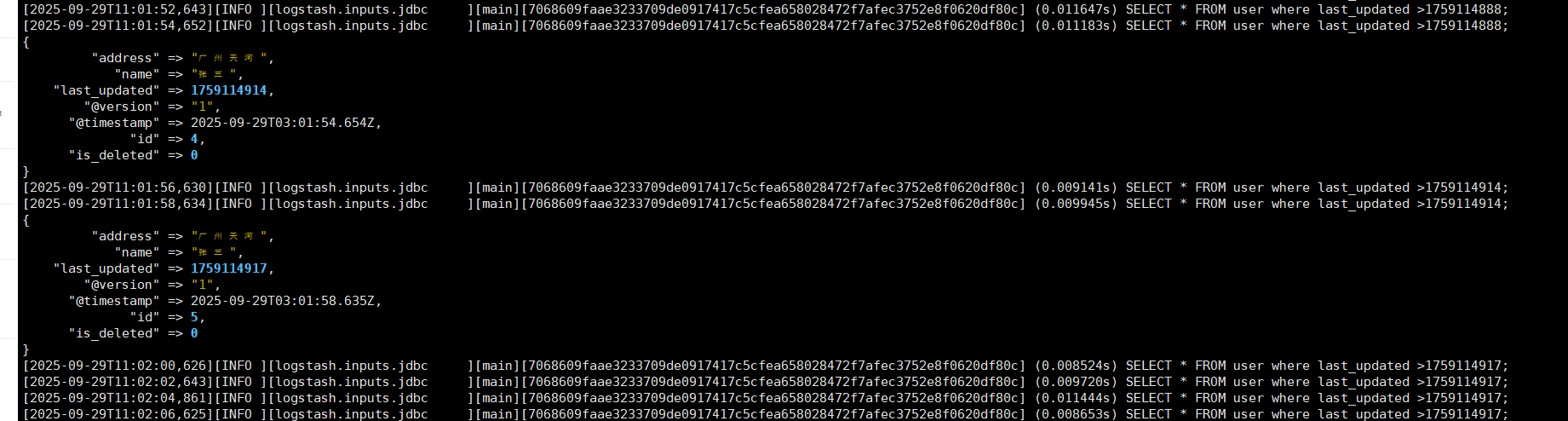
更新
update user set address="广州白云山",last_updated=unix_timestamp(NOW()) where name="张三";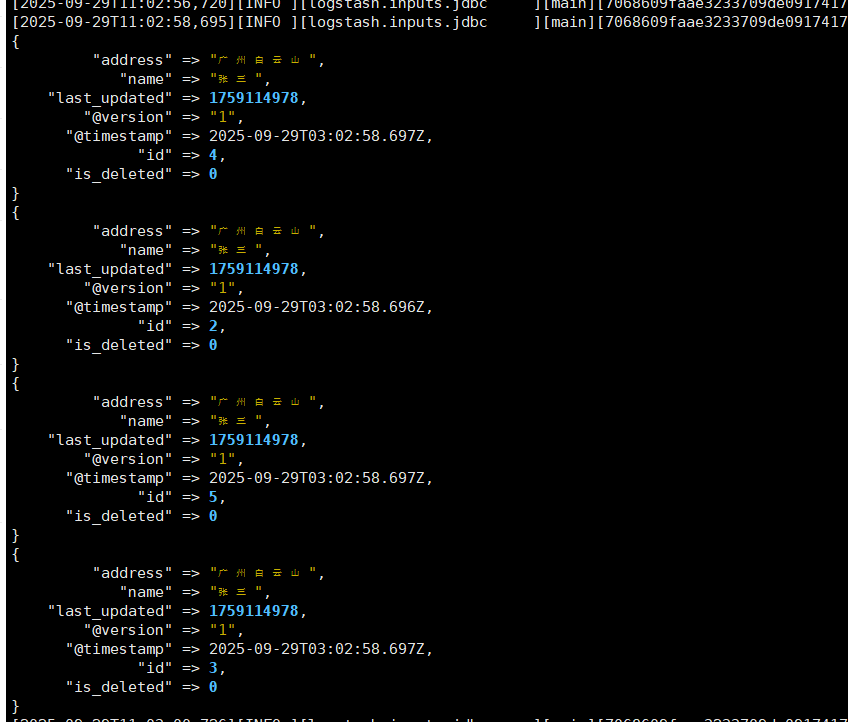
#删除
update user set is_deleted=1,last_updated=unix_timestamp(NOW()) where name="张三";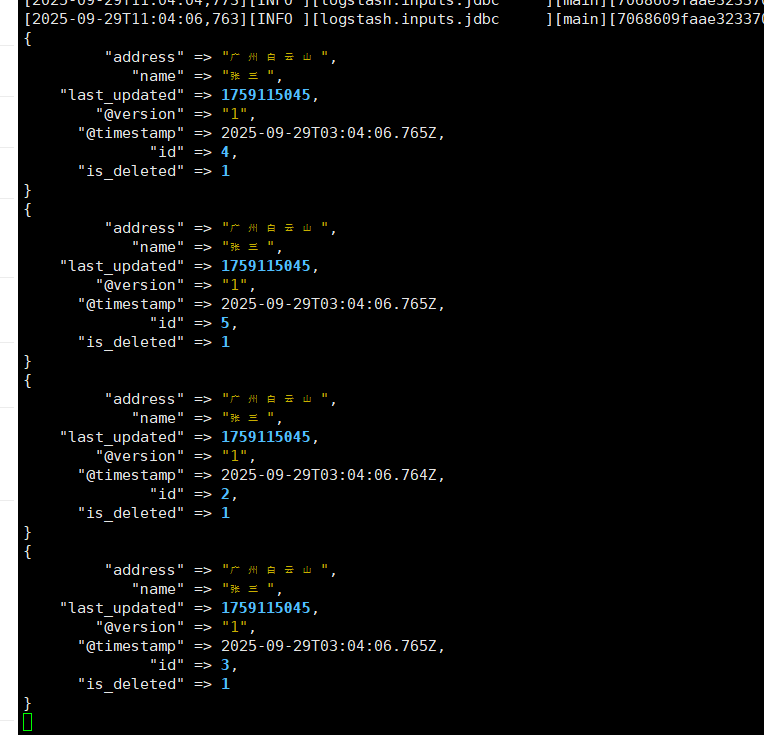
#ES中查询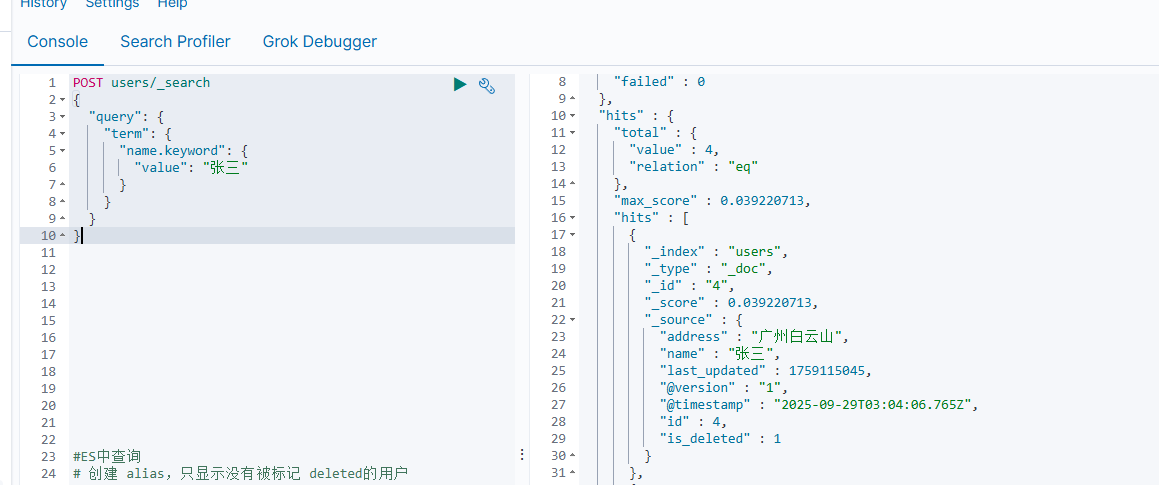
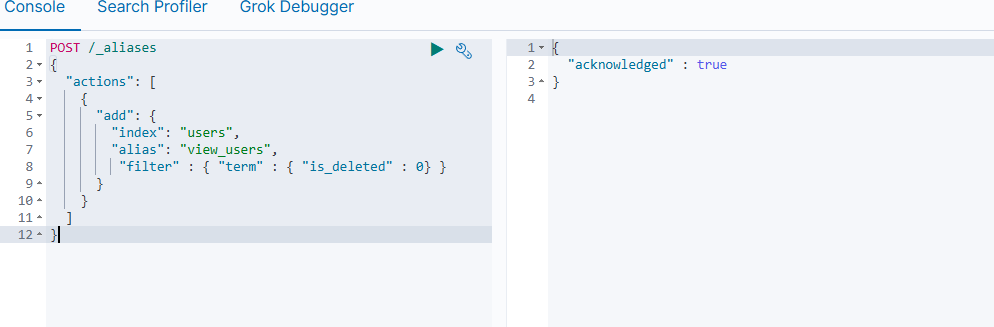
创建 alias,只显示没有被标记 deleted的用户
POST /_aliases
{
"actions": [
{
"add": {
"index": "users",
"alias": "view_users",
"filter" : { "term" : { "is_deleted" : 0} }
}
}
]
}
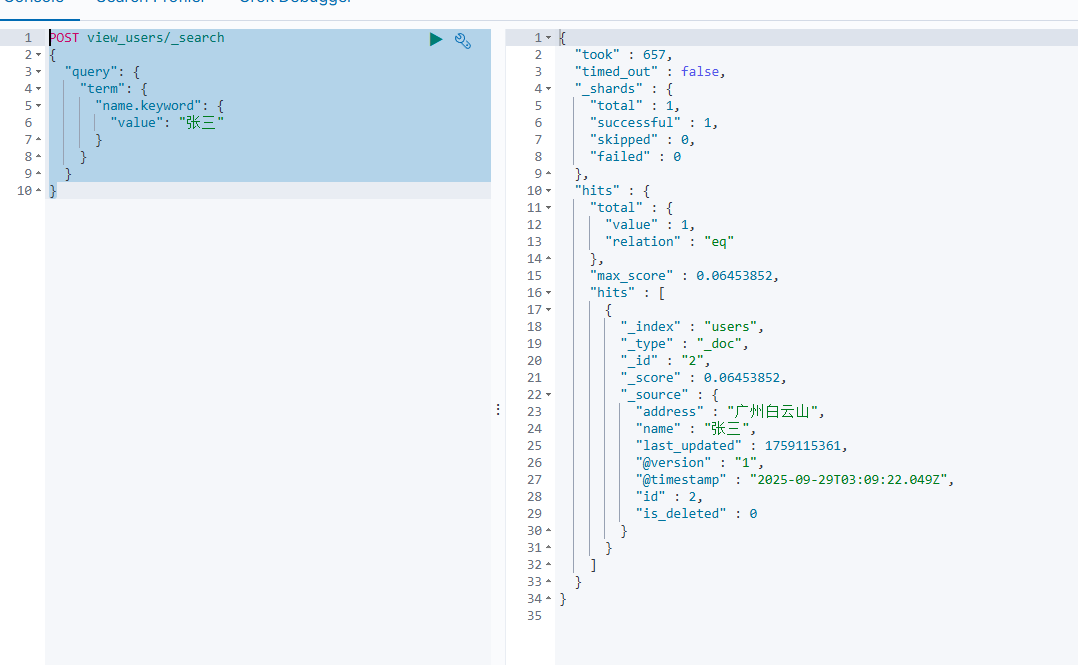
通过 Alias查询,查不到被标记成 deleted的用户
POST view_users/_search
POST view_users/_search
{
“query”: {
“term”: {
“name.keyword”: {
“value”: “张三”
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号